hadoop2.x学习笔记(一):YARN
一、YARN产生的背景
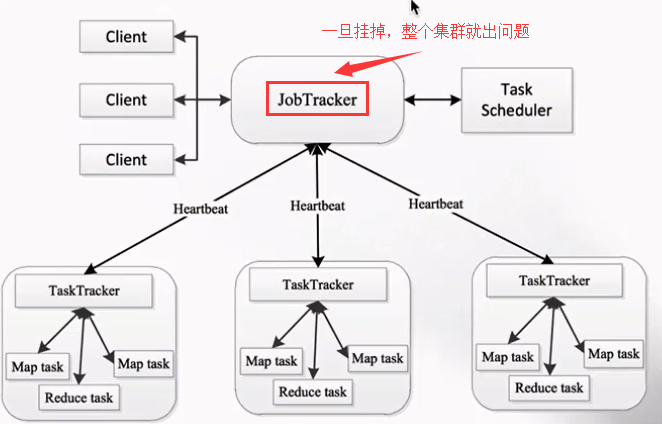
MapReduce1.x存在的问题:单点故障&节点压力大不易扩展。
资源利用率&成本
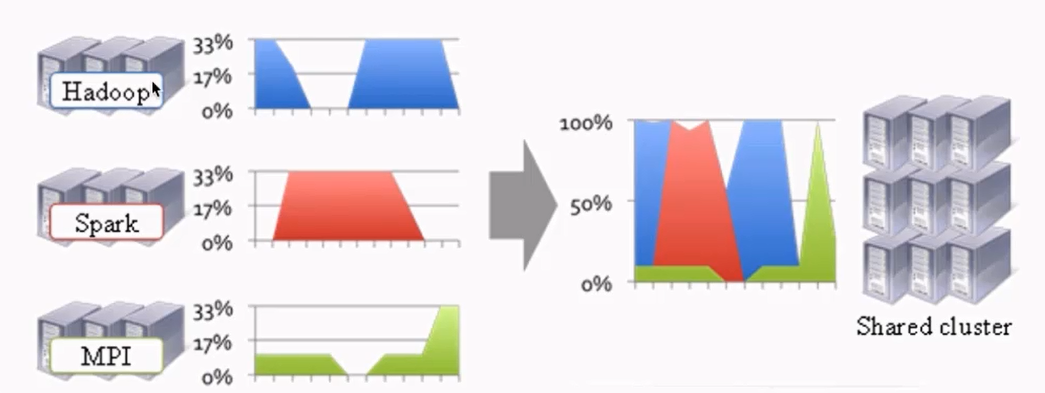
催生了YARN的诞生
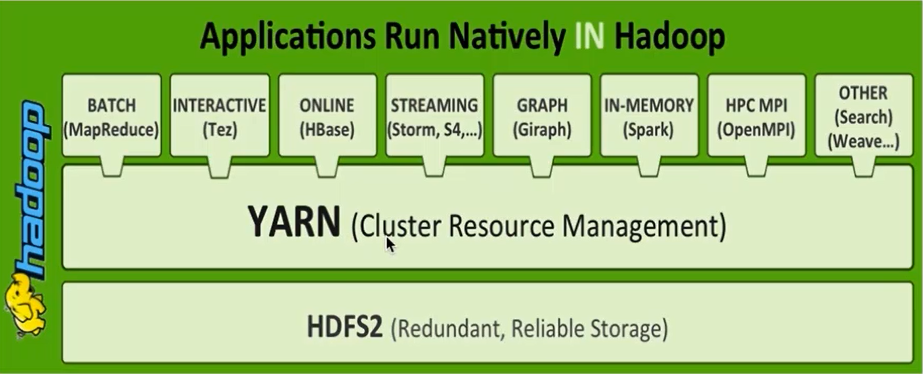
不同计算框架可以共享同一个HDFS集群上的数据,享受整体的资源调度。
XXX on YARN的好处:与其他计算框架共享集群资源,按资源需要分配,进而提高集群资源的利用率。
XXX:Spark/MapReduce/Storm/Flink
二、YARN概述
1 Yet Another Resource Negotiator
2 通用资源管理系统
3 为上层应用提供统一的资源管理和调度
三、YARN的架构
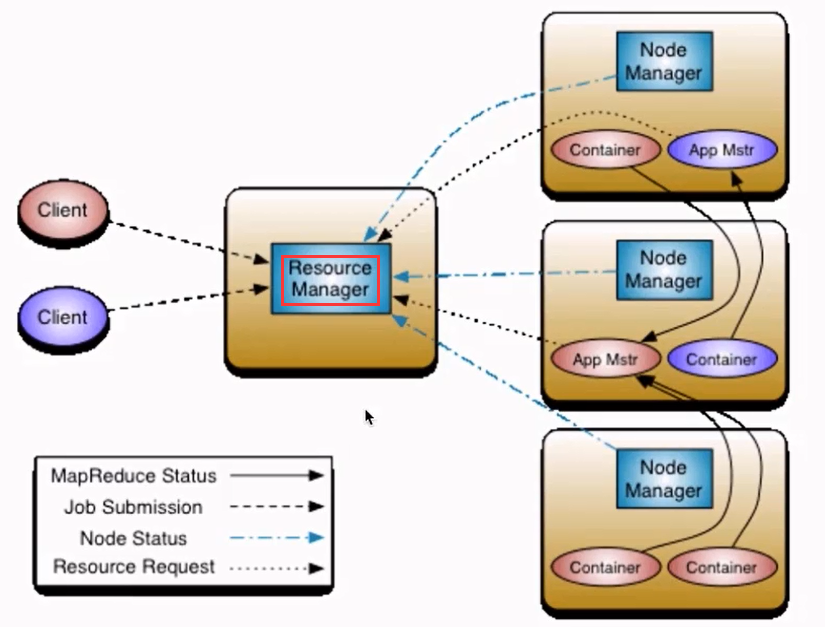
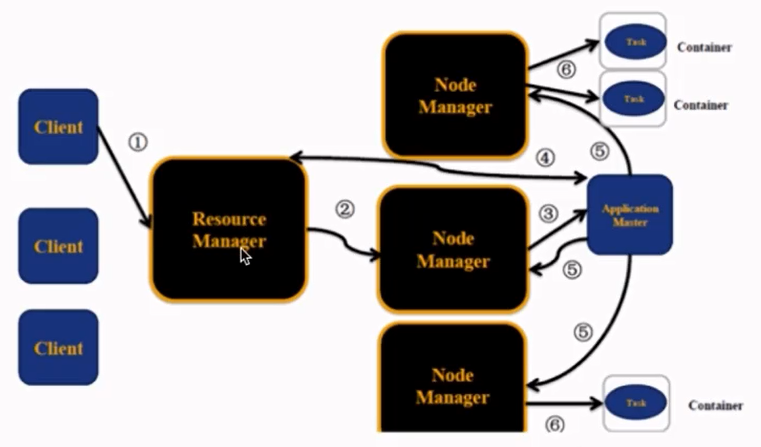
1 ResourceMananger:RM
整个集群提供服务的RM只有一个(生产中有两个,一个主,一个备),负责集群资源的统一管理和调度。
|-- 处理客户端的请求:提交一个作业、杀死一个作业。
|--监控NM,一旦某个NM挂了,那么该NM上运行的任务需要告诉AM如何进行处理。
2 NodeManager:NM
整个集群中有多个,负责自己本身节点资源管理和使用。
|--定时向RM汇报本节点的资源使用情况。
|--接收并处理来自RM的各种命令:启动Container等。
|--处理来自AM的命令。
|--单个节点的资源管理。
3 ApplicationMaster:AM
每一个应用程序对应一个:MR、Spark,负责应用程序的管理。
|--为每个应用程序向RM申请资源(core、memory),分配给内部task。
|--需要与NM通信:启动/停止task,task是运行在Container里面,AM也是运行在Container里面。
4 Container
|--封装了CPU、Memory等资源的一个容器
|--是一个任务运行环境的抽象。
5 Client
|--提交作业。
|--查询作业的运行进度。
|--杀死作业。
四、YARN执行流程
五、YARN的环境搭建
1 yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
2 mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3 启动YARN相关的进程
sbin/start-yarn.sh
4 验证
|-- jps
|--ResourceManager
|--NodeManager
|-- http://master01:8088/
5 停止YARN相关的进程
sbin/stop-yarn.sh
六、MapReduce作业提交到YARN上运行
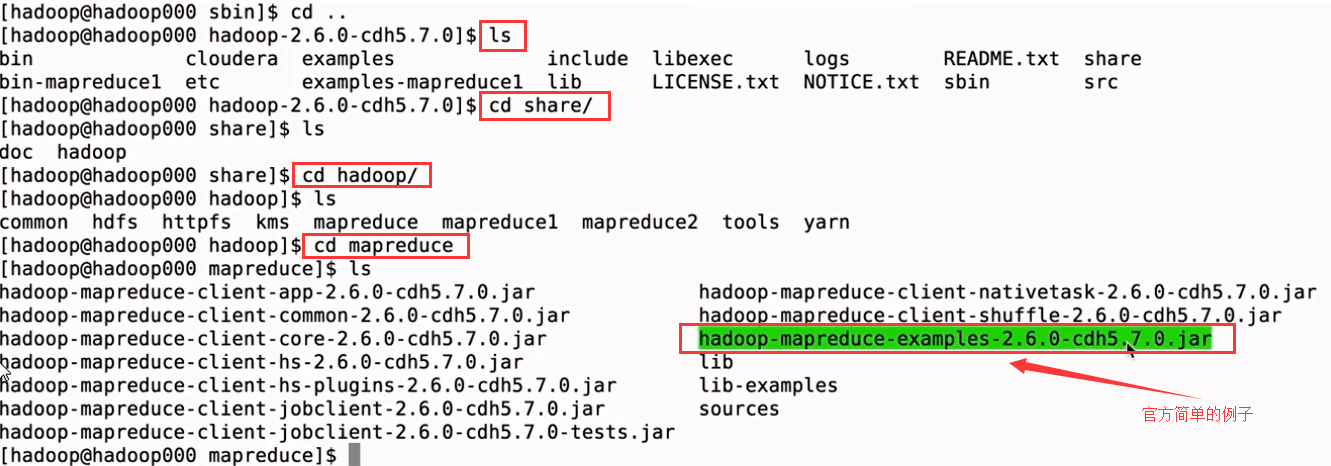
命令:
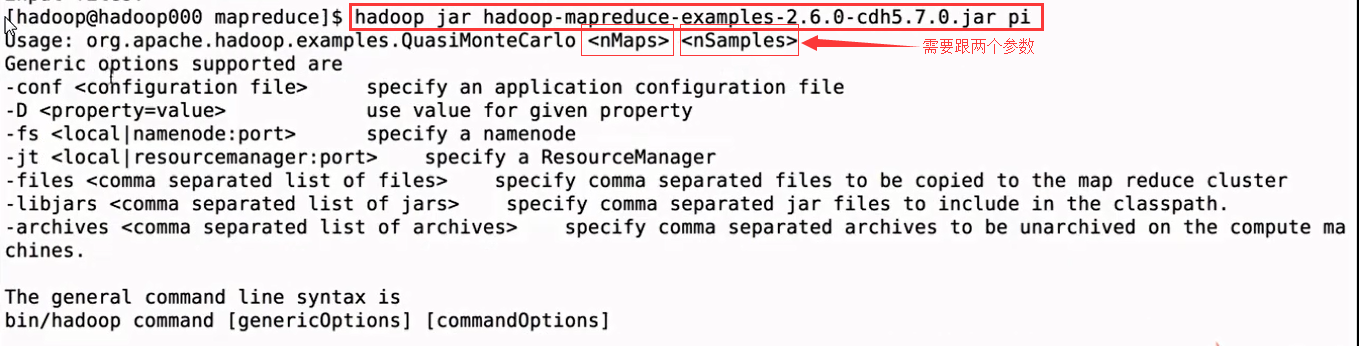
hadoop jar hadoop-mapreduce-examples-2.6.-cdh5.7.0.jar pi 2 3 //前者是Map的数量,后者是取样的数量
hadoop2.x学习笔记(一):YARN的更多相关文章
- 二十六、Hadoop学习笔记————Hadoop Yarn的简介复习
1. 介绍 YARN(Yet Another Resource Negotiator)是一个通用的资源管理平台,可为各类计算框架提供资源的管理和调度. 之前有提到过,Yarn主要是为了减轻Hadoop ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Node.js学习笔记(4):Yarn简明教程
Node.js学习笔记(4):Yarn简明教程. 引入Yarn NPM是常用的包管理工具,现在我们引入是新一代的包管理工具Yarn.其具有快速.安全.可靠的特点. 安装方式 使用npm工具安装yarn ...
- Hadoop学习笔记—21.Hadoop2的改进内容简介
Hadoop2相比较于Hadoop1.x来说,HDFS的架构与MapReduce的都有较大的变化,且速度上和可用性上都有了很大的提高,Hadoop2中有两个重要的变更: (1)HDFS的NameNod ...
- 分布式计算框架学习笔记--hadoop工作原理
(hadoop安装方法:http://blog.csdn.net/wangjia55/article/details/53160679这里不再累述) hadoop是针对大数据设计的一个计算架构.如果你 ...
- Hadoop学习笔记01_Hadoop搭建
想往大数据方向转, 难度肯定是有的. 基础知识肯定是要有的,如果是熟悉JAVA开发的人,转向应该优势大. 像我这样的,只有Linux基础以及简单的PHP基础的人,转向难度很大.但是事在人为,努力学习多 ...
- hadoop之HDFS学习笔记(二)
主要内容:hdfs的核心工作原理:namenode元数据管理机制,checkpoint机制:数据上传下载流程 1.hdfs的核心工作原理 1.1.namenode元数据管理要点 1.什么是元数据? h ...
- HBase学习笔记之HBase的安装和配置
HBase学习笔记之HBase的安装和配置 我是为了调研和验证hbase的bulkload功能,才安装hbase,学习hbase的.为了快速的验证bulkload功能,我安装了一个节点的hadoop集 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
随机推荐
- SQL笔记---分页
随用随想,随用随记. 通过实际应用掌握SQL语句. 一. SQL分页 1. 第一种方法:利用ID大于多少进行筛选 SELECT TOP 20 *FROM dbo.WMS_Stock ...
- Linq to SQL 参考Demo
LINQ to SQL语句()之Where Where操作 适用场景:实现过滤,查询等功能. 说明:与SQL命令中的Where作用相似,都是起到范围限定也就是过滤作用的,而判断条件就是它后面所接的子句 ...
- deepin mysql安装
1.安装mysql 更新仓库:sudo apt-get update 安装:sudo apt-get install mysql-server mysql-client 问题:安装mysql5. ...
- 设置oracle主键自增长
创建test表后,创建序列: CREATE sequence seq_test INCREMENT BY 1 START WITH 1 minvalue 1 成功后,插入一条语句进行测试: I ...
- 认识与学习shell
linux的终端机执行命令的方式,是通过bash环境来处理的.bash包括变量的设置与使用,.bash操作环境的构建.数据流重定向的功能.下面的知识,对主机的维护与管理有重要的帮助. 管理整个计算机硬 ...
- Sentinel 哨兵 实现redis高可用
本文链接:http://www.cnblogs.com/zhenghongxin/p/8885879.html 我们知道redis是有主从复制的,例如下图: 但如果master主进程挂掉之后,没有sl ...
- python学习笔记6-集合
# 集合是无序且不可重复的元素的集合 a = set([1,3,1,3,3,2,2,5]) a # {1, 2, 3, 5} b = set(range(2,5)) b # {2, 3, 4} # 1 ...
- SQL一些问题
什么是索引: 一般说法:索引是与表关联的磁盘上结构,可以加快从表中检索行的速度.索引包含由表中的一列或多列生成的键.这些键存储在一个结构中,使 SQL Server 可以快速有效地查找与键值关联的行. ...
- java程序连接hive数据库遇到的问题
今天,打算学习一下用hadoop做后台,搭建一个网站,首先第一步便是在本机的eclipse中连接到虚拟机上的hive中,原本以为很简单,但是过程很是艰难.特意做总结 首先hive的版本问题就是一个很大 ...
- 异步加载的JS如何在chrome浏览器断点调试?
我们常常利用chrome强大的控制台Sources下面进行代码断点调试,但是通过$.getScript等异步加载JS的方式在Sources里面就是找不到,那如何进行debug断点调试呢? 方案一: 在 ...