《STL源码剖析》——第一、二、三章
第一章:概论:
换句话说,STL所实现的,是依据泛型思维架设起来的一个概念结构。这个以抽象概念(abstract concepts)为主体而非以实际类(classes)为主体的结构,形成了一个严谨的接口标准。在此接口之下,任何组件都有最大的独立性,并以所谓迭代器(iterator)胶合起来,或以所谓配接器(adapter)互相配接,或以所谓仿函数(functor)动态选择某种策略(policy或strategy)。
STL提供六大组件
1.容器(containers):各种数据结构,如 vector,list,deque,set,map,用来存放数据,详见本书4,5两章。从实现的角度来看,STL容器是一种class template。就体积而言,这一部分很像冰山在海面下的比率。
2.算法(algorithms):各种常用算法如sort,search,copy,erase…详见第6章。从实现的角度来看,STL算法是一种function template。
3.迭代器(iterators):扮演容器与算法之间的胶合剂,是所谓的“泛型指针”,详见第3章。共有五种类型,以及其它衍生变化。从实现的角度来看,迭代器是一种将 operator*,operator->,operatort+,operator--等指针相关操作予以重载的class template。所有STL容器都附带有自己专属的迭代器——是的,只有容器设计者才知道如何遍历自己的元素。原生指针(native pointer)也是一种迭代器。
4.仿函数(functors):行为类似函数,可作为算法的某种策略(policy),详见第7章。从实现的角度来看,仿函数是一种重载了operator()的class或class template.一般函数指针可视为狭义的仿函数。
5.配接器(adapters):一种用来修饰容器(containers)或仿函数(functors)
或迭代器(iterators)接口的东西,详见第8章。例如,STL提供的queue和stack,虽然看似容器,其实只能算是一种容器配接器,因为它们的底部完全借助 deque,所有操作都由底层的deque供应。改变functor接口者,称为function adapter;改变container 接口者,称为container adapter;改变iterator接口者,称为iterator adapter。配接器的实现技术很难一言以蔽之,必须逐一分析,详见第8章。
6.配置器(allocators):负责空间配置与管理,详见第2章。从实现的角度来看,配置器是一个实现了动态空间配置、空间管理、空间释放的class template。
class alloc{
};
C++11 STL中的容器
==================================================
一、顺序容器:
vector:可变大小数组;
deque:双端队列;
list:双向链表;
forward_list:单向链表;
array:固定大小数组;
string:与vector相似的容器,但专门用于保存字符。
==================================================
二、关联容器:
按关键字有序保存元素:(底层实现为红黑树)
map:关联数组;保存关键字-值对;
set:关键字即值,即只保存关键字的容器;
multimap:关键字可重复的map;
multiset:关键字可重复的set;
--------------------------------------------------------------------------------
无序集合:
【不会按字典规则进行排序】
unordered_map:用哈希函数组织的map;
unordered_set:用哈希函数组织的set;
unordered_multimap:哈希组织的map;关键字可以重复出现;
unordered_multiset:哈希组织的set;关键字可以重复出现。
==================================================
三、其他项:
1、stack、queue、valarray、bitset
随机访问中,[ ]与 .at( )功能相同,但是[ ]越界了会直接导致程序崩溃,而 .at( )会抛出异常,故其更安全!
2、size、capacity与shrink_to_fit
size表示目前容器的实际大小、
capacity表示容器的空间,一般 >=size,因为容器初始化或者赋值时,系统会根据情况给予容器一个适当的空间,避免每次增加数据时又得重新新分配空间,索性一次给多点,但也不会很大,
为了节省空间,你可以使用shrink_to_fit将容器空间capacity缩小为size
四、迭代器删除失效:
1. vector,erase(pos),直接把pos+1到finish的数据拷贝到以pos为起点的区间上,也就是vector的长度会逐渐变短,同时iter会逐渐往后移动,直到iter == cont.end(),由于容器中end()返回的迭代器是最后一个元素的下一个(这个地方没有任何值),现在考虑这个状态前一个状态,此时要删除的点是iter, tempIt = iter, ++iter会指向此时的end(),但是执行erase(tempIt)之后,end()向前移动了!!!问题来了,此时iter空了!!!不崩溃才怪。
2. list,erase(pos),干的事情很简单,删除自己,前后的节点连接起来就完了,所以iter自增的过程不会指空,不会崩溃喽。
3. map,erase(pos),干的事情太复杂,但是我们需要知道的信息其实很少。该容器底层实现是RBTree,删除操作分了很多种情形来讨论的,目的是为了维持红黑树性质。但是我们需要知道的就是每个节点类似于list节点,都是单独分配的空间,所以删除一个节点并不会对其他迭代器产生影响,对应到题目中,不会崩溃喽。
4. deque,erase(pos),与vector的erase(pos)有些类似,基于结构的不同导致中间有些步骤不太一致。先说说deque的结构(这个结构本身比较复杂,拣重要说吧,具体看STL源码),它是一个双向开口的连续线性空间,实质是分段连续的,由中控器map维持其整体连续的假象。其实题中只要知道它是双向开口的就够了(可以在头部或尾部增加、删除)。在题中有erase(pos),deque是这样处理的:如果pos之前的元素个数比较少,那么把start到pos-1的数据移到起始地址为start+1的区间内;否则把pos后面的数据移到起始地址为pos的区间内。在题中iter一直往后移动,总会出现后面数据比前面少的时候,这时候问题就和1一样了,必须崩溃!
关联容器(如map, set, multimap,multiset),【不会失效】删除当前的iterator,只会使当前的iterator失效,只要在erase时,递增当前iterator即可。
对于序列式容器(如vector,deque),【会失效】删除当前的iterator会使后面所有元素的iterator都失效。这是因为vetor,deque使用了连续分配的内存,删除一个元素导致后面所有的元素会向前移动一个位置。不过erase方法可以返回下一个有效的iterator,cont.erase(iter++)可以修改为cont.erase(iter)
list使用了不连续分配的内存,并且它的erase方法也会返回下一个有效的iterator。
五、为不同的容器选择不同删除方式
删除连续容器(vector,deque,string)的元素
// 当c是vector、string,删除value
c.erase(remove(c.begin(), c.end(), value), c.end()); // 判断value是否满足某个条件,删除
bool assertFun(valuetype);
c.erase(remove_if(c.begin(), c.end(), assertFun), c.end()); // 有时候我们不得不遍历去完成,并删除
for(auto it = c.begin(); it != c.end(); ){
if(assertFun(*it)){
···
it = c.erase(it);
}
else
++it;
} 删除list中某个元素 c.remove(value); // 判断value是否满足某个条件,删除
c.remove(assertFun); 删除关联容器(set,map)中某个元素 c.erase(value) for(auto it = c.begin(); it != c.end(); ){
if(assertFun(*it)){
···
c.erase(it++);
}
else
++it;
}
各大容器性能对比:
1、vector
变长一维数组,连续存放的内存块,有保留内存,堆中分配内存;
支持[]操作,高效率的随机访问;
在最后增加元素时,一般不需要分配内存空间,速度快;在中间或开始操作元素时要进行内存拷贝效率低;
vector高效的原因在于配置了比其所容纳的元素更多的内存,内存重新配置会花很多时间;
vector的内存分配:
一般是按你当时存储数据的两倍开辟空间,当插入数据空间不够时,又会重新增加空间至当时数据空间的2倍,此动作降低了vector的工作效率!!!
注:需要高效的随即存取,而不在乎插入和删除使用vector。
2、list
双向链表,内存空间上可能是不连续的,无保留内存,堆中分配内存;
不支持随机存取,开始和结尾元素的访问时间快,其它元素都O(n);
在任何位置安插和删除元素速度都比较快,安插和删除操作不会使其他元素的各个pointer,reference,iterator失效;
注:大量的插入和删除,而不关系随即存取使用list。
3、deque
双端队列,在堆上分配内存,一个堆保存几个元素,而堆之间使用指针连接;
支持[]操作,在首端和末端插入和删除元素比较快,在中部插入和删除则比较慢,像是list和vector的结合;
注:关心插入和删除并关心随即存取折中使用deque。
4、set&multiset
有序集合,使用平衡二叉树存储,按照给定的排序规则(默认按less排序)对set中的数据进行排序;
set中不允许有重复元素,multiset中运行有重复元素;
两者不支持直接存取元素的操作;
因为是自动排序,查找元素速度比较快;
不能直接改变元素值,否则会打乱原本正确的顺序,必须先下删除旧元素,再插入新的元素。
5、map&multimap
字典库,一个值映射成另一个值,使用平衡二叉树存储,按照给定的排序规则对map中的key值进行排序;
map中的key值不允许重复,multimap中的key允许重复;
根据已知的key值查找元素比较快;
插入和删除操作比较慢。
6、hash_map
hash_map使用hash表来排列配对,hash表是使用关键字来计算表位置。当这个表的大小合适,并且计算算法合适的情况下,hash表的算法复杂度为O(1)的,但是这是理想的情况下的,如果hash表的关键字计算与表位置存在冲突,那么最坏的复杂度为O(n)。
选用map还是hash_map,关键是看关键字查询操作次数,以及你所需要保证的是查询总体时间还是单个查询的时间。如果是要很多次操作,要求其整体效率,那么使用hash_map,平均处理时间短。如果是少数次的操作,使用 hash_map可能造成不确定的O(N),那么使用平均处理时间相对较慢、单次处理时间恒定的map,便更好些。
STL容器对比:
|
vector |
deque |
list |
set |
multiset |
map |
multimap |
|
|
名称 |
向量容器 |
双向队列容器 |
列表容器 |
集合 |
多重集合 |
映射 |
多重映射 |
|
内部数 据结构 |
连续存储的数组形式(一端开口的组) |
连续或分段连续存储数组(两端 开口的数组) |
双向环状链表 |
红黑树(平衡检索二叉树) |
红黑树 |
红黑树 |
红黑树 |
|
特 点 |
获取元素效率很高,插入和删除的 效率很低 |
获取元素效率较高,插入和删除的效率较高 |
获取元素效率很低,插入和删除的效率很高 |
1.键(关键字)和值(数据)相等(就是模版只有一个参数,键和值合起来) 2.键唯一 3.元素默认按升序排列 |
1.键和值相等 2.键可以不唯一 3.元素默认按升序排列 |
1.键和值分开(模版有两个参数,前面是键后面是值) 2.键唯一 3.元素默认按键的升序排列 |
1.键和值分开 2.键可以不唯一 3.元素默认按键的升序排列 |
|
头文件 |
#include <vector> |
#include <deque> |
#include <list> |
#include <set> |
#include <set> |
#include <map> |
#include <map> |
|
操作元素的方式 |
下标运算符:[0](可以用迭代器,但插入删除操作时会失效) |
下标运算符或迭代器 |
只能用迭代器(不断用变量值来递推新值,相当于指针),不支持使用下标运算符 |
迭代器 |
迭代器 |
迭代器 |
迭代器 |
|
插入删除操作迭代器是否失效 |
插入和删除元素都会使迭代器失效 |
插入任何元素都会使迭代器失效。删除头和尾元素,指向被删除节点迭代器失效,而删除中间元素会使所有迭代器失效 |
插入,迭代器不会失效。删除,指向被删除节点迭代器失效 |
插入,迭代器不会失效。删除,指向被删除节点迭代器失效 |
插入,迭代器不会失效。删除,指向被删除节点迭代器失效 |
插入,迭代器不会失效。删除,指向被删除节点迭代器失效 |
插入,迭代器不会失效。删除,指向被删除节点迭代器失效 |
总结:
|
vector |
deque |
list |
set |
multiset |
map |
multimap |
|
|
典型内存结构 |
单端数组 |
双端数组 |
双向链表 |
二叉树 |
二叉树 |
二叉树 |
二叉树 |
|
可随机存取 |
是 |
是 |
否 |
否 |
否 |
对 key 而言:不是 |
否 |
|
vector |
deque |
list |
set |
multiset |
map |
multimap |
|
|
元素搜寻速度 |
慢 |
慢 |
非常慢 |
快 |
快 |
对 key 而言:快 |
对 key 而言:快 |
|
元素安插移除 |
尾端 |
头尾两端 |
任何位置 |
- |
- |
- |
- |
容器自定义比较方式:
struct fruit
{
string name;
int price;
friend bool operator <(fruit fl, fruit f2)
{
return fl. price>f2. price;
}
};
STL容器新颖使用
将数组中的值直接付给容器
int arry[size] = {0,1,2,3,4,5,6};
xxx<int>contain(arry, arry+size);//即将数组中的值直接初始化赋予了容器中
简介SGI:
vector:
class alloc{
};
template <class T,class Alloc=alloc>
class vector{
public:
void swap(vector<T,Alloc>&){
cout<<"swap()"<< endl;
}
};
vector<int>x,y;
template <class T,class Alloc=alloc>
class vector{
public:
typedef T value_type;
typedef value_type* iterator;
template <class I>
void insert(iterator position,I first,I last){
cout <<"insert()"<< endl;
}
};
vector<int>x;
vector<int>::iterator ite;
stack:
template <class T,clase A1loc=alloc,size_t BufSiz=>
class deque{
public:
deque(){
cout <<"deque"<< endl;
}
};
//根据前一个参数值T,设定下一个参数Sequence的默认值为deque<T>
template <class T,claas Sequence= deque<T>>
class stack{
public:
stack(){
cout <<"stack"<< end1;
}
private:
Sequence c;
};
stack<int>x;
template <class T,class Alloc=alloc,size_t BufSiz=>
class deque{
public:
deque(){
cout <<"deque"<<'';
}
};
template <class T,class Sequence>
class stack;
template <class T,class Sequence>
bool operator==(const stack<T,Sequence>&x,const stack<T,Sequence>&y);
template <class T,class Sequence>
bool operator<(const stack<T,Sequence>&x,const stack<T,Sequence>&y);
template <class T,class Sequence=deque<T>>
class stack{
//写成这样是可以的
friend bool operator==<T>(const stack<T>&,const stack<T>&);
friend bool operator< <T>(const stack<T>&,const stack<T>&);
//写成这样也是可以的
friend bool operator==<T> (const stack&,const stack&);
friend bool operator< <T> (const stack&,const stack&);
//写成这样也是可以的
friend bool operator==<> (const stack&,const stack&);
friend bool operator<<>(const stack&,const stack&);
//写成这样就不可以
//friend bool operator==(const stack&,const stack&);
//friend bool operator<(const stack&,const stack&);
public:
stack(){cout <<"stack"<<endl;}
private:
Sequence c;
};
template <class T, class Sequence>
bool operator==(const stack<T, Sequence>& x, const stack<T, Sequence>&y){
return cout <<"operator=="<<'\t';
}
template <class T, class Sequence>
bool operator<(const stack<T, Sequence>& x, const stack<T, Sequence>&y){
return cout <<"operator<"<<'\t';
}
int main(){
stack<int>x;//deque stack
stack<int>y;//deque stack
cout <<(x==y)<<endl;//operator==1
cout <<(x<y)<<end1;//operator<1
stack<char>y1;//deque stack
//cout c<(x== y1)<< endl; //error: no match for...
//cout <<(x< y1)<< end1;//error: no match for...
}
deque:
inline sizet _deque_buf_size(size_t n,size_t sz){
return n!=?n:(sz<?size_t(/sz):size_t());
}
template <class T,class Ref,class Ptr,size_t BufSiz>
struct _deque_iterator{
typedef _deque_iterator<T,T&,T*,BufSiz> iterator;
typedef __deque_iterator<T,const T&,const T*,BufSiz>const_iterator;
static size_t buffer_size(){
return deque_ buf_size(Bufsiz,sizeof(T));
}
};
template <class T,class Alloc=alloc,size_t Buf8iz=>
class deque{
typedef deque_iterator<T,T&,T*,BufSiz> iterator;
};
cout << deque<int>::iterator::buffer_size()<<end1;//
cout << deque<int,alloc,>::iterator::buffer_size()<<endl;//
第二章、空间配置:
(1)考虑到小型区块所可能造成的内存破碎问题,SGI设计了双层配置器,第一级配置器直接使用malloc和free,第二级配置器则视情况采用不用的策略(需求区块是否大于128bytes)。
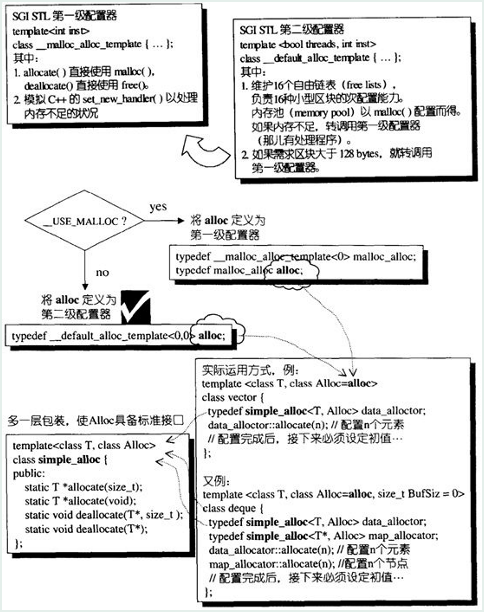
第一级适配器以malloc(),free(),reaclloc()等C函数执行实际的内存配置、释放、重配置操作。第二级配置器多了一些机制,避免太多小额区块造成内存的碎片。
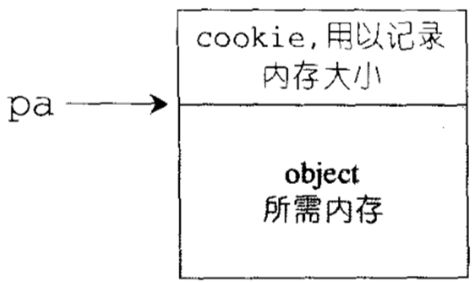
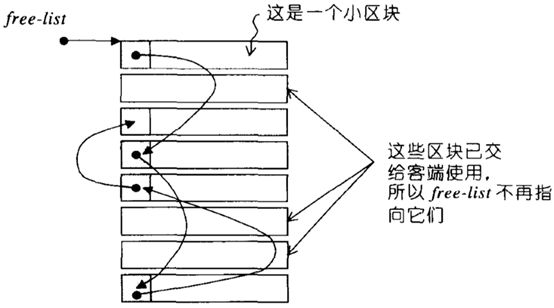
SGI第二级配置器的做法是,如果区块够大,超过128字节时,就移交第一级配置器处理。当区块小于128字节时,则以内存池(memory pool)管理,此法又称为次层配置(sub-allocation):每次配置一大块内存,并维护对应的自由链表(free-list)。下次若再有相同大小的内存需求,就直接从free-lists中拔出。如果没有,则向系统要一大块内存,然后做切割,此时切割出来的小内存块,不带cookie。如果客户端释放小额区块,就由配置器回收。为方便管理,任何小额区块的内存需求量上调至8的倍数,并维护16个free-lists,各自管理大小分别为8,16,24...128字节。
在G4.9中编译器使用的是不作任何优化的空间配置器,如果需要制定,则需要指明第二参数:
vector<string, __gnu_cxx::__pool_alloc<string>> vec;
如果free-list中没有可用的区块,将区块大小上调至8的倍数边界,然后调用refill(),准备为free-list重新填充空间。refill()之后介绍。
空间的释放,大于128字节就调用第一级配置器,小于128字节就找出对应的free list,将区块回收。
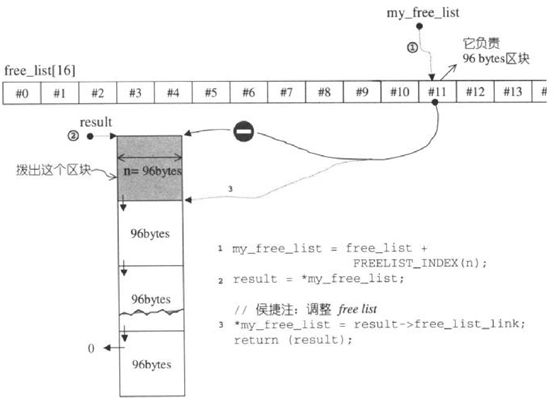
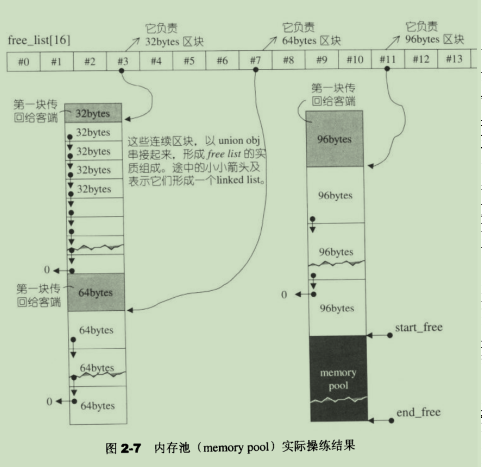
refill()重新填充空间,新的空间将取自内存池(经由chunk_alloc()完成)。内存池实际操练结果如下图:
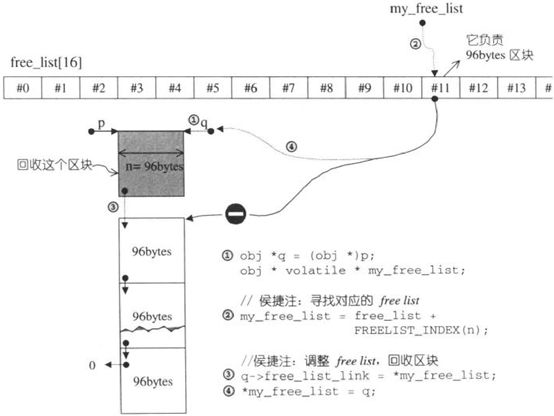
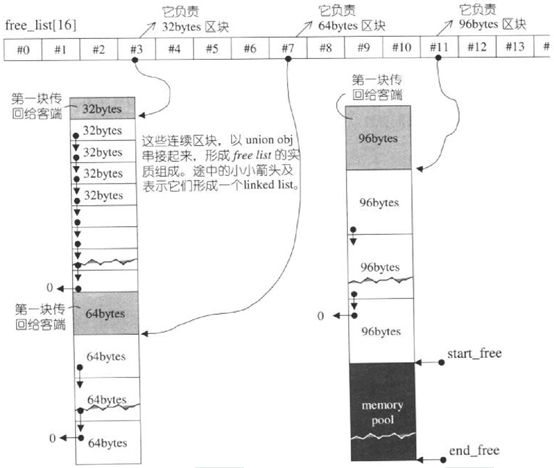
(2)第一级配置器直接调用C函数执行实际的内存操作,并实现类似C++ new handler的机制。
(3)当区块超过128bytes时,视之为足够大,便调用第一级配置器。当配置器小于128bytes时,视之为过小,便采用内存池的方式。每次配置一大块内存,并维护对应之自由链表,下次若再有相同大小的内存需求,就直接从free-list中拔出。如果客端释还小额区块,就由配置器回收到free-list中。为了方便管理,SGI第二季配置器会主动将任何小额区块的内存需求量上调至8的倍数(例如客端要求30bytes,就自动调整为32bytes),并维护16个free-list,大小分别是8,16,24,32,40,48,56,64,72,80,88,96,104,112,120,128bytes。
(4)内存池
如果水量充足,就直接调出20个区块返回给free-list,如果不够20则返回不足实际个数。如果一个都拿不出,则调用malloc配置40个区块的空间,其中20个给free-list,剩下的20个留在内存池。如果malloc分配失败,则调用第一级配置器。因为第一级配置器有new-handler机制,获取能够整理出多余的空间。、
(5)内存基本处理工具
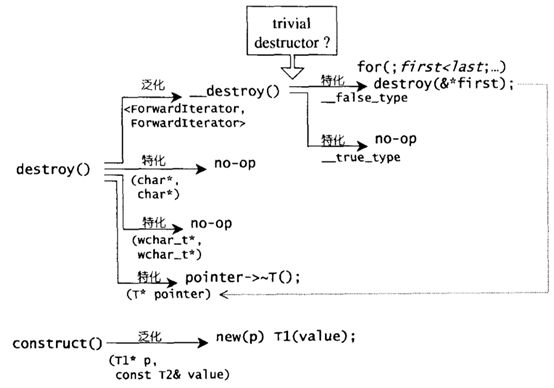
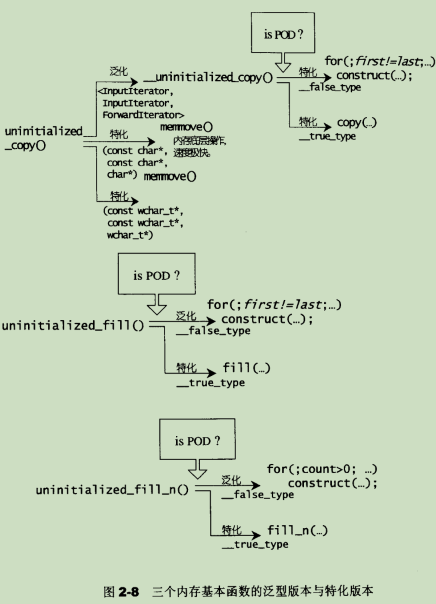
uninitialized_copy,uninitialized_fill,uninitialized_fill_n,能够将内存配置与对象构造行为分离开来。并且会对POD(即标量型别或传统C struct)对象采用最有效率的初值填写手法,而对non-POD型别采取最保险安全的做法。
为了细化分工,STL allocator将两阶段操作区分开来。内存配置操作由alloc::allocate()负责,内存释放操作由alloc::deallocate()负责;对象构造操作由::construct负责,对象析构操作由::destroy()负责。
- 内存池:
当申请空间不充足时,系统首先将剩余的空间尽量为你申请出来
一般新申请的空间大小为你所需求空间大小的2倍加上一个随机配置次数增加愈加增大的附加量
第三章、迭代器概念
STL的中心思想在于:将数据容器(containers)和算法(algorithms)分开,彼此独立设计,最后再以一帖胶着剂将它们撮合在一起。
迭代器相应型别:
迭代器相应型别之一:value type:
所谓 value type,是指迭代器所指对象的型别。任何一个打算与STL算法有完美搭配的class,都应该定义自己的vlue type内嵌型别,做法就像上节所述。
迭代器相应型别之二:difference type:
difference type用来表示两个迭代器之间的距离,因此它也可以用来表示一个容器的最大容量,因为对于连续空间的容器而言,头尾之间的距离就是其最大容量。
如果一个泛型算法提供计数功能,例如STL的count(),其传回值就必须使用迭代器的diference type:
迭代器相应型别之三:reference type
从“迭代器所指之物的内容是否允许改变”的角度观之,迭代器分为两种:
不允许改变“所指对象之内容”者,称为constant iterators,例如 const int *pic;【视为不可改的右值】
允许改变“所指对象之内容”者,称为mutable iterators,例如int *pi。当我们对一个mutable iterators进行提领操作时,获得的不应该是一个右值(rvalue),应该是一个左值(lvalue),因为右值不允许赋值操作(assignment),左值才允许:
int *pi=new int(5);
const int *pci=new int(9);
*pi=7;//对mutable iterator进行提领操作时,获得的应该是个左值,允许赋值
*pci=1;//这个操作不允许,因为pci是个constant iterator,
//提领pci所得结果,是个右值,不允许被赋值
迭代器相应型别之四:pointer type
pointers和references在C++中有非常密切的关联。如果“传回一个左值,令它代表p所指之物”是可能的,那么“传回一个左值,令它代表p所指之物的地址”也一定可以。也就是说,我们能够传回一个pointer,指向迭代器所指之物。
迭代器相应型别之五:iterator_category
最后一个(第五个)迭代器的相应型别会引发较大规模的写代码工程。在那之前,我必须先讨论迭代器的分类。
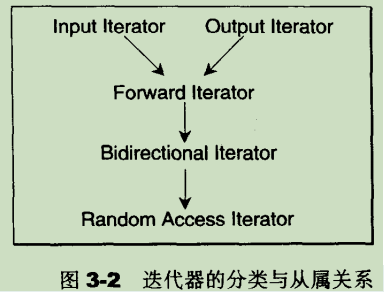
根据移动特性与施行操作,迭代器被分为五类:
·Input lterator:这种迭代器所指的对象,不允许外界改变。只读(read only)。
·Output terator:唯写(write only)。
·Forward lterator:允许“写入型”算法(例如replace())在此种迭代器所形成的区间上进行读写操作。
·Bidirectiona lterator:可双向移动。某些算法需要逆向走访某个迭代器区间(例如逆向拷贝某范围内的元素),可以使用Biairectional lterators。
·Random Access lterator:前四种迭代器都只供应一部分指针算术能力(前三种支持 operator++,第四种再加上operator--),第五种则涵盖所有指针算术能力,包括p+n,p-n,p[n],pl-p2,p1<p2。
《STL源码剖析》——第一、二、三章的更多相关文章
- 《STL源码剖析》——第四章、序列容器
1.容器的概观与分类 所谓序列式容器,其中的元素都可序(ordered)[比如可以使用sort进行排序],但未必有序(sorted).C++语言本身提供了一个序列式容器array,STL另外再提供v ...
- 重温《STL源码剖析》笔记 第二章
源码之前,了无秘密. --侯杰 第二章:空间配置器 allocator SGI特殊的空间配置器,std::alloc SGI是以malloc()和free()完成内存的配置与释放. SGI设计了双层级 ...
- c++ stl源码剖析学习笔记(三)容器 vector
stl中容器有很多种 最简单的应该算是vector 一个空间连续的数组 他的构造函数有多个 以其中 template<typename T> vector(size_type n,cons ...
- 面试题总结(三)、《STL源码剖析》相关面试题总结
声明:本文主要探讨与STL实现相关的面试题,主要参考侯捷的<STL源码剖析>,每一个知识点讨论力求简洁,便于记忆,但讨论深度有限,如要深入研究可点击参考链接,希望对正在找工作的同学有点帮助 ...
- STL源码剖析 迭代器(iterator)概念与编程技法(三)
1 STL迭代器原理 1.1 迭代器(iterator)是一中检查容器内元素并遍历元素的数据类型,STL设计的精髓在于,把容器(Containers)和算法(Algorithms)分开,而迭代器(i ...
- STL源码分析读书笔记--第二章--空间配置器(allocator)
声明:侯捷先生的STL源码剖析第二章个人感觉讲得蛮乱的,而且跟第三章有关,建议看完第三章再看第二章,网上有人上传了一篇读书笔记,觉得这个读书笔记的内容和编排还不错,我的这篇总结基本就延续了该读书笔记的 ...
- STL源码剖析读书笔记之vector
STL源码剖析读书笔记之vector 1.vector概述 vector是一种序列式容器,我的理解是vector就像数组.但是数组有一个很大的问题就是当我们分配 一个一定大小的数组的时候,起初也许我们 ...
- 《STL源码剖析》相关面试题总结
原文链接:http://www.cnblogs.com/raichen/p/5817158.html 一.STL简介 STL提供六大组件,彼此可以组合套用: 容器容器就是各种数据结构,我就不多说,看看 ...
- 《STL源码剖析》读书笔记
转载:https://www.cnblogs.com/xiaoyi115/p/3721922.html 直接逼入正题. Standard Template Library简称STL.STL可分为容器( ...
- 通读《STL源码剖析》之后的一点读书笔记
直接逼入正题. Standard Template Library简称STL.STL可分为容器(containers).迭代器(iterators).空间配置器(allocator).配接器(adap ...
随机推荐
- Vue基于vuex、axios拦截器实现loading效果及axios的安装配置
准备 利用vue-cli脚手架创建项目 进入项目安装vuex.axios(npm install vuex,npm install axios) axios配置 项目中安装axios模块(npm in ...
- win32 socket 编程(三)——TCP/IP
一.TCP/IP解析 TCP/IP协议的核心部分是传输层协议(TCP.UDP),网络层协议(IP)和物理接口层,这三层通常是在操作系统内核中实现.因此用户一般不涉及.编程时,编程界面有两种形式: 1. ...
- vs code 同步
vs code 同步需要在github上配置好gist id, 将gist id添加至setting.json中, 然后再在localsetting中设置access token, gist id ...
- mona!mona!mona!
$ PS: $ 关于\(mona\) 是只很棒的猫啦!想知道的可以自己去看\(persona5\)的游戏流程或者动画版啦. \(PPS:\) 补充一下设定啊,\(mona\)是摩尔加纳(原名)的代号啦 ...
- Centos添加硬盘分区
1. 查看硬盘信息 fdish -l 此处/dev/sdb为新添加硬盘 2. 格式化为ext4硬盘格式 mkfs.ext4 /dev/sdb 亦可使用其他格式 硬盘空间大于2T时,MBR分区无法识别更 ...
- python中*args和**kwargs学习
*args 和 **kwargs 经常看到,但是一脸懵逼 ,今天终于有收获了 """ python 函数的入参经常能看到这样一种情况 *args 或者是 **kwargs ...
- OC + RAC (五) RACMulticastConnection
-(void)_test5{ //弊端:有几个订阅者就会请求几次数据 // 1.创建信号 RACSignal *signal = [RACSignal createSignal:^RACDisposa ...
- vivo面试题
0.自动拆箱和装箱 java有8种原始类型,分为数字型,字符型,布尔型.其中数字型又分为整数型和浮点数型.整数型按照占用字节数从小到大依次是byte(占用1个字节,值范围是[-27 ~ 27-1]). ...
- android设置系统默认开机时间
1.设置RTC时间,该时间是如果RCT时钟断电以后使用的默认时间 Android L之前: \alps\mediatek\custom\[project]\preloader\ inc\cust_rt ...
- Hash树——数据结构