cs224d 作业 problem set1 (二) 简单的情感分析
使用在上一篇博客中训练好的wordvector
在这一节进行情感分析。
因为在上一节中得到的是一个词就是一个向量
所以一句话便是一个矩阵,矩阵的每一列表示一个词向量
情感分析的前提是已知一句话是 (超级消极,比较消极,中立,积极,非常积极)中的一类作为训练集分别用(0,1,2,3,4)进行表示
然后通过对每一句话的矩阵按列求均值,便得到一个维数固定的向量,用这个向量作为该句话的特征向量
然后将这个向量和该句话对应的label输入softmax层进行softmax回归计算。
最后训练得到的模型便是按句子进行情感分析的语言模型(即判断该句话是以上五中情感中的哪一类)
下面的代码是生成句子的特征向量和softmax回归的函数. q4_softmaxreg.py
'''
Created on 2017年9月18日 @author: weizhen
'''
import numpy as np
import random
from data_utils import *
from q1_softmax import softmax
from q2_gradcheck import gradcheck_naive
from q3_sgd import load_saved_params def getSentenceFeature(tokens, wordVectors, sentence):
"""
对上一步训练好的词向量
对每一个句子中的全体词向量计算平均值作其特征值
并试图预测所提句子中的情感层次
超级消极,比较消极,中立,积极,非常积极
对其分别从0到4进行编码。
使用SGD来训练一个softmax回归机,
并通过不断地训练/调试验证来提高回归机的泛化能力 输入:
tokens:a dictionary that maps words to their indices in the word vector list
wordVectors: word vectors(each row) for all tokens
sentence:a list of words in the sentence of interest 输出:
sentVector:feature vector for the sentence
"""
sentVector = np.zeros((wordVectors.shape[1],))
indices = [tokens[word] for word in sentence]
sentVector = np.mean(wordVectors[indices, :], axis=0)
return sentVector def softmaxRegression(features, labels, weights, regularization=0.0, nopredictions=False):
"""Softmax Regression
完成正则化的softmax回归
输入:
features:feature vectors,each row is a feature vector
labels :labels corresponding to the feature vectors
weights :weights of the regressor
regularization:L2 regularization constant 输出:
cost:cost of the regressor
grad:gradient of the regressor cost with respect to its weights
pred:label predictions of the regressor
"""
prob = softmax(features.dot(weights))
if len(features.shape) > 1:
N = features.shape[0]
else:
N = 1
"""
a vectorized implementation of 1/N * sum(cross_entropy(x_i,y_i))+1/2*|w|^2
"""
cost = np.sum(-np.log(prob[range(N), labels])) / N
cost += 0.5 * regularization * np.sum(weights ** 2) grad = np.array(prob)
grad[range(N), labels] -= 1.0
grad = features.T.dot(grad) / N
grad += regularization * weights if N > 1:
pred = np.argmax(prob, axis=1)
else:
pred = np.argmax(prob) if nopredictions:
return cost, grad
else:
return cost, grad, pred def accuracy(y, yhat):
"""Precision for classifier"""
assert(y.shape == yhat.shape)
return np.sum(y == yhat) * 100.0 / y.size def softmax_wrapper(features, labels, weights, regularization=0.0):
cost, grad, _ = softmaxRegression(features, labels, weights, regularization)
return cost, grad def sanity_check():
"""
Run python q4_softmaxreg.py
"""
random.seed(314159)
np.random.seed(265) dataset = StanfordSentiment()
tokens = dataset.tokens()
nWords = len(tokens) _, wordVectors0, _ = load_saved_params()
wordVectors = (wordVectors0[:nWords, :] + wordVectors0[nWords:, :])
dimVectors = wordVectors.shape[1] dummy_weights = 0.1 * np.random.randn(dimVectors, 5)
dummy_features = np.zeros((10, dimVectors))
dummy_labels = np.zeros((10,), dtype=np.int32)
for i in range(10):
words, dummy_labels[i] = dataset.getRandomTrainSentence()
dummy_features[i, :] = getSentenceFeature(tokens, wordVectors, words)
print("====Gradient check for softmax regression=========")
gradcheck_naive(lambda weights:softmaxRegression(dummy_features, dummy_labels, weights, 1.0, nopredictions=True), dummy_weights)
print("=======Results============")
print(softmaxRegression(dummy_features, dummy_labels, dummy_weights, 1.0)) if __name__ == "__main__":
sanity_check()
以下的代码是使用SGD(随机梯度下降方法)进行softmax模型回归训练,并且通过使用不同的正则化参数,比较了模型在测试集,训练集上的不同的误差大小。q4_sentiment.py
'''
Created on 2017年9月19日 @author: weizhen
'''
import numpy as np
import matplotlib.pyplot as plt from data_utils import *
from q3_sgd import load_saved_params, sgd
from q4_softmaxreg import softmaxRegression, getSentenceFeature, accuracy, softmax_wrapper
from data_utils import StanfordSentiment
"""
完成超参数的实现代码,从而获取最佳的惩罚因子
"""
# 尝试不同的正则化系数,选取最好的
REGULARIZATION = [0.0, 0.00001, 0.00003, 0.0001, 0.0003, 0.001, 0.003, 0.01]
# 载入数据集
dataset = StanfordSentiment()
tokens = dataset.tokens()
nWords = len(tokens) # 载入预训练好的词向量
_, wordVectors0, _ = load_saved_params()
wordVectors = (wordVectors0[:nWords, :] + wordVectors0[nWords:, :])
dimVectors = wordVectors.shape[1] # 载入训练集
trainset = dataset.getTrainSentences()
nTrain = len(trainset)
trainFeatures = np.zeros((nTrain, dimVectors))
trainLabels = np.zeros((nTrain,), dtype=np.int32)
for i in range(nTrain):
words, trainLabels[i] = trainset[i]
trainFeatures[i, :] = getSentenceFeature(tokens, wordVectors, words) # 准备好训练的特征
devset = dataset.getDevSentences()
nDev = len(devset)
devFeatures = np.zeros((nDev, dimVectors))
devLabels = np.zeros((nDev,), dtype=np.int32)
for i in range(nDev):
words, devLabels[i] = devset[i]
devFeatures[i, :] = getSentenceFeature(tokens, wordVectors, words) # 尝试不同的正则化系数
results = []
for regularization in REGULARIZATION:
random.seed(3141)
np.random.seed(59265)
weights = np.random.randn(dimVectors, 5)
print("Training for reg=%f" % regularization) # batch optimization
weights = sgd(lambda weights:softmax_wrapper(trainFeatures, trainLabels, weights, regularization), weights, 3.0, 10000, PRINT_EVERY=100) # 训练集上测效果
_, _, pred = softmaxRegression(trainFeatures, trainLabels, weights)
trainAccuracy = accuracy(trainLabels, pred)
print("Train accuracy (%%):%f" % trainAccuracy) # dev集合上看效果
_, _, pred = softmaxRegression(devFeatures, devLabels, weights)
devAccuracy = accuracy(devLabels, pred)
print("Dev accuracy (%%):%f" % devAccuracy) # 保存结果权重
results.append({
"reg":regularization,
"weights":weights,
"train":trainAccuracy,
"dev":devAccuracy
})
# 输出准确率
print(" ")
print("===Recap===")
print("Reg\t\tTrain\t\tDev")
for result in results:
print("%E\t%f\t%f" % (result["reg"], result["train"], result["dev"])) print(" ") best_dev = 0
for result in results:
if result["dev"] > best_dev:
best_dev = result["dev"]
BEST_REGULARIZATION = result["reg"]
BEST_WEIGHTS = result["weights"] # Test your findings on the test set
testset = dataset.getTrainSentences()
nTest = len(testset)
testFeatures = np.zeros((nTest, dimVectors))
testLabels = np.zeros((nTest,), dtype=np.int32)
for i in range(nTest):
words, testLabels[i] = testset[i]
testFeatures[i, :] = getSentenceFeature(tokens, wordVectors, words) _, _, pred = softmaxRegression(testFeatures, testLabels, BEST_WEIGHTS)
print("Best regularization value:%E" % BEST_REGULARIZATION)
print("Test accuracy (%%):%f" % accuracy(testLabels, pred)) # 画出正则化和准确率的关系
plt.plot(REGULARIZATION, [x["train"] for x in results])
plt.plot(REGULARIZATION, [x["dev"] for x in results])
plt.xscale('log')
plt.xlabel("regularization")
plt.ylabel("accuracy")
plt.legend(['train', 'dev'], loc='upper left')
plt.savefig("q4_reg_v_acc.png")
plt.show()
训练过程中输出的log如下所示,感觉这个随机梯度下降速度还是非常快的
Training for reg=0.000000
iter#100,cost=55.80770312357766
iter#200,cost=113.26516427955131
iter#300,cost=170.77662506220236
iter#400,cost=228.2905711144178
iter#500,cost=285.80464483901727
iter#600,cost=343.3187251832418
iter#700,cost=400.83280587095913
C:\Users\weizhen\workspace\Word2vector\q4_softmaxreg.py:58: RuntimeWarning: divide by zero encountered in log
cost = np.sum(-np.log(prob[range(N), labels])) / N
iter#800,cost=inf
iter#900,cost=inf
iter#1000,cost=inf
iter#1100,cost=inf
iter#1200,cost=inf
iter#1300,cost=inf
iter#1400,cost=inf
iter#1500,cost=inf
iter#1600,cost=inf
iter#1700,cost=inf
iter#1800,cost=inf
iter#1900,cost=inf
iter#2000,cost=inf
iter#2100,cost=inf
iter#2200,cost=inf
iter#2300,cost=inf
iter#2400,cost=inf
iter#2500,cost=inf
iter#2600,cost=inf
iter#2700,cost=inf
iter#2800,cost=inf
iter#2900,cost=inf
iter#3000,cost=inf
iter#3100,cost=inf
iter#3200,cost=inf
iter#3300,cost=inf
iter#3400,cost=inf
iter#3500,cost=inf
iter#3600,cost=inf
iter#3700,cost=inf
iter#3800,cost=inf
iter#3900,cost=inf
iter#4000,cost=inf
iter#4100,cost=inf
iter#4200,cost=inf
iter#4300,cost=inf
iter#4400,cost=inf
iter#4500,cost=inf
iter#4600,cost=inf
iter#4700,cost=inf
iter#4800,cost=inf
iter#4900,cost=inf
iter#5000,cost=inf
iter#5100,cost=inf
iter#5200,cost=inf
iter#5300,cost=inf
iter#5400,cost=inf
iter#5500,cost=inf
iter#5600,cost=inf
iter#5700,cost=inf
iter#5800,cost=inf
iter#5900,cost=inf
iter#6000,cost=inf
iter#6100,cost=inf
iter#6200,cost=inf
iter#6300,cost=inf
iter#6400,cost=inf
iter#6500,cost=inf
iter#6600,cost=inf
iter#6700,cost=inf
iter#6800,cost=inf
iter#6900,cost=inf
iter#7000,cost=inf
iter#7100,cost=inf
iter#7200,cost=inf
iter#7300,cost=inf
iter#7400,cost=inf
iter#7500,cost=inf
iter#7600,cost=inf
iter#7700,cost=inf
iter#7800,cost=inf
iter#7900,cost=inf
iter#8000,cost=inf
iter#8100,cost=inf
iter#8200,cost=inf
iter#8300,cost=inf
iter#8400,cost=inf
iter#8500,cost=inf
iter#8600,cost=inf
iter#8700,cost=inf
iter#8800,cost=inf
iter#8900,cost=inf
iter#9000,cost=inf
iter#9100,cost=inf
iter#9200,cost=inf
iter#9300,cost=inf
iter#9400,cost=inf
iter#9500,cost=inf
iter#9600,cost=inf
iter#9700,cost=inf
iter#9800,cost=inf
iter#9900,cost=inf
iter#10000,cost=inf
Train accuracy (%):13.623596
Dev accuracy (%):13.351499
Training for reg=0.000010
iter#100,cost=55.783274593185524
iter#200,cost=113.1576936342475
iter#300,cost=170.52790886950592
iter#400,cost=227.8417504849143
iter#500,cost=285.0963279497582
iter#600,cost=342.2910221506712
iter#700,cost=399.4253380860588
iter#800,cost=inf
iter#900,cost=inf
iter#1000,cost=inf
iter#1100,cost=inf
iter#1200,cost=inf
iter#1300,cost=inf
iter#1400,cost=inf
iter#1500,cost=inf
iter#1600,cost=inf
iter#1700,cost=inf
iter#1800,cost=inf
iter#1900,cost=inf
iter#2000,cost=inf
iter#2100,cost=inf
iter#2200,cost=inf
iter#2300,cost=inf
iter#2400,cost=inf
iter#2500,cost=inf
iter#2600,cost=inf
iter#2700,cost=inf
iter#2800,cost=inf
iter#2900,cost=inf
iter#3000,cost=inf
iter#3100,cost=inf
iter#3200,cost=inf
iter#3300,cost=inf
iter#3400,cost=inf
iter#3500,cost=inf
iter#3600,cost=inf
iter#3700,cost=inf
iter#3800,cost=inf
iter#3900,cost=inf
iter#4000,cost=inf
iter#4100,cost=inf
iter#4200,cost=inf
iter#4300,cost=inf
iter#4400,cost=inf
iter#4500,cost=inf
iter#4600,cost=inf
iter#4700,cost=inf
iter#4800,cost=inf
iter#4900,cost=inf
iter#5000,cost=inf
iter#5100,cost=inf
iter#5200,cost=inf
iter#5300,cost=inf
iter#5400,cost=inf
iter#5500,cost=inf
iter#5600,cost=inf
iter#5700,cost=inf
iter#5800,cost=inf
iter#5900,cost=inf
iter#6000,cost=inf
iter#6100,cost=inf
iter#6200,cost=inf
iter#6300,cost=inf
iter#6400,cost=inf
iter#6500,cost=inf
iter#6600,cost=inf
iter#6700,cost=inf
iter#6800,cost=inf
iter#6900,cost=inf
iter#7000,cost=inf
iter#7100,cost=inf
iter#7200,cost=inf
iter#7300,cost=inf
iter#7400,cost=inf
iter#7500,cost=inf
iter#7600,cost=inf
iter#7700,cost=inf
iter#7800,cost=inf
iter#7900,cost=inf
iter#8000,cost=inf
iter#8100,cost=inf
iter#8200,cost=inf
iter#8300,cost=inf
iter#8400,cost=inf
iter#8500,cost=inf
iter#8600,cost=inf
iter#8700,cost=inf
iter#8800,cost=inf
iter#8900,cost=inf
iter#9000,cost=inf
iter#9100,cost=inf
iter#9200,cost=inf
iter#9300,cost=inf
iter#9400,cost=inf
iter#9500,cost=inf
iter#9600,cost=inf
iter#9700,cost=inf
iter#9800,cost=inf
iter#9900,cost=inf
iter#10000,cost=inf
Train accuracy (%):13.623596
Dev accuracy (%):13.351499
Training for reg=0.000030
iter#100,cost=55.733908094897714
iter#200,cost=112.93871229583235
iter#300,cost=170.01697204788633
iter#400,cost=226.91242396364854
iter#500,cost=283.61845393137014
iter#600,cost=340.130913646296
iter#700,cost=396.44591922348985
iter#800,cost=inf
iter#900,cost=inf
iter#1000,cost=inf
iter#1100,cost=inf
iter#1200,cost=inf
iter#1300,cost=inf
iter#1400,cost=inf
iter#1500,cost=inf
iter#1600,cost=inf
iter#1700,cost=inf
iter#1800,cost=inf
iter#1900,cost=inf
iter#2000,cost=inf
iter#2100,cost=inf
iter#2200,cost=inf
iter#2300,cost=inf
iter#2400,cost=inf
iter#2500,cost=inf
iter#2600,cost=inf
iter#2700,cost=inf
iter#2800,cost=inf
iter#2900,cost=inf
iter#3000,cost=inf
iter#3100,cost=inf
iter#3200,cost=inf
iter#3300,cost=inf
iter#3400,cost=inf
iter#3500,cost=inf
iter#3600,cost=inf
iter#3700,cost=inf
iter#3800,cost=inf
iter#3900,cost=inf
iter#4000,cost=inf
iter#4100,cost=inf
iter#4200,cost=inf
iter#4300,cost=inf
iter#4400,cost=inf
iter#4500,cost=inf
iter#4600,cost=inf
iter#4700,cost=inf
iter#4800,cost=inf
iter#4900,cost=inf
iter#5000,cost=inf
iter#5100,cost=inf
iter#5200,cost=inf
iter#5300,cost=inf
iter#5400,cost=inf
iter#5500,cost=inf
iter#5600,cost=inf
iter#5700,cost=inf
iter#5800,cost=inf
iter#5900,cost=inf
iter#6000,cost=inf
iter#6100,cost=inf
iter#6200,cost=inf
iter#6300,cost=inf
iter#6400,cost=inf
iter#6500,cost=inf
iter#6600,cost=inf
iter#6700,cost=inf
iter#6800,cost=inf
iter#6900,cost=inf
iter#7000,cost=inf
iter#7100,cost=inf
iter#7200,cost=inf
iter#7300,cost=inf
iter#7400,cost=inf
iter#7500,cost=inf
iter#7600,cost=inf
iter#7700,cost=inf
iter#7800,cost=inf
iter#7900,cost=inf
iter#8000,cost=inf
iter#8100,cost=inf
iter#8200,cost=inf
iter#8300,cost=inf
iter#8400,cost=inf
iter#8500,cost=inf
iter#8600,cost=inf
iter#8700,cost=inf
iter#8800,cost=inf
iter#8900,cost=inf
iter#9000,cost=inf
iter#9100,cost=inf
iter#9200,cost=inf
iter#9300,cost=inf
iter#9400,cost=inf
iter#9500,cost=inf
iter#9600,cost=inf
iter#9700,cost=inf
iter#9800,cost=inf
iter#9900,cost=inf
iter#10000,cost=inf
Train accuracy (%):13.623596
Dev accuracy (%):13.351499
Training for reg=0.000100
iter#100,cost=55.555913404316605
iter#200,cost=112.13207179048013
iter#300,cost=168.09801072210058
iter#400,cost=223.3617199957655
iter#500,cost=277.88605116153644
iter#600,cost=331.6406275348183
iter#700,cost=384.59915494623067
iter#800,cost=436.73898281616846
iter#900,cost=inf
iter#1000,cost=inf
iter#1100,cost=inf
iter#1200,cost=inf
iter#1300,cost=inf
iter#1400,cost=inf
iter#1500,cost=inf
iter#1600,cost=inf
iter#1700,cost=inf
iter#1800,cost=inf
iter#1900,cost=inf
iter#2000,cost=inf
iter#2100,cost=inf
iter#2200,cost=inf
iter#2300,cost=inf
iter#2400,cost=inf
iter#2500,cost=inf
iter#2600,cost=inf
iter#2700,cost=inf
iter#2800,cost=inf
iter#2900,cost=inf
iter#3000,cost=inf
iter#3100,cost=inf
iter#3200,cost=inf
iter#3300,cost=inf
iter#3400,cost=inf
iter#3500,cost=inf
iter#3600,cost=inf
iter#3700,cost=inf
iter#3800,cost=inf
iter#3900,cost=inf
iter#4000,cost=inf
iter#4100,cost=inf
iter#4200,cost=inf
iter#4300,cost=inf
iter#4400,cost=inf
iter#4500,cost=inf
iter#4600,cost=inf
iter#4700,cost=inf
iter#4800,cost=inf
iter#4900,cost=inf
iter#5000,cost=inf
iter#5100,cost=inf
iter#5200,cost=inf
iter#5300,cost=inf
iter#5400,cost=inf
iter#5500,cost=inf
iter#5600,cost=inf
iter#5700,cost=inf
iter#5800,cost=inf
iter#5900,cost=inf
iter#6000,cost=inf
iter#6100,cost=inf
iter#6200,cost=inf
iter#6300,cost=inf
iter#6400,cost=inf
iter#6500,cost=inf
iter#6600,cost=inf
iter#6700,cost=inf
iter#6800,cost=inf
iter#6900,cost=inf
iter#7000,cost=inf
iter#7100,cost=inf
iter#7200,cost=inf
iter#7300,cost=inf
iter#7400,cost=inf
iter#7500,cost=inf
iter#7600,cost=inf
iter#7700,cost=inf
iter#7800,cost=inf
iter#7900,cost=inf
iter#8000,cost=inf
iter#8100,cost=inf
iter#8200,cost=inf
iter#8300,cost=inf
iter#8400,cost=inf
iter#8500,cost=inf
iter#8600,cost=inf
iter#8700,cost=inf
iter#8800,cost=inf
iter#8900,cost=inf
iter#9000,cost=inf
iter#9100,cost=inf
iter#9200,cost=inf
iter#9300,cost=inf
iter#9400,cost=inf
iter#9500,cost=inf
iter#9600,cost=inf
iter#9700,cost=inf
iter#9800,cost=inf
iter#9900,cost=inf
iter#10000,cost=inf
Train accuracy (%):13.600187
Dev accuracy (%):13.169846
Training for reg=0.000300
iter#100,cost=55.00595210314415
iter#200,cost=109.5333104576623
iter#300,cost=161.7381100668071
iter#400,cost=211.38762873096093
iter#500,cost=258.3796618306362
iter#600,cost=302.67623521301323
iter#700,cost=344.2868074645255
iter#800,cost=383.2567327327972
iter#900,cost=419.6581025580854
iter#1000,cost=453.58239168137726
iter#1100,cost=485.1345714574452
iter#1200,cost=inf
iter#1300,cost=inf
iter#1400,cost=inf
iter#1500,cost=inf
iter#1600,cost=inf
iter#1700,cost=inf
iter#1800,cost=inf
iter#1900,cost=inf
iter#2000,cost=inf
iter#2100,cost=inf
iter#2200,cost=inf
iter#2300,cost=inf
iter#2400,cost=inf
iter#2500,cost=inf
iter#2600,cost=inf
iter#2700,cost=inf
iter#2800,cost=inf
iter#2900,cost=inf
iter#3000,cost=inf
iter#3100,cost=inf
iter#3200,cost=inf
iter#3300,cost=inf
iter#3400,cost=inf
iter#3500,cost=inf
iter#3600,cost=inf
iter#3700,cost=inf
iter#3800,cost=inf
iter#3900,cost=inf
iter#4000,cost=inf
iter#4100,cost=inf
iter#4200,cost=inf
iter#4300,cost=inf
iter#4400,cost=inf
iter#4500,cost=inf
iter#4600,cost=inf
iter#4700,cost=inf
iter#4800,cost=inf
iter#4900,cost=inf
iter#5000,cost=inf
iter#5100,cost=inf
iter#5200,cost=inf
iter#5300,cost=inf
iter#5400,cost=inf
iter#5500,cost=inf
iter#5600,cost=inf
iter#5700,cost=inf
iter#5800,cost=inf
iter#5900,cost=inf
iter#6000,cost=inf
iter#6100,cost=inf
iter#6200,cost=inf
iter#6300,cost=inf
iter#6400,cost=inf
iter#6500,cost=inf
iter#6600,cost=inf
iter#6700,cost=inf
iter#6800,cost=inf
iter#6900,cost=inf
iter#7000,cost=inf
iter#7100,cost=inf
iter#7200,cost=inf
iter#7300,cost=inf
iter#7400,cost=inf
iter#7500,cost=inf
iter#7600,cost=inf
iter#7700,cost=inf
iter#7800,cost=inf
iter#7900,cost=inf
iter#8000,cost=inf
iter#8100,cost=inf
iter#8200,cost=inf
iter#8300,cost=inf
iter#8400,cost=inf
iter#8500,cost=inf
iter#8600,cost=inf
iter#8700,cost=inf
iter#8800,cost=inf
iter#8900,cost=inf
iter#9000,cost=inf
iter#9100,cost=inf
iter#9200,cost=inf
iter#9300,cost=inf
iter#9400,cost=inf
iter#9500,cost=inf
iter#9600,cost=inf
iter#9700,cost=inf
iter#9800,cost=inf
iter#9900,cost=inf
iter#10000,cost=inf
Train accuracy (%):26.884363
Dev accuracy (%):25.340599
Training for reg=0.001000
iter#100,cost=52.70927259731105
iter#200,cost=98.50597258376452
iter#300,cost=135.55092745073773
iter#400,cost=164.67768614426865
iter#500,cost=187.1734394014672
iter#600,cost=204.3396827449289
iter#700,cost=217.3297803631474
iter#800,cost=227.10158270618547
iter#900,cost=234.42124979570002
iter#1000,cost=239.88729673052336
iter#1100,cost=243.96001255674346
iter#1200,cost=246.98960876193254
iter#1300,cost=249.24055160501223
iter#1400,cost=250.91149258138643
iter#1500,cost=252.15107535333902
iter#1600,cost=253.07021555249503
iter#1700,cost=253.7515090665275
iter#1800,cost=254.2563716018845
iter#1900,cost=254.63042020679455
iter#2000,cost=254.90751017855177
iter#2100,cost=255.11275282803217
iter#2200,cost=255.2647657128228
iter#2300,cost=255.37734746741998
iter#2400,cost=255.4607226865884
iter#2500,cost=255.5224663178653
iter#2600,cost=255.56818957210155
iter#2700,cost=255.60204860388984
iter#2800,cost=255.62712160606557
iter#2900,cost=255.64568827509464
iter#3000,cost=255.65943687846433
iter#3100,cost=255.66961765483308
iter#3200,cost=255.67715644281037
iter#3300,cost=255.6827388423264
iter#3400,cost=255.6868725463425
iter#3500,cost=255.68993350282864
iter#3600,cost=255.69220010045092
iter#3700,cost=255.69387848443705
iter#3800,cost=255.69512130362006
iter#3900,cost=255.6960415929005
iter#4000,cost=255.69672305330522
iter#4100,cost=255.69722766437994
iter#4200,cost=255.69760132114078
iter#4300,cost=255.69787800820194
iter#4400,cost=255.6980828906762
iter#4500,cost=255.69823460295643
iter#4600,cost=255.69834694353008
iter#4700,cost=255.69843012996608
iter#4800,cost=255.69849172821802
iter#4900,cost=255.69853734075687
iter#5000,cost=255.69857111612546
iter#5100,cost=255.69859612625504
iter#5200,cost=255.69861464586282
iter#5300,cost=255.69862835934086
iter#5400,cost=255.69863851395561
iter#5500,cost=255.6986460332883
iter#5600,cost=255.69865160123553
iter#5700,cost=255.69865572421295
iter#5800,cost=255.6986587772128
iter#5900,cost=255.6986610379111
iter#6000,cost=255.6986627119228
iter#6100,cost=255.69866395150189
iter#6200,cost=255.69866486939068
iter#6300,cost=255.698665549073
iter#6400,cost=255.69866605236703
iter#6500,cost=255.69866642504832
iter#6600,cost=255.69866670101302
iter#6700,cost=255.69866690536037
iter#6800,cost=255.6986670566768
iter#6900,cost=255.698667168724
iter#7000,cost=255.69866725169328
iter#7100,cost=255.69866731313053
iter#7200,cost=255.69866735862394
iter#7300,cost=255.69866739231105
iter#7400,cost=255.69866741725588
iter#7500,cost=255.69866743572723
iter#7600,cost=255.6986674494048
iter#7700,cost=255.69866745953283
iter#7800,cost=255.69866746703244
iter#7900,cost=255.6986674725857
iter#8000,cost=255.6986674766978
iter#8100,cost=255.69866747974302
iter#8200,cost=255.69866748199792
iter#8300,cost=255.69866748366752
iter#8400,cost=255.69866748490375
iter#8500,cost=255.69866748581921
iter#8600,cost=255.69866748649707
iter#8700,cost=255.6986674869992
iter#8800,cost=255.6986674873709
iter#8900,cost=255.69866748764613
iter#9000,cost=255.6986674878499
iter#9100,cost=255.6986674880009
iter#9200,cost=255.69866748811256
iter#9300,cost=255.69866748819533
iter#9400,cost=255.69866748825658
iter#9500,cost=255.69866748830182
iter#9600,cost=255.69866748833562
iter#9700,cost=255.69866748836034
iter#9800,cost=255.69866748837904
iter#9900,cost=255.69866748839206
iter#10000,cost=255.69866748840226
Train accuracy (%):27.083333
Dev accuracy (%):25.340599
Training for reg=0.003000
iter#100,cost=44.87426292034912
iter#200,cost=68.0134662780099
iter#300,cost=78.13883165157826
iter#400,cost=82.36088053197292
iter#500,cost=84.09039670349404
iter#600,cost=84.79396518269795
iter#700,cost=85.07938308037015
iter#800,cost=85.19503952907226
iter#900,cost=85.24188440045062
iter#1000,cost=85.2608547253842
iter#1100,cost=85.26853638958765
iter#1200,cost=85.2716468368632
iter#1300,cost=85.27290629894894
iter#1400,cost=85.27341626964268
iter#1500,cost=85.27362276223595
iter#1600,cost=85.27370637323054
iter#1700,cost=85.27374022817936
iter#1800,cost=85.27375393639349
iter#1900,cost=85.27375948698896
iter#2000,cost=85.27376173448152
iter#2100,cost=85.27376264451414
iter#2200,cost=85.27376301299557
iter#2300,cost=85.27376316219747
iter#2400,cost=85.27376322261087
iter#2500,cost=85.27376324707288
iter#2600,cost=85.27376325697782
iter#2700,cost=85.27376326098837
iter#2800,cost=85.27376326261232
iter#2900,cost=85.27376326326981
iter#3000,cost=85.27376326353613
iter#3100,cost=85.2737632636439
iter#3200,cost=85.27376326368754
iter#3300,cost=85.2737632637052
iter#3400,cost=85.27376326371234
iter#3500,cost=85.27376326371515
iter#3600,cost=85.27376326371623
iter#3700,cost=85.27376326371623
iter#3800,cost=85.27376326371623
iter#3900,cost=85.27376326371623
iter#4000,cost=85.27376326371623
iter#4100,cost=85.27376326371623
iter#4200,cost=85.27376326371623
iter#4300,cost=85.27376326371623
iter#4400,cost=85.27376326371623
iter#4500,cost=85.27376326371623
iter#4600,cost=85.27376326371623
iter#4700,cost=85.27376326371623
iter#4800,cost=85.27376326371623
iter#4900,cost=85.27376326371623
iter#5000,cost=85.27376326371623
iter#5100,cost=85.27376326371623
iter#5200,cost=85.27376326371623
iter#5300,cost=85.27376326371623
iter#5400,cost=85.27376326371623
iter#5500,cost=85.27376326371623
iter#5600,cost=85.27376326371623
iter#5700,cost=85.27376326371623
iter#5800,cost=85.27376326371623
iter#5900,cost=85.27376326371623
iter#6000,cost=85.27376326371623
iter#6100,cost=85.27376326371623
iter#6200,cost=85.27376326371623
iter#6300,cost=85.27376326371623
iter#6400,cost=85.27376326371623
iter#6500,cost=85.27376326371623
iter#6600,cost=85.27376326371623
iter#6700,cost=85.27376326371623
iter#6800,cost=85.27376326371623
iter#6900,cost=85.27376326371623
iter#7000,cost=85.27376326371623
iter#7100,cost=85.27376326371623
iter#7200,cost=85.27376326371623
iter#7300,cost=85.27376326371623
iter#7400,cost=85.27376326371623
iter#7500,cost=85.27376326371623
iter#7600,cost=85.27376326371623
iter#7700,cost=85.27376326371623
iter#7800,cost=85.27376326371623
iter#7900,cost=85.27376326371623
iter#8000,cost=85.27376326371623
iter#8100,cost=85.27376326371623
iter#8200,cost=85.27376326371623
iter#8300,cost=85.27376326371623
iter#8400,cost=85.27376326371623
iter#8500,cost=85.27376326371623
iter#8600,cost=85.27376326371623
iter#8700,cost=85.27376326371623
iter#8800,cost=85.27376326371623
iter#8900,cost=85.27376326371623
iter#9000,cost=85.27376326371623
iter#9100,cost=85.27376326371623
iter#9200,cost=85.27376326371623
iter#9300,cost=85.27376326371623
iter#9400,cost=85.27376326371623
iter#9500,cost=85.27376326371623
iter#9600,cost=85.27376326371623
iter#9700,cost=85.27376326371623
iter#9800,cost=85.27376326371623
iter#9900,cost=85.27376326371623
iter#10000,cost=85.27376326371623
Train accuracy (%):27.083333
Dev accuracy (%):25.340599
Training for reg=0.010000
iter#100,cost=24.75784233489464
iter#200,cost=26.23418217255656
iter#300,cost=26.305377714234208
iter#400,cost=26.308763117953248
iter#500,cost=26.30892399422158
iter#600,cost=26.308931638996803
iter#700,cost=26.308932002276617
iter#800,cost=26.308932019539853
iter#900,cost=26.308932020360217
iter#1000,cost=26.30893202039921
iter#1100,cost=26.30893202040106
iter#1200,cost=26.308932020401073
iter#1300,cost=26.308932020401073
iter#1400,cost=26.308932020401073
iter#1500,cost=26.308932020401073
iter#1600,cost=26.308932020401073
iter#1700,cost=26.308932020401073
iter#1800,cost=26.308932020401073
iter#1900,cost=26.308932020401073
iter#2000,cost=26.308932020401073
iter#2100,cost=26.308932020401073
iter#2200,cost=26.308932020401073
iter#2300,cost=26.308932020401073
iter#2400,cost=26.308932020401073
iter#2500,cost=26.308932020401073
iter#2600,cost=26.308932020401073
iter#2700,cost=26.308932020401073
iter#2800,cost=26.308932020401073
iter#2900,cost=26.308932020401073
iter#3000,cost=26.308932020401073
iter#3100,cost=26.308932020401073
iter#3200,cost=26.308932020401073
iter#3300,cost=26.308932020401073
iter#3400,cost=26.308932020401073
iter#3500,cost=26.308932020401073
iter#3600,cost=26.308932020401073
iter#3700,cost=26.308932020401073
iter#3800,cost=26.308932020401073
iter#3900,cost=26.308932020401073
iter#4000,cost=26.308932020401073
iter#4100,cost=26.308932020401073
iter#4200,cost=26.308932020401073
iter#4300,cost=26.308932020401073
iter#4400,cost=26.308932020401073
iter#4500,cost=26.308932020401073
iter#4600,cost=26.308932020401073
iter#4700,cost=26.308932020401073
iter#4800,cost=26.308932020401073
iter#4900,cost=26.308932020401073
iter#5000,cost=26.308932020401073
iter#5100,cost=26.308932020401073
iter#5200,cost=26.308932020401073
iter#5300,cost=26.308932020401073
iter#5400,cost=26.308932020401073
iter#5500,cost=26.308932020401073
iter#5600,cost=26.308932020401073
iter#5700,cost=26.308932020401073
iter#5800,cost=26.308932020401073
iter#5900,cost=26.308932020401073
iter#6000,cost=26.308932020401073
iter#6100,cost=26.308932020401073
iter#6200,cost=26.308932020401073
iter#6300,cost=26.308932020401073
iter#6400,cost=26.308932020401073
iter#6500,cost=26.308932020401073
iter#6600,cost=26.308932020401073
iter#6700,cost=26.308932020401073
iter#6800,cost=26.308932020401073
iter#6900,cost=26.308932020401073
iter#7000,cost=26.308932020401073
iter#7100,cost=26.308932020401073
iter#7200,cost=26.308932020401073
iter#7300,cost=26.308932020401073
iter#7400,cost=26.308932020401073
iter#7500,cost=26.308932020401073
iter#7600,cost=26.308932020401073
iter#7700,cost=26.308932020401073
iter#7800,cost=26.308932020401073
iter#7900,cost=26.308932020401073
iter#8000,cost=26.308932020401073
iter#8100,cost=26.308932020401073
iter#8200,cost=26.308932020401073
iter#8300,cost=26.308932020401073
iter#8400,cost=26.308932020401073
iter#8500,cost=26.308932020401073
iter#8600,cost=26.308932020401073
iter#8700,cost=26.308932020401073
iter#8800,cost=26.308932020401073
iter#8900,cost=26.308932020401073
iter#9000,cost=26.308932020401073
iter#9100,cost=26.308932020401073
iter#9200,cost=26.308932020401073
iter#9300,cost=26.308932020401073
iter#9400,cost=26.308932020401073
iter#9500,cost=26.308932020401073
iter#9600,cost=26.308932020401073
iter#9700,cost=26.308932020401073
iter#9800,cost=26.308932020401073
iter#9900,cost=26.308932020401073
iter#10000,cost=26.308932020401073
Train accuracy (%):27.083333
Dev accuracy (%):25.340599 ===Recap===
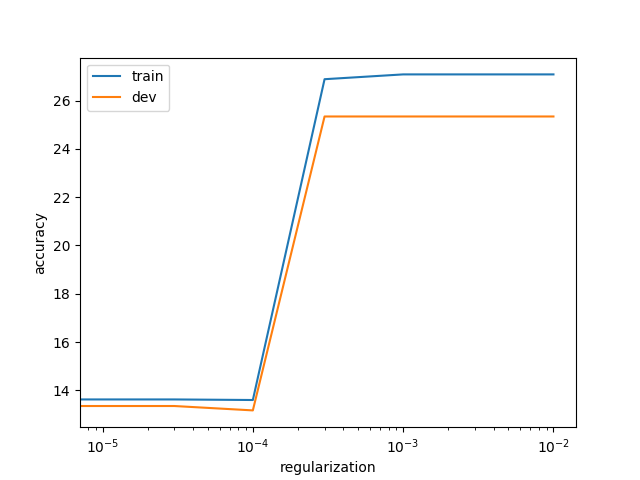
Reg Train Dev
0.000000E+00 13.623596 13.351499
1.000000E-05 13.623596 13.351499
3.000000E-05 13.623596 13.351499
1.000000E-04 13.600187 13.169846
3.000000E-04 26.884363 25.340599
1.000000E-03 27.083333 25.340599
3.000000E-03 27.083333 25.340599
1.000000E-02 27.083333 25.340599 Best regularization value:3.000000E-04
Test accuracy (%):26.884363
下边是不同的正则化参数,输出的不同的误差变化
更完整的代码详见:https://github.com/weizhenzhao/cs224d_natural_language_processing
cs224d 作业 problem set1 (二) 简单的情感分析的更多相关文章
- cs224d 作业 problem set1 (一) 主要是实现word2vector模型,SGD,CBOW,Softmax,算法
''' Created on 2017年9月13日 @author: weizhen ''' import numpy as np def sigmoid(x): return 1 / (1 + np ...
- cs224d 作业 problem set2 (二) TensorFlow 实现命名实体识别
神经网络在命名实体识别中的应用 所有的这些包括之前的两篇都可以通过tensorflow 模型的托管部署到 google cloud 上面,发布成restful接口,从而与任何的ERP,CRM系统集成. ...
- cs224d 作业 problem set2 (三) 用RNNLM模型实现Language Model,来预测下一个单词的出现
今天将的还是cs224d 的problem set2 的第三部分习题, 原来国外大学的系统难度真的如此之大,相比之下还是默默地再天朝继续搬砖吧 下面讲述一下RNN语言建模的数学公式: 给出一串连续 ...
- cs224d 作业 problem set3 (一) 实现Recursive Nerual Net Work 递归神经网络
1.Recursive Nerual Networks能够更好地体现每个词与词之间语法上的联系这里我们选取的损失函数仍然是交叉熵函数 2.整个网络的结构如下图所示: 每个参数的更新时的梯队值如何计算, ...
- cs224d 作业 problem set2 (一) 用tensorflow纯手写实现sofmax 函数,线性判别分析,命名实体识别
Hi Dear Today we will use tensorflow to implement the softmax regression and linear classifier algor ...
- NetAnalyzer笔记 之 二. 简单的协议分析
[创建时间:2015-08-27 22:15:17] NetAnalyzer下载地址 上篇我们回顾完了NetAnalyzer一些可有可无的历史,在本篇,我决定先不对NetAnalyzer做介绍,而是先 ...
- 情感分析的现代方法(包含word2vec Doc2Vec)
英文原文地址:https://districtdatalabs.silvrback.com/modern-methods-for-sentiment-analysis 转载文章地址:http://da ...
- R语言︱情感分析—基于监督算法R语言实现(二)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:本文大多内容来自未出版的<数据 ...
- 文本情感分析(二):基于word2vec、glove和fasttext词向量的文本表示
上一篇博客用词袋模型,包括词频矩阵.Tf-Idf矩阵.LSA和n-gram构造文本特征,做了Kaggle上的电影评论情感分类题. 这篇博客还是关于文本特征工程的,用词嵌入的方法来构造文本特征,也就是用 ...
随机推荐
- SVG开发包, 20 个有用的 SVG 工具,提供更好的图像处理
20 个有用的 SVG 工具,提供更好的图像处理 SVG 现正在 Web 设计领域变得越发流行, 你可以使用 Illustrator 或者 Inkscape 来创建 SVG 图像. 但当进行 Web ...
- windows10 cortana 不能搜索解决办法
不太确定是某次系统更新或安装VS软件之后, 发现windows10 cortana 搜索的结果是空白了, 搜索了相关帖子, 试遍所有方法都无效, 最后在联网的情况下, 只用了在powershell中重 ...
- configure error C compiler cannot create executables错误解决
我们在编译软件的时候,是不是经常遇到下面的错误信息呢? checking build system type... i686-pc-linux-gnuchecking host system ty ...
- 在BUG分支下创建分支,开发后合并到bus分支
在BUG分支下创建分支 1.切换到bus分支 2,创建新分支 git checkout -b bugfix/fix_vedio_0627 3,把创建的分支push到远程分支 git push orig ...
- Django 上下文管理器的应用
使用场景:模板继承可以减少页面内容的重复定义,实现页面内容的重用.个人博客右侧的导航栏都是继承base页面从而让代码得到最大程度的复用.但是当父模板中有动态数据的话,这些动态数据在子模版中是不会显示的 ...
- Spring Boot开启的2种方式
Spring Boot依赖 使用Spring Boot很简单,先添加基础依赖包,有以下两种方式 1. 继承spring-boot-starter-parent项目 <parent> < ...
- 网关中加入熔断机制(Hystrix)
网关中加入熔断机制 在网关中加入熔断机制 添加依赖项 spring-cloud-gateway项目POM文件加入spring-cloud-starter-netflix-hystrix <dep ...
- 金额格式化,例子:fmoney("12345.675910", 3),返回12,345.676
/** * 金额格式化 * 例子:fmoney("12345.675910", 3),返回12,345.676 * @data 备注lhh 2016-09-18 */ functi ...
- LINUX查看服务器硬件配置(转)
LINUX查看硬件配置 1. 查看所有硬件的型号 dmidecode | more # dmidecode 2.2 SMBIOS 2.5 present. 170 structures oc ...
- min-element & max_element
C++ STL之min_element()与max_element()(取容器中的最大最小值) min_element()和max_element 头文件:#include<algorithm& ...