再回首数据结构—数组(Golang实现)
数组为线性数据结构,通常编程语言都有自带了数组数据类型结构,数组存放的是有个相同数据类型的数据集;
为什么称数组为线性数据结构:因为数组在内存中是连续存储的数据结构,数组中每个元素最多只有左右两个方向有相邻的元素;数组中的每个元素都有一个索引(或称下标)标识,这个索引在编程语言中通常都是从0开始,通过索引可访问到数组中对应的元素;数组的数据结构如下所示:

数组的优势
从上文中我们知道数组在内存中是连续存储的也就是说数组中元素在内存块为连续,此时我们利用此特性通过索引快速访问数据元素;因此也称数组支持随机访问;
下面我们通过一个示例来说明数组的随机访问特性;
在Go中定义一个长度为7的数组:
var array [7] int
此时我们可以通过索引随机访问数组中元素如:array[5]即可访问到数组中的第六个元素,这背后又是怎样的呢,上面我们说过数组在内存中的存储结构是连续的上面我们定义的数组结构如下所示:
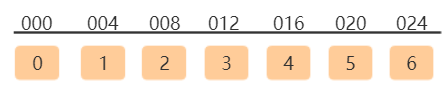
此处假设该数组内存空间首地址为:000,由于该数据类型为int因此每个数据元素占4个字节,所以上面定义7个长度数组占用的内存地址为:000~024连续的地址空间;所以通过下面的计算公式即可实现数组的随机访问,比如访问数组中第五个元素内存地址的计算公式如下:
所访问元素内存地址=数组首地址 + index * 数据类型大小
array[5]内存地址 = 000 + 5 * 4
所以数组的优势为:1、简单;2、支持随机访问,通过索引随机访问时间复杂度为O(1)
数组插入与删除
数组的插入与删除其实并不高效,由于数组存储是连续的内存空间,所以我们在对数组进行操作时都需要去维护这个连续性,因此也就牺牲了一些效率,当插入或删除数组中元素时数组中元素都需要大量移动如下图所示:
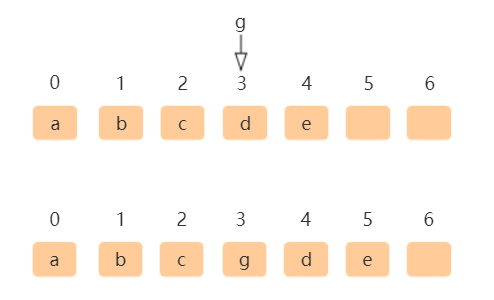
在索引为3的位置插入g,需把索引3~n元素后移一位
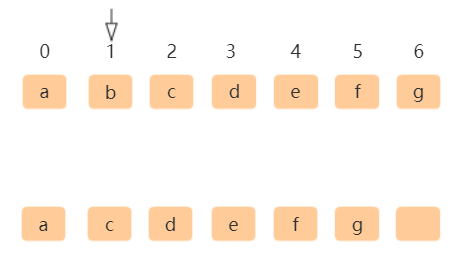
删除数组索引为1的元素,需把索引2~n元素前移一位
因此数组的插入、删除平均时间复杂度为:O(n),这里说的是平均复杂度是因为还有例外情况,比如在数组末尾插入元素、删除数组末尾元素这些情况时间复杂度为O(1);
每种编程语言中都存在数组,数组其实还分为静态数组、动态数组;静态数组是指数组创建后存储空间固定不变的、而动态数组为在使用数组过程中当存储空间不足时可动态扩容;下面为使用Golang实现的动态数组封装,动态数组的扩容、缩容需要注意扩容的大小与缩容的零界点,此处可能会影响到数组性能;
type Array struct {
data []interface{}
size int
}
func NewArray(capacity int) *Array {
array := new(Array)
array.data = make([]interface{}, capacity)
array.size = 0
return array
}
func NewDefaultArray() *Array {
return NewArray(10)
}
/**
获取元素个数
*/
func (a *Array) Size() int {
return a.size
}
/**
获取容量大小
*/
func (a *Array) Capacity() int {
return len(a.data)
}
/**
是否为空
*/
func (a *Array) IsEmpty() bool {
return a.size == 0
}
/**
往数组末尾添加元素
*/
func (a *Array) AddLast(e interface{}) error {
return a.Add(a.size, e)
}
/**
清空数组
*/
func (a *Array) Clear() {
a.data = make([]interface{}, a.size)
a.size = 0
}
/**
往第一个位置添加元素
*/
func (a *Array) AddFirst(e interface{}) error {
return a.Add(0, e)
}
/**
往指定索引添加元素
*/
func (a *Array) Add(index int, e interface{}) error {
if index < 0 || index > a.size {
return errors.New("Add failed, Require index >= 0 and index< size")
}
if a.size == len(a.data) {
a.resize(2 * len(a.data))
}
for i := a.size - 1; i >= index; i-- {
a.data[i+1] = a.data[i]
}
a.data[index] = e
a.size++
return nil
}
/**
更新指定位置元素
*/
func (a *Array) Update(index int, e interface{}) error {
if index < 0 || index > a.size {
return errors.New("update failed, Require index >= 0 and index< size")
}
a.data[index] = e
return nil
}
/**
获取指定位置元素
*/
func (a *Array) FindElement(index int) interface{} {
if index < 0 || index > a.size {
return errors.New("update failed, Require index >= 0 and index< size")
}
return a.data[index]
}
/**
删除数组指定索引位置的元素,返回删除的元素
*/
func (a *Array) Remove(index int) (e interface{}) {
if index < 0 || index > a.size {
return errors.New("remove failed, Require index >= 0 and index< size")
}
e = a.data[index]
for i := index + 1; i < a.size; i++ {
a.data[i-1] = a.data[i]
}
a.size--
//删除元素后数组缩小一位,将该位置元素置nil
a.data[a.size] = nil
return
}
/**
删除数组首个元素
*/
func (a *Array) RemoveFirst() (e interface{}) {
return a.Remove(0)
}
/**
数组扩容
*/
func (a *Array) resize(newCapacity int) {
newData := make([]interface{}, newCapacity)
for i := 0; i < a.size; i++ {
newData[i] = a.data[i]
}
a.data = newData
}
参考资料: https://zh.wikipedia.org/wiki/数组
文章首发地址:Solinx
http://www.solinx.co/archives/1265
再回首数据结构—数组(Golang实现)的更多相关文章
- 再回首数据结构—AVL树(一)
前面所讲的二叉搜索树有个比较严重致命的问题就是极端情况下当数据以排序好的顺序创建搜索树此时二叉搜索树将退化为链表结构因此性能也大幅度下降,因此为了解决此问题我们下面要介绍的与二叉搜索树非常类似的结构就 ...
- 再回首数据结构—AVL树(二)
前面主要介绍了AVL的基本概念与结构,下面开始详细介绍AVL的实现细节: AVL树实现的关键点 AVL树与二叉搜索树结构类似,但又有些细微的区别,从上面AVL树的介绍我们知道它需要维护其左右节点平衡, ...
- (js描述的)数据结构 [数组的一些补充](1)
(js描述的)数据结构 [数组的一些补充](1) 1. js的数组: 1.优点:高度封装,对于数组的操作就是调用API 2.普通语言的数组: 1.优点:根据index来查询,修改数据效率很高 2.缺点 ...
- 再回首,Java温故知新——开篇说明
不知不觉在IT界从业2年了,两年时间足够一个人成长很多,当然也会改变很多事.在这两年时间里,随着对技术的深入了解,知识面的拓展以及工作难度的增大,渐渐的感觉自己技术方面根基不稳,多数问题也只是做到知其 ...
- JAVA基础再回首(二十五)——Lock锁的使用、死锁问题、多线程生产者和消费者、线程池、匿名内部类使用多线程、定时器、面试题
JAVA基础再回首(二十五)--Lock锁的使用.死锁问题.多线程生产者和消费者.线程池.匿名内部类使用多线程.定时器.面试题 版权声明:转载必须注明本文转自程序猿杜鹏程的博客:http://blog ...
- 再回首UML之下篇
接着我们上篇博客再回首UML之上篇说,在类图中有四种关系,关联.依赖.泛化.实现,接下来,我们来看看依赖,依赖--描述的是一种使用关系,她说明一个事物的规格说明的变化可能影响到他使用的另一个事物,反之 ...
- 再回首UML之上篇
UML,统一建模语言,是一种用来对真实世界物体进行建模的标准标记,这个建模的过程是开发面向对象设计方法的第一步,UML不是一种方法学,不需要任何正式的工作产品. UML提供多种类型的模型描述图,当在某 ...
- 【C/C++学院】0828-数组与指针/内存分配/数据结构数组接口与封装
[送给在路上的程序猿] 对于一个开发人员而言,可以胜任系统中随意一个模块的开发是其核心价值的体现. 对于一个架构师而言,掌握各种语言的优势并能够运用到系统中.由此简化系统的开发,是其架构生涯的第一步. ...
- UML——再回首
概述 在画图的过程中,发现自己还是有好多不懂的地方,对于四大关系理解的不是特别透彻,所以画图的过程中总是"剪不断,理还乱!"再一次整理四大关系,再回首必然丰收~~~ 1.实 ...
随机推荐
- Capsules for Object Segmentation(理解)
0 - 背景 今年来卷积网络在计算机视觉任务上取得的显著成果,但仍然存在一些问题.去年Hinton等人提出了使用动态路由的新型网络结构——胶囊网络来解决卷积网络的不足,该新型结构在手写体识别以及小图像 ...
- 关于操作HDFS的一个问题
近日写程序定时任务调Hadoop MR程序,然后生成报表,发送邮件,当时起了两个任务A和B,调MR程序之前,会操作hdfs(读写都有),任务A每天一点跑,任务B每十分钟跑一次,B任务不会调用MR程序, ...
- “放到桌面”的Servlet实现
复习下Servlet下载文件, 当response把ContentType设置成application/xxxx的时候呢,浏览器会默认启动下载,而不是试图打开. 通过给httpHeader里面加入内容 ...
- 20175204 张湲祯 2018-2019-2《Java程序设计》2
20175204 张湲祯 2018-2019-2<Java程序设计>2 必做课下作业MyCP 要求 编写MyCP.java 实现类似Linux下cp XXX1 XXX2的功能,要求MyCP ...
- Java继承详解
目录 前言 继承的格式: 继承的特点: 继承的优缺点 继承的注意点(重要) 继承的使用 前言 类是对对象的抽象,具有共同属性和行为的许多对象抽象出一个类. 例如:有三个学生小明,小红,小李都有姓名,年 ...
- linux中gcc和g++的区别
1.两者都是编译器 2.gcc编译c语言:g++既可以编译c语言,也可以编译c++语言 3.gcc不能自动链接库文件,一般用g++来链接库文件,非要用gcc的话,一般使用gcc -lstdc++命令 ...
- C# EntityFramework Code First 迁移
如果使用的是 Code First 工作流,推荐使用 Code First 迁移改进应用程序的数据库架构. 迁移提供一组允许以下操作的工具: 创建可用于 EF 模型的初始数据库 生成迁移以跟踪对 EF ...
- selenium打开Chrome浏览器并最大化
#打开Chrome浏览器并放大 from selenium import webdriver def BrowserOpen(): driver = webdriver.Chrome(); drive ...
- PDF怎么添加文字水印与图片水印
现在是个知识分享时代,但不可避免的盗版也无处不在,不知道在我们大家身边有没有遇到过这样的情况:自己煞费苦心制作的PDF文档不知道在什么时候就会被别人给盗用了,那么如何才能尽量避免这个问题呢?今天带大家 ...
- linux目录的特点
1./是所有目录的顶点. 2.目录结构像一颗倒挂的树 3.目录和磁盘分区,默认是木有关联的 4./不同的目录可能会对应不同的分区或磁盘 linux里设备如果不挂载是看不到入口的, 如果希望设备被访问, ...