大数据笔记(十九)——数据采集引擎Sqoop和Flume安装测试详解
一.Sqoop数据采集引擎
采集关系型数据库中的数据
用在离线计算的应用中
强调:批量
(1)数据交换引擎: RDBMS <---> Sqoop <---> HDFS、HBase、Hive
(2)底层依赖MapReduce
(3)依赖JDBC
(4)安装:tar -zxvf sqoop-1.4.5.bin__hadoop-0.23.tar.gz -C ~/training/
设置环境变量:
SQOOP_HOME=/root/training/sqoop-1.4.5.bin__hadoop-0.23
export SQOOP_HOME PATH=$SQOOP_HOME/bin:$PATH
export PATH
注意:如果是Oracle数据库,大写:用户名、表名、列名
(*)codegen Generate code to interact with database records
根据表结构自动生成对应Java类
sqoop codegen --connect jdbc:oracle:thin:@192.168.153.135:1521/orcl --username SCOTT --password tiger --table EMP --outdir /root/sqoop
(*)create-hive-table Import a table definition into Hive
(*)eval Evaluate a SQL statement and display the results
在Sqoop中执行SQL
sqoop eval --connect jdbc:oracle:thin:@192.168.153.135:1521/orcl --username SCOTT --password tiger --query 'select * from emp'
(*)export Export an HDFS directory to a database table
(*)help List available commands
(*)import Import a table from a database to HDFS
导入数据
(1)导入EMP表的所有数据(HDFS上)
sqoop import --connect jdbc:oracle:thin:@192.168.153.135:1521/orcl --username SCOTT --password tiger --table EMP --target-dir /sqoop/import/emp1
(2)导入指定的列
sqoop import --connect jdbc:oracle:thin:@192.168.153.135:1521/orcl --username SCOTT --password tiger --table EMP --columns ENAME,SAL --target-dir /sqoop/import/emp2
(3) 导入订单表
sqoop import --connect jdbc:oracle:thin:@192.168.153.135:1521/orcl --username SH --password sh --table SALES --target-dir /sqoop/import/sales -m 1
错误:ERROR tool.ImportTool: Error during import: No primary key could be found for table SALES. Please specify one with --split-by or perform a sequential import with '-m 1'.
(*)import-all-tables Import tables from a database to HDFS
导入某个用户下所有的表,默认路径:/user/root
sqoop import-all-tables --connect jdbc:oracle:thin:@192.168.153.135:1521/orcl --username SCOTT --password tiger
(*)job Work with saved jobs
(*)list-databases List available databases on a server
(*) MySQL数据库:就是数据库的名字
(*) Oracle数据库:是数据库中所有用户的名字
sqoop list-databases --connect jdbc:oracle:thin:@192.168.153.135:1521/orcl --username SYSTEM --password password
(*)list-tables List available tables in a database
(*)merge Merge results of incremental imports
(*)metastore Run a standalone Sqoop metastore
(*)version Display version information
3、Flume:采集日志
用在实时计算(流式计算)的应用中
强调:实时
Flume的体系结构:
1.安装:通过winscp上传到linux
解压:tar -zxvf 安装包名字 -C ~/training
进入flume安装目录,修改配置文件:
cd conf
cp flume-env.sh.template flume-env.sh
vim flume-env.sh
找到JAVA_HOME那一列,配置成你自己的jdk路径。
2.flume监听telnet接口测试
下面通过一个简单的例子来测试一下:
在 conf目录下新建一个文件netcat-logger.conf,用来从网络接口接收数据,打印到控制台。
vim netcat-logger.conf
内容:
# example.conf: A single-node Flume configuration # Name the components on this agent
#定义这个agent中各组件的名字,给那三个组件sources,sinks,channels取个名字,是一个逻辑代号:
#a1是agent的代表。
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source 描述和配置source组件:r1
#类型, 从网络端口接收数据,在本机启动, 所以localhost, type=spoolDir采集目录源,目录里有就采
#type是类型,是采集源的具体实现,这里是接受网络端口的,netcat可以从一个网络端口接受数据的。netcat在linux里的程序就是nc,可以学习一下。
#bind绑定本机localhost。port端口号为1234。 a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 1234 # Describe the sink 描述和配置sink组件:k1
#type,下沉类型,使用logger,将数据打印到屏幕上面。
a1.sinks.k1.type = logger # Use a channel which buffers events in memory 描述和配置channel组件,此处使用是内存缓存的方式
#type类型是内存memory。
#下沉的时候是一批一批的, 下沉的时候是一个个eventChannel参数解释:
#capacity:默认该通道中最大的可以存储的event数量,1000是代表1000条数据。
#trasactionCapacity:每次最大可以从source中拿到或者送到sink中的event数量。
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel 描述和配置source channel sink之间的连接关系
#将sources和sinks绑定到channel上面。
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
在flume目录下,执行:
bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
启动命令:
#告诉flum启动一个agent。
#--conf conf指定配置参数,。
#conf/netcat-logger.conf指定采集方案的那个文件(自命名)。
#--name a1:agent的名字,即agent的名字为a1。
#-Dflume.root.logger=INFO,console给log4j传递的参数。
$ bin/flume-ng agent --conf conf --conf-file conf/netcat-logger.conf --name a1 -Dflume.root.logger=INFO,console

另起一个窗口,运行:
telnet localhost 1234
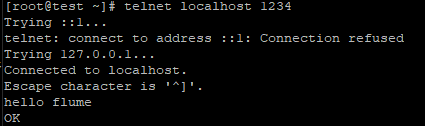
看到采集结果如下:

注:如果没有telnet,就安装一个:
yum install telnet
3.监听文件夹
监视文件夹 第一步:
首先 在flume的conf的目录下创建文件名称为:spool-logger.conf的文件。
将下面的内容复制到这个文件里面。 # Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
#监听目录,spoolDir指定目录, fileHeader要不要给文件夹前坠名
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /data/flumetest
a1.sources.r1.fileHeader = true # Describe the sink
a1.sinks.k1.type = logger # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1 第二步:根据a1.sources.r1.spoolDir = /data/flumetest 配置的文件路径,创建相应的目录。必须先创建对应的目录,不然报错。java.lang.IllegalStateException: Directory does not exist: /home/hadoop/flumespool
[root@master conf]# mkdir /data/flumetest
第三步:启动命令:
bin/flume-ng agent -c ./conf -f ./conf/spool-logger.conf -n a1 -Dflume.root.logger=INFO,console
36[root@master apache-flume-1.6.0-bin]# bin/flume-ng agent --conf conf --conf-file conf/spool-logger.conf --name a1 -Dflume.root.logger=INFO,console
第四步:测试:
往/data/flumetest放文件(mv ././xxxFile /data/flumetest)。
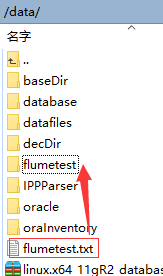
采集成功,内容被采集到了flumetest.txt.COMPLETED里面。

4.采集目录到hdfs
编写配置文件a4.conf:
#bin/flume-ng agent -n a4 -f myagent/a4.conf -c conf -Dflume.root.logger=INFO,console
#定义agent名, source、channel、sink的名称
a4.sources = r1
a4.channels = c1
a4.sinks = k1 #具体定义source 监听目录
a4.sources.r1.type = spooldir
a4.sources.r1.spoolDir = /root/training/logs #具体定义channel
a4.channels.c1.type = memory
a4.channels.c1.capacity = 10000
a4.channels.c1.transactionCapacity = 100 #定义拦截器,为消息添加时间戳
a4.sources.r1.interceptors = i1
a4.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder #具体定义sink 目的地
a4.sinks.k1.type = hdfs
a4.sinks.k1.hdfs.path = hdfs://192.168.153.11:9000/flume/%Y%m%d
a4.sinks.k1.hdfs.filePrefix = events-
a4.sinks.k1.hdfs.fileType = DataStream #不按照条数生成文件
a4.sinks.k1.hdfs.rollCount = 0
#HDFS上的文件达到128M时生成一个文件
a4.sinks.k1.hdfs.rollSize = 134217728
#HDFS上的文件达到60秒生成一个文件
a4.sinks.k1.hdfs.rollInterval = 60 #组装source、channel、sink
a4.sources.r1.channels = c1
a4.sinks.k1.channel = c1
启动Flume命令:
bin/flume-ng agent -n a4 -f myagent/a4.conf -c conf -Dflume.root.logger=INFO,console
监听 /root/training/logs 目录,有变化时:
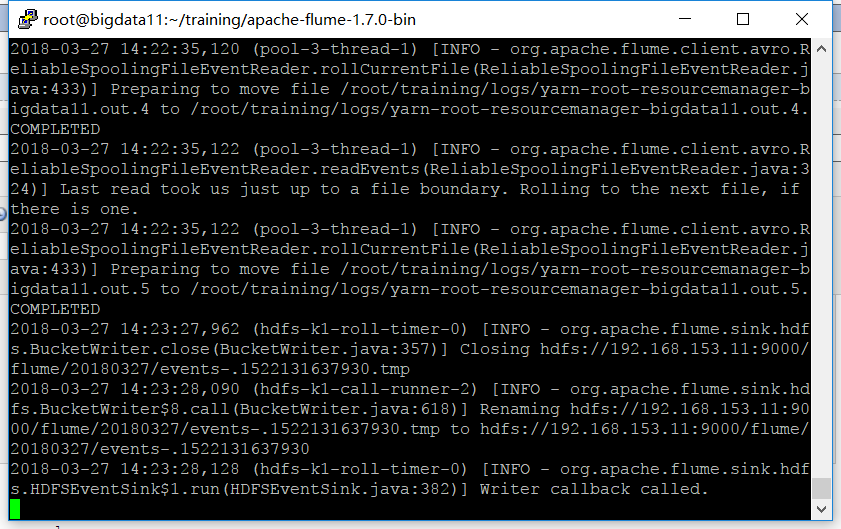
去WebUI查看,发现已经到达了hdfs:
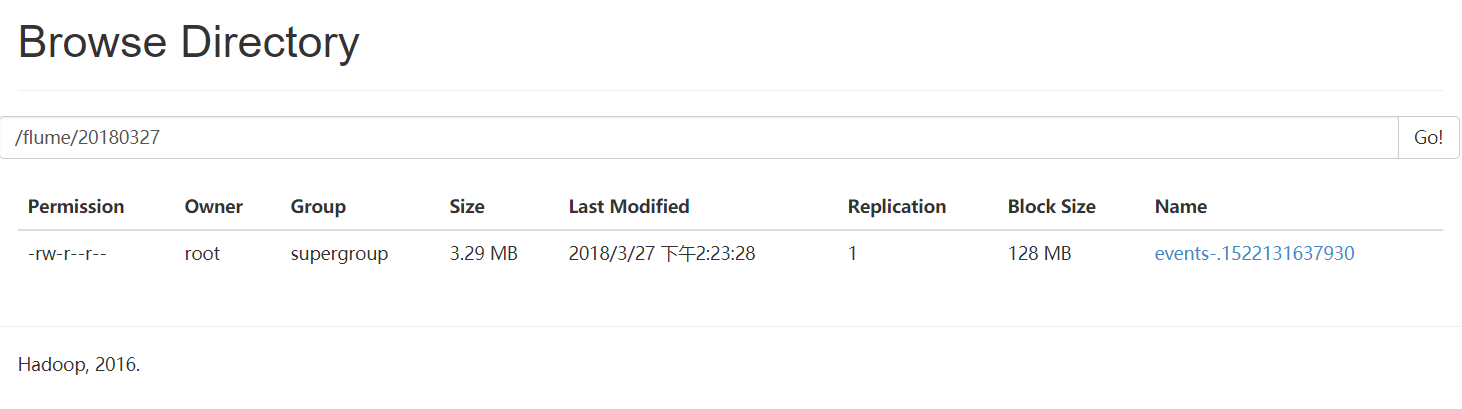
更多请见Flume官方网站:
http://flume.apache.org/FlumeUserGuide
大数据笔记(十九)——数据采集引擎Sqoop和Flume安装测试详解的更多相关文章
- “全栈2019”Java第六十九章:内部类访问外部类成员详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- 大数据笔记(九)——Mapreduce的高级特性(B)
二.排序 对象排序 员工数据 Employee.java ----> 作为key2输出 需求:按照部门和薪水升序排列 Employee.java package mr.object; impo ...
- 跟上节奏 大数据时代十大必备IT技能
跟上节奏 大数据时代十大必备IT技能 新的想法诞生新的技术,从而造出许多新词,云计算.大数据.BYOD.社交媒体……在互联网时代,各种新词层出不穷,让人应接不暇.这些新的技术,这些新兴应用和对应的IT ...
- 分布式大数据多维分析(OLAP)引擎Apache Kylin安装配置及使用示例【转】
Kylin 麒麟官网:http://kylin.apache.org/cn/download/ 关键字:olap.Kylin Apache Kylin是一个开源的分布式分析引擎,提供Hadoop之上的 ...
- 大数据系列之分布式计算批处理引擎MapReduce实践-排序
清明刚过,该来学习点新的知识点了. 上次说到关于MapReduce对于文本中词频的统计使用WordCount.如果还有同学不熟悉的可以参考博文大数据系列之分布式计算批处理引擎MapReduce实践. ...
- python3.4学习笔记(十九) 同一台机器同时安装 python2.7 和 python3.4的解决方法
python3.4学习笔记(十九) 同一台机器同时安装 python2.7 和 python3.4的解决方法 同一台机器同时安装 python2.7 和 python3.4不会冲突.安装在不同目录,然 ...
- 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
这个很简单,在集群机器里,选择就是了,本来自带就有Impala的. 扩展博客 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
- 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
不多说,直接上干货! Impala和Hive的关系(详解) 扩展博客 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解) 参考 horton ...
- 决战大数据之二:CentOS 7 最新JDK 8安装
决战大数据之二:CentOS 7 最新JDK 8安装 [TOC] 修改hostname # hostnamectl set-hostname node1 --static # reboot now 重 ...
随机推荐
- C语言Ⅰ博客作业02
1. 这个作业属于哪个课程 C语言程序设计Ⅰ 这个作业要求在哪里 https://edu.cnblogs.com/campus/zswxy/CST2019-3/homework/8656 我在这个课程 ...
- 遍历文件夹下的csv,把数据读进一张表
import pandas as pd import os if __name__ == '__main__': Path = 'c:\checklog' dfs = [] for dir_path, ...
- [BZOJ3133] [Baltic2013]ballmachine(树上倍增+堆)
[BZOJ3133] [Baltic2013]ballmachine(树上倍增+堆) 题面 有一个装球机器,构造可以看作是一棵树.有下面两种操作: 从根放入一个球,只要下方有空位,球会沿着树滚下.如果 ...
- python3使用hashlib进行加密
hashlib是个专门提供hash算法的库,里面包括md5, sha1, sha224, sha256, sha384, sha512,使用非常简单.方便. MD5 MD5的全称是Message-Di ...
- solr集群搭建(SolrCloud)
SolrCloud(solr 云)是 Solr 提供的分布式搜索方案,当你需要大规模,容错,索引量很大,搜索请求并发很高时可以使用SolrCloud.它是基于 Solr 和Zookeeper的分布式搜 ...
- Centos 修改当前路径显示为全路径
1.修改显示全路径: vim /etc/bashrc 找到[ "$PS1" = "\\s-\\v\\\$ " ] && PS1="[\ ...
- php 操作分表代码
//哈希分表 function get_hash_table($table, $userid) { $str = crc32($userid); if ($str < 0) { $hash = ...
- PAT Advanced 1042 Shuffling Machine (20 分)(知识点:利用sstream进行转换int和string)
Shuffling is a procedure used to randomize a deck of playing cards. Because standard shuffling techn ...
- test dword ptr [eax],eax ; probe page.局部数组变量定义所分配的最大空间为1M
问题的出现 使用VS2017编写程序时,程序编译可以通过,但运行时就会弹出错误 经过查证发现: 这跟局部数组变量定义所分配的最大空间设置大小有关. 局部变量的申请空间是存放于栈中,windows里默认 ...
- C#基础知识之事件和委托
本文中,我将通过两个范例由浅入深地讲述什么是委托.为什么要使用委托.委托的调用方式.事件的由来..Net Framework中的委托和事件.委托和事件对Observer设计模式的意义,对它们的中间代码 ...