win7安装scrapy
Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
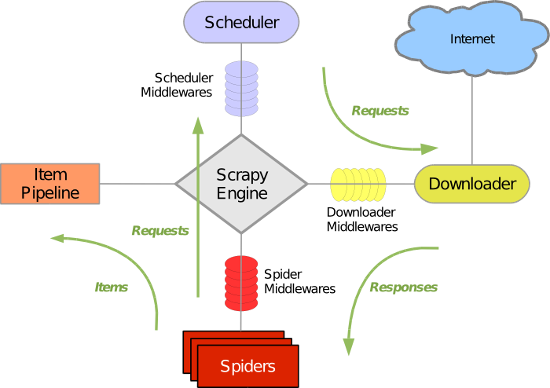
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
windows平台需要依赖pywin32
一、安装
1、安装pywin32
地址:https://nchc.dl.sourceforge.net/project/pywin32/pywin32/Build%20221/pywin32-221.win-amd64-py3.6.exe。
下载完毕之后,点击安装即可
2、Twisted
地址:https://download.lfd.uci.edu/pythonlibs/rqr3k8is/Twisted-17.9.0-cp36-cp36m-win_amd64.whl
cp后面是python版本,amd64代表64位
安装:
pip install C:\Users\CR\Downloads\Twisted-17.5.0-cp36-cp36m-win_amd64.whl
3、安装Scrapy
pip install scrapy
二、基本使用
1、创建项目
运行命令:
scrapy statproject spide1
自动创建目录:
project_name/
scrapy.cfg
project_name/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
文件说明:
- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
2、编写爬虫
在spiders目录中新建 xiaohuar_spider.py 文件
#!/usr/bin/ python
# _*_ coding:utf-8 _*_ import scrapy class XiaohuaSpider(scrapy.spiders.Spider):
name = "xiaohuar" #APP名字
start_urls = [
"http://www.xiaohuar.com/hua/",
] def parse(self, response):
current_url = response.url
body = response.body
unicode_body = response.body_as_unicode()
print(unicode_body)
3、运行
进入project_name目录,运行命令
scrapy crawl xiaohuar --nolog
4、递归访问
以上的爬虫仅仅是爬去初始页,而我们爬虫是需要源源不断的执行下去,直到所有的网页被执行完毕
import scrapy
import urllib.request as req
import os class XiaohuaSpider(scrapy.spiders.Spider):
name = "xiaohuar" #APP名字
start_urls = [
"http://www.xiaohuar.com/hua/",
] def parse(self, response):
# current_url = response.url
# body = response.body
# unicode_body = response.body_as_unicode()
# print(unicode_body)
current_dir = os.path.dirname(os.path.dirname(__file__))
# if os.path.exists(os.path.join(current_dir,'pic')):
# pass
# else:
# current_dir = os.mkdir(os.path.join(current_dir,'pic'))
from scrapy.selector import HtmlXPathSelector
hxs = HtmlXPathSelector(response)
#//div 代表找到所有的div /div 从根目录开始找 @class="item_list infinite_scrol 代表class为item_list infinite_scroll的div
#/div代表前一个div下面的孩子,即子div
#items = hxs.select('//div[@class="item_list infinite_scroll"]/div//img/@src').extract()
hxs.select('//div[@class="item_list infinite_scroll"]/div[1]').extract() #获取第一个元素
items = hxs.select('//div[@class="item_list infinite_scroll"]/div')
for i in range(len(items)):
srcs = hxs.select( '//div[@class="item_list infinite_scroll"]/div[%d]//div[@class="img"]/a/img/@src' % i).extract()
names = hxs.select( '//div[@class="item_list infinite_scroll"]/div[%d]//div[@class="img"]/span/text()' % i).extract()
schools = hxs.select('//div[@class="item_list infinite_scroll"]/div[%d]//div[@class="img"]/div[@class="btns"]/a/text()' % i).extract()
if srcs and names:
ab_src = "http://www.xiaohuar.com" + srcs[0]
file_name = "%s_%s.jpg" % (schools[0], names[0])
file_path = os.path.join(current_dir,file_name)
#print(file_path)
req.urlretrieve(ab_src, file_path)
以上代码将符合规则的页面中的图片保存在指定目录,并且在HTML源码中找到所有的其他 a 标签的href属性,从而“递归”的执行下去,直到所有的页面都被访问过为止。
win7安装scrapy的更多相关文章
- win7中python3.4下安装scrapy爬虫框架(亲测可用)
貌似最新的scrapy已经支持python3,但是错误挺多的,以下为在win7中的安装步骤: 1.首先需要安装Scrapy的依赖包,包括parsel, w3lib, cryptography, pyO ...
- 怎么安装Scrapy框架以及安装时出现的一系列错误(win7 64位 python3 pycharm)
因为要学习爬虫,就打算安装Scrapy框架,以下是我安装该模块的步骤,适合于刚入门的小白: 一.打开pycharm,依次点击File---->setting---->Project---- ...
- win7(x64)安装scrapy框架
Scrapy(官网http://scrapy.org/)是Python开发网络爬虫,一个极好的开源工具.本次安装Scrapy确实不易啊.居然花了2天多时间,需要的支持包比较多,这些支持包相互之间的依赖 ...
- win7安装python3.6.1及scrapy
---恢复内容开始--- 第一篇博客,记录自己自学python的过程及问题. 首先下载python3.6.1及所需资料 百度云:https://pan.baidu.com/s/1geOEp6z 密码: ...
- python 3.6.1 安装scrapy踩坑之旅
系统环境:win10 64位系统安装 python基础环境配置不做过多的介绍 window环境安装scrapy需要依赖pywin32,下载对应python版本的exe文件执行安装,下载的pywin32 ...
- python3.7.1安装Scrapy爬虫框架
python3.7.1安装Scrapy爬虫框架 环境:win7(64位), Python3.7.1(64位) 一.安装pyhthon 详见Python环境搭建:http://www.runoob.co ...
- Python3.X下安装Scrapy
Python3.X下安装Scrapy (转载) 2017年08月09日 15:19:30 jingzhilie7908 阅读数:519 标签: python 相信很多同学对于爬虫需要安装Scrap ...
- win7安装时,避免产生100m系统保留分区的办法
在通过光盘或者U盘安装Win7操作系统时,在对新硬盘进行分区时,会自动产生100m的系统保留分区.对于有洁癖的人来说,这个不可见又删不掉的分区是个苦恼.下面介绍通过diskpart消灭保留分区的办法: ...
- CentOs安装Scrapy出现error: Setup script exited with error: command ‘gcc’ failed with exit status 1错误解决方案
按照 http://www.1207.me/archives/209.html 的教程安装Scrapy出现了上述错误,但是本身机器已经有了gcc,所以应该是安装包的问题 百度又看到了同博客里的解决方案 ...
随机推荐
- docker 内时区和宿主机差8个小时,怎么办?
docker run -d -it --name tt -e TZ=Asia/Shanghai -p : api 使用-e参数指定时区
- php shuffle()函数 语法
php shuffle()函数 语法 作用:把数组中的元素按随机顺序重新排序:富瑞华 语法:shuffle(array) 参数: 参数 描述 array 必需.规定要使用的数组. 说明:若成功则返回 ...
- makefile filter &&filter-out
sources := foo.c bar.c baz.s abc.h foo: $(sources) gcc $(filter %.c %.s,$(sources)) -o ...
- (41)freeRTOS之任务管理
1. 简介: 在 FreeRTOS 中没有线程和进程的区别,只有一个被翻译成任务的程序,相当于进程的概念,拥有独立的栈空间. 对于实时性,可以分为 软实时.硬实时:桌面电脑的输入处理可以看做是软实时, ...
- 认识了一个新的手机游戏剖析工具- SnapDragon Profiler
原来这个是高通的工具,具说UNITY官方推荐了这个工具.大概看了下,可以从宏观上实时剖析手机应用的方方面面
- python 浮点运算
print(format(float(a)/float(b),'.2f'))
- 主流架构 : MVP
1 背景 MVC 平时开发APP时会发现,activity职责非常重.以MVC角度来看: M:model数据操作层(网络请求,耗时操作,数据存取,其他逻辑操作) V:view,指xml布局文件,其实并 ...
- PHP图片处理
开启GD扩展(php_gd2.dll) 创建画布 画布:一种资源型数据,可以操作的图像资源. 创建新画布(新建) ImageCreate(宽,高);创建基于调色板的画布. imageCreateTru ...
- 阶段1 语言基础+高级_1-3-Java语言高级_06-File类与IO流_07 缓冲流_1_缓冲流的原理
一个字节一个字节的读取,先读取到a,a给到os操作系统.os再给JVM,.jVM再把a给java程序 读完a再读取b.这样一层层的返回,效率低下 一次读取,缓冲区数组返回来.
- 阶段1 语言基础+高级_1-3-Java语言高级_05-异常与多线程_第3节 线程同步机制_1_线程安全问题的概述