Agens层次聚类
层次聚类是另一种主要的聚类方法,它具有一些十分必要的特性使得它成为广泛应用的聚类方法。它生成一系列嵌套的聚类树来完成聚类。单点聚类处在树的最底层,在树的顶层有一个根节点聚类。根节点聚类覆盖了全部的所有数据点。层次聚类分为两种:
- 合并(自下而上)聚类(agglomerative)
- 分裂(自上而下)聚类(divisive)
目前 使用较多的是合并聚类 ,本文着重讲解合并聚类的原理。
Agens层次聚类原理
合并聚类主要是将N个元素当成N个簇,每个簇与其 欧氏距离最短 的另一个簇合并成一个新的簇,直到达到需要的分簇数目K为止,示意图如下:

举个例子,作者将26个字母随机分配了坐标(x,y),如:
# {'K': {'y': 34, 'x': 81}, 'V': {'y': 68, 'x': 50}, 'G': {'y': 1, 'x': 10}, 'C': {'y': 2, 'x': 9}, 'T': {'y': 78, 'x': 40}, 'A': {'y': 20, 'x': 12}, 'B': {'y': 21, 'x': 39}, 'N': {'y': 37, 'x': 67}, 'S': {'y': 92, 'x': 56}, 'Q': {'y': 7, 'x': 62}, 'D': {'y': 18, 'x': 4}, 'E': {'y': 0, 'x': 38}, 'Z': {'y': 92, 'x': 46}, 'H': {'y': 30, 'x': 32}, 'I': {'y': 21, 'x': 35}, 'U': {'y': 71, 'x': 51}, 'L': {'y': 1, 'x': 96}, 'W': {'y': 99, 'x': 59}, 'F': {'y': 10, 'x': 14}, 'O': {'y': 16, 'x': 97}, 'J': {'y': 37, 'x': 76}, 'X': {'y': 86, 'x': 49}, 'Y': {'y': 67, 'x': 50}, 'P': {'y': 17, 'x': 76}, 'M': {'y': 32, 'x': 88}, 'R': {'y': 6, 'x': 70}}
点的位置如下:
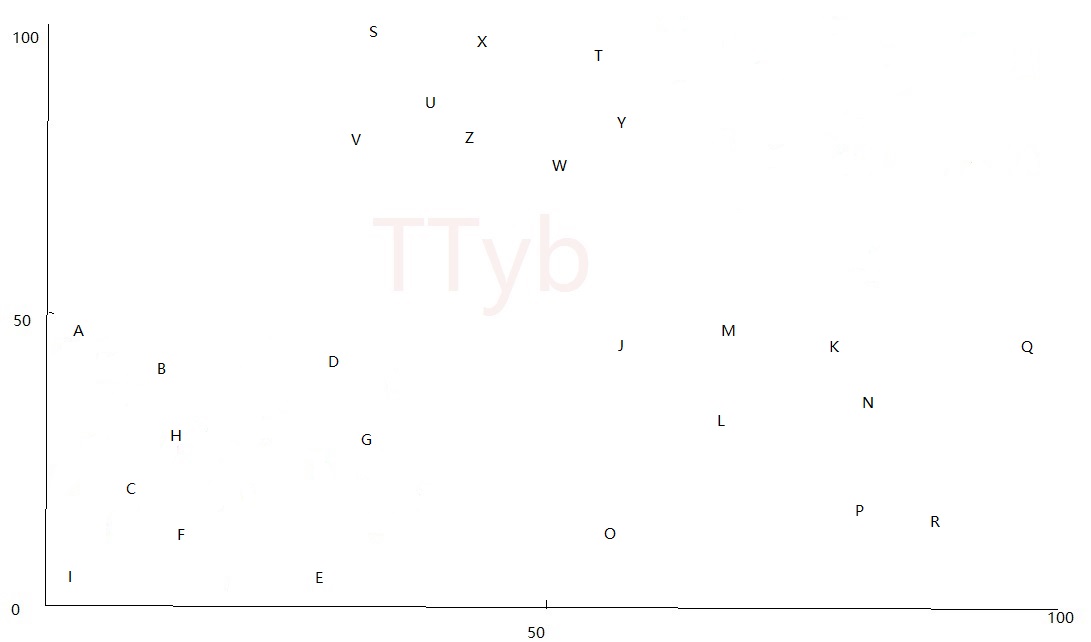
- 假设要分成1个簇,即
K=1,那么平面上的所有点都在一起,如下图红色点:
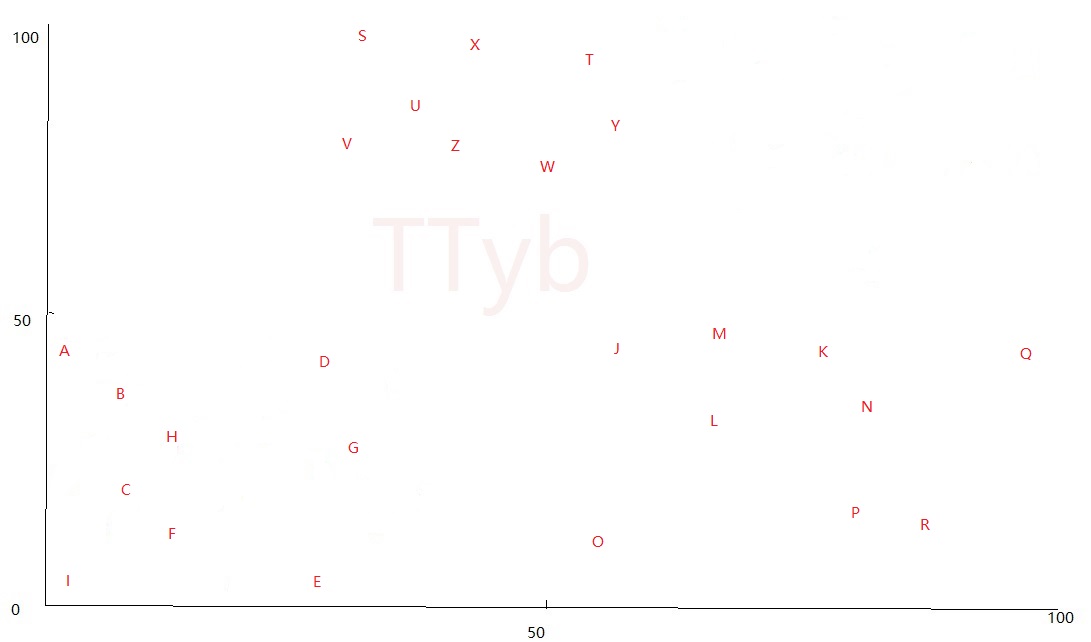
- 假设要分成2个簇,即
K=2,则根据欧式距离公式,首先将字母分成了红色的点和绿色的点,黑色的点为未分配:
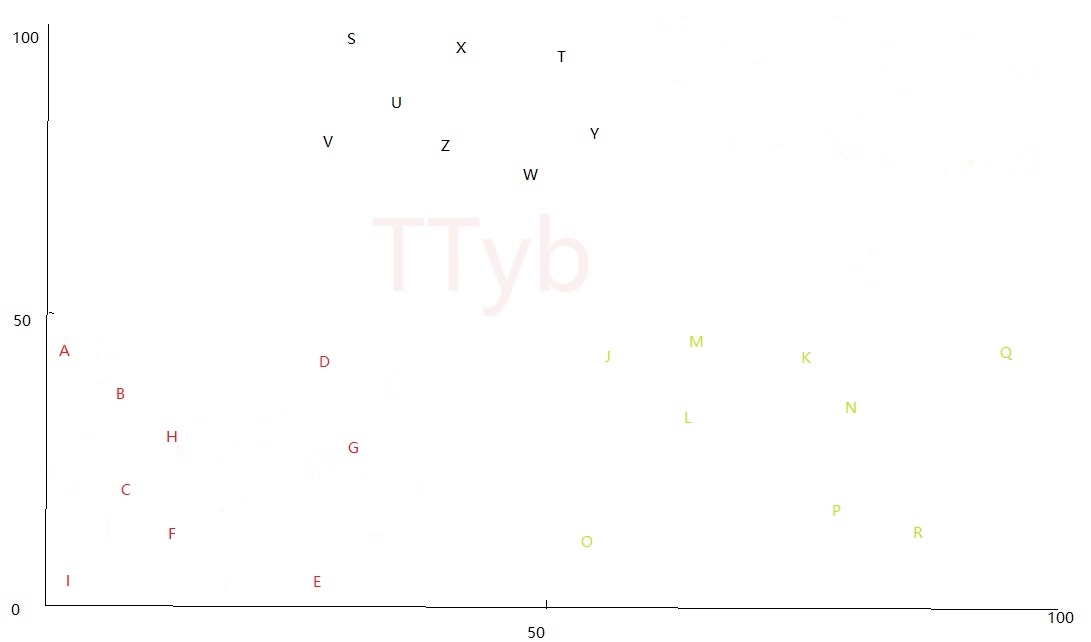
而黑色的点可能一部分与红色的点距离较近,所以一部分变成了红色,一部分变成了绿色:

- 假设要分成3个簇,即
K=3,如下图红色、绿色、紫色的点:
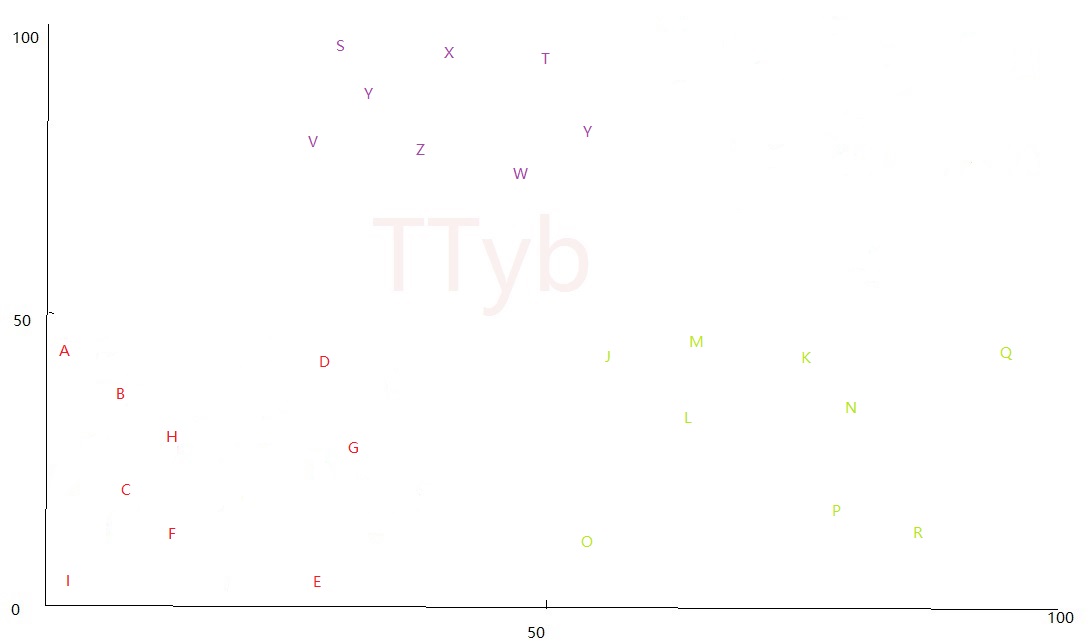
假设 K=3 ,合并的步骤为:
- 26个字母首先被分配成 26 个簇
- 两两欧氏距离最近的两个簇合并,此时簇变成了 13 个
- 再次两两欧氏距离最近的两个簇合并,此时一共有 12 个簇合并成了6个簇,还余下一个簇,因此此时剩下
6+1=7个簇- 一直重复上一步的操作,直到簇的数量为 3 的时候,就算是分簇完成
Agens层次聚类实现:
- 随机生成26个字母:
# 生成坐标字典
def buildclusters():
clusters = {}
keys = [chr(i) for i in range(ord('A'), ord('Z') + 1)]
# ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
# 生成第一个分簇坐标
for i in range(0, 9):
# A-I
temp = {}
x = random.randint(0, 40)
y = random.randint(0, 40)
temp["x"] = x
temp["y"] = y
clusters[keys[i]] = temp
# 生成第二个分簇坐标
for i in range(9, 18):
# J-R
temp = {}
x = random.randint(60, 100)
y = random.randint(0, 40)
temp["x"] = x
temp["y"] = y
clusters[keys[i]] = temp
# 生成第三个分簇坐标
for i in range(18, 26):
# S-Z
temp = {}
x = random.randint(40, 60)
y = random.randint(60, 100)
temp["x"] = x
temp["y"] = y
clusters[keys[i]] = temp
return clusters
得到的结果为:
{'K': {'y': 34, 'x': 81}, 'V': {'y': 68, 'x': 50}, 'G': {'y': 1, 'x': 10}, 'C': {'y': 2, 'x': 9}, 'T': {'y': 78, 'x': 40}, 'A': {'y': 20, 'x': 12}, 'B': {'y': 21, 'x': 39}, 'N': {'y': 37, 'x': 67}, 'S': {'y': 92, 'x': 56}, 'Q': {'y': 7, 'x': 62}, 'D': {'y': 18, 'x': 4}, 'E': {'y': 0, 'x': 38}, 'Z': {'y': 92, 'x': 46}, 'H': {'y': 30, 'x': 32}, 'I': {'y': 21, 'x': 35}, 'U': {'y': 71, 'x': 51}, 'L': {'y': 1, 'x': 96}, 'W': {'y': 99, 'x': 59}, 'F': {'y': 10, 'x': 14}, 'O': {'y': 16, 'x': 97}, 'J': {'y': 37, 'x': 76}, 'X': {'y': 86, 'x': 49}, 'Y': {'y': 67, 'x': 50}, 'P': {'y': 17, 'x': 76}, 'M': {'y': 32, 'x': 88}, 'R': {'y': 6, 'x': 70}}
- 欧氏距离公式:
# 两点间的距离公式/欧式距离
def distance(x1, x2, y1, y2):
distan = ((x1 - x2) ** 2 + (y1 - y2) ** 2) ** 0.5
return distan
- 第一次分簇:
# 计算各个分簇直到达到分簇的效果
def splitcluster(clusters):
dict = {}
newdict = {}
arr = []
i = 1
for key1 in clusters:
temp = {}
for key2 in clusters:
if key1 != key2:
if key1 in arr or key2 in arr:
pass
else:
name = str(key1 + "->" + key2)
temp[name] = distance(clusters[key1]["x"], clusters[key2]["x"], clusters[key1]["y"],
clusters[key2]["y"])
arr.append(key1)
arr.append(key2)
if temp:
# reverse=False值按照从小到大排序
temp = sorted(temp.items(), key=lambda d: d[1], reverse=False)
newdict[temp[0][0]] = temp[0][1]
newdict = sorted(newdict.items(), key=lambda d: d[1], reverse=False)
for item in newdict:
name = "cluster" + str(i)
i += 1
dict[name] = item[0]
return dict
成功的将其分成13个簇,得到的结果为:
{'cluster13': 'B->T', 'cluster11': 'U->M', 'cluster10': 'Z->H', 'cluster5': 'L->D', 'cluster1': 'F->E', 'cluster4': 'G->A', 'cluster12': 'I->S', 'cluster3': 'W->V', 'cluster8': 'C->R', 'cluster9': 'P->X', 'cluster2': 'K->N', 'cluster7': 'O->Q', 'cluster6': 'Y->J'}
- 迭代分簇,直到满足K为止:
# 判断分簇
def judgecluster(clusters, firstcluster, K):
dict = {}
i = 1
arr = []
for item in firstcluster:
temparr = firstcluster[item].split("->")
distan = {}
for judge in temparr:
if judge in arr:
pass
else:
for value in clusters:
if value in temparr:
pass
elif value in arr:
pass
else:
for key in temparr:
name = value + "->" + key
distan[name] = distance(clusters[key]["x"], clusters[value]["x"], clusters[key]["y"],
clusters[value]["y"])
if key in arr:
pass
else:
arr.append(key)
if distan:
distan = sorted(distan.items(), key=lambda d: d[1], reverse=False)
# print(distan)
element = distan[0][0].split("->")[0]
for ele in firstcluster:
elearr = firstcluster[ele].split("->")
if element in elearr:
values = firstcluster[item]
for va in elearr:
values = values + "->" + va
arr.append(va)
cluster = "cluster" + str(i)
i += 1
dict[cluster] = values
if len(arr) != 26:
# 生成26个字母
letters = [chr(i) for i in range(ord('A'), ord('Z') + 1)]
# 得到剩下没有被放到dict的字母
remain = []
for letter in letters:
if letter in arr:
pass
else:
remain.append(letter)
dis = {}
for letter in remain:
for item in dict:
elearr = dict[item].split("->")
for ele in elearr:
name = letter + "->" + ele
dis[name] = distance(clusters[letter]["x"], clusters[ele]["x"], clusters[letter]["y"],
clusters[ele]["y"])
if dis:
dis = sorted(dis.items(), key=lambda d: d[1], reverse=False)
element = dis[0][0].split("->")
for cluster in dict:
array = dict[cluster].split("->")
for item in element:
if item in array:
values = "->".join(remain)
dict[cluster] = dict[cluster] + "->" + values
if len(dict) == K:
print(dict)
# {'cluster1': 'M->X->P->Y->J->U->T->R->L->O', 'cluster3': 'V->B->W->N->E->A->I->G', 'cluster2': 'C->H->Q->F->D->S->Z->K'}
return dict
else:
judgecluster(clusters, dict, K)
本文选取的 K=3 ,最后得到的结果为:
{'cluster1': 'M->X->P->Y->J->U->T->R->L->O', 'cluster3': 'V->B->W->N->E->A->I->G', 'cluster2': 'C->H->Q->F->D->S->Z->K'}
由此可见,按照这个结果,作者手动画的图是错误的...
python代码在我的博客上面:
Agens层次聚类的更多相关文章
- 挑子学习笔记:BIRCH层次聚类
转载请标明出处:http://www.cnblogs.com/tiaozistudy/p/6129425.html 本文是“挑子”在学习BIRCH算法过程中的笔记摘录,文中不乏一些个人理解,不当之处望 ...
- 2.交通聚类 -层次聚类(agnes)Java实现
1.项目背景 在做交通路线分析的时候,客户需要找出车辆的行车规律,我们将车辆每天的行车路线当做一个数据样本,总共有365天或是更多,从这些数据中通过聚类来获得行车路线规律统计分析. 我首先想到是K-m ...
- 聚类算法:K均值、凝聚层次聚类和DBSCAN
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- Python爬虫技术(从网页获取图片)+HierarchicalClustering层次聚类算法,实现自动从网页获取图片然后根据图片色调自动分类—Jason niu
网上教程太啰嗦,本人最讨厌一大堆没用的废话,直接上,就是干! 网络爬虫?非监督学习? 只有两步,只有两个步骤? Are you kidding me? Are you ok? 来吧,follow me ...
- 机器学习(六)K-means聚类、密度聚类、层次聚类、谱聚类
本文主要简述聚类算法族.聚类算法与前面文章的算法不同,它们属于非监督学习. 1.K-means聚类 记k个簇中心,为\(\mu_{1}\),\(\mu_{2}\),...,\(\mu_{k}\),每个 ...
- 机器学习算法总结(五)——聚类算法(K-means,密度聚类,层次聚类)
本文介绍无监督学习算法,无监督学习是在样本的标签未知的情况下,根据样本的内在规律对样本进行分类,常见的无监督学习就是聚类算法. 在监督学习中我们常根据模型的误差来衡量模型的好坏,通过优化损失函数来改善 ...
- 【层次聚类】python scipy实现
层次聚类 原理 有一个讲得很清楚的博客:博客地址 主要用于:没有groundtruth,且不知道要分几类的情况 用scipy模块实现聚类 参考函数说明: pdist squareform linkag ...
- 常见聚类算法——K均值、凝聚层次聚类和DBSCAN比较
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- ML: 聚类算法R包-层次聚类
层次聚类 stats::hclust stats::dist R使用dist()函数来计算距离,Usage: dist(x, method = "euclidean", di ...
随机推荐
- js实现页面重新加载
https://blog.csdn.net/wangjian530/article/details/80596801
- Javascript获取value值的三种方法及注意点
JavaScript获取value值,主要有以下三种: 1.用document.getElementById(“id名”).value来获取(例1): 2.通过form表单中的id名或者name名来获 ...
- 工作流——activiti
1.导入依赖 <!-- activiti工作流 --> <dependency> <groupId>org.activiti</groupId> < ...
- SpringBoot使用prometheus监控
本文介绍SpringBoot如何使用Prometheus配合Grafana监控. 1.关于Prometheus Prometheus是一个根据应用的metrics来进行监控的开源工具.相信很多工程都在 ...
- JAVA基础复习与总结<四> 抽象类与接口
抽象类(Abstract Class) 是一种模版模式.抽象类为所有子类提供了一个通用模版,子类可以在这个模版基础上进行扩展.通过抽象类,可以避免子类设计的随意性.通过抽象类,我们就可以做到严格限制子 ...
- C# 串口操作系列(4) -- 协议篇,文本协议数据解析
C# 串口操作系列(4) -- 协议篇,文本协议数据解析 标签: c#uiobjectstringbyte 2010-06-09 01:50 19739人阅读 评论(26) 收藏 举报 分类: 通讯 ...
- 动态规划——Freedom Trail
题目:https://leetcode.com/problems/freedom-trail/ 额...不解释大意了,题目我也不想写过程了有点繁琐,直接给出代码: public int findRot ...
- lua 语言基础
1.数据类型: string(字符串) ·运算符“+.-.*./”等操作字符串,lua会尝试讲字符串转换为数字后操作: ·字符串连接用“..”运算符 ·用“#”来计算字符串的长度(放在字符串前面) · ...
- ef.core Mysql
Entity层 using System; using System.Collections.Generic; using System.ComponentModel.DataAnnotations; ...
- 常见的UI框架
移动端框架 1.Admui 管理系统快速开发框架--http://docs.admui.com/ 为什么选择Admui?代码开源--开放所有源码,不存在任何加密混淆代码,安全全程可控,开箱即用--包含 ...