pandas实战——对星巴克数据的分析
一、实验对象
实验对象为星巴克在全球的门店数据,我们可以使用pandas对其进行简单的分析,如分析每个国家星巴克的数量,根据门店数量对国家进行排序等。
二、数据分析
1、读取数据并获取数据行列数
首先读取数据:
import numpy as npimport pandas as pdstarbucks = pd.read_csv("D:\\directory.csv")print "数据的列标签如下:"print starbucks.columnsprint "每列的数据类型:"print starbucks.dtypesprint "文件行数:"print len(starbucks.index)print "文件列数:"print starbucks.columns.size
输出:
数据的列标签如下:Index([u'Brand', u'Store Number', u'Store Name', u'Ownership Type',u'Street Address', u'City', u'State/Province', u'Country', u'Postcode',u'Phone Number', u'Timezone', u'Longitude', u'Latitude'],dtype='object')每列的数据类型:Brand objectStore Number objectStore Name objectOwnership Type objectStreet Address objectCity objectState/Province objectCountry objectPostcode objectPhone Number objectTimezone objectLongitude float64Latitude float64dtype: object文件行数:25600文件列数:13
可以看到文件共有25600条数据,每条数据有13列。
2、查看数据
#查看文件的前五行数据print starbucks.head()
输出:
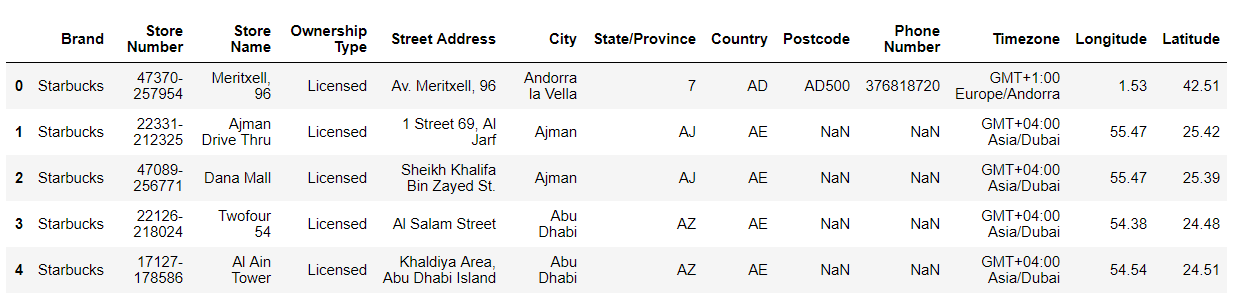
可以通过DataFrame.head(n)来获取数据帧的前n行数据,未指定n则返回前5行,同样的函数还有DataFrame.tail(n)。上图中有些数据为NaN,如果NaN对数据处理有影响的话可以使用DataFrame.fillna(value)将NaN替换成value,或者使用DataFrame.dropna()删除含有NaN的行。本文将不对NaN做处理。
3、按照星巴克数量由多到少对国家排序
要实现这个功能需要用到DataFrame.groupby()函数,相当于sql中的group by。在本例中可以使用starbucks.groupby(["Country"])来对星巴克按国家分组,然后使用starbucks.groupby(["Country"]).size()求得每个国家有多少星巴克。
df = starbucks.groupby(["Country"]).size().reset_index()
输出:
CountryAD 1AE 144AR 108AT 18AU 22AW 3AZ 4BE 19BG 5BH 21BN 5BO 4BR 102BS 10CA 1468CH 61CL 96CN 2734CO 11CR 11CW 3CY 10CZ 28DE 160DK 21EG 31ES 101FI 8FR 132GB 901...LU 2MA 9MC 2MX 579MY 234NL 59NO 17NZ 24OM 12PA 5PE 89PH 298PL 53PR 24PT 11QA 18RO 27RU 109SA 102SE 18SG 130SK 3SV 11TH 289TR 326TT 3TW 394US 13608VN 25ZA 3Length: 73, dtype: int64
然后我们将上一步的结果使用reset_index()方法封装成一个新的DataFrame,然后对这个DataFrame排序即可。
#根据每个国家的国家名和星巴克数量重建为一个DataFramedf = starbucks.groupby(["Country"]).size().reset_index()#查看df的前5行数据print df.head()#修改列名(将“0”改为“Nums”)df.columns=["Country", "Nums"]#按照星巴克数量由多到少对国家排序df.sort_values(by=["Nums"], ascending=False).head()
输出:
Country 00 AD 11 AE 1442 AR 1083 AT 184 AU 22Country Nums70 US 1360817 CN 273414 CA 146837 JP 123739 KR 993
可以看到,美国的星巴克最多,有13608家,其次是中国、加拿大、日本、韩国。由于篇幅限制只显示了排序后的5行,可以去掉head()显示全部数据。
4、按星巴克数量多少对中国城市排序
首先要在所有国家的数据中选择中国的数据,可以使用布尔索引实现这一目的:
#选择中国的数据df = starbucks[starbucks["Country"]=="CN"]#统计每个城市的星巴克数量df.groupby(["City"]).size()
输出:
CityAdmiralty 2Causeway Bay 5Central 1Chaiwan 1Changshu 1Changzhou 1Fortress Hill 1Hangzhou 2Hong Kong 104Jiaxing 2Jinhua 1Kowloon 19Kowloon Bay 1Kowloon Tong 1Lantau Island 2Macau 13Mong Kok 2N.T. 2Nanjing 1Nantong 4New Territories 7Ningbo 3Quarry Bay 3ShangHai 2Shanghai 2Shantin 1Stanley 1Suzhou 3Tai Koo Shing 1Tin Hau 1...萧山市 1蚌埠市 1衡阳市 3衢州市 3襄樊市 1襄阳市 2西宁市 3西安市 40诸暨市 2贵阳 8贵阳市 1连云港 1连云港市 3邢台市 1邯郸 1郑州市 18重庆市 41金华市 11银川市 2镇江市 9长春市 10长沙市 26阳江市 1青岛市 28靖江市 2鞍山市 3马鞍山 3高邮市 1黄石市 1龙岩市 2Length: 197, dtype: int64
可以看到数据不是很规范,城市名称既有中文又有英文,而且上海被存储为ShangHai和Shanghai。对于上海的问题,我们将拼音全部改为小写即可;对于中文和拼音混用的问题,可以使用相应的python库(如库pinyin)将中文转换为拼音后作统计。
首先安装库pinyin,如果是在命令行里运行的python,直接pip install pinyin,安装成功后import pinyin即可。我是在jupyter notebook里面写的,外部pip安装的模块无法导入,所以使用下面的方法(或者使用conda命令安装):
import pippip.main(['install', 'pinyin'])
安装后导入并做相应的处理:
import pinyin#选择中国的数据df = starbucks[starbucks["Country"]=="CN"]#需要拷贝一下,不然会出现“A value is trying to be set on a copy of a slice from a DataFrame.”的警告df1 = df.copy()#将城市名改为小写df1["City"] = df1["City"].apply(lambda x:x.lower())df2 = df1.copy()#将汉字城市名改为小写拼音df2["City"] = df2["City"].apply(lambda x:pinyin.get(x, format="strip", delimiter="")[0:-3]) #去掉“市”的拼音#统计每个城市的星巴克数量df2.groupby(["City"]).size()
输出:
Cityadmira 2anshan 3bangbu 1baoding 3baoji 1baotou 4beihai 1beijing 234causeway 5cent 1chai 1chang 1changchun 10changsha 26changshu 6changz 1changzhou 26chengde 1chengdu 98cixi 5dali 1dalian 25danzhou 1daqing 2deyang 2dezhou 2dongguan 31dongyang 1dongying 1fenghua 2...yancheng 6yangjiang 1yangzhong 1yangzhou 12yanji 1yantai 8yichang 4yinchuan 2yingkou 2yiwu 2yixing 3yuen l 2yueyang 2yuyao 1zhangjia 1zhangjiag 1zhangjiagang 1zhangzhou 1zhanjiang 4zhaoqing 1zhengzhou 18zhenjiang 9zhongqing 41zhongshan 11zhous 1zhoushan 5zhuhai 14zhuji 2zhuzhou 2zibo 5Length: 192, dtype: int64
这里使用到了DataFrame.apply(func)方法,该方法将函数func应用到整个DataFrame上,也可以通过指定axis参数来指定每一行或每一列的数据应用函数func。
接下来使用reset_index方法将上一步得到的数据封装到一个新的DataFrame中排序即可。
df3 = df2.groupby(["City"]).size().reset_index()#更改列索引名称df3.columns = ["City", "Nums"]print df3.sort_values(by=["Nums"], ascending=False).head()
输出:
City Nums121 shanghai 5427 beijing 23446 hangzhou 117126 shenzhen 11336 guangzhou 106
可以看到在中国,上海的星巴克最多,有542家,其次的是北京、杭州、深圳和广州,去掉.head()可以查看所有城市的数据。
三、总结
本文主要按照星巴克数量对国家和中国的城市进行排序,用到的知识有:
- 使用DataFrame.groupby()方法对DataFrame按照一列或多列分组;
- 使用布尔索引选择数据;
- 使用DataFrame.reset_index()方法重新指定索引(也就是把原DataFrame的行索引也当做数据并重新指定索引),该方法返回一个新的DataFrame;
- 通过对DataFrame.columns的赋值,重新指定列标签;
- 使用DataFrame.apply(func)方法,将函数func应用到整个DataFrame上,也可以通过指定axis参数来指定每一行或每一列的数据应用函数func。
- 使用DataFrame.sort()方法对DataFrame按照某一列或者某几列进行排序。
我们也可以看到一些pandas的操作可以与SQL操作练习起来:
1、Where语句
在上文中我们使用布尔索引选择了中国的数据df = starbucks[starbucks["Country"]=="CN"],这一点很像SQL里面的where语句select * from starbucks where Country="CN"。
2、Select语句
starbucks有很多列,如Country,City,Brand,Postcode等,如果我们要从所有列中选择两列Country和City,则pandas可以使用df = starbucks[["Country", "City"]],与之对应的是SQL中的select语句select Country, City from starbucks;
3、Group by语句
上文中通过国家分组,pandas使用DataFrame.groupby()方法starbucks.groupby(["Country"]),对应的为SQL中的select * from starbucks group by Country。
pandas实战——对星巴克数据的分析的更多相关文章
- 如何获取(GET)一杯咖啡——星巴克REST案例分析
英文原文:How to GET a Cup of Coffee 我们已习惯于在大型中间件平台(比如那些实现CORBA.Web服务协议栈和J2EE的平台)之上构建分布式系统了.在这篇文章里,我们将采取另 ...
- 使用bs4中的方法爬取星巴克数据
import urllib.request # 请求url url = 'https://www.starbucks.com.cn/menu/' # 模拟浏览器发出请求 response = urll ...
- pyecharts实现星巴克门店分布可视化分析
项目介绍 使用pyecharts对星巴克门店分布进行可视化分析: 全球门店分布/拥有星巴克门店最多的10个国家或地区: 拥有星巴克门店最多的10个城市: 门店所有权占比: 中国地区门店分布热点图. 数 ...
- 《Wireshark数据包分析实战》 - http背后,tcp/ip抓包分析
作为网络开发人员,使用fiddler无疑是最好的选择,方便易用功能强. 但是什么作为爱学习的同学,是不应该止步于http协议的,学习wireshark则可以满足这方面的需求.wireshark作为抓取 ...
- Spark大型项目实战:电商用户行为分析大数据平台
本项目主要讲解了一套应用于互联网电商企业中,使用Java.Spark等技术开发的大数据统计分析平台,对电商网站的各种用户行为(访问行为.页面跳转行为.购物行为.广告点击行为等)进行复杂的分析.用统计分 ...
- Python实战——基于股票的金融数据量化分析
说明:本文只是通过自己的已学知识对股票数据进行了一个简单的量化分析,只考虑了收盘情况,真实的量化交易中仅仅考虑收盘情况是不够的,还有很多的复杂因素,而且仅仅三年数据是不足以来指导真实的股票交易的,因此 ...
- 用实战玩转pandas数据分析(一)——用户消费行为分析(python)
CD商品订单数据的分析总结.根据订单数据(用户的消费记录),从时间维度和用户维度,分析该网站用户的消费行为.通过此案例,总结订单数据的一些共性,能通过用户的消费记录挖掘出对业务有用的信息.对其他产 ...
- iOS开发——项目实战总结&数据持久化分析
数据持久化分析 plist文件(属性列表) preference(偏好设置) NSKeyedArchiver(归档) SQLite 3 CoreData 当存储大块数据时你会怎么做? 你有很多选择,比 ...
- wireshark数据包分析实战 第一章
1,数据包分析工具:tcpdump.wireshark.前者是命令行的,后者是图形界面的. 分析过程:收集数据.转换数据(二进制数据转换为可读形式).分析数据.tcpdump不提供分析数据,只将最原始 ...
随机推荐
- Redis总体 概述,安装,方法调用
1 什么是redis redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合)和zset( ...
- springboot 以jar方式在linux后台运行
linux命令如下: nohup java -jar 自己的springboot项目.jar >日志文件名.log 2>&1 & 命令解释: nohup:不挂断地运行命令, ...
- Android SDK更新失败对策
Fetching https://dl-ssl.google.com/android/repository/addons_list-2.xml Failed to fetch URL https:// ...
- ConcrrentSkipListMap介绍和原理分析
一.前言: JDK为我们提供了很多Map接口的实现,使得我们可以方便地处理Key-Value的数据结构. 当我们希望快速存取<Key, Value>键值对时我们可以使用HashMap. 当 ...
- 莫队-小Z的袜子
----普通莫队 首先清楚概率怎么求假设我们要求从区间l到r中拿出一对袜子的概率sum[i]为第i种袜子在l到r中的数量 $$\frac{\sum_{i=l}^{r} {[sum[i] \times ...
- layui-laypage模块代码详解
/** layui-v2.4.0 MIT License By https://www.layui.com */;layui.define(function(e) { "use strict ...
- Treats for the Cows 区间DP POJ 3186
题目来源:http://poj.org/problem?id=3186 (http://www.fjutacm.com/Problem.jsp?pid=1389) /** 题目意思: 约翰经常给产奶量 ...
- 【四校联考】【比赛题解】FJ NOIP 四校联考 2017 Round 7
此次比赛为厦门一中出题.都是聚劳,不敢恭维. 莫名爆了个0,究其原因,竟然是快读炸了……很狗,很难受. 话不多说,来看看题: [T1] 题意: 样例: PS:1<=h[i]<=100000 ...
- python基础之命名空间
前言 命名空间通俗的理解就是对象或变量的作用范围,在python中分为局部命令空间.模块命名空间和build-in全局命名空间. 局部命名空间 局部命名空间即在一个函数或一个类中起作用的变量或引用的字 ...
- select()函数用法三之poll函数
poll是Linux中的字符设备驱动中有一个函数,Linux 2.5.44版本后被epoll取代,作用是把当前的文件指针挂到等待队列,和select实现功能差不多. poll()函数:这个函数是某些U ...