ELMO,BERT和GPT简介
1.Contextualized Word Embedding
同样的单词有不同的意思,比如下面的几个句子,同样有 “bank” ,却有着不同的意思。但是用训练出来的 Word2Vec 得到 “bank” 的向量会是一样的。向量一样说明 “word” 的意思是一样的,事实上并不是如此。这是 Word2Vec 的缺陷。
下面的句子中,同样是“bank”,确是不同的 token,只是有同样的 type
 我们期望每一个 word token 都有一个 embedding。每个 word token 的 embedding 依赖于它的上下文。这种方法叫做 Contextualized Word Embedding。
我们期望每一个 word token 都有一个 embedding。每个 word token 的 embedding 依赖于它的上下文。这种方法叫做 Contextualized Word Embedding。
2.EMLO
EMLO 是 Embeddings from Language Model 的缩写,它是一个 RNN-based 的模型,只需要有大量句子就可以训练。
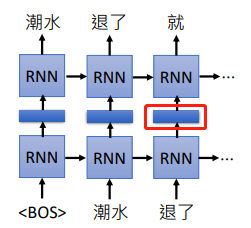
我们可以把训练的 RNN 隐藏层的权重拿出来,把词汇经过隐藏层后输出的向量当做这个单词的 embedding,因为 RNN 是考虑上下文的,所以同一个单词在不同的上下文中它会得到不同的向量。上面是一个正向里的 RNN,如果觉得考虑到的信息不够,可以训练双向 RNN ,同样将隐藏层的输出作为 embedding。
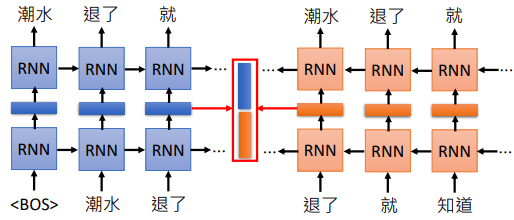
如果我们的 RNN 有很多层,我们要拿那一隐藏层的输出作为 embedding?
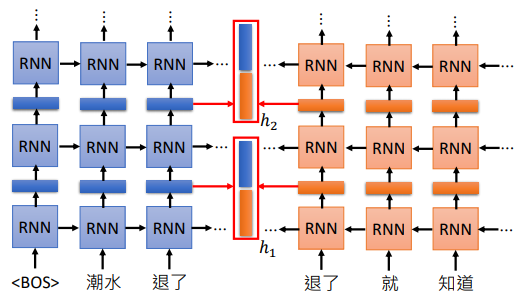 在 ELMO 中,它取出每一层得到的向量,经过运算得到我们每一个单词的 embedding
在 ELMO 中,它取出每一层得到的向量,经过运算得到我们每一个单词的 embedding
比如上图,假设我们有2层,所以每个单词都会得到 2 个向量,最简单的方法就是把两个向量加起来作为这个单词的embedding。
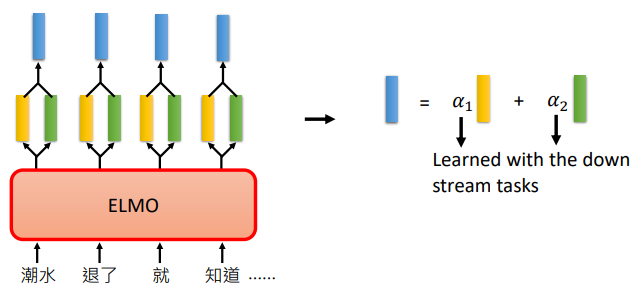
EMLO中会把两个向量取出来,然后乘以不同的权重 $\alpha $,再将得到的我们得到的 embedding 做下游任务。
$\alpha $ 也是模型学习得到的,它会根据我们的下游任务一起训练得到,所以不同的任务用到的 $\alpha $ 是不一样的
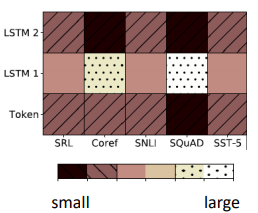
比如我们的 embedding 可以有3个来源,如上图所示。分别是
- 原来没有经过 contextualized 的 embedding,就是上面的 Token
- Token 经过第一层抽出第一个 embedding
- Token 经过第二层抽出第二个 embedding
颜色的深浅代表了权重的大小,可以看到不同的任务(SRL、Coref 等)有着不同的权重。
3.BERT
BERT 是 Bidirectional Encoder Representations from Transformers 的缩写,BERT 是 Transformer 中的 Encoder。它由许多个 Encoder 堆叠而成

在 BERT 里面,我们的文本是不需要标签的,只有收集到一堆句子就可以训练了。
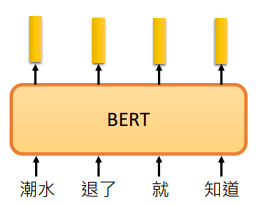
BERT 是 Encoder,所以可以看成输入一个句子,输出 embedding,每个 embedding 对应一个 word
上图的例子我们是以 “词” 为单位,有时候我们以 “字” 为单位会更好。比如中文的 “词” 是很多的,但是常用的 “字” 是有限的。
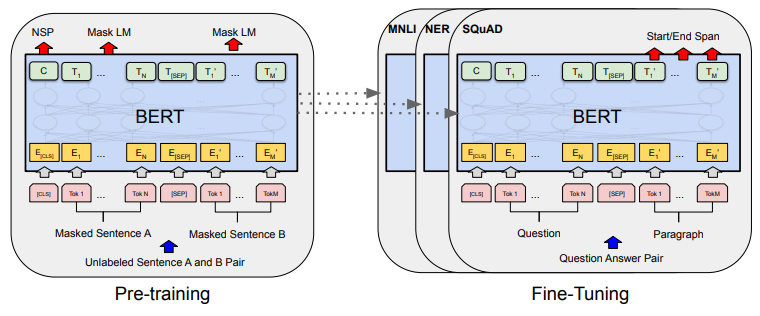
在 BERT 中,有两种训练方法,一种是 Masked LM。另一种是 Next Sentence Prediction。但一般同时使用,会取得更好的效果。下图是 BERT 的大体架构。可以看到 Pre-training 阶段和 Fine-Tuning 阶段中 BERT 模型,只有输出层不同,其他部分是完全一样的。
3.1Masked LM
在 Masked LM 中,我们会把输入的句子中随机将15%的词汇置换为一个特殊的 token ,叫做 [MASK]
其实并不是所有被选中的词汇都会被替换为 [MASK] ,在 BERT 论文的 3.1 Pre-training BERT 中谈到了 3 种方式。
(1)80% 被替换为 [MASK]
(2)10% 被替换为随机 token
(3)10% 不替换
BERT 的任务就是猜出这些被置换掉的词汇的什么。
就像是一个填词游戏,挖去一句话中的某个单词,让你自己填上合适的单词
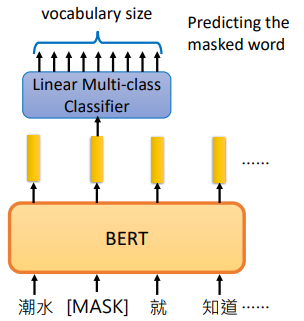
经过 BERT 后我们得到一个 embedding,再把置换为 [MASK] 的那个位置输出的 embedding 通过一个线性分类器,预测这个单词是什么
因为这个分类器是 Linear 的,所以它的能力非常非常弱,所以 BERT 要输出一个非常好的 embedding,才能预测出被置换掉的单词是什么
如果两个不同的词可以填在同一个句子,他们会有相似的embedding,因为他们语义相近
3.2Next Sentence Prediction
在 Next Sentence Prediction 中,我们给 BERT 两个句子,让 BERT 预测这两个句子是不是接在一起的
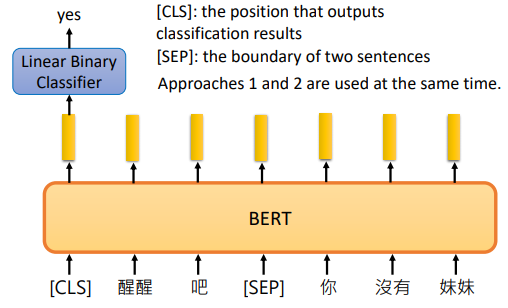
[SEP]:特殊的toekn,代表两个句子的交界处
[CLS]:特殊的token,代表要做分类
我们再把 [CLS] 输出的向量通过一个线性分类器,让分类器判断这两个句子应不应该接在一起。
BERT 是 Transformer 的 Encoder,它用到了 self-attention 机制,可以读到句子的全部信息,所以 [CLS] 可以放在开头
BERT 论文中谈到输入的句子对中,以 A-B 描述这样的句子对。B 有50%的概率不变,就是真正的下一句(IsNext)。也有 50% 的概率会变成其他句子(NotNext)。
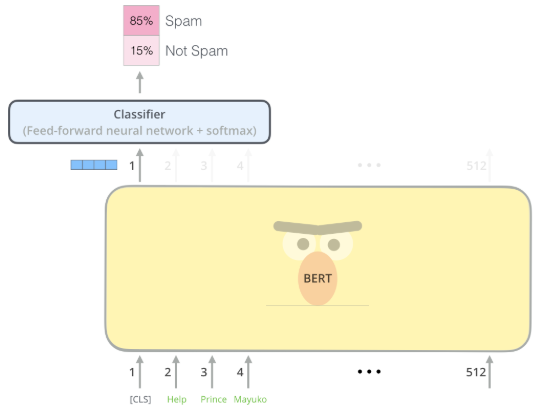
我们也可以直接把这个向量输入一个分类器中,判断文本的类别,比如下面判断垃圾邮件的实例
3.3BERT的输入
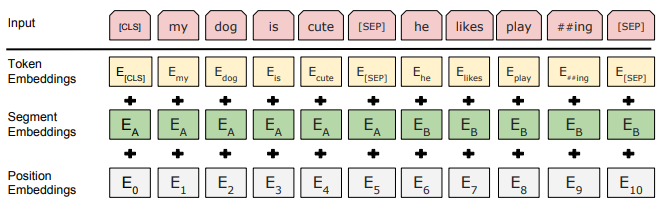
如上图所处,BERT 的输入 embedding 是 token embeddings、segment embeddings 和 position embedding 的和
token embedding:词向量
segment embedding:表示句子是第一句还是第二句
position embedding:表示词汇在句子中的位置
3.4ERNIE
ERNIE 是 Enhance Representation through Knowledge Integration 的缩写
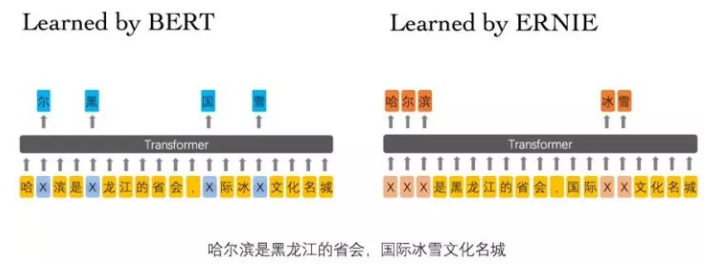
ERNIE是专门为中文准备的,BERT的输入以中文的字为单位,随机盖掉一些字后其实是很容易被猜出来的,如上图所示。所以盖掉一个词汇比较合适。
4.GPT
GPT 是 Generative Pre-Training 的缩写,它的参数量特别大,如下图所示,它的参数量是 BERT 的4.5倍左右
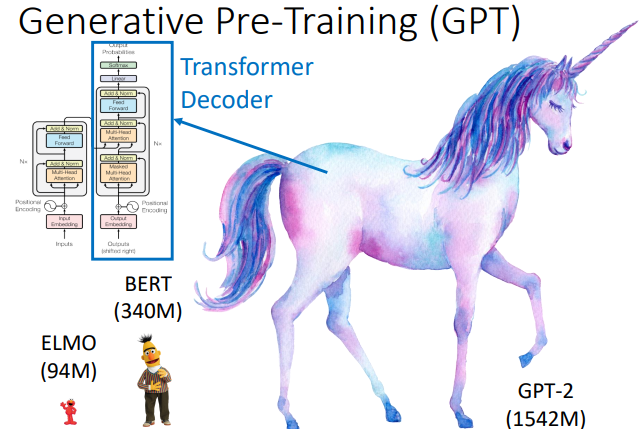
BERT 是 Transformer 的 Encoder,GPT则是 Transformer 的 Decoder。GPT 输入一些词汇,预测接下来的词汇。其计算过程如下图所示。
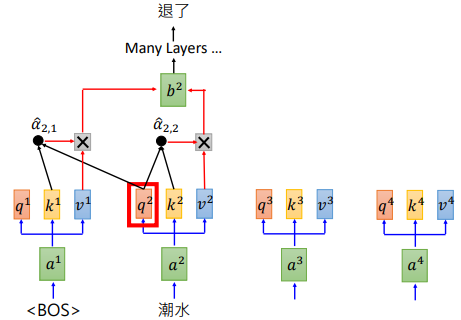
我们输入单词 “潮水”,经过许多层的 self-attention 后得到输出 “退了”。再把 “退了” 作为输入,预测下一个输出。
GPT可以做阅读理解、句子或段落生成和翻译等NLP任务
下面的网址可以体验训练好的 GPT
比如让它自己写代码
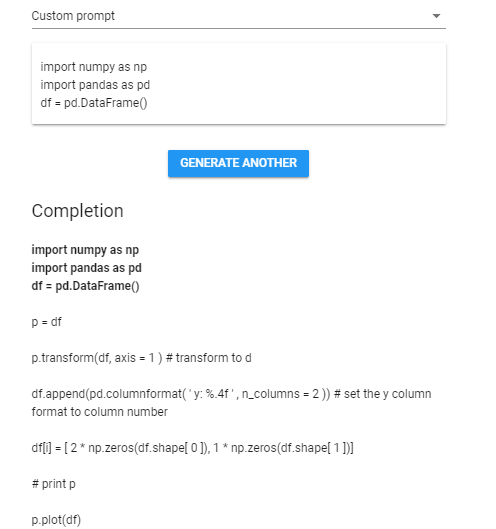 也可以让它写文章、写剧本什么的,网址就在上面,可以自己去体验
也可以让它写文章、写剧本什么的,网址就在上面,可以自己去体验

参考资料:
http://jalammar.github.io/illustrated-bert/
李宏毅深度学习
ELMO,BERT和GPT简介的更多相关文章
- GPT and BERT
目录 概 主要内容 GPT BERT Radford A., Narasimhan K., Salimans T. and Sutskever I. Improving language unders ...
- 理解BERT:一个突破性NLP框架的综合指南
概述 Google的BERT改变了自然语言处理(NLP)的格局 了解BERT是什么,它如何工作以及产生的影响等 我们还将在Python中实现BERT,为你提供动手学习的经验 BERT简介 想象一下-- ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
- 【中文版 | 论文原文】BERT:语言理解的深度双向变换器预训练
BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding 谷歌AI语言组论文<BERT:语言 ...
- 【NLP】彻底搞懂BERT
# 好久没更新博客了,有时候随手在本上写写,或者Evernote上记记,零零散散的笔记带来零零散散的记忆o(╥﹏╥)o..还是整理到博客上比较有整体性,也方便查阅~ 自google在2018年10月底 ...
- BERT论文解读
本文尽量贴合BERT的原论文,但考虑到要易于理解,所以并非逐句翻译,而是根据笔者的个人理解进行翻译,其中有一些论文没有解释清楚或者笔者未能深入理解的地方,都有放出原文,如有不当之处,请各位多多包含,并 ...
- zz从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 Bert最近很火,应该是最近最火爆的AI进展,网上的评价很高,那么Bert值得这么高的评价吗?我个人判断是值得.那为什么 ...
- BERT解析及文本分类应用
目录 前言 BERT模型概览 Seq2Seq Attention Transformer encoder部分 Decoder部分 BERT Embedding 预训练 文本分类试验 参考文献 前言 在 ...
- bert论文笔记
摘要 BERT是“Bidirectional Encoder Representations from Transformers"的简称,代表来自Transformer的双向编码表示.不同于 ...
随机推荐
- LeetCode102. 二叉树的层次遍历
102. 二叉树的层次遍历 描述 给定一个二叉树,返回其按层次遍历的节点值. (即逐层地,从左到右访问所有节点). 示例 例如,给定二叉树: [3,9,20,null,null,15,7], 3 / ...
- 使用jQuery实现Socket客户端
摘于抄书web前端开发 <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> & ...
- 5.canvas
1.canvas:固定语句:定义画布/设置绘图环境为2d. 2.canvas样式:lineWidth线宽/strokeStyle绘制样式. 3.canvas绘制矩形: Context.moveTo(x ...
- .net core api迁移 3.0后Post 405 Method Not Allowed
问题由来:.net core api之前是用 .net core 2.0开发的,测试过都是正常的,近期升级到了3.0,发现api get正常,post提示400,405 Method Not Allo ...
- SQL Server 2008将数据库数据导出到脚本
1.在要到处的数据库上右键 2.选择“任务” 3.选择“生成脚本” 4.选定要导出的数据库 5.在“编写数据的脚本”处选择“True” 6.接下来选定要导出的表,然后选择“完成”
- [web 安全] xxe
一.探测漏洞 1.是否支持实体解析. 2.是否支持外部实体解析. 2.1 直接读取本地文件: 2.2 远程文件: 3.不回显错误,则用 blind xxe.(先获取本地数据,然后带着本地数据去访问恶意 ...
- Linux 系统参数优化
修改系统所有进程可打开的文件数量 sysctl -w fs.file-max=2097152sysctl -w fs.nr_open=2097152 > vi /etc/sysctl.conff ...
- Linux内核设计与实现 总结笔记(第八章)下半部和推后执行的工作
上半部分的中断处理有一些局限,包括: 中断处理程序以异步方式执行,并且它有可能打断其他重要代码的执行. 中断会屏蔽其他程序,所以中断处理程序执行的越快越好. 由于中断处理程序往往需要对硬件进行操作,所 ...
- vue中的render函数介绍
简介:对于不了解slot的用法(参考:大白话vue-slot的用法)又刚接触render函数的同学来说,官网的解释无疑一脸懵逼,这里就整理下个人对render函数的理解 问题: 1.render函数是 ...
- [USACO17DEC]Barn Painting (树形$dp$)
题目链接 Solution 比较简单的树形 \(dp\) . \(f[i][j]\) 代表 \(i\) 为根的子树 ,\(i\) 涂 \(j\) 号颜色的方案数. 转移很显然 : \[f[i][1]= ...