python 爬虫之beautifulsoup(bs4)使用 --待完善
#!/usr/bin/env python
# -*- coding:utf- -*-
from bs4 import BeautifulSoup
import requests url = 'http://www.jd.com/'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'
}
#User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36
web_date = requests.get(url,headers=headers)
soup = BeautifulSoup(web_date.text,'lxml')
print soup
headers表示头文件,伪装成浏览器浏览网页
wb_data网页数据requests.get请求访问(url网页京东,headers伪装的头文件)
soup解析后的数据BeautifulSoup解析数据(wb_data网页数据,lxml解析的格式按这个要求解析)
打印结果如下:
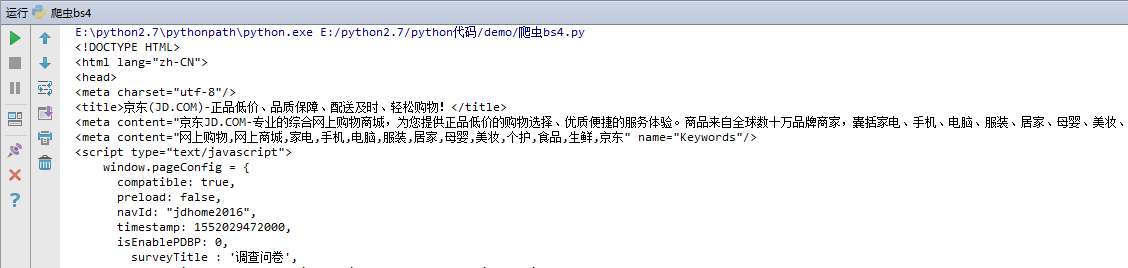
python 爬虫之beautifulsoup(bs4)使用 --待完善的更多相关文章
- 使用Python爬虫库BeautifulSoup遍历文档树并对标签进行操作详解(新手必学)
为大家介绍下Python爬虫库BeautifulSoup遍历文档树并对标签进行操作的详细方法与函数下面就是使用Python爬虫库BeautifulSoup对文档树进行遍历并对标签进行操作的实例,都是最 ...
- Python爬虫——用BeautifulSoup、python-docx爬取廖雪峰大大的教程为word文档
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 廖雪峰大大贡献的教程写的不错,写了个爬虫把教程保存为word文件,供大家方便下载学习:http://p ...
- 【Python爬虫】BeautifulSoup网页解析库
BeautifulSoup 网页解析库 阅读目录 初识Beautiful Soup Beautiful Soup库的4种解析器 Beautiful Soup类的基本元素 基本使用 标签选择器 节点操作 ...
- Python爬虫之BeautifulSoup的用法
之前看静觅博客,关于BeautifulSoup的用法不太熟练,所以趁机在网上搜索相关的视频,其中一个讲的还是挺清楚的:python爬虫小白入门之BeautifulSoup库,有空做了一下笔记: 一.爬 ...
- python爬虫入门--beautifulsoup
1,beautifulsoup的中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/ 2, from bs4 import Be ...
- python爬虫之Beautifulsoup学习笔记
相关内容: 什么是beautifulsoup bs4的使用 导入模块 选择使用解析器 使用标签名查找 使用find\find_all查找 使用select查找 首发时间:2018-03-02 00:1 ...
- Python爬虫系列-BeautifulSoup详解
安装 pip3 install beautifulsoup4 解析库 解析器 使用方法 优势 劣势 Python标准库 BeautifulSoup(markup,'html,parser') Pyth ...
- Python爬虫实践~BeautifulSoup+urllib+Flask实现静态网页的爬取
爬取的网站类型: 论坛类网站类型 涉及主要的第三方模块: BeautifulSoup:解析.遍历页面 urllib:处理URL请求 Flask:简易的WEB框架 介绍: 本次主要使用urllib获取网 ...
- Python爬虫之Beautifulsoup模块的使用
一 Beautifulsoup模块介绍 Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Be ...
随机推荐
- Redis数据库云端最佳技术实践
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由腾讯云数据库 TencentDB发表于云+社区专栏 邹鹏,腾讯高级工程师,腾讯云数据库Redis负责人,多年数据库.网络安全研发经验. ...
- Python函数二(函数名,闭包,迭代器)之杵臼之交
函数名的使用: 函数名可以作为值,赋值给变量. 函数名可以作为参数传参给函数. 函数名可以作为返回值. 函数名可以作为元素存储在容器里. 闭包:在嵌套函数内,使用外层局部变量(非全局变量)就是一个闭包 ...
- 浅谈TCP IP协议栈(一)入门知识【转】
说来惭愧,打算写关于网络方面的知识很久了,结果到今天才正式动笔,好了,废话不多说,写一些自己能看懂的入门知识,对自己来说是一种知识的总结,也希望能帮到一些想了解网络知识的童鞋. 万事开头难,然后中间难 ...
- 启动期间的内存管理之bootmem_init初始化内存管理–Linux内存管理(十二)
1. 启动过程中的内存初始化 首先我们来看看start_kernel是如何初始化系统的, start_kerne定义在init/main.c?v=4.7, line 479 其代码很复杂, 我们只截取 ...
- NSTimer 不工作 不调用方法
比如,定义一个NSTimer来隔一会调用某个方法,但这时你在拖动textVIew不放手,主线程就被占用了.timer的监听方法就不调用,直到你松手,这时把timer加到 runloop里,就相当于告诉 ...
- iOS 设置View阴影
iOS 设置View投影 需要设置 颜色 阴影半径 等元素 UIView *shadowView = [[UIView alloc] init]; shadowView.frame = CGRectM ...
- 关于tomcat 配置时一闪而过的问题
TOMCAT JAVA_HOME or JRE_HOME environment variable is not defined correctly 按照教程已经安装了JDK并设置好了JAVA_HOM ...
- Mysql数据中Packet for query is too large错误的解决方法
有时,程序在连接mysql执行操作数据库时,会出现如下类似错误信息: Packet for query is too large (4230 > 1024). You can change th ...
- 转://ORA-00603,ORA-27501,ORA-27300,ORA-27301,ORA-27302故障案例一则
背景介绍: 这是一套windows的rac系统.数据库后台日志报ORA-00474:SMON process terminated with error.接着报ORA-00603,ORA-27501, ...
- Oracle 查询表对应的索引
select col.table_owner "table_owner", idx.table_name "table_name", col.index_own ...