hadoop tez 结合搭建以及测试异常解决
hadoop tez 搭建
1、下载tez,本人下载的是bin.0.92版本。
http://www.apache.org/dyn/closer.lua/tez/0.9.2/
hadoop dfs -mkdir -p /apps/tez
tar -zxvf apache-tez-0.9.2-bin.tar.gz
hadoop dfs -copyFromLocal tez.tar.gz /apps/tez
2、在hadoop/etc/hadoop下创建 tez-site.xml文件,内容如下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>tez.lib.uris</name>
<!-- hdfs tez 包目录 --> <value>${fs.defaultFS}/apps/tez/tez.tar.gz</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>false</value>
</property>
</configuration>
在 hadoo-env.sh 下面追加
# hadoop tez 配置文件位置
TEZ_CONF_DIR=/software/hadoop/etc/hadoop/tez-site.xml
# tez 路径
TEZ_JARS=/softeware/tez
export HADOOP_CLASSPATH=${HADOOP_CLASSPATH}:${TEZ_CONF_DIR}:${TEZ_JARS}/*:${TEZ_JARS}/lib/* GitHub安装配置说明地址:https://github.com/apache/incubator-tez/blob/branch-0.2.0/INSTALL.txt
官网参考:http://tez.apache.org/install.html
解压缩在tez 目录下面找到share 目录
3、将mapred-site.xml 的yarn 模式改成yarn-tez 模式
<property>
<name>mapreduce.framework.name</name>
<!-- <value>yarn</value> -->
<value>yarn-tez</value>
<final>true</final>
</property>
将修改完成的 tez-site.xml 和 mapred-site.xml 发送到其他节点 重新启动yarn就可以了
在tez 测试
hadoop dfs -put LINCENSE /data/input
hadoop jar tez-examples-0.9.0.jar orderedwordcount /data/tez_input /user/ceshi/tez_output

如图示则是成功 5、可能出现异常解决方式。如果出现上述问题,则可能是 tez container 内存多大导致
可实际情况修改 在tez-site.xml 下面写入
<property>
<name>tez.container.max.java.heap.fraction</name>
<value>0.13</value>
</property>
我的调整比例是 0.13, 自己可据实际情况去修改 不用重启yarn 直接进行测试
hadoop jar tez-examples-0.9.0.jar orderedwordcount /data/tez_input /user/ceshi/tez_output
如果出现如下问题:
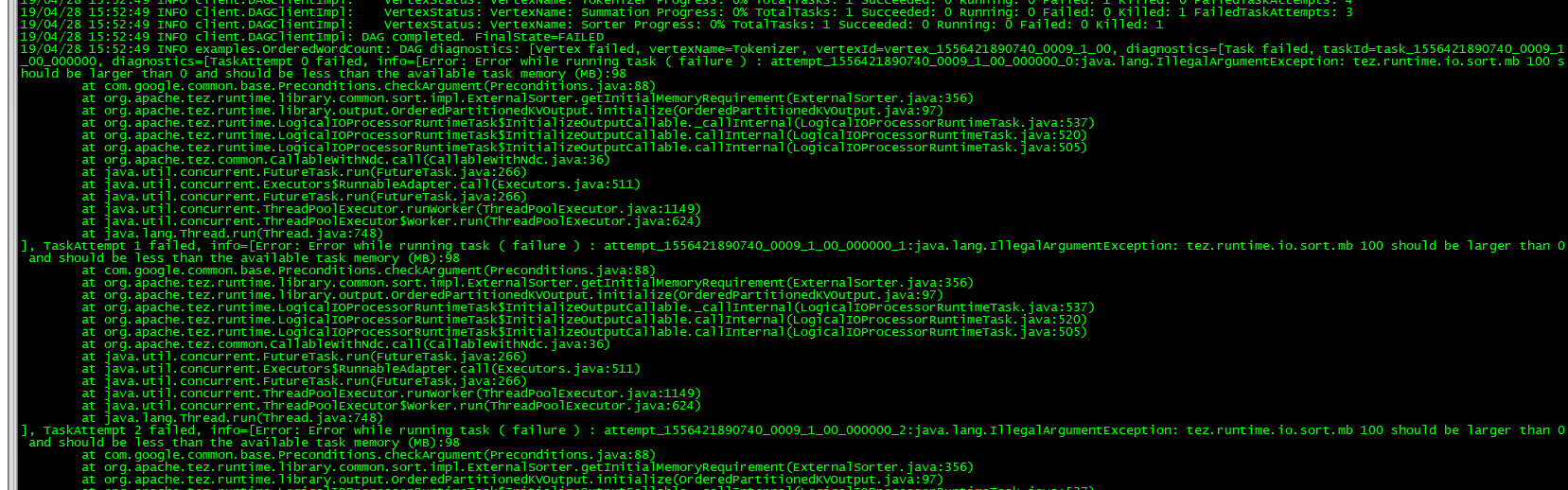
则根据提示在tez-site.xml 后面追加相应配置参数,根据实际情况去修改参数配置。不出现该问题不管就ok
<property>
<name>tez.runtime.io.sort.mb</name>
<value>85</value>
</property>
到此终于跑通了
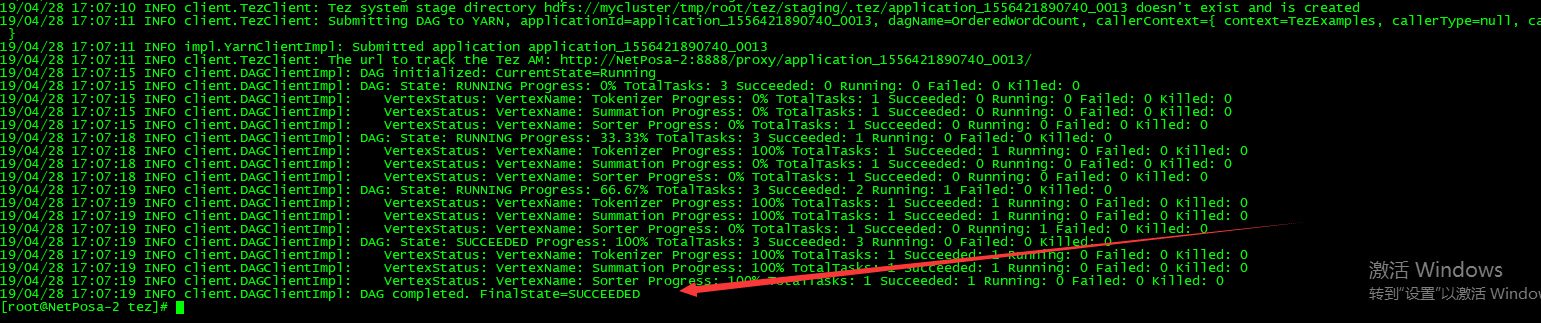
我的 tez-site.xml 完成配置,自己跟自己实际需求配置就可以了
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/apps/tez/tez.tar.gz</value>
</property> <property>
<name>tez.use.cluster.hadoop-libs</name>
<value>false</value>
</property> <property>
<name>tez.container.max.java.heap.fraction</name>
<value>0.13</value>
</property> <property>
<name>tez.runtime.io.sort.mb</name>
<value></value>
</property>
转发请标明来源连接
hadoop tez 结合搭建以及测试异常解决的更多相关文章
- hadoop 3.x 完全分布式集群搭建/异常处理/测试
共计三台虚拟机分别为hadoop002(master,存放namenode),hadoop003(workers,datanode以及resourcemanage),hadoop004(workers ...
- 大数据初级笔记二:Hadoop入门之Hadoop集群搭建
Hadoop集群搭建 把环境全部准备好,包括编程环境. JDK安装 版本要求: 强烈建议使用64位的JDK版本,这样的优势在于JVM的能够访问到的最大内存就不受限制,基于后期可能会学习到Spark技术 ...
- Hadoop集群搭建(完全分布式版本) VMWARE虚拟机
Hadoop集群搭建(完全分布式版本) VMWARE虚拟机 一.准备工作 三台虚拟机:master.node1.node2 时间同步 ntpdate ntp.aliyun.com 调整时区 cp /u ...
- hadoop过程中遇到的错误与解决方法
本文整理了在hadoop学习过程中遇到的各种问题. windows下开发环境搭建 大部分情况下,我们都是在windows下开发,hadoop则一般部署于linux服务器(无论是CDH还是原生hadoo ...
- hadoop分布式快速搭建
hadoop分布式快速搭建 1.配置主节点与从节点的ssh互信:[其中在主从节点主机的/etc/hosts文件中需绑定主机名ip间的映射关系; 如,192.168.1.113 node0 192.16 ...
- hadoop和spark搭建记录
因玩票需要,使用三台搭建spark(192.168.1.10,192.168.1.11,192.168.1.12),又因spark构建在hadoop之上,那么就需要先搭建hadoop.历经一个两个下午 ...
- 1.Hadoop集群搭建之Linux主机环境准备
Hadoop集群搭建之Linux主机环境 创建虚拟机包含1个主节点master,2个从节点slave1,slave2 虚拟机网络连接模式为host-only(非虚拟机环境可跳过) 集群规划如下表: 主 ...
- 大型网站技术架构(四)--核心架构要素 开启mac上印象笔记的代码块 大型网站技术架构(三)--架构模式 JDK8 stream toMap() java.lang.IllegalStateException: Duplicate key异常解决(key重复)
大型网站技术架构(四)--核心架构要素 作者:13GitHub:https://github.com/ZHENFENG13版权声明:本文为原创文章,未经允许不得转载.此篇已收录至<大型网站技 ...
- 【hadoop+spark】搭建spark过程
部分转载,已标红源地址,本博客为本菜搭建与爬坑记录,整理版请看: https://blog.csdn.net/the_fool_/article/details/78211166 记录: ====== ...
随机推荐
- Java(20)file i/o
1 I/0: input/output 1.1.java.io.File 1.2 表示:文件或者文件夹(目录) 1.3 File f = new File("文件路径"); 1. ...
- JavaScript之深入理解【函数】
一 参考文献 <JavaScript忍者秘籍> 二 函数特征总结 1. 函数是[第一型对象(first-class object)]:可以像这门语言的其它对象一样使用 函数可以共处,可 ...
- 移动端-处理后台传过来的html中图片的显示
function DealWithImg() { var width = 0; if (window.screen.width) { width = window.screen.width; } el ...
- pandas.read_csv() 报错 OSError: Initializing from file failed,报错原因分析和解决方法
今天调用pandas读取csv文件时,突然报错“ OSError: Initializing from file failed ”,我是有点奇怪的,以前用的好好的,read_csv(path)方法不是 ...
- 002 requests的使用方法以及xpath和beautifulsoup4提取数据
1.直接使用url,没用headers的请求 import requests url = 'http://www.baidu.com' # requests请求用get方法 response = re ...
- jQuery的一些基本的函数和用jQuery做一些动画操作
jQuery是对js的封装,因为js有一些不方便的地方.所以,jQuery才会去对js进行封装. jQuery对于标签元素的获取 $('div')或$('li') <!DOCTYPE html& ...
- javascript闭包学习
(function(){})()===>>>>函数会被立即执行function(){}是一个函数用括号包起来表示是函数表达式再加()表示函数自执行 如何理解闭包?1.定义和用 ...
- WPF 10天修炼 第十天- WPF数据绑定
WPF数据绑定 数据绑定到元素属性是将源对象指定为一个WPF元素,并且源属性是一个依赖属性,依赖属性内置了变更通知.当改变源对象依赖属性值之后,绑定目标可以立即得到更新,开发人员不需要手动编写响应事件 ...
- django中常用的数据查询方法
https://blog.csdn.net/chen1042246612/article/details/84071006
- java程序设计第二次作业