NLP 自然语言处理之综述
(1) NLP 介绍
NLP 是什么?
NLP (Natural Language Processing) 自然语言处理,是计算机科学、人工智能和语言学的交叉学科,目的是让计算机处理或“理解”自然语言。自然语言通常是指一种自然地随文化演化的语言,如汉语、英语、日语。
NLP 可以用来做什么?以及它的应用领域是什么?
文本朗读(Text to speech)/ 语音合成(Speech synthesis)
语音识别(Speech recognition)
中文自动分词(Chinese word segmentation)
词性标注(Part-of-speech tagging)
句法分析(Parsing)
自然语言生成(Natural language generation)
文本分类(Text categorization)
信息检索(Information retrieval)
信息抽取(Information extraction)
文字校对(Text-proofing)
问答系统(Question answering)
机器翻译(Machine translation)
自动摘要(Automatic summarization)
文字蕴涵(Textual entailment)
(2)NLP 技术发展路线
从时间轴角度,可以看到 NLP 中重要模型的发布链:
word2vec -> seq2seq -> Attention model -> Transformer(vanilla) -> ELMO -> Transformer(universal) -> GPT -> BERT -> GPT-2 -> Transformer-XL -> XLNet
但是被广为使用的模型迭代图是:ELMO -> Transformer -> GPT -> BERT
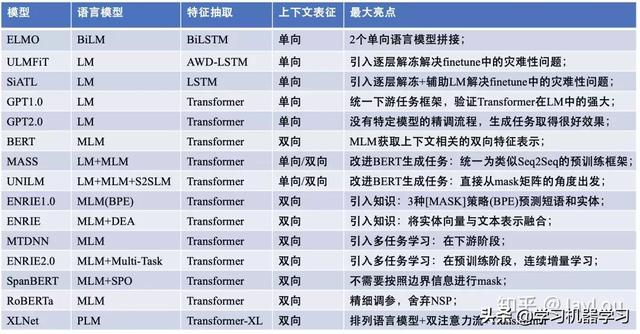
以下对上述模型做初步介绍:
word2vec
时间:2013.01
论文地址:https://arxiv.org/abs/1301.3781
github: https://github.com/danielfrg/word2vec
问题提出:
one-hot编码解决了文本特征离散表示的问题,但它假设词与词相互独立并且特征向量会过于稀疏,会造成维度灾难。
方法:
通过训练,将每个词都映射到一个较短的词向量上来。所有的这些词向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系。
word2vec的具体实现分为CBOW和Skip-Gram两种模型。CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。
Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。
结论:
CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。Skip-Gram模型的训练需要更长的时间。
seq2seq
时间:2014.09
论文地址:https://arxiv.org/pdf/1409.3215.pdf
问题提出:
原始的RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。
方法:
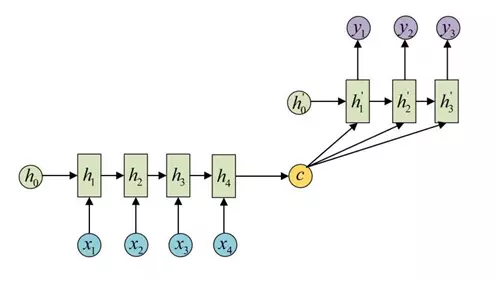
结论:
这一结构在机器翻译。文本摘要、阅读理解、语音识别等领域能取得很好的性能。
Attention model
时间:2015.02
论文地址: https://arxiv.org/abs/1502.03044v1
问题提出:
在Encoder-Decoder框架中,在预测每一个yi时对应的语义编码c都是一样的,也就意味着无论句子X中的每个单词对输出Y中的每一个单词的影响都是相同的。这样就会产生两个弊端:一是语义向量无法完全表示整个序列的信息,再者就是先输入的内容携带的信息会被后输入的信息稀释掉,或者说被覆盖了。输入序列越长,这个现象就越严重。这就使得在解码的时候一开始就没有获得输入序列足够的信息, 那么解码的准确度自然也就要打个折扣了。
方法:
注意力机制模型中,Decoder 的输出会与Encoder每一个时间点的输出进行分数计算,具体的算方法很多,常见的方式为内积。接著通过softmax层便可得到每一个encoder hidden state’s attention weights,和为1,可表示为该decoder步骤注重encoder 输出的权重分布,之后将每个encoder输出与 attention weights 作加权求合即得到最终的attention vector,Decoder在每一个时间点都会进行上述的注意力计算。
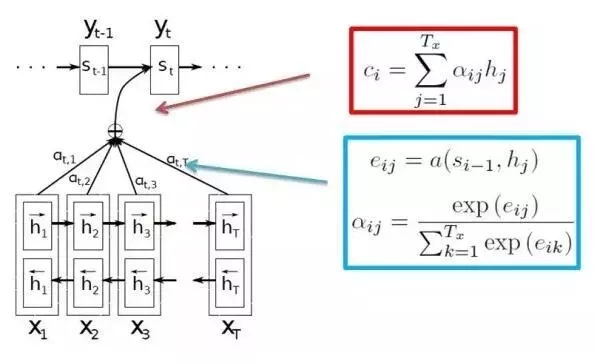
结论:
注意力机制能大大提升LSTM,GRU的整体性能。
Transformer(vanilla)
时间:2017.06
论文地址:https://arxiv.org/abs/1706.03762
github:https://github.com/tensorflow/tensor2tensor
问题提出:
RNN结构本身比较简单,也很适合序列建模,但RNN的明显缺点之一就是无法并行,因此速度较慢,这是递归的天然缺陷。另外RNN无法很好地学习到全局的结构信息,因为它本质是一个马尔科夫决策过程。CNN事实上只能获取局部信息,是通过层叠来增大感受野。
方法:
- 通过多头自注意力结构一步到位获取了全局信息。其中单个自注意力模块的计算公式如下:

2. 由于self-Attention无法并不能捕捉序列的顺序,通过Position Embedding,将每个位置编号,然后通过正余弦函数将编号映射为一个向量,就给每个词都引入了一定的位置信息。
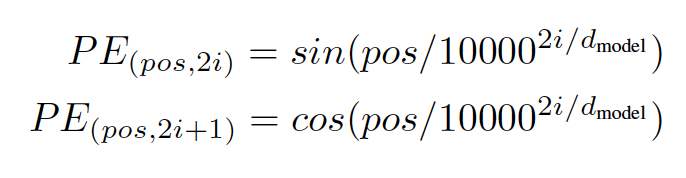
式中pos表示位置编号rang(0,100),i表示维度rang(0,512)。
结论:
实验验证transformer在翻译任务做到了SOFA,比循环神经网络快,效果好。
ELMO
时间:2018.02
论文地址:https://arxiv.org/abs/1802.05365
问题提出:
词向量需要解决两个问题:(1)词使用的复杂特性,如句法和语法。(2)如何在具体的语境下使用词,比如多义词的问题。传统的词向量如word2vec能够解决第一类问题,但是无法解决第二类问题。
方法:
Elmo主要使用了一个两层双向的LSTM语言模型,结合上下文来理解词义。先在一个大型的预料库上面进行训练,用模型的内部状态来表征一个词的向量,此时内部状态混合了所有的语义;然后将下游任务的文本输入模型,此时的词具备了具体的上下文语境,再用内部状态的线性组合来表征词。这种线性组合是在下游任务中进行训练得到的。
结论:
biLSTM层能有效地编码上下文中不同类型的语法和语义信息,提高整体任务性能。
Transformer(universal)
时间:2018.07
论文地址:https://arxiv.org/abs/1807.03819
问题提出:
Transformer 中 Encoder和Decoder Block执行的次数仍是人为设定的超参数,这意味著,模型架构无法随著任务的特性、难易,自动的调整训练的策略和次数。
方法:
Universal Transformer 通过正弦函数具周期的特性,Position embedding将位置信息加入每一个input symbol,除此之外,Timestep embedding(递回次数)也使用相同方法处理。将position和timestep embedding 一并与输入作加法运算,即成功将位置和递回次数信息加入模型中。
使用Transition function,除了增加非线性变换的次数外,与Vanilla Transformer不同的是,每一个Symbol都有自己独立的Transition function,这能够有效率的学习到更深层的语意资讯。每一个symbol在著训练的过程,都能自由的控制iteration次数,因为有些symbol需要多次的iteration才能充分理解其语意,有些则不需要,先停止的symbol会复制相同的数据到下一个step,直到所有的symbol都停止,或到达了iteration的上限值。
Transition function 是有别于Vanilla Transformer一个重要的特点,Transition function可以是一个简单的Dense Layer,也可以是CNN Layer,差别在于,Vanilla Transformer再通过self-attention后,将所有的输出一并送进Dense Layer,而Universal Transformer的Transition function则是基于每一个不同的symbol分头进行。通过此方法,能提升训练收敛速度且让每个symbol有更好的vector representation,因此能提升整体表现。
结论:
Universal Transformer采用了 adaptive computation time (ACT)让模型可以动态地调整每个symbol的计算次数,借以获得最好的向量表达,此外有别于传统做法,此方法在transition function依照个别symbol分头进行,这能够有效率的学习每个symbol的向量表达,并保留了Vanilla Transformer的优点,解决传统方法梯度爆炸/消失和资讯遗失的问题;实验发现Universal Transformer不仅让机器翻译达到更准确的效果,也补足了algorithmic tasks 成效低落的缺点,让Universal Transformer能更泛用于各式各样不同的任务,成为计算通用模型。
GPT
问题提出:
首次提出结合无监督的预训练(pre-training)和有监督的微调(fine-tuning),旨在学习一种通用的表示方式,转移到各种类型的NLP任务中都可以做很少的改变。
方法:
单向自回归Transformer模型,词向量+位置向量
结论:
对四种类型的NLP任务(12个task)进行了评估 ,在9个做到了SOFA。
BERT
时间:2018.10
论文地址:https://arxiv.org/abs/1810.04805
github: https://github.com/google-research/bert
问题提出:
ELMo 使用两条独立训练的LSTM获取双向信息,但融合方式是直接concat,太过粗暴。而 GPT 使用自回归模式的Transformer 只能获取单向信息。
方法:
采用3种embedding相加的方式作为模型输入:Token Embeddings+Segment Embeddings+Position Embeddings,其中token embedding采用的是word piece embedding,Position Embeddings不同于Transformer,使用了一组随机初始化的参数同模型一起学习,模型同Transformer。
最关键的点在于对模型的预训练。采用了2种不同的预训练任务。
(1)把一篇文章中,15% 的词汇遮盖,让模型根据上下文全向地预测被遮盖的词。假如有 1 万篇文章,每篇文章平均有 100 个词汇,随机遮盖 15% 的词汇,模型的任务是正确地预测这 15 万个被遮盖的词汇。通过全向预测被遮盖住的词汇,来初步训练 Transformer 模型的参数。
(2)预测下一句是否连续。譬如从上述 1 万篇文章中,挑选 20 万对语句(总共 40 万条语句)。挑选语句对的时候,其中 10 万对语句,是连续的两条上下文语句,另外 10 万对语句,不是连续的语句。然后让 Transformer 模型来识别这 20 万对语句,哪些是连续的,哪些不连续。
结论:
BERT主要贡献是将无监督pre-training+有监督fine-tuning这一模式推广到更深层的双向结构中。
GPT-2
时间:2019.02
论文地址:https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
github: https://github.com/openai/gpt-2
问题提出:
目前主流的机器学习模型都是在指定的任务上去用一部分数据来训练模型,再用一部分不相同但同分布的数据来测试其性能。这样的模式在特定场景效果的确不错,但是对于字幕或者说阅读理解、图像分类这样的任务来说,输入的多样性和不确定性就会把缺点给暴露出来。目前普遍采用的用单一领域的数据来训练单一模型是该问题的罪魁祸首,如果要构建一个泛化能力更强的模型,需要在更广泛的任务和领域上进行训练。
方法:
把多任务学习和无监督学习联系起来,将条件概率由p(output|input) 改为p(output|input,task) 。在多个任务上进行预训练,无监督地做下游任务。
模型沿用GPT 1.0 单向自回归语言模型, 数据质量高、更宽泛、量更大。 Transformer模型也更大(48层,15亿参数)。
结论:
当一个大的语言模型被训练在一个足够大和不同的数据集上时,它能够在许多领域和数据集上表现良好。GPT-2在测试的8个数据集中有7个数据集,该模型能够在零样本的情况下取得SOFA,经过训练的高容量模型能够最大限度地提高文本语料库多样性的可能性,从而在不需要做监督学习的情况下执行数量惊人的任务。
Transformer-XL
时间:2019.06
论文地址:https://arxiv.org/abs/1901.02860
github: https://github.com/kimiyoung/transformer-xl
问题提出:
vanilla Transformers使用固定长度的上下文来实现,即将一个长的文本序列截断为512个字符的固定长度片段,然后分别处理每个片段。这造成了3个限制:
1. 上下文长度受限:字符之间的最大依赖距离受输入长度的限制,模型看不到出现在几个句子之前的单词。
2. 上下文碎片:对于长度超过512个字符的文本,都是从头开始单独训练的。段与段之间没有上下文依赖性,会让训练效率低下,也会影响模型的性能。
3. 推理速度慢:在测试阶段,每次预测下一个单词,都需要重新构建一遍上下文,并从头开始计算,这样的计算速度非常慢。
方法:
1. 提出片段级递归机制。Transformer-XL仍然是使用分段的方式进行建模,但其与vanilla Transformer的本质不同是在于引入了段与段之间的循环机制,使得当前段在建模的时候能够利用之前段的信息来实现长期依赖性。
在训练阶段,处理后面的段时,每个隐藏层都会接收两个输入:
(1)该段的低隐藏层的输出(与vanilla Transformer相同)。
(2)前面段的隐藏层的输出,可以使模型创建长期依赖关系。
2. 使用了相对位置编码来重新实现postion embedding。在分段的情况下,如果仅仅对于每个段仍直接使用Transformer中的位置编码,即每个不同段在同一个位置上的表示使用相同的位置编码,就会出现问题。比如,第i−2段和第i−1段的第一个位置将具有相同的位置编码,但它们对于第i段的建模重要性显然并不相同(例如第i−2段中的第一个位置重要性可能要低一些)。因此,需要对这种位置进行区分。
结论:
对于长文档建模能力有明显的提升,依赖关系的有效长度比循环网络长80%,比vanilla Transforme长450%。在验证阶段比vanilla Transforme快1,800+倍。
XLNet
时间:2019.06
论文地址:https://arxiv.org/pdf/1906.08237.pdf
github: https://github.com/zihangdai/xlnet
问题提出:
- BERT在预训练阶段引入[mask]标记,而在下游任务中不存在,破坏了预训练与下游任务的一致性。
- BERT在根据句子的其他词预测Mask掉的单词时,对被Mask掉的单词做了独立性假设,即假设被Mask掉的单词之间相互独立。
方法:
- 采用自回归语言模型的模式,通过对输入全排列来引入上下文信息(通过双流自注意力机制和Attention掩码实现)。
- 使用了最新的Transformer-XL模型,直接使用了相对位置编码,并将递归机制整合到全排列设定中。
结论:
维持了表面看上去的自回归语言模型的从左向右的模式,这个有明显的好处,就是对于生成类的任务,能够在维持表面从左向右的生成过程前提下,模型里隐含了上下文的信息。引入了Transformer XL的机制,所以对于长文档输入类型的NLP任务,也会比Bert有明显优势。
参考文献:
https://blog.csdn.net/qq_33360393/article/details/100045351
https://www.toutiao.com/a6742415474396496387/?traffic_source=&in_ogs=&utm_source=&source=search_tab&utm_medium=wap_search&original_source=&in_tfs=&channel=
attention,命名实体识别,
word2vec,embading
NLP 自然语言处理之综述的更多相关文章
- flask 第六章 人工智能 百度语音合成 识别 NLP自然语言处理+simnet短文本相似度 图灵机器人
百度智能云文档链接 : https://cloud.baidu.com/doc/SPEECH/index.html 1.百度语音合成 概念: 顾名思义,就是将你输入的文字合成语音,例如: from a ...
- NLP 自然语言处理实战
前言 自然语言处理 ( Natural Language Processing, NLP) 是计算机科学领域与人工智能领域中的一个重要方向.它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和 ...
- NLP 自然语言处理
参考: 自然语言处理怎么最快入门:http://www.zhihu.com/question/ 自然语言处理简介:http://wenku.baidu.com/link?url=W6Mw1f-XN8s ...
- NLP自然语言处理学习笔记二(初试)
前言: 用Python对自然语言处理有很好的库.它叫NLTK.下面就是对NLTK的第一尝试. 安装: 1.安装Pip 比较简单,得益于CentOS7自带的easy_install.执行一行命令就可以搞 ...
- NLP自然语言处理 jieba中文分词,关键词提取,词性标注,并行分词,起止位置,文本挖掘,NLP WordEmbedding的概念和实现
1. NLP 走近自然语言处理 概念 Natural Language Processing/Understanding,自然语言处理/理解 日常对话.办公写作.上网浏览 希望机器能像人一样去理解,以 ...
- 初识NLP 自然语言处理
接下来的一段时间,要深入研究下自然语言处理这一个学科,以期能够带来工作上的提升. 学习如何实用python实现各种有关自然语言处理有关的事物,并了解一些有关自然语言处理的当下和新进的研究主题. NLP ...
- [NLP自然语言处理]谷歌BERT模型深度解析
我的机器学习教程「美团」算法工程师带你入门机器学习 已经开始更新了,欢迎大家订阅~ 任何关于算法.编程.AI行业知识或博客内容的问题,可以随时扫码关注公众号「图灵的猫」,加入”学习小组“,沙雕博主 ...
- NLP自然语言处理入门-- 文本预处理Pre-processing
引言 自然语言处理NLP(nature language processing),顾名思义,就是使用计算机对语言文字进行处理的相关技术以及应用.在对文本做数据分析时,我们一大半的时间都会花在文本预处理 ...
- 43、哈工大NLP自然语言处理,LTP4j的测试+还是测试
1.首先需要构建自然语言处理的LTP的框架 (1)需要下载LTP的源码包即c++程序(https://github.com/HIT-SCIR/ltp)下载完解压缩之后的文件为ltp-master (2 ...
随机推荐
- [BZOJ1547]周末晚会:Burnside引理+DP
分析 Attention!这道题的模数是\(1e8+7\). 注意到循环同构会被认为是同一种方案,我们可以把顺时针旋转每个人的位置作为置换,容易发现这些置换一定会形成一个置换群,于是题目所求的所有合法 ...
- VMware 15 搭建win 10 实操步骤+共享文件+激活操作
写于:2018.12.22 一.简介: VMware 15 里搭建win 10是件很坑的事.我尝试了3种方法,最后才搭建成功.为了不让网友们不在走我走过的坑,特写了本文. 坑一:用老毛桃.大白菜搭 ...
- 深入理解JVM虚拟机11:Java内存异常原理与实践
本文转自互联网,侵删 本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutori ...
- Junit单元测试的使用
这里拿Dynamic Web Project项目来演示,首先创建一个Dynamic Web Project项目,起名,点next, 继续点next, 将web.xml文件勾选,finish, 接下来在 ...
- Crypko 基于滚动条进行的动画是如何实现的?
Crypko 网站里面的下拉滚动条进行的动画感觉非常炫,于是研究了一下她的实现,发现她主要是使用了 ScrollMagic 这个库实现了基于滚动条的动画. 为什么这么确定就是用了 ScrollMagi ...
- Linux_LAMP 最强大的动态网站解决方案
目录 目录 LAMP Install LAMP via YUM Install LAMP via ResourceCode Apache Apache Virtual Machine Type Use ...
- Delphi XE2 之 FireMonkey 入门(11) - 控件居中、旋转、透明
RotationAngle.RotationCenter.Opacity 属性继承自 TControl(FMX.Types), 这些新属性成了控件的基本功能. 先在 HD 窗体上添加 TRectang ...
- 测开之路一百零五:bootstrap的两种引用方式
一:下载到本地引用: 3.3.7版本:https://getbootstrap.com/docs/3.3/getting-started/#download 下载后解压到本地项目中引用 第二种,cdn ...
- ecshop注册用户增加手机验证功能
1.去掉“用户名”注册 a.去掉提交 user_passport.dwt页面去掉 <input name="username" type="text" s ...
- Hibernate的批量抓取
批量抓取理解:如果我们需要查找到客户的所有联系人的话,按照正常的思路,一般是首先查询所有的客户,得到返回的客户的List集合.然后遍历List集合,得到集合中的每一个客户,在取出客户中的联系人(客户表 ...