[大数据面试题]storm核心知识点
1.storm基本架构
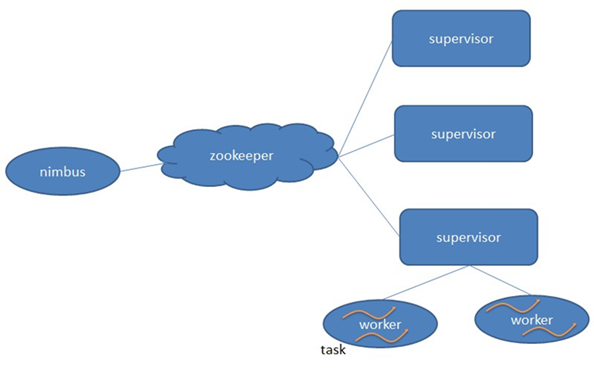
storm的主从分别为Nimbus、Supervisor,工作进程为Worker.

2.计算模型
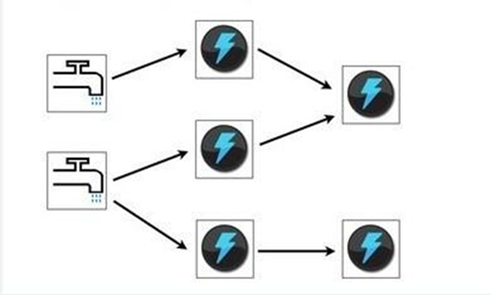
Storm的计算模型分为Spout和Bolt,Spout作为管口、Bolt作为中间节点,数据传输的单元为tuple,每个tuple都有一个值列表,
需要注意这个值列表是带name列表的,Bolt只需要订阅Bolt/Spout的值列表的某些name,就能获得该Bolt/Spout传过来的相应字段的数据。
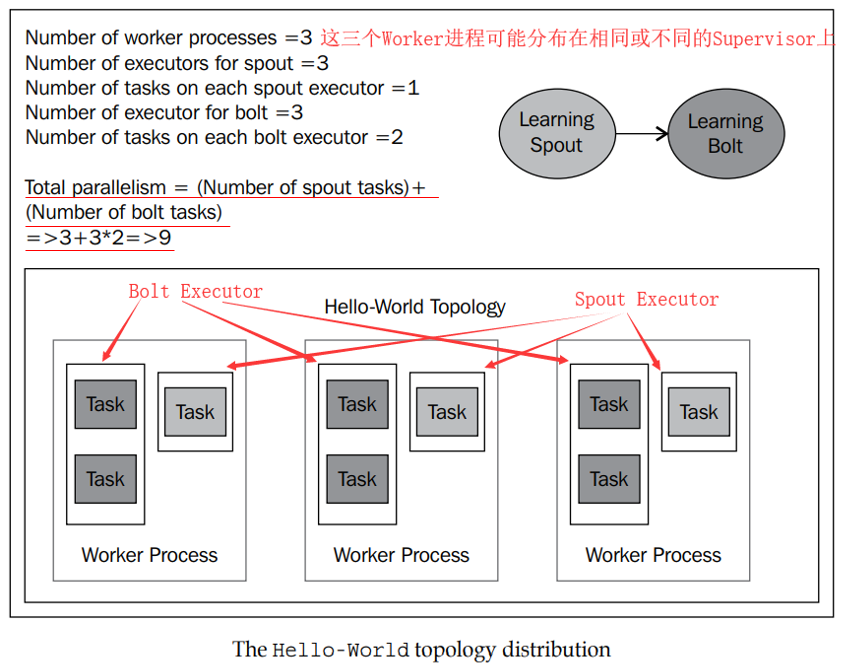
需要清楚并行度是怎么计算的,并行度其实就是Task的数目(也就是Bolt/Spout的具体实例数)。
总并行度 = Spout的executor线程数 * Spout的每个executor的task数目 + ABolt的executor线程数 * ABolt的每个executor的task的数目 + BBolt的executor线程数*BBolt的每个task的数目 + ....
3.流式计算框架对比
流计算框架按数据流的粒度不同分为两种:
1)原生的流处理,这种以消息/记录为传输处理单位进行挨个处理
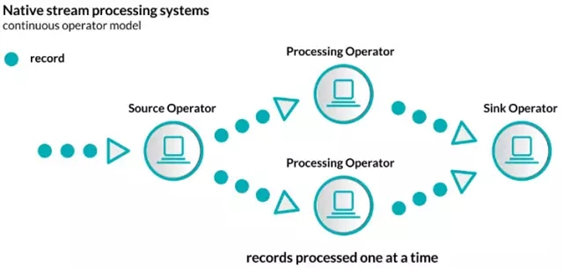
以消息/记录为单位进行处理 : Storm 、Samza 、Flink
2)微批处理,这种以一批消息/记录为单位进行小批次的批处理
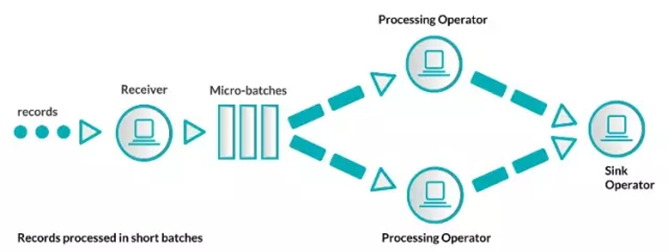
以小批次消息/记录为单位进行小批次批处理:Storm Trident 、Spark Streaming
使用这两种方式,导致本质上,原生的流处理比微批处理的方式延时更低一些。
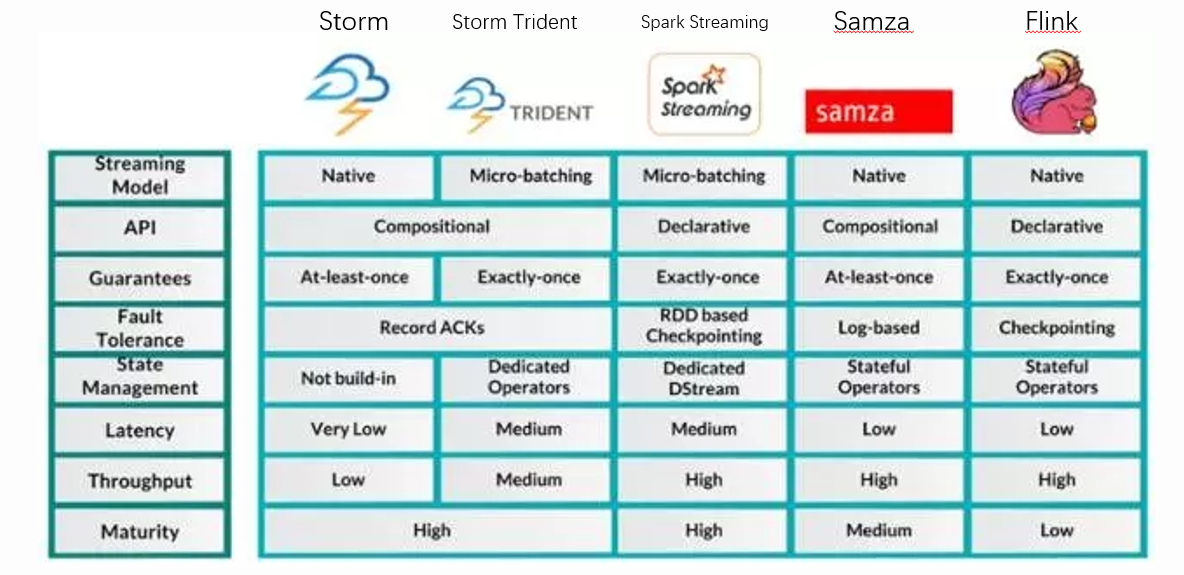
其中:
1)Storm、Samza、Flink因为其使用原生的流处理,因此Latency都很低。而使用微批处理的Storm Trident以及Spark Streaming延时不是很低。
2)关于数据传输可靠性,有“At-least-once"至少一次、”Exactly-once"精确一次、“At-most-once"至多一次三种语义。
可靠性排序: 精确一次 > 至少一次 -> 至多一次
3)对于流处理框架的选择,在不同的场景下会有不同
3.1 : 可靠性优先,必须保证“精确一次”: 这时,我们会从Storm Trident 、Spark Streming 以及 Flink当中选取,但是Storm Trident和Spark Streaming是微批处理的,所以延时相对原生批处理的Flink高。
而且Flink的吞吐量与Spark Streaming都是比较高的。因此采用Flink是可靠性优先的最优选择。
3.2 : 实时性优先,要求超低延时: 这时,我们只能选择Storm,Storm 底层采用ZeroMQ,处理速度是常见的MQ中最快的。但是这个选择一是状态管理需要自行完成,二是可靠性只能到“至少一次”级别,需要自己处理到“精确一次”,三是吞吐量很低。
4.常用的API

TODO
5.Grouping机制 - 分组策略
TODO
6.事务
TODO
7.DRPC
TODO
8.Trident
TODO
9.实际问题
1)pv计算,典型的聚合场景
Spout消费MQ中的数据并发送出去。
第一个Bolt进行分词和提取,判断每条数据记录,如果是访问记录,则emit出去1。
第二个Bolt进行局部的聚合,计算本地PV,并发送(thread_id,pv)标志线程级别的唯一性。
第三个Bolt进行全局聚合,计算总PV,这个全局聚合只能有一个,内部维护一个Hash<Long,Long>的数据结构(thread_id,pv),收到数据后实时更新,然后实时/每隔一段时间对pv进行求和。
2)UV计算,典型的去重聚合场景
常规思路:与之前PV计算类似
Spout消费MQ中的数据并发送出去。
第一个Bolt进行一些预处理,将(session_id,1)为单位发送出去。
第二个Bolt订阅第一个Bolt的数据,内部维护一个HashMap<String,Long>的结构存储局部的(session_id,count)信息。然后把(thread_id,hashmap)发送出去。
第三个Bolt进行全局聚合,计算总的UV,这个全局聚合只能有1个,内部维护一个HashMap<Long,HashMap<String,Long>>的结构存储(thread_id,hashmap(session_id,count)),
收到数据后实时进行更新,然后实时/每隔一段时间对UV进行session粒度的聚合。
特殊思路:我们可以想到在WordCount场景下不一定全局聚合只可以一个Bolt实例。完全可以通过hash(session_id)的方式,把相同的session_id控制在同一个的Bolt实例内。
Spout消费MQ中的数据并发送出去。
第一个Bolt进行一些预处理,将(hash_session_id,session_id,1)发射出去。
第二个Bolt注意要使用fieldsGrouping的方式,指定hash_session_id为grouping的依据字段,也就是说第一个Bolt发出的数据,只要hash_session_id相同,就会被发送到同一个Bolt实例。
第二个Bolt直接对session_id进行全局聚合,因为同一个session_id只会被发送到同一个Bolt实例,因此数据是准确的。内部直接维护一个HashMap<String,Long>的格式(session_id,count)。
这个Bolt实例可以有多个,将它们的数据分别持久化就可以了。
[大数据面试题]storm核心知识点的更多相关文章
- [大数据面试题]hadoop核心知识点
* 面试答案为LZ所写,如需转载请注明出处,谢谢. * 这里不涉及HiveSQL和HBase操作的笔试题,这些东西另有总结. 1.MR意义. MR是一个用于处理大数据的分布式离线计算框架,它采用”分而 ...
- 大数据Spark与Storm技术选型
先做一个对比: 对比点 Storm Spark Streaming 实时计算模型 纯实时,来一条数据,处理一条数据 准实时,对一个时间段内的数据收集起来,作为一个RDD,再处理 实时计算延迟度 毫 ...
- 大数据学习:storm流式计算
Storm是一个分布式的.高容错的实时计算系统.Storm适用的场景: 1.Storm可以用来用来处理源源不断的消息,并将处理之后的结果保存到持久化介质中. 2.由于Storm的处理组件都是分布式的, ...
- BAT大数据面试题
1.kafka的message包括哪些信息 一个Kafka的Message由一个固定长度的header和一个变长的消息体body组成 header部分由一个字节的magic(文件格式)和四个字节的CR ...
- 大数据 -- kafka学习笔记:知识点整理(部分转载)
一 为什么需要消息系统 1.解耦 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险.许多 ...
- Shell在大数据的魅力时代:从一点点思路百度大数据面试题
供Linux开发中的同学们,Shell这可以说是一个基本功. 对于同学们的操作和维护.Shell也可以说是一种必要的技能,Shell.对于Release Team,软件配置管理的同学来说.Shell也 ...
- Shell在大数据时代的魅力:从一道百度大数据面试题想到的点滴
对于在Linux下开发的同学来说,Shell可以说是一种基本功. 对于运维的同学来说,Shell可以说是一种必备的技能,而且应该要非常熟练的书写Shell.对于Release Team,软件配置管理的 ...
- 大数据学习——kafka+storm+hdfs整合
1 需求 kafka,storm,hdfs整合是流式数据常用的一套框架组合,现在 根据需求使用代码实现该需求 需求:应用所学技术实现,kafka接收随机句子,对接到storm中:使用storm集群统计 ...
- 大数据面试题(一)----HADOOP 面试题
1. 下列哪项通常是集群的最主要瓶颈(C) A. CPU B. 网络 C. 磁盘IO D. 内存 2. 下列哪项可以作为集群的管理工具?(C) A.Puppet B.Pdsh C.ClouderaMa ...
随机推荐
- Matlab文件和数据的导入与导出
ref: https://blog.csdn.net/zengzeyu/article/details/72530596 Matlab文件和数据的导入与导出 2017年05月19日 15:18:35 ...
- 客户端不能连接MySQL - 2003-Can't connect to MySQL server on '192.168.43.180'(10060 "Unknown error")
客户端不能连接MySQL 场景: 数据库(此处以MySQL为例)安装在虚拟机里面,在宿主机上进行连接数据库的时候始终不能连接,但在虚拟机中使用正常. 针对上面的场景: 1. 在虚拟机里面可以正常使用M ...
- CSS其它特性
文本内容左右对齐及盒子自身左右对齐 说白了,浮动就是可以让我们的div在一行中显示,方便布局,并且各个div之间没有空隙,如果使用display:inline-block也能在一行显示几个div,但是 ...
- [转载来之雨松:NGUI研究院之为什么打开界面太慢(十三)]
本文固定链接: http://www.xuanyusong.com/archives/2799
- Log4j2 日志级别
Log4j2日志级别 级别 在log4j2中, 共有8个级别,按照从低到高为:ALL < TRACE < DEBUG < INFO < WARN < ERROR < ...
- 2018-2019-3 网络对抗技术 20165305 Exp3 免杀原理与实践
1.实验内容及步骤 1.1 正确使用msf编码器,msfvenom生成如jar之类的其他文件,veil-evasion,加壳工具,使用shellcode编程 将做实验二时生成的后门文件用virusto ...
- appium工作原理
Appium原理 面试的时候,被问到appium原理,一点不会,实在尴尬.大家可以直接翻看原作https://blog.csdn.net/jffhy2017/article/details/69220 ...
- Java面向对象概述和三大特性
Java 是面向对象的高级编程语言,类和对象是 Java 程序的构成核心.围绕着 Java 类和 Java 对象,有三大基本特性:封装是 Java 类的编写规范.继承是类与类之间联系的一种形式.而多态 ...
- Git抽取版本之间的差异,打包解压
patch.sh文件代码 #!/bin/bash MY_SAVEIFS=$IFS #IFS=$(echo -en "\n\b") IFS=$'\n' build_dir=" ...
- 安卓加载网络图片OOM问题解决
前言:次片是上篇后续出现的问题,在网上找了很多博客,越解决越乱,好在最后看了郭霖的博客给了我一点思路 借鉴:http://blog.csdn.net/guolin_blog/article/detai ...