论文翻译:BinaryConnect: Training Deep Neural Networks with binary weights during propagations
目录
论文地址:https://arxiv.org/pdf/1511.00363.pdf
摘要
深度神经网络在大量任务中取得了最先进的成果。GPU因为其更快的计算速度,帮助深度网络实现了这些突破。未来,在训练和测试时更快的计算速度对于进一步发展,以及能够在低功耗设备上的消费级别的应用可能至关重要。因此,对深度学习专用硬件的研究和开发展开了新的热潮。二值权重,即仅限于两个可能值(例如-1或1)的权重,通过用简单累加代替许多乘法—累加操作,为专用深度学习硬件带来巨大便利。因为乘法器在神经网络的数字实现上是空间和功率消耗最高的组件。我们提出BinaryConnect的方法,在训练期间,前向传播和反向传播具有二值化权重的DNN,但是在计算梯度时仍然保持全精度的权重。与dropout方法一样,BinaryConnect也是一种正则化手段。我们通过BinaryConnect,在MNIST,CIFAR-10和SVHN获得近乎最佳的结果。
1.引言
深度神经网络(DNN)极大地推动了各种任务的发展,特别是在语音识别和计算机视觉领域。最近,深度学习在自然语言处理,尤其是机器翻译方面取得了重大进展。有趣的是,实现这一重大进展的关键因素之一是GPU的出现,速度提升了10到30倍,并且在分布式训练也取得了较大的进步。事实上,使用大量的数据来训练更大的模型,在过去几年中取得了突破性进展。如今,研究人员和开发人员设计新的深度学习算法和应用程序往往会发现深受计算能力的限制。与此同时,推动深度学习系统在低功耗设备上的应用(与GPU不同)极大地增加了对深度网络专用硬件研发的兴趣。
在深度神经网络的训练和应用期间执行的大多数计算都是关于通过实数激活值(在识别或反向传播算法的前向传播阶段)乘以实值权重或梯度(反向传播算法中反向传播阶段)。本文提出了一种称为BinaryConnect的方法,通过约束在这些前向和后向传播中使用的权重为二进制来消除对这些乘法的需要,即仅约束为两个值(不一定是0和1)。从而将这些乘法运算变为加减运算。这样即压缩了网络模型大小,有加快速度。我们表明使用BinaryConnect在控制变量MNIST,CIFAR-10和SVHN时可以实现最先进的结果。
使这个可行的原因有两个:
1)需要足够的精度来累积和平均大量的随机数梯度,但权重的噪音(我们可以将离散化视为少数值作为一种噪声形式,特别是如果我们使这种离散化随机)非常兼容随机梯度下降(SGD),SGD是深度主要优化算法。SGD通过生成小的噪声来尝试探索参数空间,通过每个权重累积的随机梯度贡献来平均噪声。因此,为这些累加器保持足够的精度非常重要,乍一看,这表明绝对需要高精度。 [14]和[15]表明可以使用随机或随机舍入来提供无偏离的离散化。[14]已经表明,SGD需要具有至少6到8位精度的权重,[16]成功用12位动态定点计算训练DNN。此外,大脑突触的估计精确度在6到12位之间变化[17]。
2)噪声权重实际上提供了一种正则化形式,可以帮助泛化能力更好,如先前所示的变分权重噪声[18],Dropout [19,20]和DropConnect [21],这增加了激活或权重的噪声。例如,最接近BinaryConnect的DropConnect [21]是非常有效的正则化器,它在传播过程中随机地用0替换一半的权重。以前的工作表明,只有权重的预期值需要高精度,而噪声实际上是有益的。
本文主要贡献如下:
1.我们引入了BinaryConnect,它是一种在正向和反向传播期间用二值化权重训练DNN的方法(第2节)。
2.我们证明了BinaryConnect是一个正则化器,我们在控制变量MNIST,CIFAR-10和SVHN(第3节)上获得近似最先进的结果。
3.我们开源了BinaryConnect的代码。
2.BinaryConnect
在本节中,我们给出BinaryConnect的更详细的视图,考虑选择哪两个值,如何离散化,如何训练以及如何执行inference(用训练好的模型去做预测)。
2.1 +1 or -1
应用DNN主要包括卷积和矩阵乘法。 因此,DL的关键算术运算是乘加运算。 人工神经元基本上是计算其输入的加权和的乘加器。
BinaryConnect在传播过程中将权重约束为+1或-1。 结果,许多乘加操作被简单的加法(和减法)代替。 这是一个巨大的增益,因为固定点加法器在面积和能量方面比定点乘加器要便宜得多[22]。
2.2确定性与随机性二值化
二值化操作将实值权重转换为两个可能的值。 一个非常简单的二值化操作将基于符号函数:
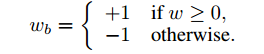
其中wb是二值化权重,w是实值权重。 虽然这是一种确定性操作,但是对隐藏单元的许多输入权重进行平均化可以补偿丢失的信息。 一种允许更精细和更正确的平均过程的替代方案是随机二值化:
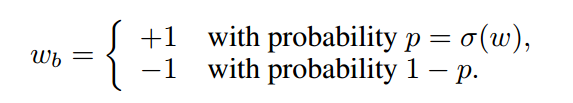
其中σ 是 ’‘hard sigmoid’‘ 函数
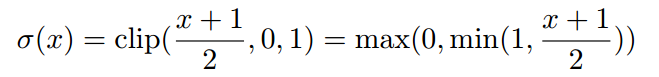
我们使用这样一个‘’hard sigmoid‘’而不是原来版本,因为它的计算成本要低得多(在软件和专用硬件执行中都是如此)并且在我们的实验中取得了很好的效果。 它类似于[23]引入的“hard tanh”非线性。 它也是分段的线性并且对应于rectifier(Relu?)的有界形式[24]。
2.3 Propagations vs updates
让我们考虑使用SGD进行反向传播更新的不同步骤以及它在每个步骤中对权重进行离散化是有意义。
1.给定DNN输入,逐层计算网络单元激活值,通向顶层给其输入,这是DNN的输出。 该步骤称为前向传播。
2.给定DNN目标,计算训练目标的梯度 w.r.t. 每一层的激活值,从顶层开始,逐层向下,直到第一个隐藏
层。 该步骤被称为后向传播或反向传播的反向阶段。
3.计算梯度w.r.t. 和每层的参数,然后使用他们的计算梯度和以前的值来更新参数。 该步骤称为参数更新。
算法一: 用SGD训练BinaryConnect网络
C是minibatch的loss函数,函数binarize(w)和clip(w)详细说明如何二值化和剪辑权重。 L是层数。

如在算法1中说明,理解BinaryConnect的一个关键点是我们只在前向和后向传播(步骤1和2)期间对权重进行二值化,而不是在参数更新(步骤3)期间进行二值化。SGD需要在更新期间保持良好的精确权重才能有作用。 这些参数变化很小由于梯度下降获得的功效,即SGD在最大改进的方向上执行大量几乎无穷小的变化来训练目标(加上噪音)。 描述这一切的一种方法是假设在训练结束时最重要的是权重w *的符号,但为了弄清楚,我们执行
对连续值数量w进行了很多微小的改变,并且只在最后考虑它的符号:
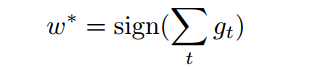
其中gt 是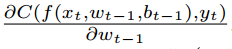 的噪声estimator, 其中C(f(xt; wt-1; bt-1); yt) 是样本(xt,yt)(input,target)的目标函数(loss),其中wt-1是之前的权值,w*是其最终离散化的权重值。
的噪声estimator, 其中C(f(xt; wt-1; bt-1); yt) 是样本(xt,yt)(input,target)的目标函数(loss),其中wt-1是之前的权值,w*是其最终离散化的权重值。
设想这种离散化的另一种方式是作为一种崩坏形式,因此作为一种正规化器,我们的实证结果证实了这一假设。此外,我们可以做出离散化错误在不同的权重上大致相互抵消,同时通过适当的离散化保持很高的精度。我们提出了一种保留随机离散化的形式来保持离散权重的预期值。
因此,在训练时,在一个minibatch中,BinaryConnect为每个权重随机选择的两个值中的一个,用于backprop的前向和后向传播阶段。但是,SGD需要存储参数的实值变量累积来更新参数。
理解BinaryConnect的一个有趣的类比是DropConnect算法[21]。类似BinaryConnect,DropConnect仅在传播期间向权重注入噪声。而DropConnect的噪声增加了伯努利噪声,BinaryConnect的噪声是二进制采样过程。在这两种情况下,损坏的值都具有纯正的原始值作为预期值。
2.4 Clipping
当权值波动幅度超出二进制值±1时,由于二值化操作不受实际权重w的变化的影响,并且由于通常的做法是约束权重(通常是权重向量)以使它们正规化,我们在权重更新后的间隔选择剪切实值权重在[-1,1],根据算法1所示。在没有二值化权重产生的任何影响下,实值权重会变得非常大。
2.5 A few more tricks

表1:根据优化方法在CIFAR-10上训练的(小)CNN的测试错误率以及是否使用[25]中的权重初始化系数来缩放学习速率。
我们在所有实验中使用批量标准化(BN)[26],不仅因为它通过减少内部协变量转移加速l了训练,也因为它减少了权重缩放的整体影响。 此外,我们在所有CNN实验中使用ADAM学习规则[27]。最后但并非最不重要的是,当用ADAM优化时,我们分别使用权重初始化系数来衡量权重学习率[25],以及在用SGD或Nesterov动量优化时,用这些系数的平方进行缩放权值学习速率[28]。 表1说明了这些技巧有效性。
2.6 Test-Time Inference
到目前为止,我们已经介绍了通过实时权重二值化训练DNN的不同方法。什么是使用这种训练有素的网络的合理方式,是在新样本执行测试时间推断? 我们考虑了三种合理的选择:
1.使用得到的二进制权重wb(使其有意义的是确定性形式的BinaryConnect)。
2.使用实值权重w,即二值化仅有助于实现更快的训练,但没有加快的测试时间性能。
3.在随机情况下,可以根据等式2通过对不同的网络的权值采样wb。然后可以通过获得这些网络的整体输出平均各个网络的输出。
我们使用第一种方法即确定型形式的BinaryConnect。 至于随机形式在BinaryConnect中,我们专注于训练优势,并在实验中使用第二种方法,即使用实值权重的测试时间推断。 这遵循Dropout的做法方法,在测试时,“噪音”被移除。
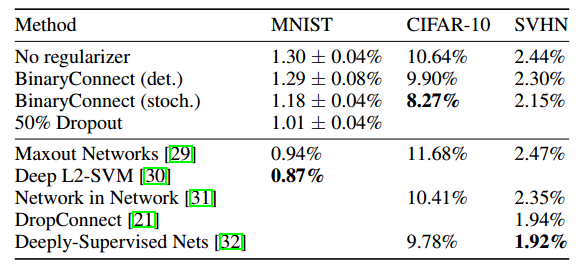
表2:在不同方法下测试在MNIST(无卷积且无无监督预训练)、CIFAR-10(无数据增强)和SVHN上训练的DNN的错误率。 我们看到虽然在传播过程中每个权重只使用一位比特置,但性能并不差比普通(无正规化)DNN,它实际上更好,尤其是随机型版本,表明BinaryConnect充当正则化器。

图1:根据正则化器在MNIST上训练的MLP第一层的特征。 从从左到右:没有正则化器,deterministic BinaryConnect ,stochastic BinaryConnect、Dropout。
3 Benchmark results
在本节中,我们展示了BinaryConnect作为正则化器,在控制变量MNIST,CIFAR-10和SVHN下,我们用BinaryConnect获得了近乎最优秀的结果。
3.1 Permutation-invariant MNIST
MNIST是一个基准图像分类数据集[33]。 它包含60000和60000的训练集测试集10000个28×28灰度图像,表示从0到9的数字。控制变量意味着模型必须不知道数据的图像(2-D)结构(换句话说,CNN被禁止)。 此外,我们不使用任何数据增强,预处理或无监督预训练。 我们在MNIST上训练的MLP包含3个1024 Rectifier的隐藏层线性整流单位(ReLU)[34,24,3]和L2-SVM输出层(已显示L2-SVM执行在几个分类基准[30,32]上比Softmax更好)。 用没有动量的SGD来最小话square hinge loss。 我们使用指数衰减的学习率。 我们Batch使用大小为200的小批量进行标准化以加速培训。
通常,我们使用训练集的最后 10000个样本作为早期停止和模型选择的验证集。 我们在1000个epochs后记录与最佳验证错误率相关的测试错误率(我们没有重新训练验证集)。 我们用不同的初始化重复每个实验6次。该结果见表2. 他们表明BinaryConnect的随机版本可以考虑作为一个正则化器,虽然这种情况下Dropout略弱一点。
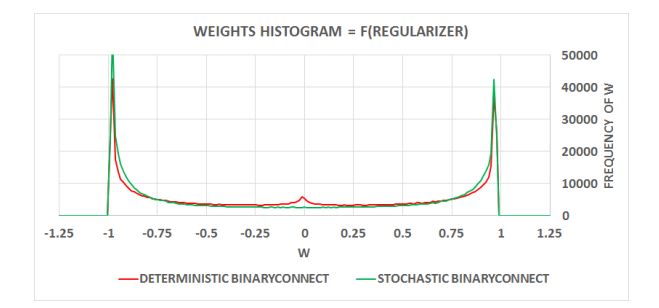
图2:依据不同正则化器在MNIST训练的MLP第一层的权重直方图。 在这两种情况下,权重似乎试图成为确定性的减少训练错误率。 似乎确定性BinaryConnect的一些权重在大约0附近被卡住了,在-1和1之间犹豫不决。
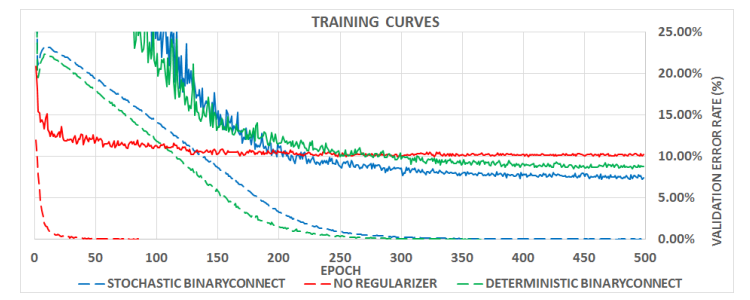
图3:CNIF在CIFAR-10上的训练曲线取决于正则化器。 虚线代表训练成本(方铰链损失)和连续线相应的有效值
误差率。 两种版本的BinaryConnect都显着增加了培训成本,减慢了速度培训并降低验证错误率,这是我们对Dropout的期望方案。
3.2 CIFAR-10
CIFAR-10是基准图像分类数据集。 它包含50000的训练集和一组10000×32×32测试集,这些彩色图像分别代表飞机,汽车,鸟类,猫,鹿,狗,青蛙,马,船和卡车。 我们使用全局对比度归一化和ZCA白化预处理数据。 我们不使用任何数据增强(对这个数据集[35]来说这实际上可以改变游戏规则)。 CNN的架构是:

其中C3是3×3 包含ReLU激活函数的卷积层,MP 2是2×2最大池化层,FC是完全连接层,SVM和L2-SVM是输出层。 这种架构受到了VGG的极大启发。 使用ADAM最小化square hinge loss 。 我们使用指数衰减的学习率。 我们使用批量标准化和大小为50的小批量来加速培训。我们使用训练集的最后5000个样本作为验证集。 我们在500个训练epochs之后记录与最佳验证错误率相关的测试错误率(我们不在验证集上重新训练)。 结果见表2和图3。
3.3 SVHN
SVHN是基准图像分类数据集。 它包含一个604K的训练集和一个26K 32×32彩色图像的测试集,表示从0到9的数字。我们遵循我们用于CIFAR-10的相同程序,除了一些值得注意的例外:我们使用了一半数量的隐藏神经元,我们训练200个epochs而不是500个(因为SVHN是一个非常大的数据集)。 结果是
表2。
4 Related works
利用二值化权重训练DNN已成为最近的主要关注工作[37,38,39,40]。 尽管我们有着共同的目标,但我们的方法却截然不同。 [37,38]不使用反向传(BP)训练他们的DNN,而是使用称为期望反向传播(EBP)的变体。 EBP基于期望传播(EP)[41],它是用于在概率图形模型中进行推理的变分贝叶斯方法。 让我们将他们的方法与我们的方法进行比较:
• 它优化后验分布的权重(不是二值化)。 在这方面,我们的方法非常相似,因为我们保留了权重的实值版本。
• 它将神经元输出和权重二值化,这比仅仅对权重进行二值化更加硬件友好。
• 它在全连接的网络(在MNIST上)产生了良好的分类精度,但在ConvNets却没有相应结果(尚未做实验)。
[39,40] 在前向和后向传播期间具有三重权重的重新训练神经网络,即:
• 他们训练高精度的神经网络,
• 训练后,他们将权重三角化为三个可能的值-H,0和+ H,并调整H以最小化输出误差,
• 最终,他们在传播过程中使用三元权重进行重新训练,并在更新期间使用高精度权重进行重新训练。
相比之下,我们在传播期间一直用二进制权重训练,即我们的训练程序可以用有效的专用硬件实现,避免向前和向后传播乘法,总量相当于2/3的乘法运算量(参见算法1)。
5. Conclusion and future works
我们在前向和后向传播期间为权重引入了一种新奇的二值化方法,称为BinaryConnect。我们已经证明,可以在控制变量MNIST,CIFAR-10和SVHN数据集上使用BinaryConnect训练DNN,可以获得近乎最先进的结果。这种方法对深度网络的专用硬件实现的影响通过消除大约2/3的乘法的需要,可能是主要的,因此可能在训练时加速3倍。使用确定性版本的BinaryConnect,测试时时间的影响可能更为重要,完全消除乘法并减少至少16(从16位单浮点精度到单位精度)的因子深度网络的内存需求,这会对在内存的计算上带宽和可运行模型的大小产生影响。未来的工作应该将这些结果扩展到其他模型和数据集,并通过从权重更新计算中消除它们的需要,探索在训练期间完全消除乘法。
参考资料
https://blog.csdn.net/xiaofei0801/article/details/72844673
本人根据其他博主的翻译和谷歌翻译组织整理语句,英语水平有限,翻译错误望指正
论文翻译:BinaryConnect: Training Deep Neural Networks with binary weights during propagations的更多相关文章
- Training Deep Neural Networks
http://handong1587.github.io/deep_learning/2015/10/09/training-dnn.html //转载于 Training Deep Neural ...
- Training (deep) Neural Networks Part: 1
Training (deep) Neural Networks Part: 1 Nowadays training deep learning models have become extremely ...
- CVPR 2018paper: DeepDefense: Training Deep Neural Networks with Improved Robustness第一讲
前言:好久不见了,最近一直瞎忙活,博客好久都没有更新了,表示道歉.希望大家在新的一年中工作顺利,学业进步,共勉! 今天我们介绍深度神经网络的缺点:无论模型有多深,无论是卷积还是RNN,都有的问题:以图 ...
- 论文翻译:BinaryNet: Training Deep Neural Networks with Weights and Activations Constrained to +1 or −1
目录 摘要 引言 1.BinaryNet 符号函数 梯度计算和累积 通过离散化传播梯度 一些有用的成分 算法1 使用BinaryNet训练DNN 算法2 批量标准化转换(Ioffe和Szegedy,2 ...
- 为什么深度神经网络难以训练Why are deep neural networks hard to train?
Imagine you're an engineer who has been asked to design a computer from scratch. One day you're work ...
- This instability is a fundamental problem for gradient-based learning in deep neural networks. vanishing exploding gradient problem
The unstable gradient problem: The fundamental problem here isn't so much the vanishing gradient pro ...
- [C4] Andrew Ng - Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization
About this Course This course will teach you the "magic" of getting deep learning to work ...
- Paper Reading:Deep Neural Networks for YouTube Recommendations
论文:Deep Neural Networks for YouTube Recommendations 发表时间:2016 发表作者:(Google)Paul Covington, Jay Adams ...
- 论文翻译:2018_Source localization using deep neural networks in a shallow water environment
论文地址:https://asa.scitation.org/doi/abs/10.1121/1.5036725 深度神经网络在浅水环境中的源定位 摘要: 深度神经网络(DNNs)在表征复杂的非线性关 ...
随机推荐
- 在JavaScript中使用三目运算符时进行多个操作
今天使用三目运算符时,刚好需要在false时进行两个操作,故测试并记录在三目运算符中使用多个操作的方式 例子如下: true ? (console.log(1),console.log(2), tes ...
- 一些矩阵范数的subgradients
目录 引 正交不变范数 定理1 定理2 例子:谱范数 例子:核范数 算子范数 定理3 定理4 例子 \(\ell_2\) <Subgradients> Subderivate-wiki S ...
- 你懂redis吗
一.redis简介 Redis是当前比较热门的NOSQL系统之一,它是一个开源的使用ANSI c语言编写的key-value存储系统(区别于MySQL的二维表格的形式存储.).和Memcache类似, ...
- python模拟登陆Github示例
首先进入github登录页:https://github.com/login 输入账号密码,打开开发者工具,在Network页勾选上Preserve Log(显示持续日志),点击登录,查看Sessio ...
- Spring自动注入之@Autowired、@Resource、@Inject
相同点: 三者都支持对spring bean的自动注入 不同点: ①Autowired按照类型进行注入( Bean bean = applicationContext.getBean(Bean.cla ...
- LODOP打印当前日期时间的方法
JS方法直接获取.之前有个详细介绍的博文:LODOP打印用JS获取的当前日期本文也再演示一下,详细介绍见上面链接的博文,该方法此文不做详细介绍. 本文有三段:1.JS获取日期,2,.LODOP的FOR ...
- poj 3694(割边+lca)
题意:给你一个无向图,可能有重边,有q次询问,问你每次我添加一条边,添加后这个图还有多少个桥 解题思路:首先先把所有没有割边的点对缩成一个联通块,无向图一般并查集判环,然后就得到一个割边树,给你一条新 ...
- Lua中ipairs和pairs的区别详解
迭代器for遍历table时,ipairs和pairs的区别: 区别一:ipairs遇到nil会停止,pairs会输出nil值然后继续下去 区别二: , b = , x = , y = , " ...
- Python神器 Jupyter Notebook
什么是Jupyter Notebook? 简介 Jupyter Notebook是基于网页的用于交互计算的应用程序.其可被应用于全过程计算:开发.文档编写.运行代码和展示结果. Jupyter Not ...
- 洛谷P1512伊甸园的日历游戏题解
题目 因为可能要参加qbxt的数论考试,所以最近要开始猛刷数论题了. 这是第一道,不过看样子并不想数论题啊,只是一个博弈论. 思路 一位著名老师说过,数学就是转化和化简,所以先考虑化简,先考虑化简年份 ...