mapreduce项目中加入combiner
combiner相当于是一个本地的reduce,它的存在是为了减少网络的负担,在本地先进行一次计算再叫计算结果提交给reduce进行二次处理。
现在的流程为:
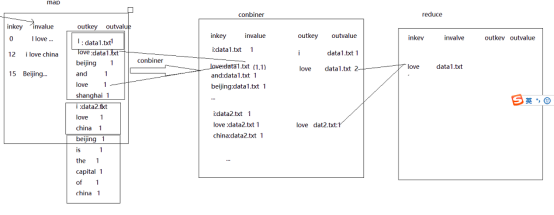
对于combiner我们有这些理解:


Mapper代码展示:
package com.nenu.mprd.test; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit; public class MyMap extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
//获取到单词
String line=value.toString();
String[] words=line.split(" ");
//获取到文件名
FileSplit filesplit = (FileSplit)context.getInputSplit();
String fileName = filesplit.getPath().getName().trim();//.substring(0,5). String outkey=null;
for (String word : words) {
//字母+:+文件名
outkey=word.trim()+":"+fileName;
System.out.println("map:"+outkey); context.write(new Text(outkey), new Text("1"));
}
}
}
Combiner代码展示:
package com.nenu.mprd.test; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class MyCombiner extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values,Context context) throws IOException, InterruptedException {
Text n = null;//输出key
int count=0;
Text m=null;//输出value
for(Text v :values){ //对同一个map输出的k,v对进行按k进行一次汇总。不同map的k,v汇总必须要用reduce方法
String[] words=key.toString().split(":");
n=new Text(words[0].trim());//字母--key
System.out.println("MyCombiner KEY:"+n); count+=Integer.parseInt(v.toString());
m=new Text("("+words[1].trim()+" "+count+")"); }
System.out.println("MyCombiner value:"+m);
context.write(n, m);
} }
Reduce代码展示:
package com.nenu.mprd.test; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class MyReduce extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values,
Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
System.out.println("reduce: key"+key);
String out="";
for (Text Text : values) {
//sum+=intWritable.get();
out+=Text.toString()+" ";
}
System.out.println("reduce value:"+out);
context.write(key, new Text(out));
}
}
Job代码展示:
package com.nenu.mprd.test; import java.net.URI; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class MyJob extends Configured implements Tool{ public static void main(String[] args) throws Exception {
MyJob myJob=new MyJob();
ToolRunner.run(myJob, null);
}
@Override
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf=new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.64.141:9000"); //添加自动删除hadoop下的文件
//如果导成架包则需要改变一些参数作为手动输入
FileSystem filesystem =FileSystem.get(new URI("hdfs://192.168.64.141:9000"), conf, "root");
Path deletePath=new Path("/hadoop/wordcount/city/out");
if(filesystem.exists(deletePath)){
filesystem.delete(deletePath,true);//str: b:
} Job job=Job.getInstance(conf);
job.setJarByClass(MyJob.class);
job.setMapperClass(MyMap.class); //设置combiner 如果combiner和reduce一样则可以不用设置
job.setCombinerClass(MyCombiner.class); job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path("/hadoop/wordcount/city"));
FileOutputFormat.setOutputPath(job, new Path("/hadoop/wordcount/city/out"));
job.waitForCompletion(true);
return 0;
} }
mapreduce项目中加入combiner的更多相关文章
- MapReduce项目中的一个JVM错误问题分析和解决
最近一周都在查项目的各种问题,由于对原有的一个MapReduce分析数据的项目进行重构,减少了运行时的使用资源,但是重构完成后,在Reduce端总是不定时地抛出JVM的相关错误,非常随机,没有发现有什 ...
- 项目中Map端内存占用的分析
最近在项目中开展重构活动,对Map端内存尽量要省一些,当前的系统中Map端内存最高占用大概3G左右(设置成2G时会导致Java Heap OOM).虽然个人觉得占用不算多,但是显然这样的结果想要试 ...
- 在eclipse中用gradle搭建MapReduce项目
我用的系统是ubuntu14.04新建一个Java Project. 这里用的是gradle打包,gradle默认找src/main/java下的类编译.src目录已经有了,手动在src下创建main ...
- ubuntu14.04 Hadoop单机开发环境搭建MapReduce项目
Hadoop官网:http://hadoop.apache.org/ 目前最新的版本是Hadoop 3.0.0-alpha1前提:java 1.6 版本以上 首先从官网下载压缩包(hadoop-3.0 ...
- MongoDB在实际项目中的使用
MongoDB简介 MongoDB是近些年来流行起来的NoSql的代表,和传统数据库最大的区别是支持文档型数据库. 当然,现在的一些数据库通过自定义复合类型,可变长数组等手段也可以模拟文档型数据库. ...
- SparkSQL项目中的应用
Spark是一个通用的大规模数据快速处理引擎.可以简单理解为Spark就是一个大数据分布式处理框架.基于内存计算的Spark的计算速度要比Hadoop的MapReduce快上100倍以上,基于磁盘的计 ...
- mapreduce任务中Shuffle和排序的过程
mapreduce任务中Shuffle和排序的过程 流程分析: Map端: 1.每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认为64M)为一个分片,当然我们也可以设置 ...
- hadoop-初学者写map-reduce程序中容易出现的问题 3
1.写hadoop的map-reduce程序之前所必须知道的基础知识: 1)hadoop map-reduce的自带的数据类型: Hadoop提供了如下内容的数据类型,这些数据类型都实现了Writab ...
- 通过Maven管理多个MapReduce项目
1. 配置Maven环境 首先检查Windows是否配置了maven,进入cmd命令行,输入mvn -version命令,如果出现下图所示的 情形则表示满意配置maven. 从浏览器进入maven官网 ...
随机推荐
- docker 删除镜像
有时候我们不需要某个镜像,需要对它进行删除.1.停止所有的container,这样才能够删除其中的images: docker stop $(docker ps -a -q) 如果想要删除所有cont ...
- Mac 下 Eclipse 添加 Dynamic Web Project 并配置 Tomcat
最近拿到了一个 Dynamic Web Project,我的 Mac 上的 Eclipse 之前没有过这类型的项目,所以导入之后无法正常运行.下面是我记录的如何配置 Eclipse 使之能够运行 Dy ...
- DirectX11 With Windows SDK--23 立方体映射:动态天空盒的实现
前言 上一章的静态天空盒已经可以满足绝大部分日常使用了.但对于自带反射/折射属性的物体来说,它需要依赖天空盒进行绘制,但静态天空盒并不会记录周边的物体,更不用说正在其周围运动的物体了.因此我们需要在运 ...
- 记一次线上Java程序导致服务器CPU占用率过高的问题排除过程
博文转至:http://www.jianshu.com/p/3667157d63bb,转本博文的目的就是需要的时候以防忘记 1.故障现象 客服同事反馈平台系统运行缓慢,网页卡顿严重,多次重启系统后问题 ...
- important的妙用解决firefox和ie的css兼容问题
设置css的min-height属性.min-height在Firefox里有效,但IE无法识别.下面有个不错的解决方案,大家可以参考下 对于某些内容可变的层(比如用户评论),我们希望它有个最小的高度 ...
- data_summarize.pl data目录文本时长汇总脚本
#!/usr/bin/env perl # Copyright 2018 Jarvan Wang if (@ARGV != 1) { #print STDERR "Usage: keywor ...
- C# 动态调用 webservice 的类
封装这个类是为之后使用 webservice 不用添加各种引用了. using System; using System.Collections.Generic; using System.Compo ...
- Git开发工作流
1.1 master分支 主分支,产品的功能全部实现后,最终在master分支对外发布. 1.2 develop分支 开发分支,基于master分支克隆,产品的编码工作在此分支进行. 1.3 rele ...
- js 个人笔记
/* * Created by lsw 2018-06 */ ; (function (window) { //js ready var ie = !!(window.attachEvent & ...
- windows下Qt5.1 for android开发环境配置
1.下载安装Qt 5.1.0 for Android (Windows 32-bit, 716 MB) http://qt-project.org/downloads 2.打开Qt Creator ...