Go语言学习之11 日志收集系统kafka库实战
本节主要内容:
1. 日志收集系统设计
2. 日志客户端开发
1. 项目背景
a. 每个系统都有日志,当系统出现问题时,需要通过日志解决问题
b. 当系统机器比较少时,登陆到服务器上查看即可满足
c. 当系统机器规模巨大,登陆到机器上查看几乎不现实
2. 解决方案
a. 把机器上的日志实时收集,统一的存储到中心系统
b. 然后再对这些日志建立索引,通过搜索即可以找到对应日志
c. 通过提供界面友好的web界面,通过web即可以完成日志搜索
3. 面临的问题
a. 实时日志量非常大,每天几十亿条
b. 日志准实时收集,延迟控制在分钟级别
c. 能够水平可扩展
4. 业界方案ELK
日志收集系统架构
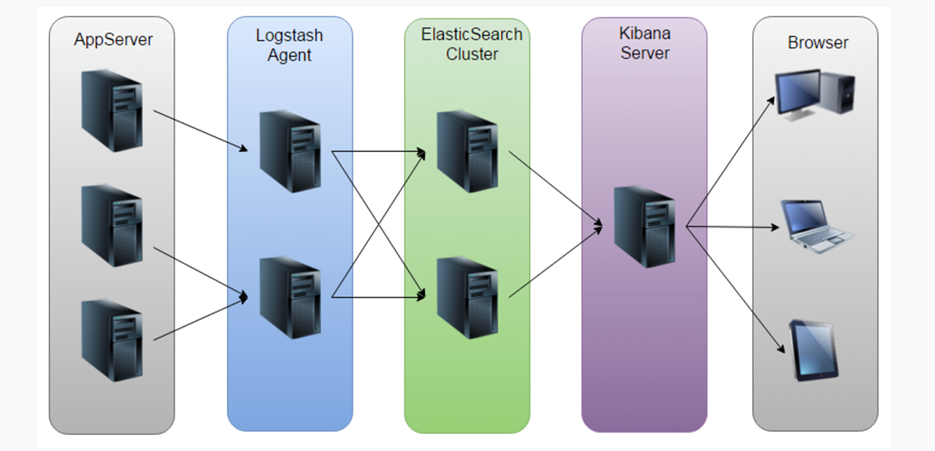
该方案问题:
a. 运维成本高,每增加一个日志收集,都需要手动修改配置
b. 监控缺失,无法准确获取logstash的状态
c. 无法做定制化开发以及维护
6. 日志收集系统设计
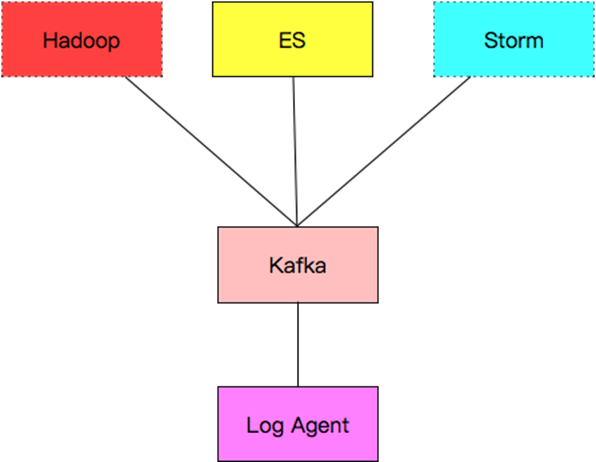
各组件介绍:
a. Log Agent,日志收集客户端,用来收集服务器上的日志
b. Kafka,高吞吐量的分布式队列,linkin开发,apache顶级开源项目
c. ES,elasticsearch,开源的搜索引擎,提供基于http restful的web接口
d. Hadoop,分布式计算框架,能够对大量数据进行分布式处理的平台
7. kafka应用场景
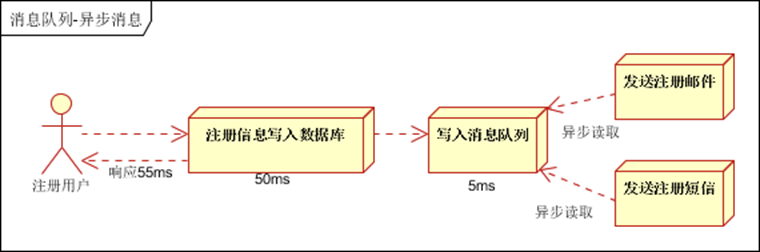
1. 异步处理, 把非关键流程异步化,提高系统的响应时间和健壮性

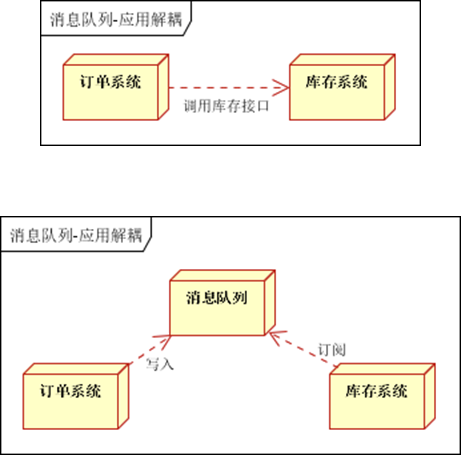
2. 应用解耦,通过消息队列
3. 流量削峰3. 流量削峰
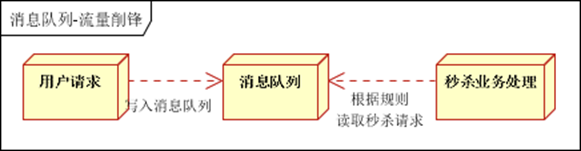
8. zookeeper应用场景
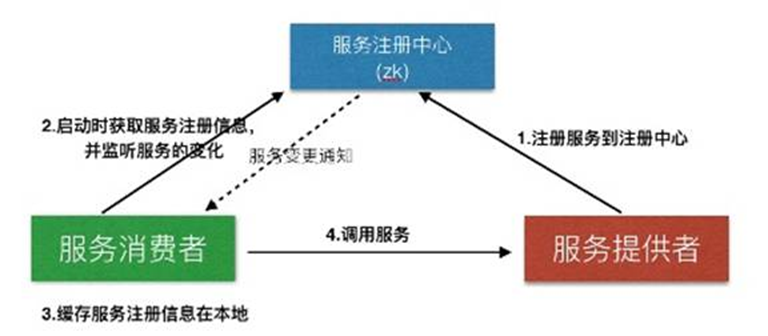
1. 服务注册&服务发现
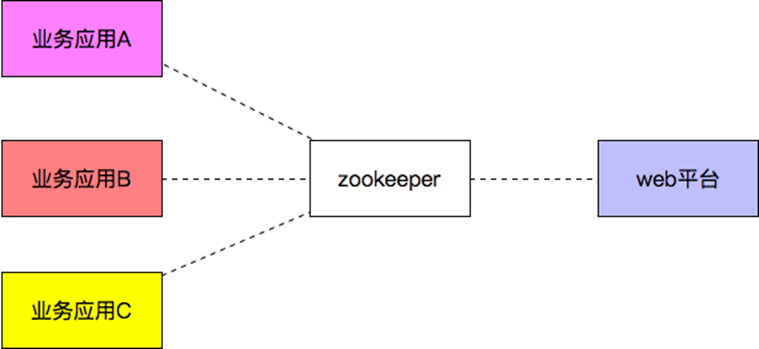
2. 配置中心
3. 分布式锁
- Zookeeper是强一致的
- 多个客户端同时在Zookeeper上创建相同znode,只有一个创建成功
9. 安装kafka
见博客:https://www.cnblogs.com/xuejiale/p/10505391.html
10. log agent设计
11. log agent流程
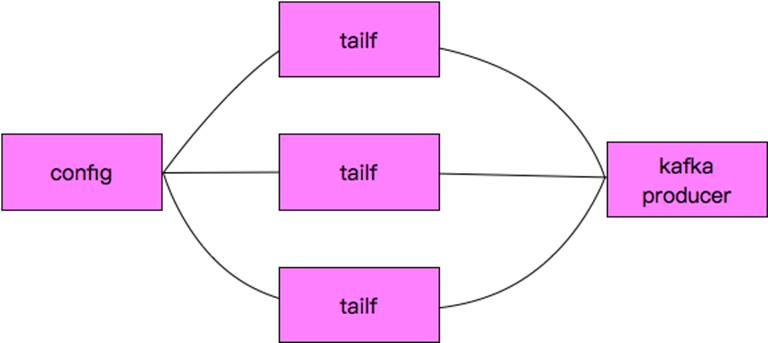
11. kafka示例
先导入第三方包:
github.com/Shopify/sarama
我的kafka和ZooKeeper都安装在Linux(Centos6.5,ip: 192.168.30.136)上:
package main import (
"fmt"
"time"
"github.com/Shopify/sarama"
) func main() { config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll
config.Producer.Partitioner = sarama.NewRandomPartitioner
config.Producer.Return.Successes = true client, err := sarama.NewSyncProducer([]string{"192.168.30.136:9092"}, config)
if err != nil {
fmt.Println("producer close, err:", err)
return
} defer client.Close()
for {
msg := &sarama.ProducerMessage{}
msg.Topic = "nginx_log"
msg.Value = sarama.StringEncoder("this is a good test, my message is good") pid, offset, err := client.SendMessage(msg)
if err != nil {
fmt.Println("send message failed,", err)
return
} fmt.Printf("pid:%v offset:%v\n", pid, offset)
time.Sleep(time.Second)
}
}
kafka示例
注意:Shopify/sarama的同步/异步producer,https://www.jianshu.com/p/666d2604e8f8
Windows启动程序往Linux上的kafka发送数据:

Linux上的kafka接收数据:

再来看一个kafka生产和消费示例:
package main import (
"fmt"
"github.com/Shopify/sarama"
) func main() {
// 新建一个arama配置实例
config := sarama.NewConfig()
// WaitForAll waits for all in-sync replicas to commit before responding.
config.Producer.RequiredAcks = sarama.WaitForAll
// NewRandomPartitioner returns a Partitioner which chooses a random partition each time.
config.Producer.Partitioner = sarama.NewRandomPartitioner
config.Producer.Return.Successes = true // new producer
client, err := sarama.NewSyncProducer([]string{"192.168.30.136:9092"}, config)
if err != nil {
fmt.Println("producer close, err:", err)
return
}
defer client.Close() // new message
msg := &sarama.ProducerMessage{}
msg.Topic = "food"
msg.Key = sarama.StringEncoder("fruit")
msg.Value = sarama.StringEncoder("apple") // send message
pid, offset, err := client.SendMessage(msg)
if err != nil {
fmt.Println("send message failed,", err)
return
}
fmt.Printf("pid: %v, offset:%v\n", pid, offset) // new message
msg2 := &sarama.ProducerMessage{}
msg2.Topic = "food"
msg2.Key = sarama.StringEncoder("fruit")
msg2.Value = sarama.StringEncoder("orange") // send message
pid2, offset2, err := client.SendMessage(msg2)
if err != nil {
fmt.Println("send message failed,", err)
return
}
fmt.Printf("pid2: %v, offset2:%v\n", pid2, offset2) fmt.Println("Produce success.")
}
produce
package main import (
"sync"
"github.com/Shopify/sarama"
"fmt"
) var wg sync.WaitGroup func main() {
consumer, err := sarama.NewConsumer([]string{"192.168.30.136:9092"}, nil)
if err != nil {
fmt.Println("consumer connect error:", err)
return
}
fmt.Println("connnect success...")
defer consumer.Close() partitions, err := consumer.Partitions("food")
if err != nil {
fmt.Println("geet partitions failed, err:", err)
return
} for _, p := range partitions {
partitionConsumer, err := consumer.ConsumePartition("food", p, sarama.OffsetOldest)
if err != nil {
fmt.Println("partitionConsumer err:", err)
continue
}
wg.Add()
go func(){
for m := range partitionConsumer.Messages() {
fmt.Printf("key: %s, text: %s, offset: %d\n", string(m.Key), string(m.Value), m.Offset)
}
wg.Done()
}()
}
wg.Wait() fmt.Println("Consumer success.")
}
consumer
12. tailf组件使用
先导入第三方包:
github.com/hpcloud/tail
package main import (
"fmt"
"github.com/hpcloud/tail"
"time"
)
func main() {
filename := "F:\\Go\\project\\src\\go_dev\\logCollect\\tailf\\my.log"
tails, err := tail.TailFile(filename, tail.Config{
ReOpen: true,
Follow: true,
//Location: &tail.SeekInfo{Offset: 0, Whence: 2},
MustExist: false,
Poll: true,
})
if err != nil {
fmt.Println("tail file err:", err)
return
}
var msg *tail.Line
var ok bool
for {
msg, ok = <-tails.Lines
if !ok {
fmt.Printf("tail file close reopen, filename:%s\n", tails.Filename)
time.Sleep( * time.Millisecond)
continue
}
fmt.Println("msg:", msg)
}
}
tailf示例代码
my.log文件内容(unix格式):
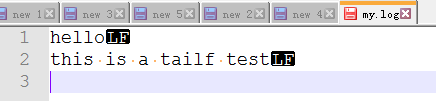
在Windows上,当我的上面代码里日志文件(my.log)为Windows格式,代码执行结果如下:

当时用notepade++将文件格式转换为Unix格式,执行代码结果如下:

注意:最后一行必须有换行符,否则该行无法读取。
13. 配置文件库使用
先导入第三方包:
github.com/astaxie/beego/config
1) 初始化配置库
iniconf, err := NewConfig("ini", "testini.conf")
if err != nil {
log.Fatal(err)
}
2) 读取配置项
String(key string) string
Int(key string) (int, error)
Int64(key string) (int64, error)
Bool(key string) (bool, error)
Float(key string) (float64, error)
例如:
iniconf.String("server::listen_ip")
iniconf.Int("server::listen_port")
[server]
listen_ip = "0.0.0.0"
listen_port =
[logs]
log_level=debug
log_path=./logs/logagent.log
[collect]
log_path=/home/work/logs/nginx/access.log
topic=nginx_log
package main import (
"fmt"
"github.com/astaxie/beego/config"
) func main() {
conf, err := config.NewConfig("ini", "./logcollect.conf")
if err != nil {
fmt.Println("new config failed, err:", err)
return
} port, err := conf.Int("server::listen_port")
if err != nil {
fmt.Println("read server:port failed, err:", err)
return
} fmt.Println("Port:", port)
log_level := conf.String("log::log_level")
if err != nil {
fmt.Println("read log_level failed, ", err)
return
}
fmt.Println("log_level:", log_level) log_path := conf.String("log::log_path")
fmt.Println("log_path:", log_path)
}
config示例代码
配置文件内容:
[server]
listen_ip = "0.0.0.0"
listen_port = [log]
log_level=debug
log_path=./logs/logagent.log [collect]
log_path=/home/work/logs/nginx/access.log
topic=nginx_log
执行结果:

14. 日志库的使用
先导入第三方包:
github.com/astaxie/beego/logs
1) 配置log组件
config := make(map[string]interface{})
config["filename"] = "./logs/logcollect.log"
config["level"] = logs.LevelDebug
configStr, err := json.Marshal(config)
if err != nil {
fmt.Println("marshal failed, err:", err)
return
}
2) 初始化日志组件
logs.SetLogger(“file”, string(configStr))
package main import (
"encoding/json"
"fmt"
"github.com/astaxie/beego/logs"
) func main() {
config := make(map[string]interface{})
config["filename"] = "./logcollect.log"
config["level"] = logs.LevelDebug configStr, err := json.Marshal(config)
if err != nil {
fmt.Println("marshal failed, err:", err)
return
} logs.SetLogger(logs.AdapterFile, string(configStr)) logs.Debug("this is a test, my name is %s", "stu01")
logs.Trace("this is a trace, my name is %s", "stu02")
logs.Warn("this is a warn, my name is %s", "stu03")
}
logs示例
15. 日志收集项目整体实现
开发环境为Windows系统,go version go1.12.1 windows/amd64, kafka_2.11-2.0.0,zookeeper-3.4.12。
先实现了一个demo,V1版本:
(1)代码结构图
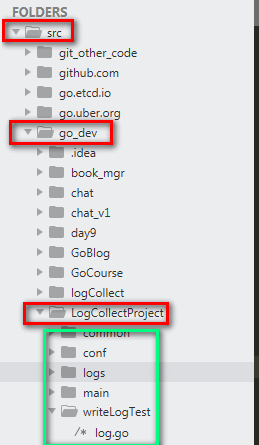
(2)代码地址见本人github:https://github.com/XJL635438451/logCollectProject/tree/master
(3)如何运行
1)先安装 go, kafka,zookeeper;
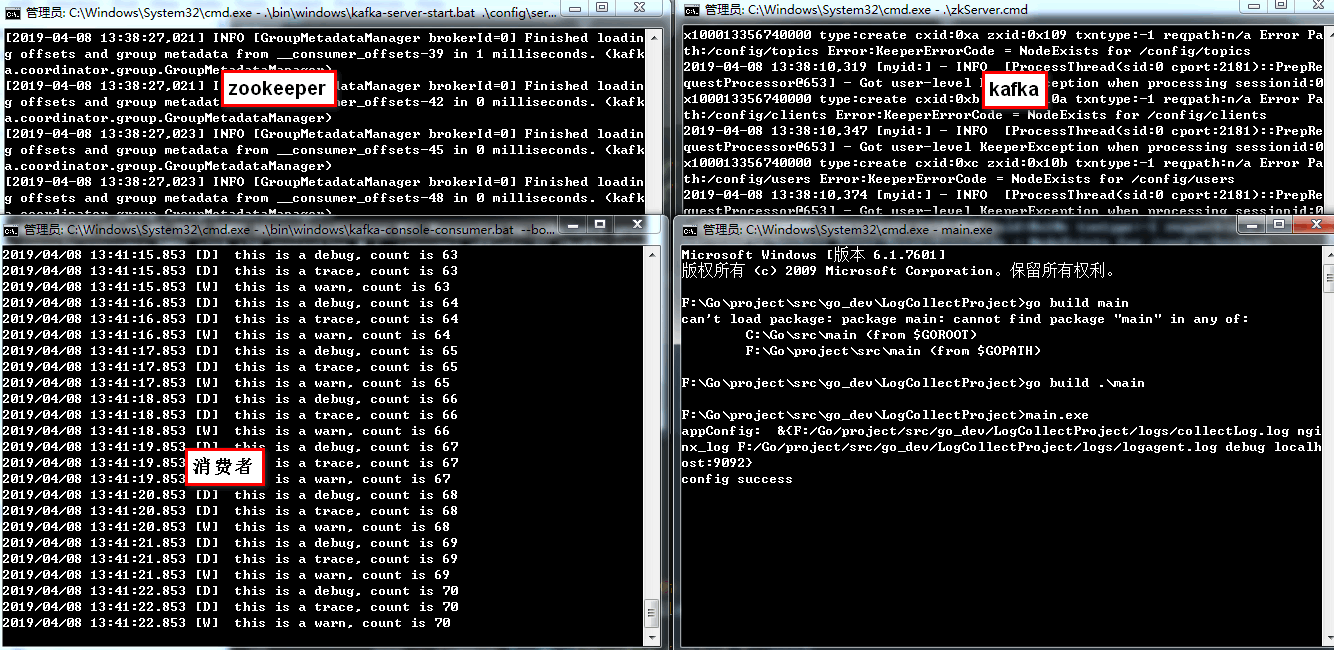
2)先启动 zookeeper,然后启动kafka,下面是启动的命令;
启动ZK
.\zkServer.cmd 启动kafka
F:\Go\project\src\module\kafka_2.-2.0.>.\bin\windows\kafka-server-start.bat .\config\server.properties 创建topic
F:\Go\project\src\module\kafka_2.-2.0.>.\bin\windows\kafka-topics.bat --create --zookeeper localhost: --replication-factor --partitions --topic kafkaTest 启动生产者:
F:\Go\project\src\module\kafka_2.-2.0.>.\bin\windows\kafka-console-producer.bat --broker-list localhost: --topic kafkaTest 启动消费者:
F:\Go\project\src\module\kafka_2.-2.0.>.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost: --topic nginx_log --from-beginning
3)如果自己不行写日志文件,可以运行代码中的 writeLogTest/log.go,然后运行 main.exe (如果自己修改了代码还需要重新编译);
4)可以起一个kafka的consumer来查看日志是否写入到了kafka,方法就是上面的启动生产者命令,如果正常就可以看到日志一直在kafka中刷新。
Go语言学习之11 日志收集系统kafka库实战的更多相关文章
- GO学习-(35) Go实现日志收集系统4
Go实现日志收集系统4 到这一步,我的收集系统就已经完成很大一部分工作,我们重新看一下我们之前画的图: 我们已经完成前面的部分,剩下是要完成后半部分,将kafka中的数据扔到ElasticSear ...
- GO学习-(34) Go实现日志收集系统3
Go实现日志收集系统3 再次整理了一下这个日志收集系统的框,如下图 这次要实现的代码的整体逻辑为: 完整代码地址为: etcd介绍 高可用的分布式key-value存储,可以用于配置共享和服务发现 ...
- GO学习-(32) Go实现日志收集系统1
Go实现日志收集系统1 项目背景 每个系统都有日志,当系统出现问题时,需要通过日志解决问题 当系统机器比较少时,登陆到服务器上查看即可满足 当系统机器规模巨大,登陆到机器上查看几乎不现实 当然即使是机 ...
- Go语言之高级篇beego框架之日志收集系统
一.日志收集系统架构设计 图1 图2 二.开发环境 1.安装jdk jdk-8u51-windows-x64.exe 安装目录:C:\Program Files\jdk8 2.安装zookeeper ...
- GO学习-(33) Go实现日志收集系统2
Go实现日志收集系统2 一篇文章主要是关于整体架构以及用到的软件的一些介绍,这一篇文章是对各个软件的使用介绍,当然这里主要是关于架构中我们agent的实现用到的内容 关于zookeeper+kaf ...
- [转载] 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
原文: http://www.36dsj.com/archives/25042 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要有日志收集系统.消息系统.分布式服务 ...
- 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
作者:大数据女神-诺蓝(微信公号:dashujunvshen).本文是36大数据专稿,转载必须标明来源36大数据. 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要 ...
- ELK+kafka构建日志收集系统
ELK+kafka构建日志收集系统 原文 http://lx.wxqrcode.com/index.php/post/101.html 背景: 最近线上上了ELK,但是只用了一台Redis在 ...
- Flume -- 开源分布式日志收集系统
Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. 一.Flum ...
随机推荐
- Cocos Creator(圆形遮罩头像)动态增加遮盖层 mask 并设为圆形生效
var avatar = new cc.Node('avatar'); var sp = node.addComponent(cc.Sprite); sp.spriteFrame = new cc.S ...
- kafka笔记9(监控)
Kafka提供的所有度量指标都是通过JMX(Java Management Extensions)接口访问 JMX端口查询: zookeeper上获取端口信息 /brokers/ids/<I ...
- PHP----------php的opcache扩展配置参数介绍
[opcache]zend_extension = "路径/ext/php_opcache.dll" ; Zend Optimizer + 的开关, 关闭时代码不再优化.opcac ...
- Linux启动顺序、运行级别及开机启动
一.启动顺序 当我们经过BIOS引导,并选择了Linux作为准备引导的操作系统后,接下来的执行顺序如下:1.加载并执行内核 第一个被加载的东西就是内核.然后把内核在内存中解压缩,就可以开始运行了.2. ...
- 记录Django学习1
一.Django 1.首先安装好django模块 pip3 install django 2.然后配置好相应的环境变量 C:\Python35\Scripts 3. 创建Django工程,首先可以使用 ...
- HTML——HTML部分学习笔记
1.前端工程师是干什么的? PC页面 移动端页面 Web开发 = 前端开发 + 后台开发--->web应用(网站) 后台:数据 前台:负责数据展示 + 交互效 ...
- eclipse jpa 工具生成实体类
1,配置数据库连接 打开eclipse, 选择数据库: 下一步,选择驱动包 根据自己的驱动包路径选择对应的驱动包: 2,配置jpa-tool 在项目上面右键->properties 点击ok,然 ...
- World is Exploding (容斥 + 统计)
题意:满足题目中的式子,a < b && c < d && Va < Vb && Vc > Vd 思路:先求不讨论位置重合的情况 ...
- JVM内存分配与垃圾回收机制管理
项目上线,性能优化有个重要组成就是jvm内存分配和垃圾回收机制的管理配置. 网上随便能搜到相关的具体步骤,以及内存中各种参数对应的意义,不再赘述. 干货就是直接抛出遇到的问题,以及如何解决的,再说说待 ...
- 使用gulp构建一个项目
gulp是前端开发过程中自动构建项目的工具,相同作用的还有grunt.构建工具依靠插件能够自动监测文件变化以及完成js/sass/less/html/image/css/coffee等文件的语法检查. ...