Policy Improvement and Policy Iteration
From the last post, we know how to evaluate a policy. But that's not enough, because the purpose of policy evaluation is to improve policies so that finally get the optimal policy. So in this post, we will discuss about how to improve a given policy, and how to from a given policy get to the optimal policy.
Firstly, when you have an evaluated policy, the Action-Value function is known for every state. That is, at a certain state s, we known which action can give the system the largest reward.
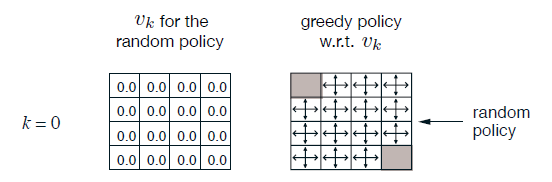
In the puzzle wandering example, we evaluate the random policy. However,the State-Value functions can be used for policy improvement. After 1 step calculating,we can conclude at the circled location, moving left is better than randomly picking a direction because left side has more reward.
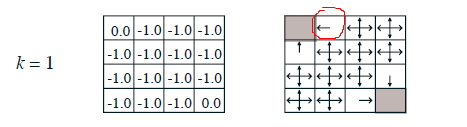
After three steps, we've got a much better intuition about the map. We can change the random policy to a new better one.

The way to improve the current policy is to greedyly pick actions for every state. It is worth noting that greedily picking actions does not means it only consider one step (too greedy to consider multiple steps). Instead, when k=3, the algorithm can foresee three steps, and the greedy picking algorithm will select the best action for k steps.
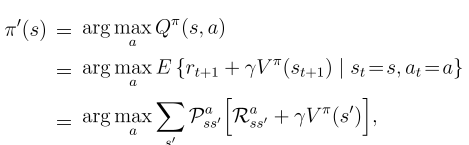
The Policy Iteration Algorithm is keep doing evaluation and improvement tasks untill the policy becomes stable,
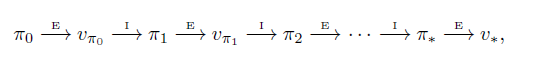

This process means Action-Value function of the improved policy picking the best return from a single action:
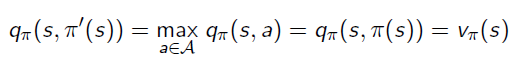
The algorithm is:

Policy Improvement and Policy Iteration的更多相关文章
- Provider Policy与Consumer Policy在bnd中的区别
首先需要了解的是bnd的相关知识: 1. API(也就是接口), 2. API Provider(接口的实现) 3. API Consumer( 接口的使用者) OSGi中的一个版本有4个部分: ...
- Reinforcement Learning Index Page
Reinforcement Learning Posts Step-by-step from Markov Property to Markov Decision Process Markov Dec ...
- Policy Gradient Algorithms
Policy Gradient Algorithms 2019-10-02 17:37:47 This blog is from: https://lilianweng.github.io/lil-l ...
- Deep Learning专栏--强化学习之从 Policy Gradient 到 A3C(3)
在之前的强化学习文章里,我们讲到了经典的MDP模型来描述强化学习,其解法包括value iteration和policy iteration,这类经典解法基于已知的转移概率矩阵P,而在实际应用中,我们 ...
- 使用 SecurityManager 和 Policy File 管理 Java 程序的权限
参考资料 该文中的内容来源于 Oracle 的官方文档.Oracle 在 Java 方面的文档是非常完善的.对 Java 8 感兴趣的朋友,可以从这个总入口 Java SE 8 Documentati ...
- Utility2:Appropriate Evaluation Policy
UCP收集所有Managed Instance的数据的机制,是通过启用各个Managed Instances上的Collection Set:Utility information(位于Managem ...
- trait与policy模板应用简单示例
trait与policy模板应用简单示例 accumtraits.hpp // 累加算法模板的trait // 累加算法模板的trait #ifndef ACCUMTRAITS_HPP #define ...
- trait与policy模板技术
trait与policy模板技术 我们知道,类有属性(即数据)和操作两个方面.同样模板也有自己的属性(特别是模板参数类型的一些具体特征,即trait)和算法策略(policy,即模板内部的操作逻辑). ...
- Network Policy - 每天5分钟玩转 Docker 容器技术(171)
Network Policy 是 Kubernetes 的一种资源.Network Policy 通过 Label 选择 Pod,并指定其他 Pod 或外界如何与这些 Pod 通信. 默认情况下,所有 ...
随机推荐
- 模型验证方法——R语言
在数据分析中经常会对不同的模型做判断 一.混淆矩阵法 作用:一种比较简单的模型验证方法,可算出不同模型的预测精度 将模型的预测值与实际值组合成一个矩阵,正例一般是我们要预测的目标.真正例就是预测为正例 ...
- keepalived容灾方案,实现nginx负载均衡主从架构(1)
一:环境准备:4台nginx服务器,两台用yum安装,两台使用源码安装 第一步:使用yum安装nginx服务器,在浏览器输入ip,可以显示以下内容,这步比较简单,安装好修改/usr/share/ngi ...
- vscode 黑屏及类名报错解决方案
1.安装vscode之后打开黑屏,解决方案如下图,右键--属性--兼容性--勾选上 2.vscode 类名总报错 是ES2017的语法修饰器引起vscode警告. 解除的方法如果你使用的typescr ...
- vue开发知识点总结
一.vue介绍 Vue.js 是一套构建用户界面(UI)的渐进式JavaScript框架,是一个轻量级MVVM(model-view-viewModel)框架. 二.数据绑定 最常用的方式:Musta ...
- window.location对象 获取页面地址
window.location对象的属性: 属性 含义 值 location.protocol 协议 "http://"或"https://" location ...
- shiro常见的异常以及处理方法
1.shiro的常见异常 1.1 AuthenticationException 异常是Shiro在登录认证过程中,认证失败需要抛出的异常. AuthenticationException包含以下子 ...
- unittest----常用属性详解(框架属性详解)
很久没有写关于测试的随笔了,最近有空学习.整理一下关于unittest框架的知识. unittest单元测试框架,不仅可以适用于单元测试,还可以适用WEB自动化测试用例的开发与执行. unittest ...
- 密码技术之密钥、随机数、PGP、SSL/TLS
第三部分:密码技术之密钥.随机数.PGP.SSL/TLS 密码的本质就是将较长的消息变成较短的秘密消息——密钥. 一.密钥 什么是密钥? (1)密钥就是一个巨大的数字,然而密钥数字本身的大小不重要,重 ...
- vue props父组件与子组件传值方法
/~~父组件 runshow.vue~~/ <template> <div> <conditions :fenxiConditonsList="propCond ...
- React Native 中 static的navigationOptions中的点击事件不能用this
想在某个页面中设置导航栏,title + 左右按钮(按钮上肯定需要有事件) static navigationOptions = ({ navigation, navigationOptions }) ...