java基础71 XML解析中的【DOM和SAX解析工具】相关知识点(网页知识)
本文知识点(目录):本文下面的“实例及附录”全是DOM解析的相关内容
1、xml解析的含义
2、XML的解析方式
3、xml的解析工具
4、XML的解析原理
5、实例
6、附录1(获取xml中的所有节点、根标签、根标签下的子标签、子标签中的文本内容)
7、附录2(获取xml中的所有节点、根标签、根标签下的子标签、子标签中的文本内容)
8、附录3(把xml文档中的信息封装到对象中)
1、xml解析的含义
xml文件除了给开发者看,更多情况下是使用程序读取xml文件中的内容
2、XML的解析方式
DOM解析
SAX解析
3、xml的解析工具
3.1、DOM解析工具
1.JAXP(oracle-Sun公司官方)
2.JDOM工具(非官方)
3.Dom4j工具(非官方的)。 三大框架(默认读取xml的工具就是DOM4j)
3.2、SAX解析工具
1.Sax解析工具(oracle-Sun公司官方)
4、XML的解析原理
4.1、DOM解析的原理
xml解析器一次性把整个xml文档加载进内存,然后在内存中构建一个Document的对象树,通过document对象,得到树上的节点对象,通过节点对象访问(操作)到xml文档的内容.
缺点:内存消耗大
优点:文档增删改查比较容易
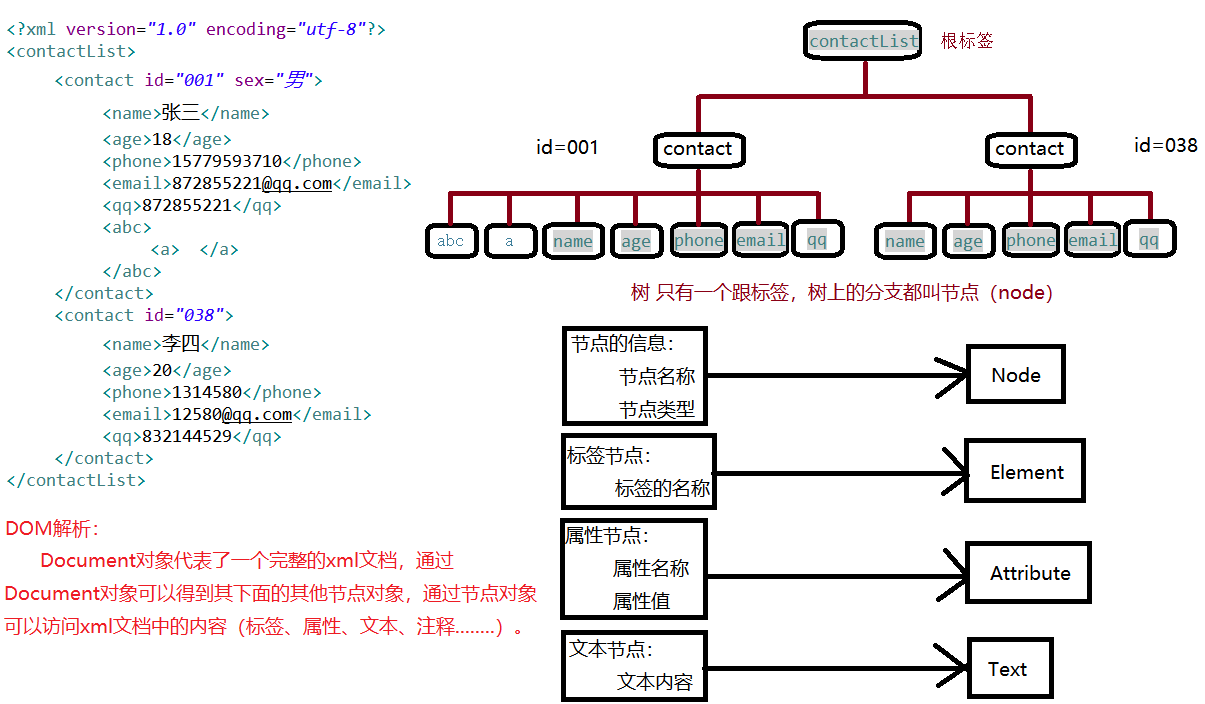
4.2、SAX解析的原理
从上往下读,读一行处理一行。 DOM与SAX解析的区别 SAX解析原理
优点:内存消耗小,适合读
缺点:不适合增删改
5、实例
例1:
package com.bw.test; import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.io.SAXReader; public class Demo1 {
/*
* 第一个Dom4j读取xml文档的例子
*
* */
public static void main(String[] args) {
try {
//1.创建一个xml解析器对象
SAXReader reader = new SAXReader();
//2.读取xml文档,返回Document对象
Document doc= reader.read("./src/contact.xml");
System.out.println(doc);
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
contact.xml文件
<?xml version="1.0" encoding="utf-8"?>
<contactList>
<contact id="001" sex="男">
<name>张三</name>
<age>18</age>
<phone>15779593710</phone>
<email>872855221@qq.com</email>
<qq>872855221</qq>
<abc>
<a><b></b></a>
</abc>
</contact>
<contact id="038">
<name>李四</name>
<age>20</age>
<phone>1314580</phone>
<email>12580@qq.com</email>
<qq>832144529</qq>
</contact>
</contactList>
例2:
package com.shore.test; import java.io.File;
import java.util.Iterator;
import java.util.List; import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import org.junit.Test; /**
* @author DSHORE / 2018-8-29
*
*/
public class Demo1 {
@Test
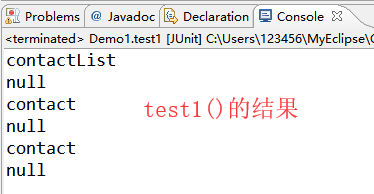
public void test1() throws DocumentException{
//1.读取xml文档,返回一个document对象
SAXReader reader=new SAXReader();
Document doc=reader.read(new File("./src/contact.xml"));
//nodeIterator:得到当前节点下的所有子节点对象(不包含孙以及孙以下的节点)
Iterator<Node> it=doc.nodeIterator();
while(it.hasNext()){//判断是否有下一位元素
Node node=it.next();
System.out.println(node.getName());
//继续获取下面的子节点
//只有标签有子节点
//判断当前节点是否为标签节点
if(node instanceof Element){
Element elem=(Element)node;
Iterator<Node> it2=elem.nodeIterator();
while(it2.hasNext()){
Node n2=it2.next();
System.out.println(n2.getName());
}
}
}
}
}
实例结果图

附录1
package com.shore.test; import java.io.File;
import java.util.Iterator;
import java.util.List; import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import org.junit.Test; /**
* @author DSHORE / 2018-8-29
*
*/
/*
* 第二个dom4j读取的xml文件内容
* 节点
* 标签
* 属性
* 文本
* */
public class Demo1 {
@Test
public void test1() throws DocumentException{
//1.读取xml文档,返回一个document对象
SAXReader reader=new SAXReader();
Document doc=reader.read(new File("./src/contact.xml"));
//nodeIterator:得到当前节点下的所有子节点对象(不包含孙以及孙以下的节点)
Iterator<Node> it=doc.nodeIterator();
while(it.hasNext()){//判断是否有下一位元素
Node node=it.next();
System.out.println(node.getName());
//继续获取下面的子节点
//只有标签有子节点
//判断当前节点是否为标签节点
if(node instanceof Element){
Element elem=(Element)node;
Iterator<Node> it2=elem.nodeIterator();
while(it2.hasNext()){
Node n2=it2.next();
System.out.println(n2.getName());
}
}
}
}
/*
* 遍历xml文件的所有节点
* */
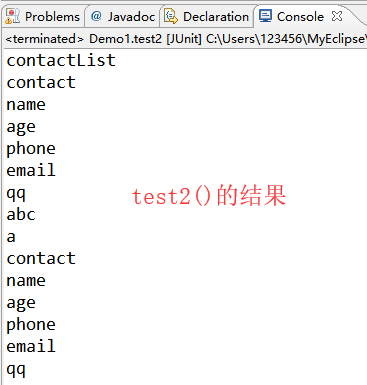
@Test
public void test2() throws DocumentException{
//1.读取xml文档获取Document对象
SAXReader reader=new SAXReader();
Document doc=reader.read(new File("./src/contact.xml"));
//得到跟标签
Element rootEls=doc.getRootElement();
getChildNodes(rootEls);
}
/*
* 获取传入标签下的所有子标签
* */
private void getChildNodes(Element rootEls) {
if(rootEls instanceof Element){
System.out.println(rootEls.getName());
}
//得到子节点
Iterator<Node> it=rootEls.nodeIterator();
while(it.hasNext()){
Node node=it.next();
//判断是否是标签节点
if(node instanceof Element){
Element el=(Element)node;
//递归
getChildNodes(el);
}
}
}
/*
* 获取标签
* */
@Test
public void test3() throws DocumentException{
//1.读取xml文档,返回Document对象
SAXReader reader=new SAXReader();
Document doc=reader.read(new File("./src/contact.xml"));
//得到跟标签
Element elt=doc.getRootElement();
//得到标签名称
String name=elt.getName();
System.out.println(name);//返回值:contactList //方法1:得到当前标签下指定的名称的第一个子标签
Element contactElem=elt.element("contact");
String name1=contactElem.getName();
System.out.println(name1);//返回值:contact //方法2:得到当前根标签下的所有下一级子标签
List<Element> list=elt.elements();
//遍历list
//1).传统的for循环 2).增强for循环 3).迭代器
for(int i=0;i<list.size();i++){
Element e=list.get(i);
System.out.println(e.getName());//返回值:contact 注意:这里的返回值是有两个contact,因为contact.xml文件中有两个根标签的下一级标签contact(两个contact是同一级)
}
for (Element e : list) {//增强for循环
System.out.println(e.getName());//返回值:contact 同上
}
Iterator<Element> it=list.iterator();
while(it.hasNext()){//迭代器
Element e=it.next();
System.out.println(e.getName());//返回值:contact 同上
} //方法3:获取更深层次标签(方法只能一层层地获取)
Element element=doc.getRootElement().element("contact").element("name");
System.out.println(element.getName());//返回值:name
}
/*
* 获取属性值
* */
@Test
public void test4() throws DocumentException{
//1.读取xml文档,返回一个Document对象
SAXReader reader=new SAXReader();
Document doc=reader.read(new File("./src/contact.xml"));
//获取属性(先获取标签对象,然后在获取属性)
//获得标签对象
Element contactElt=doc.getRootElement().element("contact");
//获取属性,得到指定名称属性值
String idValue=contactElt.attributeValue("id");
System.out.println(idValue);//返回值:001
//得到指定属性名称的属性对象
Attribute idAttr=contactElt.attribute("id");
//getName()属性名 getValue属性值
System.out.println(idAttr.getName()+"/"+idAttr.getValue());//返回值:id/001
}
}
结果图

注:test3()的结果,看代码中的注释
附录2
package com.shore.test; import java.io.File;
import java.util.Iterator;
import java.util.List; import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.junit.Test;
/**
* @author DSHORE / 2018-8-29
*
*/ public class Demo2 {
/*
* 获取属性
* */
@Test
public void test() throws DocumentException{
//1.解析xml文档,返回一个document对象
Document doc=new SAXReader().read(new File("./src/contact.xml"));
//获取属性:(先获取属性所在标签对象,然后才能获取属性值)
//2.得到标签
Element elt=doc.getRootElement().element("contact");
//3.得到属性
//得到指定名称的属性值
String idValue=elt.attributeValue("id");
System.out.println(idValue);//返回值:001
//得到指定名称的属性对象
Attribute aib=elt.attribute("id");
//getName() 属性名称 getValue()属性值
System.out.println("属性名称:"+aib.getName()+"/"+"属性值:"+aib.getValue());//返回值:属性名称:id/属性值:001 //方式1:得到所有属性对象,返回一个list()
List<Attribute> list=elt.attributes();
for (Attribute attr: list) {
System.out.println(attr.getName());//返回值:id/001 sex/男
} //方式2:得到所有属性对象,返回一个迭代器
Iterator<Attribute> attr2=elt.attributeIterator();
while(attr2.hasNext()){
Attribute a=attr2.next();
System.out.println(a.getName()+"/"+a.getValue());//返回值:id/001 sex/男
}
}
/*
* 获取文本内容
* */
@Test
public void test2() throws DocumentException{
//1.解析xml文档,返回一个document对象
Document doc=new SAXReader().read(new File("./src/contact.xml"));
/*
* 注意:空格和换行也是xml的内容
* */
String content=doc.getRootElement().getText();
//获取文本内容(先获取标签,在获取标签上的内容)
Element elt=doc.getRootElement().element("contact").element("name");
//方式1:得到文本内容
String test=elt.getText();
System.out.println(test);//返回值:张三 //方式2:得到指定标签的文本内容
String test2=doc.getRootElement().element("contact").elementText("phone");
System.out.println(test2); //返回值:15779593710
}
}
附录3
contact.xml文件
<?xml version="1.0" encoding="utf-8"?>
<contactList>
<contact id="001" sex="男">
<name>张三</name>
<age>18</age>
<phone>15779593710</phone>
<email>872855221@qq.com</email>
<qq>872855221</qq>
<abc>
<a> </a>
</abc>
</contact>
<contact id="038">
<name>李四</name>
<age>20</age>
<phone>1314580</phone>
<email>12580@qq.com</email>
<qq>832144529</qq>
</contact>
</contactList>
Contact实体(模型)
package com.shore.test; /**
* @author DSHORE / 2018-8-29
*
*/
public class Contact {
private String id;
private String name;
private String age;
private String phone;
private String email;
private String qq; public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public String getQq() {
return qq;
}
public void setQq(String qq) {
this.qq = qq;
}
@Override
public String toString() {
return "Contact [id=" + id + ", name=" + name + ", age=" + age
+ ", phone=" + phone + ", email=" + email + ", qq=" + qq + "]";
}
}
把xml文档中的信息封装到对象中
package com.shore.test; import java.io.File;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List; import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader; /**
* @author DSHORE / 2018-8-29
*
*/
//把xml文档中的信息封装到对象中
public class Demo3 {
public static void main(String[] args) throws DocumentException {
List<Contact> list=new ArrayList<Contact>();
//读取xml,封装对象
Document doc=new SAXReader().read(new File("./src/contact.xml"));
Iterator<Element> it=doc.getRootElement().elementIterator("contact");
while(it.hasNext()){
Element elt=it.next();
//创建
Contact contact=new Contact();
contact.setId(elt.attributeValue("id"));
contact.setName(elt.elementText("name"));
contact.setAge(elt.elementText("age"));
contact.setPhone(elt.elementText("phone"));
contact.setEmail(elt.elementText("email"));
contact.setQq(elt.elementText("qq"));
list.add(contact);
}
for (Contact contact : list) {
System.out.println(contact);
}
}
}
结果图

|
原创作者:DSHORE 作者主页:http://www.cnblogs.com/dshore123/ 原文出自:https://www.cnblogs.com/dshore123/p/9550048.html 欢迎转载,转载务必说明出处。(如果本文对您有帮助,可以点击一下右下角的 推荐,或评论,谢谢!) |
java基础71 XML解析中的【DOM和SAX解析工具】相关知识点(网页知识)的更多相关文章
- xml解析中的DOM和SAX的区别
面试题:DMO和SAX的区别? DOM解析的优点:增删查改操作方便,缺点:占用内存较大,不适合解析大的XML文件: SAX解析的优点:占用内存小,解析快:缺点:不适合增删查改:
- Java 中,DOM 和 SAX 解析器有什么不同?
DOM 解析器将整个 XML 文档加载到内存来创建一棵 DOM 模型树,这样可以 更快的查找节点和修改 XML 结构,而 SAX 解析器是一个基于事件的解析器, 不会将整个 XML 文档加载到内存.由 ...
- java基础58 JavaScript的几种格式和变量的声明方式(网页知识)
1.JavaScript的几种格式 1.1.JavaScript的特点 1.跨平台性 2.安全性.(javaScript代码不能直接访问电脑硬盘上的信息) 1.2.Java与javaScript ...
- java基础74 XML解析中的SAX解析相关知识点(网页知识)
1.SAX解析工具 SAX解析工具:是Sun公司提供的,内置JDK中.org.xml.sax.* 点击查看: DOM解析相关知识:以及DOM和SAX解析的原理(区别) 2.SAX解析的 ...
- Java SE之XML<二>XML DOM与SAX解析
[文档整理系列] Java SE之XML<二>XML DOM与SAX解析 XML编程:CRUD(Create Read Update Delete) XML解析的两种常见方式: DOM(D ...
- java基础之XML
目录 java基础之XML 1. XML解析概述 2. DOM4J介绍 2.1 常用包 2.2 内置元素 2.2 Element类 2.3 Attribute类 2.4 常用操作 3. 代码演示 3. ...
- schema文件及XML文件的DOM和Sax解析
schema文件 <?xml version="1.0" encoding="UTF-8"?> <schema xmlns="htt ...
- Java基础语法(8)-数组中的常见排序算法
title: Java基础语法(8)-数组中的常见排序算法 blog: CSDN data: Java学习路线及视频 1.基本概念 排序: 是计算机程序设计中的一项重要操作,其功能是指一个数据元素集合 ...
- JAXP进行DOM和SAX解析
1.常用XML的解析方式:DOM和SAX 1)DOM思想:将整个XML加载内存中,形成文档对象,所以对XML操作都对内存中文档对象进行. 2)SAX思想:一边解析,一边处理,一边释放内存资源---不允 ...
随机推荐
- 主动分布式WEB资产扫描
一. Redis的服务安装 系统环境:centos7x64 ip地址:192.168.1.11 1.设置静态IP地址 [root@localhost backlion]#vi /etc/sys ...
- SQL语句平时不注意的那些小知识点总结
一.Mybatis 动态sql 之<where>标签和<trim>标签 首先两个标签都可以实现这样的功能:做一个查询接口,有两个参数,当输入参数无论是一个还是两个或者不输入的时 ...
- bzoj5016 一个简单的询问
这种不可直接做的问题 数据范围又很小 考虑莫队 但是,l1,l2,r1,r2四维? 考虑把询问二维差分! f(a,b)表示,询问[1,a],[1, b]的答案 所以,ans(l1,r1,l2,y2)= ...
- Linux上给php配置redis扩展
说明,在项目开发中难免会遇到redis中,那我应该如何配置redis这样的一个扩展呢,看下面流程: 一.安装Redis PHP在安装redis扩展时,难免要看一下官网下载安装流程,链接如下: http ...
- Kubernetes Deloyment实现滚动更新
目录 滚动更新简介 使用kubectl rolling-update更新RC Deployment的rolling-update 滚动更新简介 当kubernetes集群中的某个服务需要升级时,传统的 ...
- 二叉树(前序,中序,后序,层序)遍历递归与循环的python实现
二叉树的遍历是在面试使比较常见的项目了.对于二叉树的前中后层序遍历,每种遍历都可以递归和循环两种实现方法,且每种遍历的递归实现都比循环实现要简洁.下面做一个小结. 一.中序遍历 前中后序三种遍历方法对 ...
- python---基础知识回顾(十一)图像处理模块PIL
前戏: 虽然PIL没有入OpenCV那样强大的功能,但是所提供的功能,在一般的图像处理中足够使用. 图像类别: 计算机绘图中有两类图像:一类是矢量图,另一类是点阵图(位图) 矢量图:基于计算机数字对象 ...
- clock()、time()、clock_gettime()和gettimeofday()函数的用法和区别
1. clock_gettime( ) 提供了纳秒的精确度 int clock_gettime(clockid_t clk_id, struct timespect *tp); clockid_t c ...
- bzoj千题计划132:bzoj1189: [HNOI2007]紧急疏散evacuate
http://www.lydsy.com/JudgeOnline/problem.php?id=1189 二分答案 源点向人连边,流量为1 门拆为mid个点,同一个门的第j个点向第j+1个点连边,流量 ...
- 【测试笔记】Redis学习笔记(十二)性能测试
http://blog.csdn.net/yangcs2009/article/details/50781530 Redis测试服务器一 redis_version:2.8.4 www@iZ23s8a ...