一文看尽 Raft 一致性协议的关键点
本文由 网易云 发布。
作者:孙建良
Raft 协议的发布,对分布式行业是一大福音,虽然在核心协议上基本都是师继 Paxos 祖师爷(Lamport) 的精髓,基于多数派的协议。但是 Raft 一致性协议的贡献在于,定义了可易于实现的一致性协议的事实标准。把一致性协议从 “阳春白雪” 变成了让普通学生、IT 码农等都可以上手试一试玩一玩的东西,MIT 的分布式教学课程 6.824 都是直接使用 Raft 来介绍一致性协议。
从论文In Search of An Understandable Consensus Algorithm (Extend Version)中,我们可以看到,与其他一致性协议论文不同的是,Diego 基本已经算是把一个易于工程实现的算法讲得非常明白了,just do it,没有太多争议和发挥的空间,即便如此,要实现一个工业级的靠谱的 Raft 还是要花不少力气。
Raft 一致性协议相对来说易于实现主要归结为以下几个原因:
- 模块化的拆分:把一致性协议划分为 Leader 选举、MemberShip 变更、日志复制、SnapShot 等相对比较解耦的模块;
- 设计的简化:比如不允许类似 Paxos 算法的乱序提交、使用 Randomization 算法设计 Leader Election 算法以简化系统的状态,只有 Leader、Follower、Candidate 等等。
本文不打算对 Basic Raft 一致性协议的具体内容进行说明,而是介绍记录一些关键点,因为绝大部分内容原文已经介绍的很详实,有兴趣的读者还可把 Raft 作者 Diego Ongaro 200 多页的博士论文刷一遍(链接在文末,可自取)。
Old Term LogEntry 处理
旧 Term 未提交日志的提交依赖于新一轮的日志的提交
这个在原文 “5.4.2 Committing entries from previews terms” 有说明,但是在看的时候可能会觉得有点绕。
Raft 协议约定,Candidate 在使用新的 Term 进行选举的时候,Candidate 能够被选举为 Leader 的条件为:
- 得到一半以上(包括自己)节点的投票;
- 得到投票的前提是:Candidate 节点的最后一个LogEntry 的 Term 比投票节点大,或者在 Term 一样情况下,LogEnry 的 SN (serial number) 必须大于等于投票者。
并且有一个安全截断机制:
- Follower 在接收到 logEntry 的时候,如果发现发送者节点当前的 Term 大于等于 Follower 当前的 Term;并且发现相同序号的(相同 SN)LogEntry 在 Follower 上存在,未 Commit,并且 LogEntry Term 不一致,那么 Follower 直接截断从 (SN~文件末尾)的所有内容,然后将接收到的 LogEntryAppend 到截断后的文件末尾。
在以上条件下,Raft 论文列举了一个 Corner Case ,如下图所示:
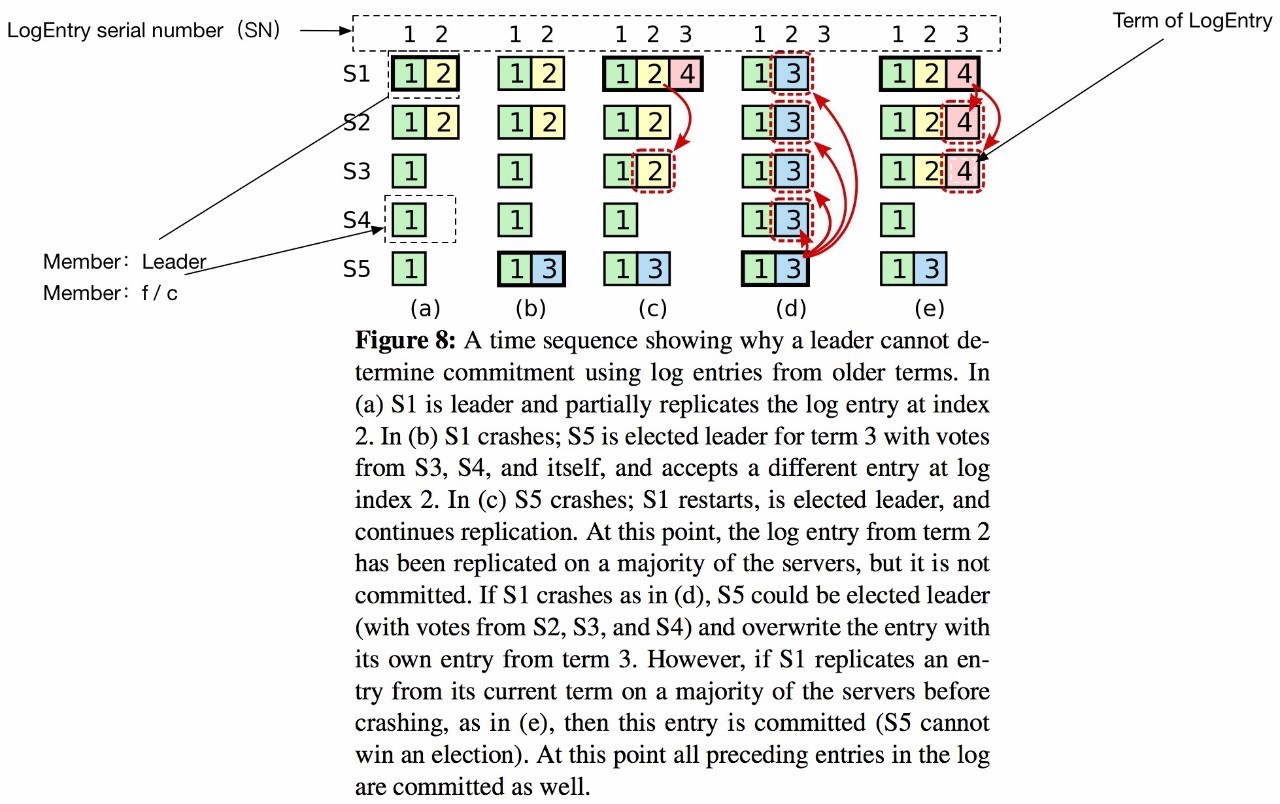
- (a):S1 成为 Leader,Append Term2 的LogEntry(黄色)到 S1、S2 成功;
- (b):S1 Crash,S5 使用 Term(3) 成功竞选为 Term(3) 的 Leader(通过获得 S3、S4、S5 的投票),并且将 Term 为 3 的 LogEntry(蓝色) Append 到本地;
- (c):S5 Crash, S1 使用 Term(4) 成功竞选为Leader(通过获得 S1、S2、S3 的投票),将黄色的 LogEntry 复制到 S3,得到多数派响应(S1、S2、S3) 的响应,提交黄色 LogEntry 为 Commit,并将 Term 为 4 的 LogEntry (红色) Append 到本地;
- (d) :S5 使用新的 Term(5) 竞选为 Leader (得到 S2、S3、S4 的投票),按照协议将所有所有节点上的黄色和红色的 LogEntry 截断覆盖为自己的 Term 为 3 的 LogEntry。
进行到这步的时候我们已经发现,黄色的 LogEnry(2) 在被设置为 Commit 之后重新又被否定了。
所以协议又强化了一个限制:
- 只有当前 Term 的 LogEntry 提交条件为:满足多数派响应之后(一半以上节点 Append LogEntry 到日志)设置为 commit;
- 前一轮 Term 未 Commit 的 LogEntry 的 Commit 依赖于高轮 Term LogEntry 的 Commit。
如图所示 (c) 状态 Term2 的 LogEntry(黄色) 只有在 (e)状态 Term4 的 LogEntry(红色)被 commit 才能够提交。
提交 NO-OP LogEntry 提交系统可用性
在 Leader 通过竞选刚刚成为 Leader 的时候,有一些等待提交的 LogEntry (即 SN > CommitPt 的 LogEntry),有可能是 Commit 的,也有可能是未 Commit 的(PS: 因为在 Raft 协议中 CommitPt 不用实时刷盘)。
所以为了防止出现非线性一致性(Non Linearizable Consistency);即之前已经响应客户端的已经 Commit 的请求回退,并且为了避免出现上图中的 Corner Case,往往我们需要通过下一个 Term 的 LogEntry 的 Commit 来实现之前的 Term 的 LogEntry 的 Commit (隐式commit),才能保障提供线性一致性。
但是有可能接下来的客户端的写请求不能及时到达,那么为了保障 Leader 快速提供读服务,系统可首先发送一个 NO-OP LogEntry 来保障快速进入正常可读状态。
Current Term、VotedFor 持久化
上图其实隐含了一些需要持久化的重要信息,即 Current Term、VotedFor! 为什么(b) 状态 S5 使用的 Term Number 为 3,而不是 2?
因为竞选为 Leader 就必须是使用新的 Term 发起选举,并且得到多数派阶段的同意,同意的操作为将 Current Term、VotedFor 持久化。
比如(a) 状态 S1 为什么能竞选为 Leader?首先 S1 满足成为 Leader 的条件,S2~S5 都可以接受 S1 成为发起 Term 为 2 的 Leader 选举。S2~S5 同意 S1 成为 Leader 的操作为:将 Current Term 设置为 2、VotedFor 设置为 S1 并且持久化,然后返回 S1。即 S1 成功成为 Term 为 2 的 Leader 的前提是一个多数派已经记录 Current Term 为 2 ,并且 VotedFor 为 S1。那么 (b) 状态 S5 如使用 Term 为 2 进行 Leader 选举,必然得不到多数派同意,因为 Term 2 已经投给 S1,S5 只能 将 Term++ 使用Term 为3 进行重新发起请求。
Current Term、VotedFor 如何持久化?
type CurrentTermAndVotedFor {
Term int64 `json:"Term"`
VotedFor int64 `json:"Votedfor"`
Crc int32
}
//current state
var currentState CurrentTermAndVotedFor
.. set value and calculate crc ...
content, err := json.Marshal(currentState)
//flush to disk
f, err := os.Create("/dist/currentState.txt")
f.Write(content)
f.Sync()
简单的方法,只需要保存在一个单独的文件,如上为简单的 go 语言示例;其他简单的方式比如在设计 Log File 的时候,Log File Header 中包含 Current Term 以及 VotedFor 的位置。
如果再深入思考一层,其实这里头有一个疑问?如何保证写了一半(写入一半然后挂了)的问题?写了 Term、没写 VoteFor?或者只写了 Term 的高 32 位?
可以看到磁盘能够保证 512 Byte 的写入原子性,这个在知乎 事务性 (Transactional)存储需要硬件参与吗?这个问答上就能找到答案。所以最简单的方法是直接写入一个 tmpfile,写入完成之后,将 tmpfile mv 成CurrentTermAndVotedFor 文件,基本可保障更新的原子性。其他方式比如采用 Append Entry 的方式也可以实现。
Cluser Membership 变更
在 Raft 的 Paper 中,简要说明了一种一次变更多个节点的 Cluser Membership 变更方式。但是没有给出更多的在 Security 以及 Avaliable 上的更多的说明。
其实现在开源的 Raft 实现一般都不会使用这种方式,比如 Etcd raft 都是采用了更加简洁的一次只能变更一个节点的 “single Cluser MemberShip Change” 算法。
当然 single cluser MemberShip 并非 Etcd 自创,其实 Raft 协议作者 Diego 在其博士论文中已经详细介绍了 Single Cluser MemberShip Change 机制,包括 Security、Avaliable 方面的详细说明,并且作者也说明了在实际工程实现过程中更加推荐 Single 方式,首先因为简单,再则所有的集群变更方式都可以通过 Single 一次一个节点的方式达到任何想要的 Cluster 状态。
Raft restrict the types of change that allowed: only one server can be added or removed from the cluster at once. More complex changes in membership are implemented as a series of single-server-change.
Safty
回到问题的第一大核心要点:Safety,membership 变更必须保持 Raft 协议的约束:同一时间(同一个 Term)只能存在一个有效的 Leader。
为什么不能直接变更多个节点,直接从 Old 变为 New 有问题? for example change from 3 Node to 5 Node?
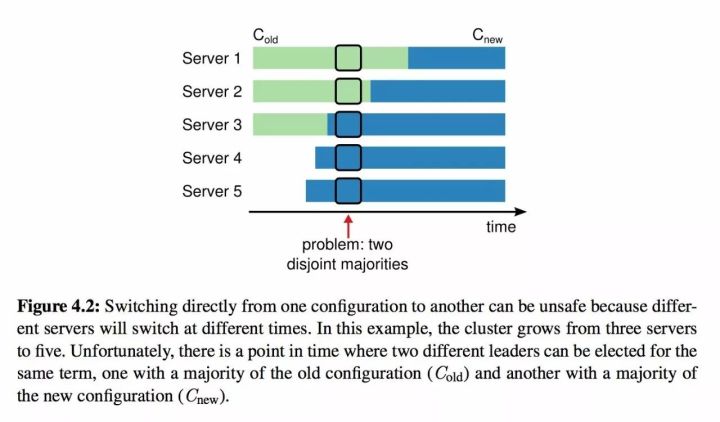
如上图所示,在集群状态变更过程中,在红色箭头处出现了两个不相交的多数派(Server3、Server4、Server 5 认知到新的 5 Node 集群;而 1、2 Server 的认知还是处在老的 3 Node 状态)。在网络分区情况下(比如 S1、S2 作为一个分区;S3、S4、S5 作为一个分区),2个分区分别可以选举产生2个新的 Leader(属于configuration< Cold>的 Leader 以及 属于 new configuration < Cnew > 的 Leader) 。
当然这就导致了 Safty 没法保证;核心原因是对于 Cold 和 CNew 不存在交集,不存在一个公共的交集节点充当仲裁者的角色。
但是如果每次只允许出现一个节点变更(增加 or 减小),那么 Cold 和 CNew 总会相交。 如下图所示:
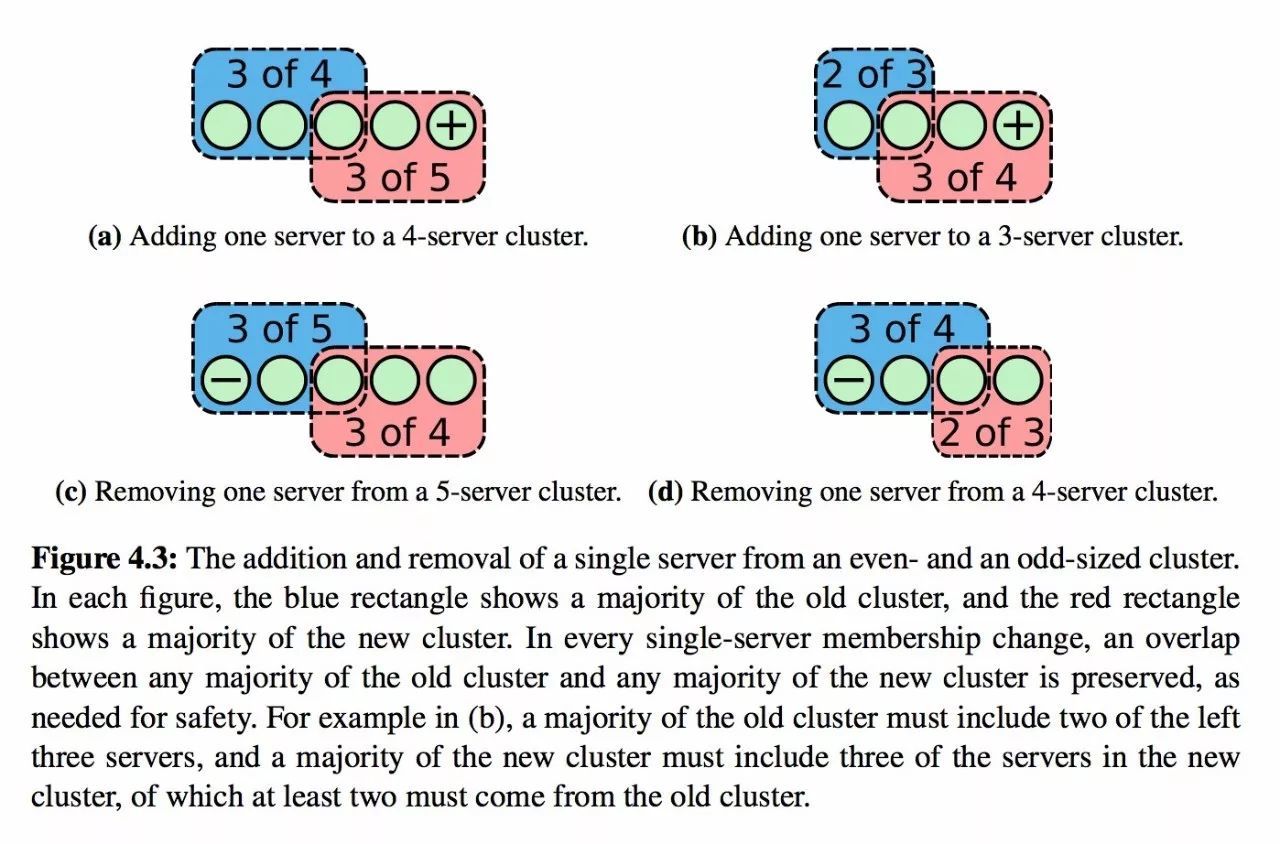
如何实现 Single membership change
论文中提以下几个关键点:
- 由于 Single 方式无论如何 Cold 和 CNew 都会相交,所以 Raft 采用了直接提交一个特殊的 replicated LogEntry 的方式来进行 single 集群关系变更。
- 跟普通的 LogEntry 提交的不同点,configuration LogEntry 不需要 commit 就生效,只需要 append 到 Log 中即可。( PS: 原文 “The New configuration takes effect on each server as soon as it is added to the server’s log”)。
- 后一轮 MemberShip Change 的开始必须在前一轮 MemberShip Change Commit 之后进行,以避免出现多个 Leader 的问题。

- 关注点 1
如图所示,如在前一轮 membership configure Change 未完成之前,又进行下一次 membership change 会导致问题,所以外部系统需要确保不会在第一次 Configuration 为成功情况下,发起另外一个不同的 Configuration 请求。( PS:由于增加副本、节点宕机丢失节点进行数据恢复的情况都是由外部触发进行的,只要外部节点能够确保在前一轮未完成之前发起新一轮请求,即可保障。)
- 关注点 2
跟其他客户端的请求不一样的,Single MemberShip Change LogEntry 只需要 Append 持久化到 Log(而不需要 commit)就可以应用。
一方面是可用性的考虑,如下所示:Leader S1 接收到集群变更请求将集群状态从(S1、S2、S3、S4)变更为 (S2、S3、S4);提交到所有节点之后 commit 之后,返回客户端集群状态变更完成(如下状态 a),S1 退出(如下状态b);由于 Basic Raft 并不需要 commit 消息实施传递到其他 S1、S2、S3 节点,S1 退出之后,S1、S2、S3 由于没有接收到 Leader S1 的心跳,导致进行选举,但是不幸的是 S4 故障退出。假设这个时候 S2、S3 由于 Single MemberShip Change LogEntry 没有 Commit 还是以(S1、S2、S3、S4)作为集群状态,那么集群没法继续工作。但是实质上在(b)状态 S1 返回客户端集群状态变更请求完成之后,实质上是认为可独立进入正常状态。

另一方面,即使没有提交到一个多数派,也可以截断,没什么问题。(这里不多做展开)
另一方面是可靠性&正确性。Raft 协议 Configuration 请求和普通的用户写请求是可以并行的,所以在并发进行的时候,用户写请求提交的备份数是无法确保是在 Configuration Change 之前的备份数还是备份之后的备份数。但是这个没有办法,因为在并发情况下本来就没法保证,这是保证 Configuration 截断系统持续可用带来的代价。(只要确保在多数派存活情况下不丢失即可(PS:一次变更一个节点情况下,返回客户端成功,其中必然存在一个提交了客户端节点的 Server 被选举为Leader)。
- 关注点 3
Single membership change 其他方面的 safty 保障是跟原始的 Basic Raft 是一样的(在各个协议处理细节上对此类请求未有任何特殊待遇),即只要一个多数派(不管是新的还是老的)将 single membership change 提交并返回给客户端成功之后,接下来无论节点怎么重启,都会确保新的 Leader 将会在已经知晓(应用)新的,前一轮变更成功的基础上处理接下来的请求:可以是读写请求、当然也可以是新的一轮 Configuration 请求。
初始状态如何进入最小备份状态
比如如何进入3副本的集群状态。可以使用系统元素的 Single MemberShip 变更算法实现。
刚开始节点的副本状态最简单为一个节点 1(自己同意自己非常简单),得到返回之后,再选择添加一个副本,达到 2个副本的状态。然后再添加一个副本,变成三副本状态,满足对系统可用性和可靠性的要求,此时该 Raft 实例可对外提供服务。
其他需要关注的事项
- servers process incoming RPC requests without consulting their current configurations. server 处理在 AppendEntries & Voting Request 的时候不用考虑本地的 configuration 信息。
- CatchUp:为了保障系统的可靠性和可用性,加入 no-voting membership 状态,进行 CatchUp,需要加入的节点将历史 LogEntry 基本全部 Get 到之后再发送 Configuration。
- Disruptive serves:为了防止移除的节点由于没有接收到新的 Leader 的心跳,而发起 Leader 选举而扰绕当前正在进行的集群状态。集群中节点在 Leader 心跳租约期间内收到 Leader 选举请求可以直接 Deny。(PS:对于一些确定性的事情,比如发现 Leader listen port reset,可以发起强制 Leader 选举的请求)。
参考文献
了解 网易云 :
网易云官网:https://www.163yun.com/
新用户大礼包:https://www.163yun.com/gift
网易云社区:https://sq.163yun.com/
一文看尽 Raft 一致性协议的关键点的更多相关文章
- 一文带你了解 Raft 一致性协议的关键点
此文已由作者孙建良授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. Raft 协议的发布,对分布式行业是一大福音,虽然在核心协议上基本都是师继 Paxos 祖师爷(lampor ...
- Raft 一致性协议算法 《In search of an Understandable Consensus Algorithm (Extended Version)》
<In search of an Understandable Consensus Algorithm (Extended Version)> Raft是一种用于管理日志复制的一致性算 ...
- Raft一致性协议
分布式存储系统通常通过维护多个副本来进行fault-tolerance,提高系统的availability,带来的代价就是分布式存储系统的核心问题之一:维护多个副本的一致性.一致性协议就是用来干这事的 ...
- 分布式一致性协议Raft原理与实例
分布式一致性协议Raft原理与实例 1.Raft协议 1.1 Raft简介 Raft是由Stanford提出的一种更易理解的一致性算法,意在取代目前广为使用的Paxos算法.目前,在各种主流语言中都有 ...
- 分布式一致性协议之:Raft算法
一致性算法Raft详解 背景 熟悉或了解分布性系统的开发者都知道一致性算法的重要性,Paxos一致性算法从90年提出到现在已经有二十几年了,而Paxos流程太过于繁杂实现起来也比较复杂,可能也是以为过 ...
- 分布式一致性协议 Raft
分布式领域,CP模型下 数据一致性协议至关重要,不然两边数据不一致容易出现数据读混乱问题.像Etcd Consul zookeeper Eureka ,Redis集群方案这些中间件 都有一致性算法来 ...
- 搞懂分布式技术2:分布式一致性协议与Paxos,Raft算法
搞懂分布式技术2:分布式一致性协议与Paxos,Raft算法 2PC 由于BASE理论需要在一致性和可用性方面做出权衡,因此涌现了很多关于一致性的算法和协议.其中比较著名的有二阶提交协议(2 Phas ...
- [转帖]分布式一致性协议介绍(Paxos、Raft)
分布式一致性协议介绍(Paxos.Raft) https://www.cnblogs.com/hugb/p/8955505.html 两阶段提交 Two-phase Commit(2PC):保证一个 ...
- 浅谈 Raft 分布式一致性协议|图解 Raft
前言 本篇文章将模拟一个KV数据读写服务,从提供单一节点读写服务,到结合分布式一致性协议(Raft)后,逐步扩展为一个分布式的,满足一致性读写需求的读写服务的过程. 其中将配合引入Raft协议的种种概 ...
随机推荐
- 使用Spring+Junit4进行测试
前言 单元测试是一个程序员必备的技能,我在这里就不多说了,直接就写相应的代码吧. 单元测试基础类 import org.junit.runner.RunWith; import org.springf ...
- 在ecplise中创建一个maven工程
1.我们首先需要在Ecplise中配置maven环境,详情见我的博客:https://www.cnblogs.com/wyhluckdog/p/10277278.html 2.maven projec ...
- Mybatis Blob和String互转,实现文件上传等。
这样的代码网上有很多,但是本人亲测有bug, 下面是我写的代码.望参考 @MappedJdbcTypes(JdbcType.BLOB) public class BlobAndStringTypeHa ...
- JSONModel简便应用
JSONModel, Mantle 这两个开源库都是用来进行封装JSON->Model的, 想想看, 直接向服务器发起一个请求,然后回来后,就是一个Model, 直接使用, 这是一个多么美好的事 ...
- AJAX初尝试——ACM/ICPC类比赛气球管理系统
很早之前做过一个,白板没界面,20秒暴力刷新,数据库每个team一个n列的对应n个题目的标记项,只能对单个比赛暴力把全部user_id导入单独的气球表(也就是cid=1000用这个表的话,cid100 ...
- android触控,先了解MotionEvent(一)
http://my.oschina.net/banxi/blog/56421 这是我个人的看法,要学好android触控,了解MotionEvent是必要,对所用的MotionEvent常用的API要 ...
- devart 放大招了
前面我纪念BDE 的文章里面说过,devart 会在今后在数据库存取技术上会有更大的 进步,没想到很快devart 放大招了.在最新的unidac 和sdac 中,devart 支持在非Windows ...
- 用Java操作数据库Datetime数据
Date.Calendar.Timestamp的区别.相互转换与使用 1 Java.util.Date 包含年.月.日.时.分.秒信息. // String转换为Date String dateStr ...
- I2C总线驱动框架详解
一.I2C子系统总体架构 1.三大组成部分 (1)I2C核心(i2c-core):I2C核心提供了I2C总线驱动(适配器)和设备驱动的注册.注销方法,I2C通信方法(”algorithm”)上层的,与 ...
- "请求被中止: 未能创建 SSL/TLS 安全通道"解决办法
1.安装证书: 手动双击证书安装,过程略 2.分配权限: 在控制台中找到安装的证书,右键选择“管理私钥”, 添加自己需要的权限,如果在测试可以直接添加Everyone 3.修改代码:public st ...