lucene源码分析(5)lucence-group
1. 普通查询的用法
org.apache.lucene.search.IndexSearcher
public void search(Query query, Collector results)
其中
Collector定义
/**
* <p>Expert: Collectors are primarily meant to be used to
* gather raw results from a search, and implement sorting
* or custom result filtering, collation, etc. </p>
*
* <p>Lucene's core collectors are derived from {@link Collector}
* and {@link SimpleCollector}. Likely your application can
* use one of these classes, or subclass {@link TopDocsCollector},
* instead of implementing Collector directly:
*
* <ul>
*
* <li>{@link TopDocsCollector} is an abstract base class
* that assumes you will retrieve the top N docs,
* according to some criteria, after collection is
* done. </li>
*
* <li>{@link TopScoreDocCollector} is a concrete subclass
* {@link TopDocsCollector} and sorts according to score +
* docID. This is used internally by the {@link
* IndexSearcher} search methods that do not take an
* explicit {@link Sort}. It is likely the most frequently
* used collector.</li>
*
* <li>{@link TopFieldCollector} subclasses {@link
* TopDocsCollector} and sorts according to a specified
* {@link Sort} object (sort by field). This is used
* internally by the {@link IndexSearcher} search methods
* that take an explicit {@link Sort}.
*
* <li>{@link TimeLimitingCollector}, which wraps any other
* Collector and aborts the search if it's taken too much
* time.</li>
*
* <li>{@link PositiveScoresOnlyCollector} wraps any other
* Collector and prevents collection of hits whose score
* is <= 0.0</li>
*
* </ul>
*
* @lucene.experimental
*/
Collector的层次结构
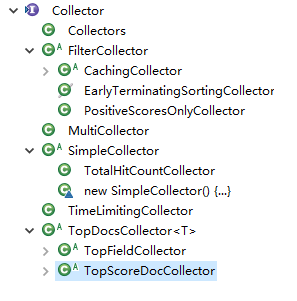
2 lucene-group
提供了分组查询GroupingSearch,对应相应的collector
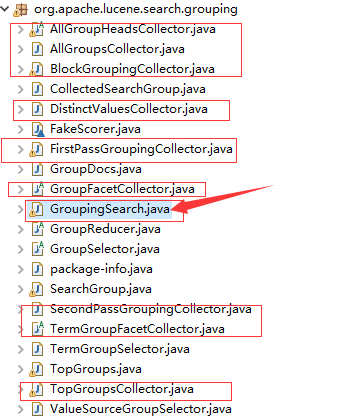
3.实例:
public Map<String, Integer> groupBy(Query query, String field, int topCount) {
Map<String, Integer> map = new HashMap<String, Integer>();
long begin = System.currentTimeMillis();
int topNGroups = topCount;
int groupOffset = 0;
int maxDocsPerGroup = 100;
int withinGroupOffset = 0;
try {
FirstPassGroupingCollector c1 = new FirstPassGroupingCollector(field, Sort.RELEVANCE, topNGroups);
boolean cacheScores = true;
double maxCacheRAMMB = 4.0;
CachingCollector cachedCollector = CachingCollector.create(c1, cacheScores, maxCacheRAMMB);
indexSearcher.search(query, cachedCollector);
Collection<SearchGroup<String>> topGroups = c1.getTopGroups(groupOffset, true);
if (topGroups == null) {
return null;
}
SecondPassGroupingCollector c2 = new SecondPassGroupingCollector(field, topGroups, Sort.RELEVANCE, Sort.RELEVANCE, maxDocsPerGroup, true, true, true);
if (cachedCollector.isCached()) {
// Cache fit within maxCacheRAMMB, so we can replay it:
cachedCollector.replay(c2);
} else {
// Cache was too large; must re-execute query:
indexSearcher.search(query, c2);
}
TopGroups<String> tg = c2.getTopGroups(withinGroupOffset);
GroupDocs<String>[] gds = tg.groups;
for(GroupDocs<String> gd : gds) {
map.put(gd.groupValue, gd.totalHits);
}
} catch (IOException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("group by time :" + (end - begin) + "ms");
return map;
}
几个参数说明:
groupField: 分组域groupSort: 分组排序topNGroups: 最大分组数groupOffset: 分组分页用withinGroupSort: 组内结果排序maxDocsPerGroup: 每个分组的最多结果数withinGroupOffset: 组内分页用
参考资料
https://blog.csdn.net/wyyl1/article/details/7388241
lucene源码分析(5)lucence-group的更多相关文章
- Lucene 源码分析之倒排索引(三)
上文找到了 collect(-) 方法,其形参就是匹配的文档 Id,根据代码上下文,其中 doc 是由 iterator.nextDoc() 获得的,那 DefaultBulkScorer.itera ...
- 一个lucene源码分析的博客
ITpub上的一个lucene源码分析的博客,写的比较全面:http://blog.itpub.net/28624388/cid-93356-list-1/
- lucene源码分析的一些资料
针对lucene6.1较新的分析:http://46aae4d1e2371e4aa769798941cef698.devproxy.yunshipei.com/conansonic/article/d ...
- Lucene 源码分析之倒排索引(一)
倒排索引是 Lucene 的核心数据结构,该系列文章将从源码层面(源码版本:Lucene-7.3.0)分析.该系列文章将以如下的思路展开. 什么是倒排索引? 如何定位 Lucene 中的倒排索引? 倒 ...
- lucene源码分析(1)基本要素
1.源码包 core: Lucene core library analyzers-common: Analyzers for indexing content in different langua ...
- Lucene 源码分析之倒排索引(二)
本文以及后面几篇文章将讲解如何定位 Lucene 中的倒排索引.内容很多,唯有静下心才能跟着思路遨游. 我们可以思考一下,哪个步骤与倒排索引有关,很容易想到检索文档一定是要查询倒排列表的,那么就从此处 ...
- lucene源码分析(8)MergeScheduler
1.使用IndexWriter.java mergeScheduler.merge(this, MergeTrigger.EXPLICIT, newMergesFound); 2.定义MergeSch ...
- lucene源码分析(7)Analyzer分析
1.Analyzer的使用 Analyzer使用在IndexWriter的构造方法 /** * Constructs a new IndexWriter per the settings given ...
- lucene源码分析(6)Query分析
查询的入口 /** Lower-level search API. * * <p>{@link LeafCollector#collect(int)} is called for ever ...
随机推荐
- Python学习-29.Python中列表的一些操作
in关键字: 注意这个是关键字,用来判断元素是否在集合中存在. list = ['a','b','c'] print('a' in list) print('f' in list) 将依次输出 Tru ...
- matlab中使用正弦波合成方波(带动画)
x=:*pi; :: s=; ::step s = s+/i*sin(i*x); end plot(s);set(figure(),'visible','off'); filename=[num2st ...
- NSUserDefaults用法详解
一.了解NSUserDefaults以及它可以直接存储的类型 NSUserDefaults是一个单例,在整个程序中只有一个实例对象,他可以用于数据的永久保存,而且简单实用,这是它可以让数据自由传递的一 ...
- 在AbpZero中hangfire后台作业的使用——hangfire的调度
在abpzero框架中,hangfiire通过依赖注入来进行接口的调用 hangfire的事件处理分为以下几种: 1.基于队列的任务处理(Fire-and-forget jobs) var jobId ...
- JQuery 的一个轻量级 Guid 字符串拓展插件.
(function ($) { function guid(g) { var arr = new Array(); //存放32位数值的数组 if (typeof (g) == "strin ...
- 双缓冲队列解决WPF界面卡死
工作中的项目,CS客户端会通过MQ接收前端设备发送的信息,之前测试的时候,由于测试的数据不大,没有进行压力测试,软件可以正常工作,随着项目现场设备数量的增加,CS客户端从MQ中订阅的数据量不断增加,最 ...
- 编程哲学之C#篇:02——学习思维
<代码大全>的第二章:介绍隐喻(类比)的思维方式, <经济学原理>的第二章:介绍怎么像经济学家一样思考, <计算机的心智操作系统之哲学原理>的第一章:介绍学习操作系 ...
- ElasticSearch学习总结(二):ES介绍与架构说明
本文主要从概念以及架构层面对Elasticsearch做一个简单的介绍,在介绍ES之前,会先对ES的"发动机"Lucene做一个简单的介绍 1. Lucene介绍 为了更深入地理解 ...
- Python(文件上传)
day26 通过socket上传文件. post_client.py import socket import os sk = socket.socket() print(sk) address = ...
- kubernetes traefik multiple namespaces
官方文档在此 https://docs.traefik.io/user-guide/kubernetes/ 官方文档在配置 RBAC 时使用了 ClusterRoleBinding, 当你想用多命名空 ...