Spark Streaming updateStateByKey案例实战和内幕源码解密
本节课程主要分二个部分:
一、Spark Streaming updateStateByKey案例实战
二、Spark Streaming updateStateByKey源码解密
第一部分:
updateStateByKey的主要功能是随着时间的流逝,在Spark Streaming中可以为每一个可以通过CheckPoint来维护一份state状态,通过更新函数对该key的状态不断更新;对每一个新批次的数据(batch)而言,Spark Streaming通过使用updateStateByKey为已经存在的key进行state的状态更新(对每个新出现的key,会同样执行state的更新函数操作);但是如果通过更新函数对state更新后返回none的话,此时刻key对应的state状态被删除掉,需要特别说明的是state可以是任意类型的数据结构,这就为我们的计算带来无限的想象空间;
非常重要:
如果要不断的更新每个key的state,就一定会涉及到状态的保存和容错,这个时候就需要开启checkpoint机制和功能,需要说明的是checkpoint的数据可以保存一些存储在文件系统上的内容,例如:程序未处理的但已经拥有状态的数据。
补充说明:
关于流式处理对历史状态进行保存和更新具有重大实用意义,例如进行广告(投放广告和运营广告效果评估的价值意义,热点随时追踪、热力图)
案例实战源码:
1.编写源码:
ackage org.apache.spark.examples.streaming;
import java.util.Arrays;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import com.google.common.base.Optional;
import scala.Tuple2;
public class UpdateStateByKeyDemo {
public static void main(String[] args) {
/*
* 第一步:配置SparkConf:
* 1,至少2条线程:因为Spark Streaming应用程序在运行的时候,至少有一条
* 线程用于不断的循环接收数据,并且至少有一条线程用于处理接受的数据(否则的话无法
* 有线程用于处理数据,随着时间的推移,内存和磁盘都会不堪重负);
* 2,对于集群而言,每个Executor一般肯定不止一个Thread,那对于处理Spark Streaming的
* 应用程序而言,每个Executor一般分配多少Core比较合适?根据我们过去的经验,5个左右的
* Core是最佳的(一个段子分配为奇数个Core表现最佳,例如3个、5个、7个Core等);
*/
SparkConf conf = new SparkConf().setMaster("local[2]").
setAppName("UpdateStateByKeyDemo");
/*
* 第二步:创建SparkStreamingContext:
* 1,这个是SparkStreaming应用程序所有功能的起始点和程序调度的核心
* SparkStreamingContext的构建可以基于SparkConf参数,也可基于持久化的SparkStreamingContext的内容
* 来恢复过来(典型的场景是Driver崩溃后重新启动,由于Spark Streaming具有连续7*24小时不间断运行的特征,
* 所有需要在Driver重新启动后继续上衣系的状态,此时的状态恢复需要基于曾经的Checkpoint);
* 2,在一个Spark Streaming应用程序中可以创建若干个SparkStreamingContext对象,使用下一个SparkStreamingContext
* 之前需要把前面正在运行的SparkStreamingContext对象关闭掉,由此,我们获得一个重大的启发SparkStreaming框架也只是
* Spark Core上的一个应用程序而已,只不过Spark Streaming框架箱运行的话需要Spark工程师写业务逻辑处理代码;
*/
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5));
//报错解决办法做checkpoint,开启checkpoint机制,把checkpoint中的数据放在这里设置的目录中,
//生产环境下一般放在HDFS中
jsc.checkpoint("/usr/local/tmp/checkpoint");
/*
* 第三步:创建Spark Streaming输入数据来源input Stream:
* 1,数据输入来源可以基于File、HDFS、Flume、Kafka、Socket等
* 2, 在这里我们指定数据来源于网络Socket端口,Spark Streaming连接上该端口并在运行的时候一直监听该端口
* 的数据(当然该端口服务首先必须存在),并且在后续会根据业务需要不断的有数据产生(当然对于Spark Streaming
* 应用程序的运行而言,有无数据其处理流程都是一样的);
* 3,如果经常在每间隔5秒钟没有数据的话不断的启动空的Job其实是会造成调度资源的浪费,因为并没有数据需要发生计算,所以
* 实例的企业级生成环境的代码在具体提交Job前会判断是否有数据,如果没有的话就不再提交Job;
*/
JavaReceiverInputDStream lines = jsc.socketTextStream("hadoop100", 9999);
/*
* 第四步:接下来就像对于RDD编程一样基于DStream进行编程!!!原因是DStream是RDD产生的模板(或者说类),在Spark Streaming具体
* 发生计算前,其实质是把每个Batch的DStream的操作翻译成为对RDD的操作!!!
*对初始的DStream进行Transformation级别的处理,例如map、filter等高阶函数等的编程,来进行具体的数据计算
* 第4.1步:讲每一行的字符串拆分成单个的单词
*/
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() { //如果是Scala,由于SAM转换,所以可以写成val words = lines.flatMap { line => line.split(" ")}
@Override
public Iterable<String> call(String line) throws Exception {
return Arrays.asList(line.split(" "));
}
});
/*
* 第四步:对初始的DStream进行Transformation级别的处理,例如map、filter等高阶函数等的编程,来进行具体的数据计算
* 第4.2步:在单词拆分的基础上对每个单词实例计数为1,也就是word => (word, 1)
*/
JavaPairDStream<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
/*
* 第四步:对初始的DStream进行Transformation级别的处理,例如map、filter等高阶函数等的编程,来进行具体的数据计算
*第4.3步:在这里是通过updateStateByKey来以Batch Interval为单位来对历史状态进行更新,
* 这是功能上的一个非常大的改进,否则的话需要完成同样的目的,就可能需要把数据保存在Redis、
* Tagyon或者HDFS或者HBase或者数据库中来不断的完成同样一个key的State更新,如果你对性能有极为苛刻的要求,
* 且数据量特别大的话,可以考虑把数据放在分布式的Redis或者Tachyon内存文件系统中;
* 当然从Spark1.6.x开始可以尝试使用mapWithState,Spark2.X后mapWithState应该非常稳定了。
*/
JavaPairDStream<String, Integer> wordsCount = pairs.updateStateByKey(new Function2<List<Integer>, Optional<Integer>, Optional<Integer>>() { //对相同的Key,进行Value的累计(包括Local和Reducer级别同时Reduce)
@Override
public Optional<Integer> call(List<Integer> values, Optional<Integer> state)
throws Exception {
Integer updatedValue = 0 ;
if(state.isPresent()){
updatedValue = state.get();
}
for(Integer value: values){
updatedValue += value;
}
return Optional.of(updatedValue);
}
});
/*
*此处的print并不会直接出发Job的执行,因为现在的一切都是在Spark Streaming框架的控制之下的,对于Spark Streaming
*而言具体是否触发真正的Job运行是基于设置的Duration时间间隔的
*诸位一定要注意的是Spark Streaming应用程序要想执行具体的Job,对Dtream就必须有output Stream操作,
*output Stream有很多类型的函数触发,类print、saveAsTextFile、saveAsHadoopFiles等,最为重要的一个
*方法是foraeachRDD,因为Spark Streaming处理的结果一般都会放在Redis、DB、DashBoard等上面,foreachRDD
*主要就是用用来完成这些功能的,而且可以随意的自定义具体数据到底放在哪里!!!
*/
wordsCount.print();
/*
* Spark Streaming执行引擎也就是Driver开始运行,Driver启动的时候是位于一条新的线程中的,当然其内部有消息循环体,用于
* 接受应用程序本身或者Executor中的消息;
*/
jsc.start();
jsc.awaitTermination();
jsc.close();
}
2.创建checkpoint目录:
jsc.checkpoint("/usr/local/tmp/checkpoint");
3. 在eclipse中通过run 方法启动main函数:
4.启动hdfs服务并发送nc -lk 9999请求:
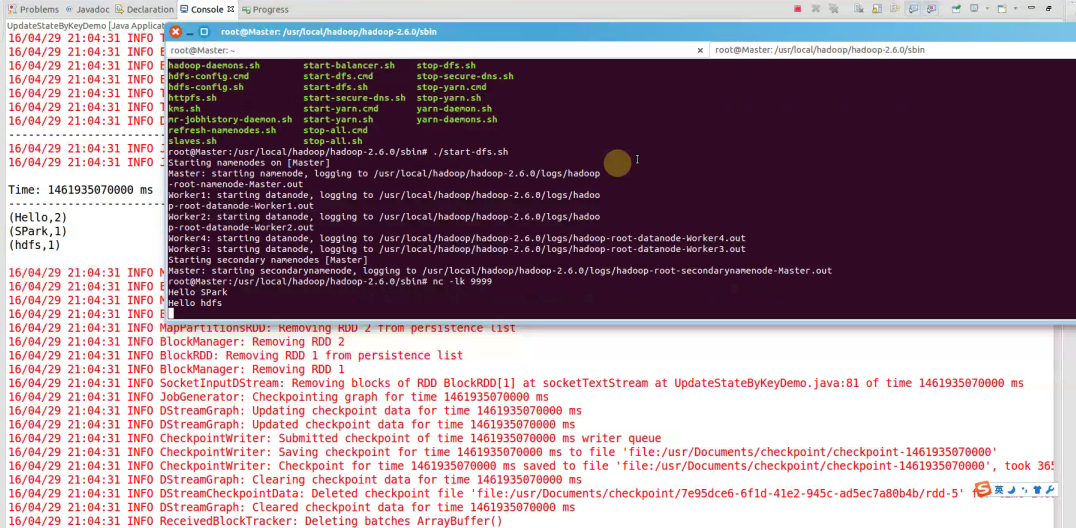
5.查看checkpoint目录输出:

源码解析:
1.PairDStreamFunctions类:
/**
* Return a new "state" DStream where the state for each key is updated by applying
* the given function on the previous state of the key and the new values of each key.
* Hash partitioning is used to generate the RDDs with Spark's default number of partitions.
* @param updateFunc State update function. If `this` function returns None, then
* corresponding state key-value pair will be eliminated.
* @tparam S State type
*/
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S]
): DStream[(K, S)] = ssc.withScope {
updateStateByKey(updateFunc, defaultPartitioner())
}
/**
* Return a new "state" DStream where the state for each key is updated by applying
* the given function on the previous state of the key and the new values of the key.
* org.apache.spark.Partitioner is used to control the partitioning of each RDD.
* @param updateFunc State update function. If `this` function returns None, then
* corresponding state key-value pair will be eliminated.
* @param partitioner Partitioner for controlling the partitioning of each RDD in the new
* DStream.
* @tparam S State type
*/
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S],
partitioner: Partitioner
): DStream[(K, S)] = ssc.withScope {
val cleanedUpdateF = sparkContext.clean(updateFunc)
val newUpdateFunc = (iterator: Iterator[(K, Seq[V], Option[S])]) => {
iterator.flatMap(t => cleanedUpdateF(t._2, t._3).map(s => (t._1, s)))
}
updateStateByKey(newUpdateFunc, partitioner, true)
}
/**
* Return a new "state" DStream where the state for each key is updated by applying
* the given function on the previous state of the key and the new values of each key.
* org.apache.spark.Partitioner is used to control the partitioning of each RDD.
* @param updateFunc State update function. Note, that this function may generate a different
* tuple with a different key than the input key. Therefore keys may be removed
* or added in this way. It is up to the developer to decide whether to
* remember the partitioner despite the key being changed.
* @param partitioner Partitioner for controlling the partitioning of each RDD in the new
* DStream
* @param rememberPartitioner Whether to remember the paritioner object in the generated RDDs.
* @tparam S State type
*/ def updateStateByKey[S: ClassTag](
updateFunc: (Iterator[(K, Seq[V], Option[S])]) => Iterator[(K, S)],
partitioner: Partitioner,
rememberPartitioner: Boolean
): DStream[(K, S)] = ssc.withScope {
new StateDStream(self, ssc.sc.clean(updateFunc), partitioner, rememberPartitioner, None)
}
override def compute(validTime: Time): Option[RDD[(K, S)]] = {
// Try to get the previous state RDD
getOrCompute(validTime - slideDuration) match {
case Some(prevStateRDD) => { // If previous state RDD exists
// Try to get the parent RDD
parent.getOrCompute(validTime) match {
case Some(parentRDD) => { // If parent RDD exists, then compute as usual
computeUsingPreviousRDD (parentRDD, prevStateRDD)
}
case None => { // If parent RDD does not exist
// Re-apply the update function to the old state RDD
val updateFuncLocal = updateFunc
val finalFunc = (iterator: Iterator[(K, S)]) => {
val i = iterator.map(t => (t._1, Seq[V](), Option(t._2)))
updateFuncLocal(i)
}
val stateRDD = prevStateRDD.mapPartitions(finalFunc, preservePartitioning)
Some(stateRDD)
}
}
}
case None => { // If previous session RDD does not exist (first input data)
// Try to get the parent RDD
parent.getOrCompute(validTime) match {
case Some(parentRDD) => { // If parent RDD exists, then compute as usual
initialRDD match {
case None => {
// Define the function for the mapPartition operation on grouped RDD;
// first map the grouped tuple to tuples of required type,
// and then apply the update function
val updateFuncLocal = updateFunc
val finalFunc = (iterator : Iterator[(K, Iterable[V])]) => {
updateFuncLocal (iterator.map (tuple => (tuple._1, tuple._2.toSeq, None)))
}
val groupedRDD = parentRDD.groupByKey (partitioner)
val sessionRDD = groupedRDD.mapPartitions (finalFunc, preservePartitioning)
// logDebug("Generating state RDD for time " + validTime + " (first)")
Some (sessionRDD)
}
case Some (initialStateRDD) => {
computeUsingPreviousRDD(parentRDD, initialStateRDD)
}
}
}
case None => { // If parent RDD does not exist, then nothing to do!
// logDebug("Not generating state RDD (no previous state, no parent)")
None
}
}
}
}
总结:
姜伟
备注:93课
更多私密内容,请关注微信公众号:DT_Spark
Spark Streaming updateStateByKey案例实战和内幕源码解密的更多相关文章
- 基于HDFS的SparkStreaming案例实战和内幕源码解密
一:Spark集群开发环境准备 启动HDFS,如下图所示: 通过web端查看节点正常启动,如下图所示: 2.启动Spark集群,如下图所示: 通过web端查看集群启动正常,如下图所示: 3.启动sta ...
- Spark Streaming从Flume Poll数据案例实战和内幕源码解密
本节课分成二部分讲解: 一.Spark Streaming on Polling from Flume实战 二.Spark Streaming on Polling from Flume源码 第一部分 ...
- Flume推送数据到SparkStreaming案例实战和内幕源码解密
本期内容: 1. Flume on HDFS案例回顾 2. Flume推送数据到Spark Streaming实战 3. 原理绘图剖析 1. Flume on HDFS案例回顾 上节课要求大家自己安装 ...
- Dream_Spark-----Spark 定制版:005~贯通Spark Streaming流计算框架的运行源码
Spark 定制版:005~贯通Spark Streaming流计算框架的运行源码 本讲内容: a. 在线动态计算分类最热门商品案例回顾与演示 b. 基于案例贯通Spark Streaming的运 ...
- 基于案例贯通 Spark Streaming 流计算框架的运行源码
本期内容 : Spark Streaming+Spark SQL案例展示 基于案例贯穿Spark Streaming的运行源码 一. 案例代码阐述 : 在线动态计算电商中不同类别中最热门的商品排名,例 ...
- 贯通Spark Streaming流计算框架的运行源码
本章节内容: 一.在线动态计算分类最热门商品案例回顾 二.基于案例贯通Spark Streaming的运行源码 先看代码(源码场景:用户.用户的商品.商品的点击量排名,按商品.其点击量排名前三): p ...
- 66、Spark Streaming:数据处理原理剖析与源码分析(block与batch关系透彻解析)
一.数据处理原理剖析 每隔我们设置的batch interval 的time,就去找ReceiverTracker,将其中的,从上次划分batch的时间,到目前为止的这个batch interval ...
- [Spark内核] 第33课:Spark Executor内幕彻底解密:Executor工作原理图、ExecutorBackend注册源码解密、Executor实例化内幕、Executor具体工作内幕
本課主題 Spark Executor 工作原理图 ExecutorBackend 注册源码鉴赏和 Executor 实例化内幕 Executor 具体是如何工作的 [引言部份:你希望读者看完这篇博客 ...
- spark streaming updateStateByKey 用法
object NetworkWordCount { def main(args: Array[String]) { ) { System.err.println("Usage: Networ ...
随机推荐
- UNP学习总结(二)
本文是UNP复习系列的第二篇,主要包括了以下几个内容 UNIX系统下5种I/O模型 阻塞.非阻塞,同步.异步 epoll函数用例 一.Unix下的五种可用I/O模型 阻塞式I/O模型 阻塞式I/O是最 ...
- Centos 安装 Wireshark
Wireshark是一款数据包识别软件,应用很广泛. yum install wireshark yum install wireshark-gnome
- Java 的类加载顺序
Java 的类加载顺序 一.加载顺序:先父类后子类,先静态后普通 1.父类的静态成员变量初始化 2.父类的静态代码块 3.子类的静态成员变量初始化 4.子类的静态代码块 5.父类的普通成员变量初始化 ...
- hdu 4442 Physical Examination 贪心排序
Physical Examination Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others ...
- js面向对象写页面
<!doctype html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- YS报警权限验证安全设计
1.总体流程图: 备注: 1. 使用加时间戳的方式优点是可以不用对报警请求进行加密,也可以防止信令重放,缺点是每次都要去DAS获取新的签名.
- SQL Structured Query Language(结构化查询语言) 数据库
SQL是Structured Query Language(结构化查询语言)的缩写. SQL是专为数据库而建立的操作命令集,是一种功能齐全的数据库语言. 在使用它时,只需要发出“做什么”的命令,“怎么 ...
- 利用.bat文件快速设置IE代理与清除IE代理
http://www.duoluodeyu.com/2009/17.html 设置IE代理.bat文件原文:将下面红色文字复制保存为.bat文件即可. 复制后将蓝色字体部分改成你要设置的代理服务器地址 ...
- hint.css使用说明
GitHub:http://liu12fei08fei.github.io/html/1hint.html hint.css使用说明 用途 快速实现tooltips提示样式 相关资源 官方网站GitH ...
- MapReduce实现排序功能
期间遇到了无法转value的值为int型,我採用try catch解决 str2 2 str1 1 str3 3 str1 4 str4 7 str2 5 str3 9 用的\t隔开,得到结果 str ...