豆瓣电影top250爬取并保存在MongoDB里
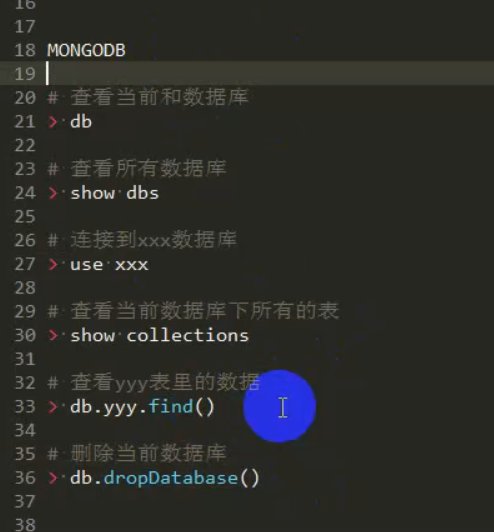
首先回顾一下MongoDB的基本操作:
数据库,集合,文档
db,show dbs,use 数据库名,drop 数据库
db.集合名.insert({})
db.集合名.update({条件},{$set:{}},{multi:true})
db.集合名.remove({条件})
db集合名.find({条件},{投影}).limit().skip().sort().count().distinct() 数据库 增加 修改 删除 查询
mysql insert update delete select
redis set set del get
mongodb insert update remove find,aggregate
string
hash
list
set
zset
增加
mysql:insert into 表名(列) values(值)
mongo:db.集合名.insert({})
修改:
mysql:update 表名 set 列=值 where 条件
mongo:db.集合名.update({条件},{值$set},{是否修改多条})
删除:
mysql:delete from 表名 where ....
mongo:db.集合名.remove({条件},{是否删除多条})
查询:
db.stu.find({},{})
比较运算符,逻辑运算符,$where
limit(),skip(),sort(),count(),distinct()
首先使用xpath提取出要爬取的信息:我们这个项目需要爬取的信息有:标题,信息,评分,简介
第一页链接:https://movie.douban.com/top250
第二页链接:https://movie.douban.com/top250?start=25&filter=
第三页链接:https://movie.douban.com/top250?start=50&filter=
规律:https://movie.douban.com/top250?start=\d+&filter=
标题://a/span[@class="title"][1]
信息://div[@class="bd"]/p[1]/text()
评分://div[@class="star"]/span[2]/text()
简介://span[@class="inq"]/text()
然后使用sscrapy startproject douban 创建项目
sscrapy genspider dopuban movie.douban.com
然后依次编写下面的文件:
items.py
doubanmovie.py
settings.py
pipelines.py
豆瓣电影top250爬取并保存在MongoDB里的更多相关文章
- 豆瓣电影信息爬取(json)
豆瓣电影信息爬取(json) # a = "hello world" # 字符串数据类型# b = {"name":"python"} # ...
- 5分钟掌握智联招聘网站爬取并保存到MongoDB数据库
前言 本次主题分两篇文章来介绍: 一.数据采集 二.数据分析 第一篇先来介绍数据采集,即用python爬取网站数据. 1 运行环境和python库 先说下运行环境: python3.5 windows ...
- Scrapy教程--豆瓣电影图片爬取
一.先上效果 二.安装Scrapy和使用 官方网址:https://scrapy.org/. 安装命令:pip install Scrapy 安装完成,使用默认模板新建一个项目,命令:scrapy s ...
- python2.7爬取豆瓣电影top250并写入到TXT,Excel,MySQL数据库
python2.7爬取豆瓣电影top250并分别写入到TXT,Excel,MySQL数据库 1.任务 爬取豆瓣电影top250 以txt文件保存 以Excel文档保存 将数据录入数据库 2.分析 电影 ...
- python2.7抓取豆瓣电影top250
利用python2.7抓取豆瓣电影top250 1.任务说明 抓取top100电影名称 依次打印输出 2.网页解析 要进行网络爬虫,利用工具(如浏览器)查看网页HTML文件的相关内容是很有必要,我使用 ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- 利用python2.7正则表达式进行豆瓣电影Top250的网络数据采集及MySQL数据库操作
转载请注明出处 利用python2.7正则表达式进行豆瓣电影Top250的网络数据采集 1.任务 采集豆瓣电影名称.链接.评分.导演.演员.年份.国家.评论人数.简评等信息 将以上数据存入MySQL数 ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- 【转】爬取豆瓣电影top250提取电影分类进行数据分析
一.爬取网页,获取需要内容 我们今天要爬取的是豆瓣电影top250页面如下所示: 我们需要的是里面的电影分类,通过查看源代码观察可以分析出我们需要的东西.直接进入主题吧! 知道我们需要的内容在哪里了, ...
随机推荐
- Anychart隐藏属性
一.嵌入字体的使用 font标签可以使用嵌入字体,只需加入embed="true"即可.
- 记录:springmvc + mybatis + maven 搭建配置流程
前言:不会配置 spring mvc,不知道为什么那样配置,也不知道从何下手,那么看这里就对了. 在 IDEA 中搭建 maven + springmvc + mybatis: 一.在 IDEA 中首 ...
- centos7下安装sublime text3并配置环境变量
注意:我解压完把sublime_text全改成了sublime,如果未改就是sublime_text 1.官网下载sublime,保存到指定目录,例如/home 2.解压 tar xjf sublim ...
- js中list 和 map还有string的部分操作
1.创建list或者数组 var list = []; list中添加元素:list.push("hello"); 如果没有先定义为数组类型不能使用 push方法 判断list ...
- opencv3.2.0形态学滤波之膨胀
//名称:膨胀 //日期:12月21日 //平台:QT5.7.1+opencv3.2.0 /* 膨胀(dilate)的含义: 膨胀就是求局部最大值的操作,就是将图像(或图像的一部分,A)与核 B 进行 ...
- Spring Boot—13事务支持
pom.xml <dependency> <groupId>org.springframework.boot</groupId> <artifactId> ...
- 如何优雅使用Coursera ? —— Coursera 视频缓冲 & 字幕遮挡
Coursera 视频缓冲 其实这个问题的根本是coursera上视频源d3c33hcgiwev3.cloudfront.net被墙,而ss的pac并未及时更新所导致的. 1 chrome 插件 - ...
- 打开struts-config.xml 报错 解决方法Could not open the editor
打开struts-config.xml 报错 解决办法Could not open the editor 错误信息:Could not open the editor: Project XXX is ...
- 设置 ExpressRoute 和站点到站点并存连接
配置站点到站点 VPN 和 ExpressRoute 共存连接具有多项优势. 可以将站点到站点 VPN 配置为 ExressRoute 的安全故障转移路径,或者使用站点到站点 VPN 连接到不是通过 ...
- [翻译] AFDropdownNotification
AFDropdownNotification Dropdown notification view for iOS. 下拉通知的view,用于iOS. Installation - 安装 If you ...