Kafka集群搭建 (2.11-0.9.0.1)
之前写过kafka_2.9.2-0.8.2.2版本的安装,kafka在新的0.9版本以上改动比较大,配置和api都有很大更新,并且broker对应的partition支持多线程生产和消费,所以性能比之前好得多,比如老版本的kafka单机每秒可以推送100条数据,但是新版的可以每秒推送达到上千条数据,多节点的性能提升非常大,下面是具体的安装过程
访问Apache Kafka官网下载安装包,地址:http://kafka.apache.org/
点击download按钮,进入版本选择,这里选择0.9.0.1版本的基于Scala 2.11的kafka_2.11-0.9.0.1.tgz安装包
注意不要安装0.9.0.0的版本,这个版本存在问题,并且已经在0.9.0.1中得到修复
安装kafka集群之前,确保zookeeper服务已经正常运行,这里3台zookeeper准备工作都已完成,三台主机分别为:linux1,linux2,linux3,接下来在linux1主节点上执行释放并做软链:
tar -xvzf kafka_2.-0.9.0.1.tgz
mv kafka_2.-0.9.0.1 /bigdata/
cd /bigdata/
ln -s kafka_2.-0.9.0.1 kafka
cd kafka
接下来执行 vim config/server.properties 编辑配置文件
修改broker.id=1,默认是0

这个值是集群中唯一的一个整数,每台机器各不相同,这里linux1设置为1其他机器后来再更改
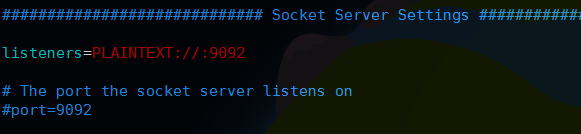
然后往下找到listeners这个配置项一般配置PLAINTEXT://ip:9092,如果配置0.0.0.0则绑定全部网卡,如果默认像下面这样,kafka会绑定默认的所有网卡ip,一般在机器中hosts,hostname都要正确配置,这里默认即可;然后下面的port默认9092不用配置,如果自定义端口号需要设置和listeners的一致,这个是kafka服务监听的端口号.
注意另外有一些advertised开头的参数,这些参数可以提供客户端访问的配置,比如advertised.listeners会覆盖listeners配置效果和listeners配置完全一样,但是客户端访问时会通过配置的参数访问zookeeper,另外还有advertised.host.name参数,这个也是指定客户端获取元数据的zookeeper主机,默认情况下如果这些参数不配置,那么客户端访问时hosts必须配置kafka集群的地址映射,否则直接会找不到对应的主机,但是advertised.host.name配置之后,客户端可以直接使用ip地址就可以生产或消费kafka,kafka会自动返回advertised.host.name的值供客户端使用,注意这里advertised.host.name一定要设置为ip地址,而不是主机名因为kafka会原样返回;这些就是advertised参数的区别和用途,生产环境中根据需要进行配置即可
然后配置kafka日志目录,注意目录要提前建好

然后下面num.partitions是默认单个broker上的partitions数量,默认是1个,如果想提高单机的并发性能,这里可以配置多个

然后是kafka日志的保留时间,单位小时,默认是168小时,也就是7天

注意之前有个log.cleaner.enable表示是否清理日志,这个配置在新版本已经废弃了,也就是日志必须是需要清理的,可以通过上面的保留时间参数或者通过字节大小来控制
然后设置协调的zookeeper集群列表,然后指定了Kafka在zookeeper上创建的znode为/kafka,

最后一项配置,默认即可

这个表示连接zookeeper服务器的超时时间,以上设置都完毕,保存配置并退出,然后将kafka目录发送至其他主机
scp -r kafka_2.-0.9.0.1 linux2:/bigdata/
scp -r kafka_2.-0.9.0.1 linux3:/bigdata/
这样就发送到了linux2和linux3这两台主机,然后依次修改linux2和linux3中config/server.properties配置文件中broker.id分别为2和3并保存
最后对三个节点都要创建日志目录: mkdir /bigdata/kafka_logs 并且根据需要创建软链接,完成之后kafka集群就安装完毕了,
然后启动所有主机的kafka服务,分别进入kafka目录,执行下面命令启动服务:
bin/kafka-server-start.sh -daemon config/server.properties
新版本的kafka无需使用nohup挂起,直接使用-daemon参数就可以运行在后台,启动后通过jps查看有Kafka进程就启动成功,对于创建topic,生产,消费操作和之前基本都是一样的,停止同样执行bin/kafka-server-stop.sh即可
Kafka集群搭建 (2.11-0.9.0.1)的更多相关文章
- kafka集群搭建和使用Java写kafka生产者消费者
1 kafka集群搭建 1.zookeeper集群 搭建在110, 111,112 2.kafka使用3个节点110, 111,112 修改配置文件config/server.properties ...
- Kafka【第一篇】Kafka集群搭建
Kafka初识 1.Kafka使用背景 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到这样的一些问题: 我们想分析下用户行为(pageviews),以便我们设计出更好的广告位 我想对用户 ...
- kafka学习(三)-kafka集群搭建
kafka集群搭建 下面简单的介绍一下kafka的集群搭建,单个kafka的安装更简单,下面以集群搭建为例子. 我们设置并部署有三个节点的 kafka 集合体,必须在每个节点上遵循下面的步骤来启动 k ...
- 【转】kafka集群搭建
转:http://www.cnblogs.com/luotianshuai/p/5206662.html Kafka初识 1.Kafka使用背景 在我们大量使用分布式数据库.分布式计算集群的时候,是否 ...
- zookeeper与Kafka集群搭建及python代码测试
Kafka初识 1.Kafka使用背景 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到这样的一些问题: 我们想分析下用户行为(pageviews),以便我们设计出更好的广告位 我想对用户 ...
- kafka集群搭建文档
kafka集群搭建文档 一. 下载解压 从官网下载Kafka,下载地址http://kafka.apache.org/downloads.html 注意这里最好下载scala2.10版本的kafka, ...
- Zookeeper + Kafka 集群搭建
第一步:准备 1. 操作系统 CentOS-7-x86_64-Everything-1511 2. 安装包 kafka_2.12-0.10.2.0.tgz zookeeper-3.4.9.tar.gz ...
- 大数据 --> Kafka集群搭建
Kafka集群搭建 下面是以三台机器搭建为例,(扩展到4台以上一样,修改下配置文件即可) 1.下载kafka http://apache.fayea.com/kafka/0.9.0.1/ ,拷贝到三台 ...
- 消息队列kafka集群搭建
linux系统kafka集群搭建(3个节点192.168.204.128.192.168.204.129.192.168.204.130) 本篇文章kafka集群采用外部zookeeper,没采 ...
- [Golang] kafka集群搭建和golang版生产者和消费者
一.kafka集群搭建 至于kafka是什么我都不多做介绍了,网上写的已经非常详尽了. 1. 下载zookeeper https://zookeeper.apache.org/releases.ht ...
随机推荐
- win10应用商店打不开,错误代码0x80131500
我也突然遇到这个问题,一开始找各种方法也解决不了.然后在外网找到方法. 很多人只是把代理开了,只要关了就可以了.这点不累述,都会提到. 我的win10应用商店有两个错误代码0x80131500和0x8 ...
- wireshark分析dhcp过程
---恢复内容开始--- DHCP DHCP(Dynamic Host Configuration Protocol)是一个用于主机动态获取IP地址的配置解 析,使用UDP报文传送,端口号为67何68 ...
- Python【第三篇】文件操作、字符编码
一.文件操作 文件操作分为三个步骤:文件打开.操作文件.关闭文件,但是,我们可以用with来管理文件操作,这样就不需要手动来关闭文件. 实现原理: import contextlib @context ...
- mysql数据库建表的基本规范
1.创建表的时候必须指定主键,并且主键建立后最好不要再有数据修改的需求 mysql从5.5版本开始默认使用innodb引擎,innodb表是聚簇索引表,也就是说数据通过主键聚集( 主键下存储该行的数据 ...
- 腾讯笔试---小Q的歌单
链接:https://www.nowcoder.com/questionTerminal/f3ab6fe72af34b71a2fd1d83304cbbb3 来源:牛客网 小Q有X首长度为A的不同的歌和 ...
- 第七篇--ubuntu18.04下面特殊符号
按住键盘win键,在搜索框输入“字符”,弹出来的工具点进去 需要什么符号就找什么符号,然后点击它复制就好.
- (二分查找 拓展) leetcode 34. Find First and Last Position of Element in Sorted Array && lintcode 61. Search for a Range
Given an array of integers nums sorted in ascending order, find the starting and ending position of ...
- javascript节点移除
var itemdel = document.getElementById("test"); itemdel.removeChild(lis[0]); 兼容性较好 itemdel. ...
- 共通脚本utils
/** * 模块名:共通脚本 * 程序名: 通用工具函数 **/ var utils = {}; /** * 格式化字符串 * 用法: .formatString("{0}-{1}" ...
- eclipse hadoop环境搭建 查看HDFS文件内容
1.下载插件 hadoop-eclipse-plugin-2.5.2.jar放入eclipse/plugin 2.准备hadoop-2.5.0-cdh5.3.6 使用WinSCP远程连接虚拟机,复制h ...