AC自动机算法详解 (转载)
首先简要介绍一下AC自动机:Aho-Corasick automation,该算法在1975年产生于贝尔实验室,是著名的多模匹配算法之一。一个常见的例子就是给出n个单词,再给出一段包含m个字符的文章,让你找出有多少个单词在文章里出现过。要搞懂AC自动机,先得有模式树(字典树)Trie和KMP模式匹配算法的基础知识。KMP算法是单模式串的字符匹配算法,AC自动机是多模式串的字符匹配算法。
AC自动机和字典树的关系比较大,所以先来简单的了解下字典树Trie。
字典树又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
简而言之:字典树就是像平时使用的字典一样的,我们把所有的单词编排入一个字典里面,当我们查找单词的时候,我们首先看单词首字母,进入首字母所再的树枝,然后看第二个字母,再进入相应的树枝,假如该单词再字典树中存在,那么我们只用花费单词长度的时间查询到这个单词。
AC自动机关键点一:字典树的构建过程:
字典树的构建过程是这样的,当要插入许多单词的时候,我们要从前往后遍历整个字符串,当我们发现当前要插入的字符其节点再先前已经建成,我们直接去考虑下一个字符即可,当我们发现当前要插入的字符没有再其前一个字符所形成的树下没有自己的节点,我们就要创建一个新节点来表示这个字符,接下往下遍历其他的字符。然后重复上述操作。
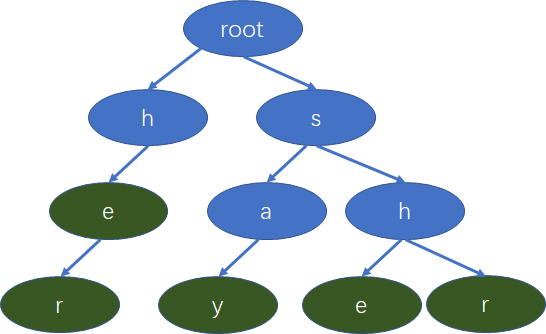
假设我们有下面的单词,she , he ,say, her, shr ,我们要构建一棵字典树
AC自动机关键点二:找Fail指针
在KMP算法中,当我们比较到一个字符发现失配的时候我们会通过next数组,找到下一个开始匹配的位置,然后进行字符串匹配,当然KMP算法试用与单模式匹配,所谓单模式匹配,就是给出一个模式串,给出一个文本串,然后看模式串在文本串中是否存在。
在AC自动机中,我们也有类似next数组的东西就是fail指针,当发现失配的字符失配的时候,跳转到fail指针指向的位置,然后再次进行匹配操作,AC自动机之所以能实现多模式匹配,就归功于Fail指针的建立。
当前节点t有fail指针,其fail指针所指向的节点和t所代表的字符是相同的。因为t匹配成功后,我们需要去匹配t->child,发现失配,那么就从t->fail这个节点开始再次去进行匹配。
Fail指针的求法:
Fail指针用BFS来求得,对于直接与根节点相连的节点来说,如果这些节点失配,他们的Fail指针直接指向root即可,其他节点其Fail指针求法如下:
假设当前节点为father,其孩子节点记为child。求child的Fail指针时,首先我们要找到其father的Fail指针所指向的节点,假如是t的话,我们就要看t的孩子中有没有和child节点所表示的字母相同的节点,如果有的话,这个节点就是child的fail指针,如果发现没有,则需要找father->fail->fail这个节点,然后重复上面过程,如果一直找都找不到,则child的Fail指针就要指向root。
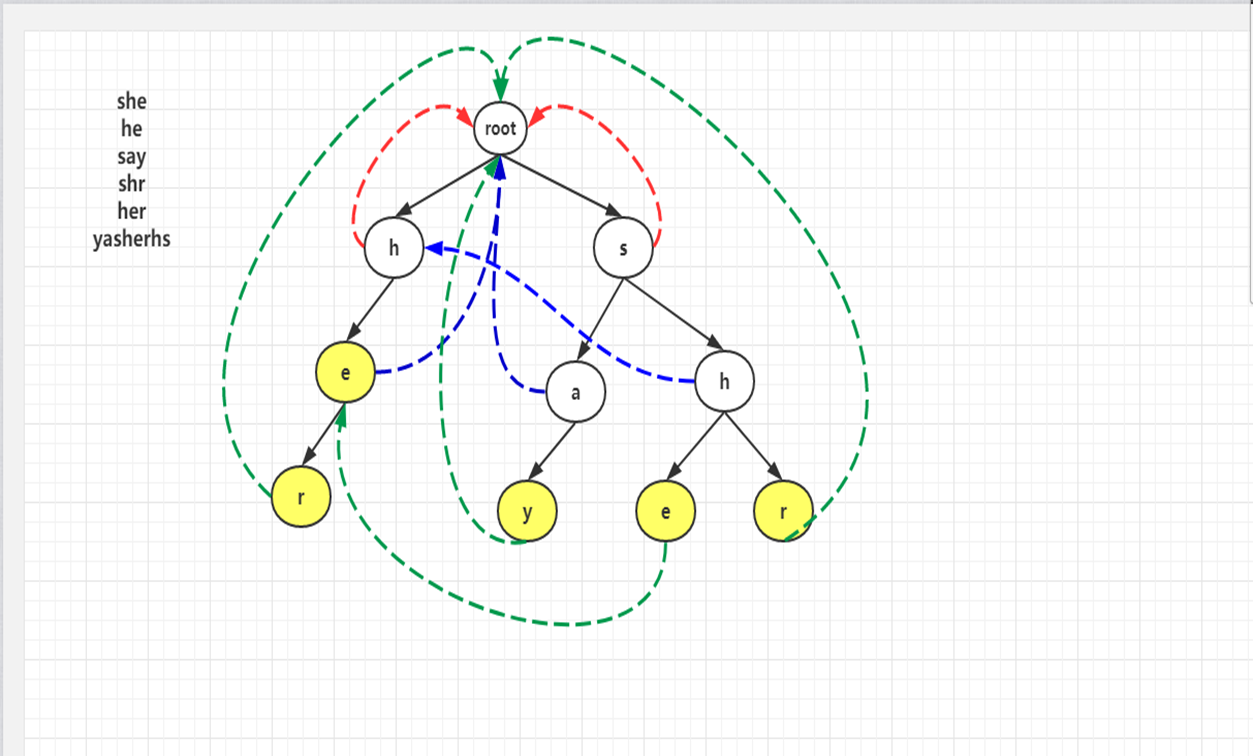
如图所示,首先root最初会进队,然后root,出队,我们把root的孩子的失败指针都指向root。因此图中h,s的失败指针都指向root,如红色线条所示,同时h,s进队。
接下来该h出队,我们就找h的孩子的fail指针,首先我们发现h这个节点其fail指针指向root,而root又没有字符为e的孩子,则e的fail指针是空的,如果为空,则也要指向root,如图中蓝色线所示。并且e进队,此时s要出队,我们再找s的孩子a,h的fail指针,
我们发现s的fail指针指向root,而root没有字符为a的孩子,故a的
fail指针指向root,a入队,然后找h的fail指针,同样的先看s的fail指针是root,发现root又字符为h的孩子,所以h的fail指针就指向了第二层的h节点。e,a , h 的fail指针的指向如图蓝色线所示。
此时队列中有e,a,h,e先出队,找e的孩子r的失败指针,我们先看e的失败指针,发现找到了root,root没有字符为r
的孩子,则r的失败指针指向了root,并且r进队,然后a出队,我们也是先看a的失败指针,发现是root,则y的fail指针就会指向root.并且y进队。然后h出队,考虑h的孩子e,则我们看h的失败指针,指向第二层的h节点,看这个节点发现有字符值为e的节点,最后一行的节点e的失败指针就指向第三层的e。最后找r的指针,同样看第二层的h节点,其孩子节点不含有字符r,则会继续往前找h的失败指针找到了根,根下面的孩子节点也不存在有字符r,则最后r就指向根节点,最后一行节点的fail指针如绿色虚线所示。
AC自动机关键点三:文本串的匹配
匹配过程分两种情况:
(1)当前字符匹配,表示从当前节点沿着树边有一条路径可以到达目标字符,如果当前匹配的字符是一个单词的结尾,我们可以沿着当前字符的fail指针,一直遍历到根,如果这些节点末尾有标记(此处标记代表,节点是一个单词末尾的标记),这些节点全都是可以匹配上的节点。我们统计完毕后,并将那些节点标记。此时只需沿该路径走向下一个节点继续匹配即可,目标字符串指针移向下个字符继续匹配;
(2)当前字符不匹配,则去当前节点失败指针所指向的字符继续匹配,匹配过程随着指针指向root结束。重复这2个过程中的任意一个,直到模式串走到结尾为止。
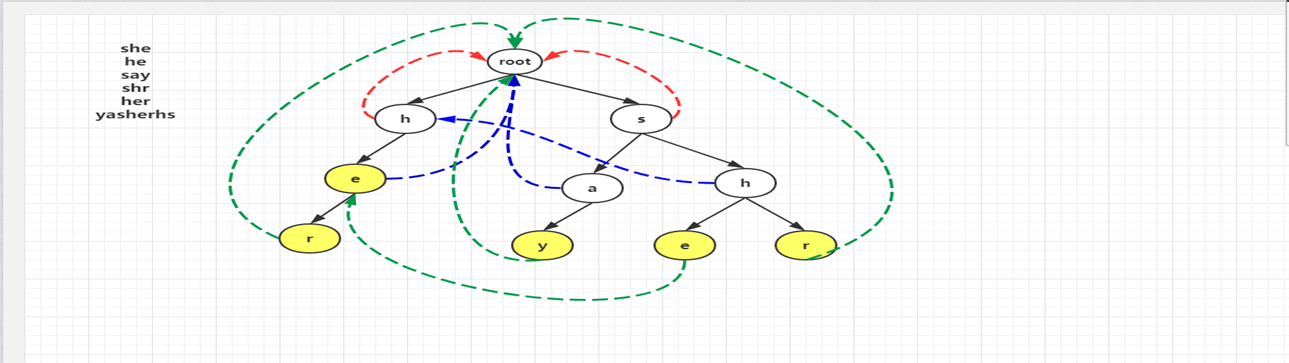
对照上图,看一下模式匹配这个详细的流程,其中模式串为yasherhs。对于i=0,1。Trie中没有对应的路径,故不做任何操作;i=2,3,4时,指针p走到左下节点e。因为节点e的count信息为1,所以cnt+1,并且讲节点e的count值设置为-1,表示改单词已经出现过了,防止重复计数,最后temp指向e节点的失败指针所指向的节点继续查找,以此类推,最后temp指向root,退出while循环,这个过程中count增加了2。表示找到了2个单词she和he。当i=5时,程序进入第5行,p指向其失败指针的节点,也就是右边那个e节点,随后在第6行指向r节点,r节点的count值为1,从而count+1,循环直到temp指向root为止。最后i=6,7时,找不到任何匹配,匹配过程结束。
AC自动机算法分为3步:构造一棵Trie树,构造失败指针和模式匹配过程。
如果你对KMP算法和了解的话,应该知道KMP算法中的next函数(shift函数或者fail函数)是干什么用的。KMP中我们用两个指针i和j分别表示,A[i-j+ 1..i]与B[1..j]完全相等。也就是说,i是不断增加的,随着i的增加j相应地变化,且j满足以A[i]结尾的长度为j的字符串正好匹配B串的前 j个字符,当A[i+1]≠B[j+1],KMP的策略是调整j的位置(减小j值)使得A[i-j+1..i]与B[1..j]保持匹配且新的B[j+1]恰好与A[i+1]匹配,而next函数恰恰记录了这个j应该调整到的位置。同样AC自动机的失败指针具有同样的功能,也就是说当我们的模式串在Tire上进行匹配时,如果与当前节点的关键字不能继续匹配的时候,就应该去当前节点的失败指针所指向的节点继续进行匹配。
看下面这个例子:给定5个单词:say she shr he her,然后给定一个字符串yasherhs。问一共有多少单词在这个字符串中出现过。我们先规定一下AC自动机所需要的一些数据结构,方便接下去的编程。
const int kind = 26;
struct node
{
node *fail; //失败指针
node *next[kind]; //Tire每个节点的个子节点(最多个字母)
int count; //是否为该单词的最后一个节点
node() //构造函数初始化
{
fail=NULL;
count=0;
memset(next,NULL,sizeof(next));
}
}*q[500001]; //队列,方便用于bfs构造失败指针
char keyword[51]; //输入的单词
char str[1000001]; //模式串
int head,tail; //队列的头尾指针
有了这些数据结构之后,就可以开始编程了:
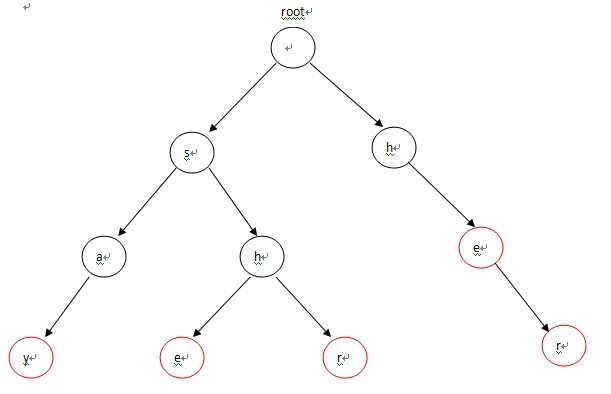
首先,将这5个单词构造成一棵Tire,如图-1所示。
void insert(char *str,node *root){
node *p=root;
int i=0,index;
while(str[i])
{
index=str[i]-'a';
if(p->next[index]==NULL) p->next[index]=new node();
p=p->next[index];
i++;
}
p->count++; //在单词的最后一个节点count+1,代表一个单词
}
在构造完这棵Tire之后,接下去的工作就是构造下失败指针。构造失败指针的过程概括起来就一句话:设这个节点上的字母为C,沿着他父亲的失败指针走,直到走到一个节点,他的儿子中也有字母为C的节点。然后把当前节点的失败指针指向那个字母也为C的儿子。如果一直走到了root都没找到,那就把失败指针指向root。具体操作起来只需要:先把root加入队列(root的失败指针指向自己或者NULL),这以后我们每处理一个点,就把它的所有儿子加入队列,队列为空。
void build_ac_automation(node *root){
int i;
root->fail=NULL;
q[head++]=root;
while(head!=tail)
{
node *temp=q[tail++];
node *p=NULL;
for(i=0; i<26; i++)
{
if(temp->next[i]!=NULL)
{
if(temp==root) temp->next[i]->fail=root;
else
{
p=temp->fail;
while(p!=NULL)
{
if(p->next[i]!=NULL)
{
temp->next[i]->fail=p->next[i];
break;
}
p=p->fail;
}
if(p==NULL) temp->next[i]->fail=root;
}
q[head++]=temp->next[i];
}
}
}
}
从代码观察下构造失败指针的流程:对照图-2来看,首先root的fail指针指向NULL,然后root入队,进入循环。第1次循环的时候,我们需要处理2个节点:root->next‘h’-‘a’ 和 root->next‘s’-‘a’。把这2个节点的失败指针指向root,并且先后进入队列,失败指针的指向对应图-2中的(1),(2)两条虚线;第2次进入循环后,从队列中先弹出h,接下来p指向h节点的fail指针指向的节点,也就是root;进入第13行的循环后,p=p->fail也就是p=NULL,这时退出循环,并把节点e的fail指针指向root,对应图-2中的(3),然后节点e进入队列;第3次循环时,弹出的第一个节点a的操作与上一步操作的节点e相同,把a的fail指针指向root,对应图-2中的(4),并入队;第4次进入循环时,弹出节点h(图中左边那个),这时操作略有不同。在程序运行到14行时,由于p->next[i]!=NULL(root有h这个儿子节点,图中右边那个),这样便把左边那个h节点的失败指针指向右边那个root的儿子节点h,对应图-2中的(5),然后h入队。以此类推:在循环结束后,所有的失败指针就是图-2中的这种形式。

最后,我们便可以在AC自动机上查找模式串中出现过哪些单词了。匹配过程分两种情况:(1)当前字符匹配,表示从当前节点沿着树边有一条路径可以到达目标字符,此时只需沿该路径走向下一个节点继续匹配即可,目标字符串指针移向下个字符继续匹配;(2)当前字符不匹配,则去当前节点失败指针所指向的字符继续匹配,匹配过程随着指针指向root结束。重复这2个过程中的任意一个,直到模式串走到结尾为止。
int query(node *root){
int i=0,cnt=0,index,len=strlen(str);
node *p=root;
while(str[i])
{
index=str[i]-'a';
while(p->next[index]==NULL && p!=root) p=p->fail;
p=p->next[index];
p=(p==NULL)?root:p;
node *temp=p;
while(temp!=root && temp->count!=-1)
{
cnt+=temp->count;
temp->count=-1;
temp=temp->fail;
}
i++;
}
return cnt;
}
对照图-2,看一下模式匹配这个详细的流程,其中模式串为yasherhs。对于i=0,1。Trie中没有对应的路径,故不做任何操作;i=2,3,4时,指针p走到左下节点e。因为节点e的count信息为1,所以cnt+1,并且讲节点e的count值设置为-1,表示改单词已经出现过了,防止重复计数,最后temp指向e节点的失败指针所指向的节点继续查找,以此类推,最后temp指向root,退出while循环,这个过程中count增加了2。表示找到了2个单词she和he。当i=5时,程序进入第5行,p指向其失败指针的节点,也就是右边那个e节点,随后在第6行指向r节点,r节点的count值为1,从而count+1,循环直到temp指向root为止。最后i=6,7时,找不到任何匹配,匹配过程结束。
AC自动机算法详解 (转载)的更多相关文章
- AC自动机算法详解
首先简要介绍一下AC自动机:Aho-Corasick automation,该算法在1975年产生于贝尔实验室,是著名的多模匹配算法之一.一个常见的例子就是给出n个单词,再给出一段包含m个字符的文章, ...
- AC自动机-算法详解
What's Aho-Corasick automaton? 一种多模式串匹配算法,该算法在1975年产生于贝尔实验室,是著名的多模式匹配算法之一. 简单的说,KMP用来在一篇文章中匹配一个模式串:但 ...
- HS光流算法详解<转载>
HS 光流法详解 前言 本文较为详细地介绍了一种经典的光流法 - HS 光流法. 光流法简介 当人的眼睛与被观察物体发生相对运动时,物体的影像在视网膜平面上形成一系列连续变化的图像,这一系列变化的图像 ...
- 【转】AC算法详解
原文转自:http://blog.csdn.net/joylnwang/article/details/6793192 AC算法是Alfred V.Aho(<编译原理>(龙书)的作者),和 ...
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- [转] KMP算法详解
转载自:http://www.matrix67.com/blog/archives/115 KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的K ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- KMP算法详解(转自中学生OI写的。。ORZ!)
KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的KMP不是拿来放电影的(虽然我很喜欢这个软件),而是一种算法.KMP算法是拿来处理字符串匹配的.换句 ...
- 第二十九节,目标检测算法之R-CNN算法详解
Girshick, Ross, et al. “Rich feature hierarchies for accurate object detection and semantic segmenta ...
随机推荐
- PHP跨域jsonp方式
<?php header('Access-Control-Allow-Origin:*');//注意!跨域要加这个头 上面那个没有 $arr = array ('a'=>1,'b'=> ...
- JetBrains 全套激活 Pycharm Clion 高校学生老师免费用
https://www.jetbrains.com/store/?fromMenu#edition=discounts https://www.jetbrains.com/zh/student/ 用高 ...
- jenkins乱码解决问题
1.jenkins控制台线上乱码解决 系统管理——系统设置,添加编码环境变量 zh.CH.UTF-8 2.java启动后,tomcat日志显示乱码,原因是环境变量没有带过去,因此shell脚本头部需要 ...
- CentOS7.5脱机安装SQL Server 2017(NEW)
发现搜到的都是在线下载安装的,都是只安装了mssql-server服务,没有mssql-server-agent服务.还以为linux下mssql没有agent服务呢.一番测试发现可以脱机安装,但是能 ...
- docker 小技巧 列出所有容器的IP地址
命令如下: [root@localhost ~]# docker inspect --format='{{.Name}} - {{range .NetworkSettings.Networks}}{{ ...
- springboot 学习进度
1 hello world --------------ok 主启动程序必须在层次结构的最上面. 2 配置 3.日志 4.Web开发 1)SpringBoot集成JSP的方法 配置applicatio ...
- CodeForces Round #552 Div.3
A. Restoring Three Numbers 代码: #include <bits/stdc++.h> using namespace std; ]; int a, b, c; i ...
- mysql varchar integer
MySQL 中将 varchar 字段转换成数字进行排序 - MySQL - 大象笔记 https://www.sunzhongwei.com/order-by-varchar-field-which ...
- SVD分解 解齐次线性方程组
SVD分解 只有非方阵才能进行奇异值分解 SVD分解:把矩阵分解为 特征向量矩阵+缩放矩阵+旋转矩阵 定义 设\(A∈R^{m×n}\),且$ rank(A) = r (r > 0) $,则矩阵 ...
- vue报错如log,如果其他项目运行没问题,很有可能是代码错误 加externals报错