Kafka笔记4(消费者)
消费者和消费群组:
Kafka消费者从属于消费者群组,一个群组里的消费者订阅的是同一个主题,每个消费者接收主题的一部分分区消息
消费者的数量不要超过主题分区的数量,多余的消费者只会被闲置
一个主题可以被多个消费群组使用,消费者群组之间互不影响
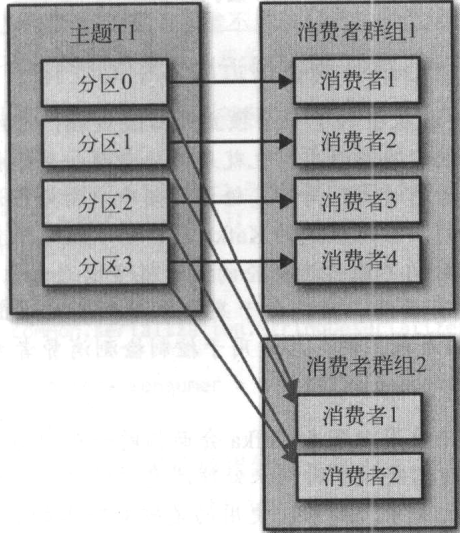
当一个消费者加入群组时,他读取的数据是原本由其他消费者读取的信息
分区的所有权从一个消费者转移至另一个消费者的行为称为“再均衡”
再均衡期间,消费者当前的读取状态会丢失,消费者无法读取信息,造成集群一小段时间的不可用,在恢复状态之前会拖慢应用程序
消费者通过向群组协调器broker发送心跳维持他们和群组的从属关系以及他们对分区的所有权关系,如果broker认为消费者死亡会触发再均衡行为
分配分区过程:
当消费者加入群组时,他会向群组协调器发送一个JoinGroup请求,第一个加入群组的消费者称为群主,群主从协调器那里获得群组的成员列表,并负责给每一个消费者分配分区。他使用一个实现PartitionAssignor接口的类来决定哪些分区应该被分配给消费者,分配完毕之后,群主把分配情况列表发送给broker,broker再把这些信息发送给所有消费者,每个消费者只能看到自己的分配信息,只有群主知道群组的所有消费者的分配信息
消息轮询是消费者API核心,通过从一个简单的轮询向服务器请求数据,一旦消费者订阅了主题,轮询就会处理所有细节,包括群组协调/分区再均衡/发送心跳/获取数据
一个消费者使用一个线程
消费者重要的属性参数配置:
fetch.min.bytes
指定了消费者从服务器获取记录的最小字节数,如果broker收到消费者请求,但数据可用量小于fetch.min.bytes,就会等到有足够的可用数据才把它返回给消费者
fetch.max.wait.ms
指定broker等待时间,默认500ms
max.partition.fetch.bytes
指定服务器从每个分区里返回给消费者的最大字节数,默认1MB max.partition.fetch.size的值必须比broker能接收的最大消息字节数(max.message.size)大
session.timeout.ms
指定消费者在被认为死亡之前可以与服务器断开连接的时间,默认3S
heartbeat.interval.ms = session.timeout.ms / 3
auto.offset.reset
指定消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该如何处理
=latest 消费者从最新的记录开始读取数据
=earliest 消费者从起始位置读取分区记录
enable.auto.commit
指定消费者是否自动提交偏移量,默认true
auto.commit.interval.ms 控制提交频率
partition.assignment.strategy
=org.apache.kafka.clients.consumer.RangeAssignor 把主题的若干连续分区分配给消费者
=org.apache.kafka.clients.consumer.RoundRobinAssignor 把主题的所有分区逐个分配给消费者
client.id
任意字符串,broker用来标识从客户端发送来的消息
max.poll.records
用于控制单次调用call() 方法返回的记录数量,可以帮你控制在轮询里需要处理的数据量
receive.buffer.bytes 和 send.buffer.bytes
默认-1
更新分区当前位置的操作叫提交
消费者会向一个叫做 _consumer_offset 的特殊主题发送消息,消息里包含了每个分区的偏移量
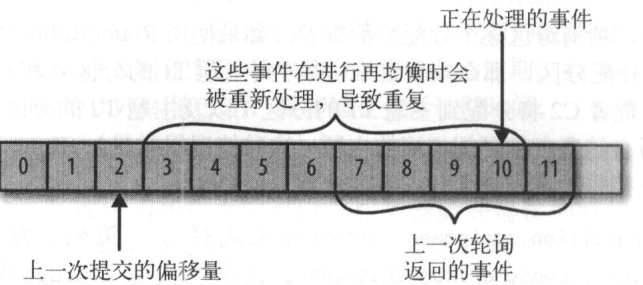
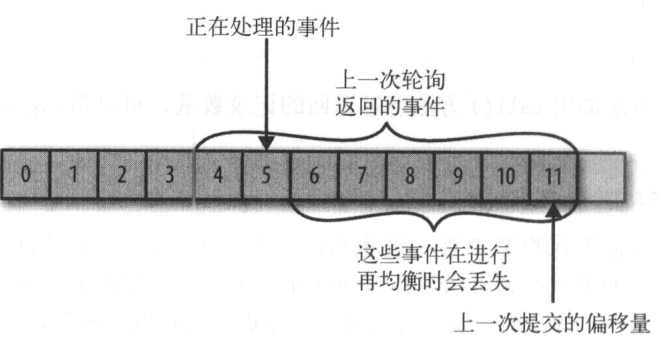
Kafka可以设置消费者自动提交偏移量,设置enable.auto.commit=true,提交时间间隔auto.commit.interval.ms=5s
自动提交是在轮询里进行的,消费者每次轮询时会检查是否该提交偏移量了,是则提交上一次轮询返回的偏移量
提交当前偏移量,使用API函数 commitSync()
异步提交偏移量,使用API函数commitAsync()
可以使用一个单调递增的序列号来维护异步提交顺序
Kafka笔记4(消费者)的更多相关文章
- Kafka笔记整理(三):消费形式验证与性能测试
Kafka消费形式验证 前面的<Kafka笔记整理(一)>中有提到消费者的消费形式,说明如下: .每个consumer属于一个consumer group,可以指定组id.group.id ...
- 关于Kafka 的 consumer 消费者处理的一些见解
前言 在上一篇 Kafka使用Java实现数据的生产和消费demo 中介绍如何简单的使用kafka进行数据传输.本篇则重点介绍kafka中的 consumer 消费者的讲解. 应用场景 在上一篇kaf ...
- [Spark][kafka]kafka 生产者,消费者 互动例子
[Spark][kafka]kafka 生产者,消费者 互动例子 # pwd/usr/local/kafka_2.11-0.10.0.1/bin 创建topic:# ./kafka-topics.sh ...
- kafka生产者和消费者流程
前言 根据源码分析kafka java客户端的生产者和消费者的流程. 基于zookeeper的旧消费者 kafka消费者从消费数据到关闭经历的流程. 由于3个核心线程 基于zookeeper的连接器监 ...
- Apache Kafka 0.9消费者客户端
当Kafka最初创建时,它与Scala生产者和消费者客户端一起运送.随着时间的推移,我们开始意识到这些API的许多限制.例如,我们有一个“高级”消费者API,它支持消费者组并处理故障转移,但不支持许多 ...
- kafka笔记——入门介绍
中文文档 目录 kafka的优势 首先几个概念 kafka的四大核心API kafka的基本术语 主题和日志(Topic和Log) 每个分区都是一个顺序的,不可变的队列,并且可以持续的添加,分区中的每 ...
- 《Kafka笔记》1、Kafka初识
目录 一.初识Kafka 1 apache kafka简介 2 消息中间件kafka的使用场景 2.1 订阅与发布队列 2.2 流处理 3 kafka对数据的管理形式 4 kafka基础架构 5 Ka ...
- kafka生产者和消费者api的简单使用
kafka生产者和消费者api的简单使用 一.背景 二.需要实现的功能 1.生产者实现功能 1.KafkaProducer线程安全的,可以在多线程中使用. 2.消息发送的key和value的序列化 3 ...
- Kafka学习笔记4--Kafka消费者的客户端(PHP)开发
一.准备工作 虽然 Kafka 是用 Java/Scala 语言编写的,但这不妨碍它对多语言的支持.可以在 Kafka 官网的 CLIENTS 查看 Kafka 支持的语言,其中包括 C/C++.Py ...
随机推荐
- HttpSession与JSESSIONID的"盗用"
https://blog.csdn.net/qq1437715969/article/details/75331652
- JMeter命令模式下动态设置线程组和持续时间等动态传参
背景: 1.当通过JMeter的图像化界面运行性能压测或者场景时候,JMeter界面很容易导致界面卡死或者无响应的情况(20个线程数就会卡死) 现象如下:
- Centos6.5部署vsftpd+mysql认证
1.FTP传输原理 FTP,文件传输协议,是工作在应用层,基于TCP实现,依赖于互联网即可通讯. 1)连接模式 控制(命令)连接,用来通信,一直在线,客户端随机端口连接服务端TCP:21端口. 数据连 ...
- Linux epoll机制
epoll_create.epoll_ctl.epoll_wait.close 在linux的网络编程中,很长的时间都在使用select来做事件触发.在linux新的内核中,有了一种替换它的机制,就是 ...
- UIButton设置标题左对齐
Button.contentHorizontalAlignment = UIControlContentHorizontalAlignmentLeft;//左对齐(UIControlContentHo ...
- [LeetCode] Swap Adjacent in LR String 交换LR字符串中的相邻项
In a string composed of 'L', 'R', and 'X' characters, like "RXXLRXRXL", a move consists of ...
- laravel之数据库增删改查
- Container/Injection
1.容器的历史 容器概念始于 1979 年提出的 UNIX chroot,它是一个 UNIX 操作系统的系统调用,将一个进程及其子进程的根目录改变到文件系统中的一个新位置,让这些进程只能访问到这个新的 ...
- python语法_字符串
字符串 a = 'asdb' #双引号和打印号没区别, 操作 "abc"*2 打印两遍"abc" #字符串 加* 重复打印字符串 “abc”[2:1] #切片 ...
- JDBC的理解
import java.sql.*;//倒入java.sql包 public class JDBC { //封装没有返回值的jdbc函数(Update) --适用于增 删 改 public stati ...