Hadoop网站日志数据清洗——正则表达式实现
周旭龙前辈的Hadoop学习笔记—网站日志分析项目案例简明、经典,业已成为高校大数据相关专业的实验项目。上周博主也完成了这个实验,不同于周前辈使用特殊符号切割字符串得到数据的做法,博主使用了正则表达式来匹配数据。在此将我的思路及代码张贴出来,以供后来者学习借鉴。
一、数据情况分析
1.1、数据格式概览
本次实验数据来自于国内某论坛,数据以行为单位,每行记录由5部分组成,访问者IP、访问时间、访问资源、访问状态、访问流量。

1.2、所需的数据
按照实验教程,我们只需要IP、时间、uri即可,不过本着既能完成实验,又能锻炼锻炼的想法,我把发个文状态以及访问流量也提取了出来。
1.3、上传数据至HDFS
本次试验到手的数据大小为60MB,约60万行。数据量较小,因此直接使用shell命令上传至HDFS。


注:欲知更详细的项目背景,请点击Hadoop学习笔记—网站日志分析项目案例(一)项目介绍__周旭龙_博客园
二、数据清洗准备
2.1、日志解析类
将解析日志信息的功能抽象成为一个日志解析类,分别解析各字段信息。
2.1.1 各字段的正则表达式
IP位于行的开头,因此定位到行起始位置,向右读取字符,直到遇到空格。又因为一个有效的IP最少为四个数字+三个符号,7位;最大为3*4+3,15位。所以行起始处7~15位为IP。表达式为:'^\S{7,15}'
时间位于一个方括号内,直接提取方括号内的数据即可:'\[.*?\]'
URI及其相关数据与时间数据位置类似,都在成对符号之内,因此可用相同的解法将其提取出来,再做下一步分析:'\".*?\"'
状态码只有三位数,且两边都是空格,可以吧两边的空格也提出来,再去掉:' \d{3} '
流量在行尾,也都是数字:'\d{1,6}$'
2.1.2 函数
除了一个parse函数以及五个分别处理字段的函数外,正则表达式匹配也抽象成了一个函数。需要注意的是匹配是否为空,以及匹配uri并将其分割为数组后下标取值是否越界。
- public class parseLine {
- public String[] parse(String line)
- {
- String ip = parseIP(line);
- String time = parseTime(line);
- String url = parseURL(line);
- String status = parseStatus(line);
- String traffic = parseTraffic(line);
- return new String[] {ip,time,url,status,traffic};
- }
- private String parseReg(String reg,String str)
- {
- Pattern pat = Pattern.compile(reg);
- Matcher matcher = pat.matcher(str);
- boolean rs = matcher.find();
- if(rs)
- return matcher.group(0);
- else
- return "null";
- }
- private String[] splitUrl(String str)
- {
- String []urlInfo = str.substring(1, str.length()-1).split(" ");
- return urlInfo;
- }
- private String parseTraffic(String line) {
- String reg_ip = "\\d{1,6}$";
- return parseReg(reg_ip,line);
- }
- private String parseStatus(String line) {
- String reg_ip = " \\d{3} ";
- return parseReg(reg_ip,line).trim();
- }
- private String parseURL(String line) {
- String reg_ip = "\".*?\"";
- String str = parseReg(reg_ip,line);
- String[] urlInfo = splitUrl(str);
- return urlInfo[1];
- }
- private String parseTime(String line) {
- String reg_ip = "\\[.*?\\]";
- String str = parseReg(reg_ip,line);
- SimpleDateFormat in=new SimpleDateFormat("[dd/MMM/yyyy:HH:mm:ss ZZZZZ]",Locale.US);
- SimpleDateFormat out=new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒");
- Date d = new Date();
- try
- {
- d=in.parse(str);
- }
- catch (ParseException e)
- {
- e.printStackTrace();
- }
- return out.format(d).trim();
- }
- private String parseIP(String line) {
- String reg_ip = "^\\S{7,15}";
- return parseReg(reg_ip,line);
- }
- }
2.2、Mapper类
map阶段的输入为<偏移量,一行文本>,输出为<偏移量,处理后的数据>。再这个类中,对数据的有效性判断也在这儿,博主只过滤了静态数据。
- public class logMap extends Mapper<LongWritable,Text,LongWritable,Text>{
- static parseInfo parseLine = new parseInfo();
- protected void map(LongWritable key1,Text value1,Context context) throws IOException,InterruptedException
- {
- String str1 = value1.toString();
- Text output = new Text();
- final String[] info = parseLine.parse(str1);
- if(info[2].startsWith("/static") || info[2].startsWith("/uc_server"))
- return ;
- StringBuilder result = new StringBuilder();
- for(String x:info)
- result.append(x).append("\t");
- output.set(result.toString());
- context.write(key1, output);
- }
- }
2.3、Reducer类
reduce阶段的输入与map的输出有关,为<偏移量,处理后数据的集合>,输出则为<处理后的数据,空>。
- public class logReducer extends Reducer<LongWritable,Text,Text,NullWritable>{
- protected void reduce(LongWritable k3,Iterable<Text> v3,Context context) throws IOException,InterruptedException{
- for(Text v3s : v3)
- context.write(v3s, NullWritable.get());
- }
- }
2.4、主函数
- public class logMain {
- public static void main(String[] args) throws Exception{
- Job job = Job.getInstance(new Configuration());
- job.setJarByClass(logMain.class);
- job.setMapperClass(logMap.class);
- job.setMapOutputKeyClass(LongWritable.class);
- job.setMapOutputValueClass(Text.class);
- job.setReducerClass(logReducer.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(NullWritable.class);
- FileInputFormat.setInputPaths(job, new Path(args[0]));
- FileOutputFormat.setOutputPath(job, new Path(args[1]));
- job.waitForCompletion(true);
- }
- }
三、数据清洗
将编写好的MR到处导出为jar包后,在hadoop中用小规模的测试用例试运行,成功后再用实验数据。
结果如下:
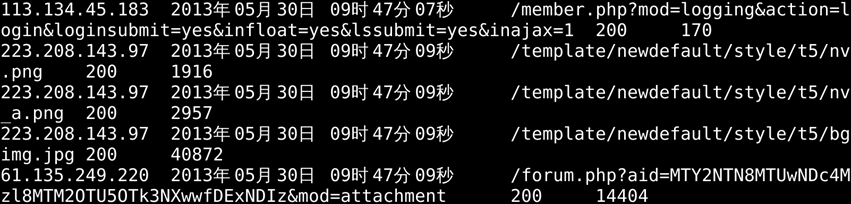
注:完整项目
Hadoop学习笔记—20.网站日志分析项目案例(一)项目介绍
Hadoop学习笔记—20.网站日志分析项目案例(二)数据清洗
Hadoop学习笔记—20.网站日志分析项目案例(三)统计分析
Hadoop网站日志数据清洗——正则表达式实现的更多相关文章
- Hadoop学习笔记—20.网站日志分析项目案例(二)数据清洗
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html 网站日志分析项目案例(二)数据清洗:当前页面 网站日志分析项目案例 ...
- Hadoop学习笔记—20.网站日志分析项目案例(一)项目介绍
网站日志分析项目案例(一)项目介绍:当前页面 网站日志分析项目案例(二)数据清洗:http://www.cnblogs.com/edisonchou/p/4458219.html 网站日志分析项目案例 ...
- Hadoop学习笔记—20.网站日志分析项目案例(三)统计分析
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html 网站日志分析项目案例(二)数据清洗:http://www.cnbl ...
- hive网站日志数据分析
一.说在前面的话 上一篇,楼主介绍了使用flume集群来模拟网站产生的日志数据收集到hdfs.但我们所采集的日志数据是不规则的,同时也包含了许多无用的日志.当需要分析一些核心指标来满足系统业务决策的时 ...
- Hive分析hadoop进程日志
想把hadoop的进程日志导入hive表进行分析,遂做了以下的尝试. 关于hadoop进程日志的解析 使用正则表达式获取四个字段,一个是日期时间,一个是日志级别,一个是类,最后一个是详细信息, 然后在 ...
- 一个简易Asp.net网站日志系统
前不久在网站上看到了网站日志访问记录组件UserVisitLogsHelp开源了! 这篇博客感觉还不错,就把源码download了下来,学习一下,发现里面的代码书写和设计并不是很好,于是自己改了改.自 ...
- 网站日志实时分析工具GoAccess使用
网站日志实时分析工具GoAccess使用 系统环境CentOS release 5.5 (Final) GoAccess是一款开源的网站日志实时分析工具. GoAccess 的工作方式就是读取和解析 ...
- 使用Nginx和Logstash以及kafka来实现网站日志采集的详细步骤和过程
使用Nginx和Logstash以及kafka来实现网站日志采集的详细步骤和过程 先列出来总体启动流程: (1)启动zookeeper集群(hadoop01.hadoop02和hadoop03这3台机 ...
- 深入剖析HADOOP程序日志
深入剖析HADOOP程序日志 前提 本文来自于 博客园 逖靖寒的世界 http://gpcuster.cnblogs.com 了解log4j的使用. 正文 本文来自于 博客园 逖靖寒的世界 http: ...
随机推荐
- [smarty] 在smarty模板中使用smarty变量初始化 javascript 变量的问题
// 总结:// 1/ 在smarty 模板文件中,使用从php中assign过来的smarty变量,一定需要使用双引号或单引号来括住smarty变量,如:var title="<!- ...
- 【算法31】寻找数组的主元素(Majority Element)
题外话 最近有些网友来信问我博客怎么不更新了,是不是不刷题了,真是惭愧啊,题还是在刷的,不过刷题的频率没以前高了,看完<算法导论>后感觉网上很多讨论的题目其实在导论中都已经有非常好的算法以 ...
- 测试一下你的T-SQL基础知识-subquery
一直以为自己SQL挺好的,没有想到今天在重构存储过程遇到了一个子查询的问题,修改为自连接之后发现居然结果不对,于是有了下面的测试.假设表中有如下数数据,请问Query1,Query2,Query3的查 ...
- ASP.NET Web API 2.0 统一响应格式
传统实现 在搭建 Web API 服务的时候,针对客户端请求,我们一般都会自定义响应的 JSON 格式,比如: { "Data" : { "Id" : 100, ...
- 如何把OpenWrt安装到PC?
前言 什么是openwrt? 它是一个适用于路由器的Linux发行版.和其他Linux发行版一样,它也内置了包管理工具,你可以从一个软件仓库里直接安装软件.OpenWrt可以用在所有需要嵌入式Linu ...
- day103 跨域请求 与频率访问限制.
目录 一.跨域请求 二.频率访问限制 一 .同一个域下的ajax请求访问 url文件 from django.conf.urls import url from django.contrib imp ...
- 「BZOJ1095」[ZJOI2007] Hide 捉迷藏
题目描述 Jiajia和Wind是一对恩爱的夫妻,并且他们有很多孩子.某天,Jiajia.Wind和孩子们决定在家里玩捉迷藏游戏.他们的家很大且构造很奇特,由N个屋子和N-1条双向走廊组成,这N-1条 ...
- 初中级web前端工程师的面试题分享
1.html三栏布局有几种(就是左右固定,中间自适应) 浮动布局float.定位布局.flex布局.表格布局.css3栅栏布局 <style media="screen"&g ...
- vsftp小记
安装一个vsftp都有问题(Version: 3.0.2-14ubuntu1),提示530 错误,之后修改配置如下(红色): # cat /etc/pam.d/vsftpdauth required ...
- 00-python概述。
人生苦短,我用Python. -发展历史: - 1989年,由Guido van Rossum开始开发, - 1991年,发布第一个公开发行版,第一个Python编译器(同时也是解释器)诞生. - 2 ...