L1、L2损失函数、Huber损失函数
L1范数损失函数,也被称为最小绝对值偏差(LAD),最小绝对值误差(LAE)
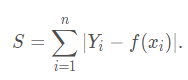
L2范数损失函数,也被称为最小平方误差(LSE)

| L2损失函数 | L1损失函数 |
|---|---|
| 不是非常的鲁棒(robust) | 鲁棒 |
| 稳定解 | 不稳定解 |
| 总是一个解 | 可能多个解 |
鲁棒性
最小绝对值偏差之所以是鲁棒的,是因为它能处理数据中的异常值。如果需要考虑任一或全部的异常值,那么最小绝对值偏差是更好的选择。
L2范数将误差平方化(如果误差大于1,则误差会放大很多),模型的误差会比L1范数来得大,因此模型会对这个样本更加敏感,这就需要调整模型来最小化误差。如果这个样本是一个异常值,模型就需要调整以适应单个的异常值,这会牺牲许多其它正常的样本,因为这些正常样本的误差比这单个的异常值的误差小。
稳定性
最小绝对值偏差方法的不稳定性意味着,对于数据集的一个小的水平方向的波动,回归线也许会跳跃很大。
相反地,最小平方法的解是稳定的,因为对于一个数据点的任何微小波动,回归线总是只会发生轻微移动
总结
MSE对误差取了平方,如果存在异常值,那么这个MSE就很大。
MAE更新的梯度始终相同,即使对于很小的值,梯度也很大,可以使用变化的学习率。MSE就好很多,使用固定的学习率也能有效收敛。
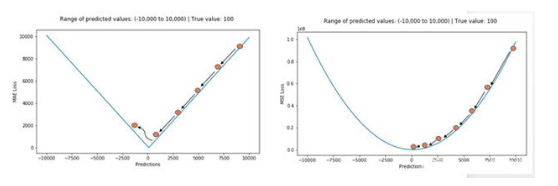
总而言之,处理异常点时,L1损失函数更稳定,但它的导数不连续,因此求解效率较低。L2损失函数对异常点更敏感,但通过令其导数为0,可以得到更稳定的封闭解。
Huber
l1和l2都存在的问题:
若数据中90%的样本对应的目标值为150,剩下10%在0到30之间。
那么使用MAE作为损失函数的模型可能会忽视10%的异常点,而对所有样本的预测值都为150,因为模型会按中位数来预测;
MSE的模型则会给出很多介于0到30的预测值,因为模型会向异常点偏移。
这些情况下最简单的办法是对目标变量进行变换。而另一种办法则是换一个损失函数,这就引出了下面要讲的第三种损失函数,即Huber损失函数。
Huber损失,平滑的平均绝对误差
Huber损失对数据中的异常点没有平方误差损失那么敏感。
本质上,Huber损失是绝对误差,只是在误差很小时,就变为平方误差。误差降到多小时变为二次误差由超参数δ(delta)来控制。当Huber损失在[0-δ,0+δ]之间时,等价为MSE,而在[-∞,δ]和[δ,+∞]时为MAE。
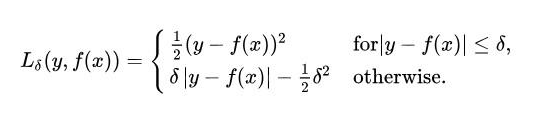
Huber损失结合了MSE和MAE的优点,对异常点更加鲁棒。
L1、L2损失函数、Huber损失函数的更多相关文章
- 回归损失函数:L1,L2,Huber,Log-Cosh,Quantile Loss
回归损失函数:L1,L2,Huber,Log-Cosh,Quantile Loss 2019-06-04 20:09:34 clover_my 阅读数 430更多 分类专栏: 阅读笔记 版权声明: ...
- 机器学习之正则化【L1 & L2】
前言 L1.L2在机器学习方向有两种含义:一是L1范数.L2范数的损失函数,二是L1.L2正则化 L1范数.L2范数损失函数 L1范数损失函数: L2范数损失函数: L1.L2分别对应损失函数中的绝对 ...
- 正则化 L1 L2
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1ℓ1-norm和ℓ2ℓ2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数. L1正则化和 ...
- ML-线性模型 泛化优化 之 L1 L2 正则化
认识 L1, L2 从效果上来看, 正则化通过, 对ML的算法的任意修改, 达到减少泛化错误, 但不减少训练误差的方式的统称 训练误差 这个就损失函数什么的, 很好理解. 泛化错误 假设 我们知道 预 ...
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
- L0/L1/L2范数的联系与区别
L0/L1/L2范数的联系与区别 标签(空格分隔): 机器学习 最近快被各大公司的笔试题淹没了,其中有一道题是从贝叶斯先验,优化等各个方面比较L0.L1.L2范数的联系与区别. L0范数 L0范数表示 ...
- 机器学习 - 正则化L1 L2
L1 L2 Regularization 表示方式: $L_2\text{ regularization term} = ||\boldsymbol w||_2^2 = {w_1^2 + w_2^2 ...
- 阅读ARM Memory(L1/L2/MMU)笔记
<ARM Architecture Reference Manual ARMv8-A>里面有Memory层级框架图,从中可以看出L1.L2.DRAM.Disk.MMU之间的关系,以及他们在 ...
- L1&L2 Regularization的原理
L1&L2 Regularization 正则化方法:防止过拟合,提高泛化能力 在训练数据不够多时,或者overtraining时,常常会导致overfitting(过拟合).其直观的表现 ...
随机推荐
- 使用vue-i18n实现项目的国际化 以及iview的国际化
一:项目的国际化 vue-i18n官网 1. 在src中新建一个language文件夹(包含index.js.US.js.CN.js) (1)US.js 保存变量的英文,内容: export defa ...
- AcWing 244. 谜一样的牛 (树状数组+二分)打卡
题目:https://www.acwing.com/problem/content/245/ 题意:有n只牛,现在他们按一种顺序排好,现在知道每只牛前面有几只牛比自己低,牛的身高是1-n,现在求每只牛 ...
- [Repost] 常用素数
作者:Miskcoo(http://blog.miskcoo.com/2014/07/fft-prime-table) 如果 \(r\cdot 2^k+1\) 是个素数, 那么在 \(\bmod r\ ...
- [CSP-S模拟测试]:tree(DP)
题目传送门(内部题57) 输入格式 第一行包含一个数:$n$表示树的节点数.接下来$n-1$行,每行包含两个数:$u,v$表示无根树的一条边. 输出格式 输出$n$行,第$i$行包含一个浮点数,保留三 ...
- Transform.Find()
代码演示: using System.Collections;using System.Collections.Generic;using UnityEngine; public class Tran ...
- 20175120彭宇辰 《Java程序设计》第十一周学习总结
教材内容总结 第十三章 Java网络编程 一.URL类 一个URL对象包含的三个基本信息:协议.地址和资源. -协议:必须是URL对象所在的Java虚拟机支持的协议,常用的有:Http.Ftp.Fil ...
- nginx启动、关闭、重启及常用的命令
nginx常用命令 启动:cd /usr/local/nginx/sbin./nginxnginx服务启动后默认的进程号会放在/usr/local/nginx/logs/nginx.pid文件cat ...
- Cocos2d-x之Action
| 版权声明:本文为博主原创文章,未经博主允许不得转载. 在Cocos2d-x中的Node对象可以有动作,特效和动画等动态特性.因此在Node类中定义了这些动态特性,因此精灵,标签,菜单,地图和粒 ...
- [伯努利数] poj 1707 Sum of powers
题目链接: http://poj.org/problem?id=1707 Language: Default Sum of powers Time Limit: 1000MS Memory Lim ...
- Python之随机选择 random
随机选择:random import random # 从一个序列中随机的抽取一个元素 values=[1,2,3,4,56] # 指定取出N个不同元素 print(random.sample(val ...