大数据笔记(二十二)——大数据实时计算框架Storm
一.
1、对比:离线计算和实时计算
离线计算:MapReduce,批量处理(Sqoop-->HDFS--> MR ---> HDFS)
实时计算:Storm和Spark Sparking,数据实时性(Flume ---> Kafka ---> 流式计算 ---> Redis)
2、常见的实时计算(流式计算)代表
(1)Apache Storm
(2)Spark Streaming
(3)Apache Flink:既可以流式计算,也可以离线计算
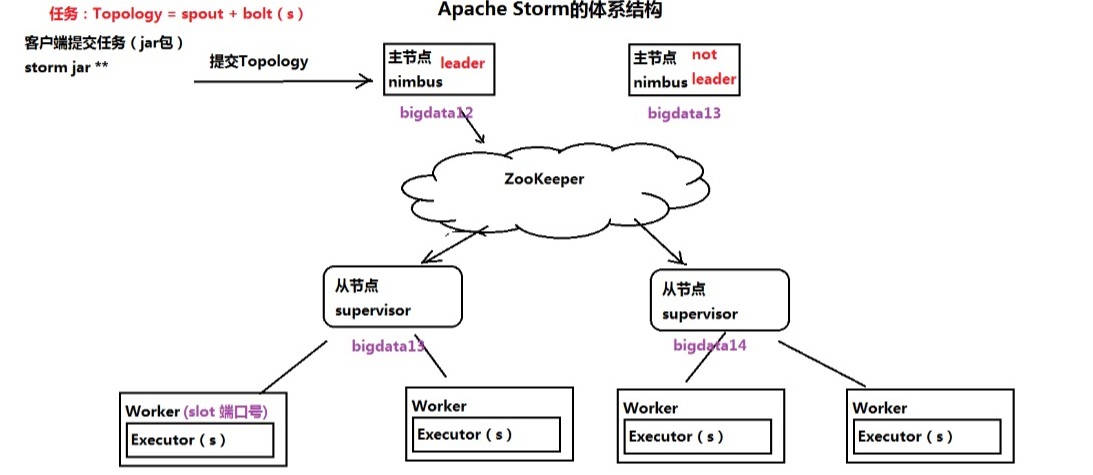
二、Storm的体系结构
三、安装和配置Apache Storm
1、前提条件:安装ZooKeeper(Hadoop的HA)
tar -zxvf apache-storm-1.0.3.tar.gz -C ~/training/
设置环境变量:
STORM_HOME=/root/training/apache-storm-1.0.3
export STORM_HOME PATH=$STORM_HOME/bin:$PATH
export PATH
配置文件: conf/storm.yaml
注意:- 后面有一个空格
: 后面有一个空格
2、Storm的伪分布模式(bigdata11)
18 storm.zookeeper.servers:
19 - "bigdata11"
主节点的信息
23 nimbus.seeds: ["bigdata11"]
每个从节点上的worker个数
25 supervisor.slots:ports:
26 - 6700
27 - 6701
28 - 6702
29 - 6703
任务上传后,保存的目录
storm.local.dir: "/root/training/apache-storm-1.0.3/tmp"
启动Storm:bigdata11
主节点: storm nimbus &
从节点: storm supervisor &
UI: storm ui & ---> http://ip:8080
logviewer:storm logviewer &
3、Storm的全分布模式(bigdata12 bigdata13 bigdata14)
(*)在bigata12上进行配置
storm.zookeeper.servers:
- "bigdata12"
- "bigdata13"
- "bigdata14"
nimbus.seeds: ["bigdata12"]
storm.local.dir: "/root/training/apache-storm-1.0.3/tmp"
supervisor.slots:ports:
- 6700
- 6701
- 6702
- 6703
(*)复制到其他节点
scp -r apache-storm-1.0.3/ root@bigdata13:/root/training
scp -r apache-storm-1.0.3/ root@bigdata14:/root/training
(*)启动
bigdata12: storm nimbus &
storm ui &
storm logviewer &
bigdata13: storm supervisor &
storm logviwer &
bigdata14: storm supervisor &
storm logviwer &
4、Storm的HA(bigdata12 bigdata13 bigdata14)
每台机器都要修改:
nimbus.seeds: ["bigdata12", "bigdata13"]
在bigdata13上,单独启动一个nimbus ----> not leader
还可以单独启动一个UI
四.WordCount数据流动的过程

用Java程序实现:
WordCountSpout.java
package demo; import java.util.Map;
import java.util.Random;
import java.util.stream.Collector; import org.apache.jute.Utils;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values; /**
* @作用:采集数据,送到下一个Bolt组件
*
*/
public class WordCountSpout extends BaseRichSpout{ /**
*
*/
private static final long serialVersionUID = 1L; //定义数据
private String[] data = {"I love Beijing","I love China","Beijing is the capital of China"}; private SpoutOutputCollector collector; @Override
public void nextTuple() {
//每三秒采集一次
org.apache.storm.utils.Utils.sleep(3000); // 由storm框架进行调用,用于接收外部系统产生的数据
//随机产生一个字符串,代表采集的数据
int random = new Random().nextInt(3);//3以内随机数 //采集数据,然后发送给下一个组件
System.out.println("采集的数据是: "+data[random]);
this.collector.emit(new Values(data[random]));
} /*
* SpoutOutputCollector 输出流
*/
@Override
public void open(Map arg0, TopologyContext arg1, SpoutOutputCollector collector) {
// spout组件初始化方法
this.collector = collector;
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 声明输出的schema
declarer.declare(new Fields("sentence"));
} }
WordCountSplitBolt.java
package demo; import java.util.Map; import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values; /**
* 第一个Bolt组件,用于分词操作
*
*/
public class WordCountSplitBolt extends BaseRichBolt{ private OutputCollector collector;
@Override
public void execute(Tuple tuple) {
//处理上一个组件发来的数据
//获取数据
String line = tuple.getStringByField("sentence");
//分词
String[] words = line.split(" "); //输出
for (String word : words) {
this.collector.emit(new Values(word,1));
}
} //OutputCollector:bolt组件输出流
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector) {
// 对bolt组件初始化
this.collector = collector;
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 声明输出的Schema
declarer.declare(new Fields("word","count"));
} }
WordCountTotalBolt.java
package demo; import java.util.HashMap;
import java.util.Map; import org.apache.storm.generated.DistributedRPCInvocations.AsyncProcessor.result;
import org.apache.storm.shade.org.apache.commons.lang.Validate;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values; /**
* 第二个Bolt组件:单词的计数
*
*/
public class WordCountTotalBolt extends BaseRichBolt{ private OutputCollector collector; private Map<String, Integer> result = new HashMap<>(); @Override
public void execute(Tuple tuple) {
//获取数据:单词、频率:1
String word = tuple.getStringByField("word");
int count = tuple.getIntegerByField("count"); if (result.containsKey(word)) {
//单词已存在
int total = result.get(word);
result.put(word, total+count);
}else {
//单词不存在
result.put(word, count);
} //输出
System.out.println("输出的结果是: "+ result);
//发送给下一个组件
this.collector.emit(new Values(word,result.get(word)));
} @Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector) {
// TODO Auto-generated method stub
this.collector = collector;
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
declarer.declare(new Fields("word","total"));
} }
WordCountTopology.java
package demo; import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.hdfs.bolt.HdfsBolt;
import org.apache.storm.hdfs.bolt.format.DefaultFileNameFormat;
import org.apache.storm.hdfs.bolt.format.DelimitedRecordFormat;
import org.apache.storm.hdfs.bolt.rotation.FileSizeRotationPolicy;
import org.apache.storm.hdfs.bolt.rotation.FileSizeRotationPolicy.Units;
import org.apache.storm.hdfs.bolt.sync.CountSyncPolicy;
import org.apache.storm.redis.bolt.RedisStoreBolt;
import org.apache.storm.redis.common.config.JedisPoolConfig;
import org.apache.storm.redis.common.mapper.RedisDataTypeDescription;
import org.apache.storm.redis.common.mapper.RedisStoreMapper;
import org.apache.storm.topology.IRichBolt;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.ITuple; public class WordCountTopology { public static void main(String[] args) throws Exception {
//设置用户为root权限
System.setProperty("HADOOP_USER_NAME", "root");
//创建一个任务:Topology = spout + bolt(s) TopologyBuilder builder = new TopologyBuilder(); //设置任务的第一个组件:spout组件
builder.setSpout("mywordcount_spout", new WordCountSpout());
//builder.setSpout("mywordcount_spout", createKafkaSpout()); //设置任务的第二个组件:bolt组件,拆分单词
builder.setBolt("mywordcount_split", new WordCountSplitBolt()).shuffleGrouping("mywordcount_spout"); //设置任务的第三个组件:bolt组件,计数
builder.setBolt("mywordcount_total", new WordCountTotalBolt()).fieldsGrouping("mywordcount_split", new Fields("word")); //设置任务的第四个bolt组件,将结果写入Redis
//builder.setBolt("mywordcount_redis", createRedisBolt()).shuffleGrouping("mywordcount_total"); //设置任务的第四个bolt组件,将结果写入HDFS
//builder.setBolt("mywordcount_hdfs", createHDFSBolt()).shuffleGrouping("mywordcount_total"); //设置任务的第四个bolt组件,将结果写入HBase
//builder.setBolt("mywordcount_hdfs", new WordCountHBaseBolt()).shuffleGrouping("mywordcount_total"); //创建任务
StormTopology topology = builder.createTopology(); //配置参数
Config conf = new Config(); //提交任务
//方式1:本地模式(直接在eclipse运行)
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("mywordcount", conf, topology); // 方式2 集群模式: storm jar temp/storm.jar demo.WordCountTopology MyStormWordCount
//StormSubmitter.submitTopology(args[0], conf, topology);
} private static IRichBolt createHDFSBolt() {
// 创建一个HDFS的Bolt组件,写入到HDFS
HdfsBolt bolt = new HdfsBolt(); //指定HDFS位置:namenode地址
bolt.withFsUrl("hdfs://192.168.153.11:9000"); //数据保存在HDFS哪个目录
bolt.withFileNameFormat(new DefaultFileNameFormat().withPath("/stormresult")); //ָ指定key和value的分隔符:Beijing|10
bolt.withRecordFormat(new DelimitedRecordFormat().withFieldDelimiter("|")); //生成文件的策略:每5M生成一个文件
bolt.withRotationPolicy(new FileSizeRotationPolicy(5.0f,Units.MB)); //与HDFS进行数据同步的策略:tuple数据达到1K同步一次
bolt.withSyncPolicy(new CountSyncPolicy(1024)); return bolt;
} private static IRichBolt createRedisBolt() {
// 创建一个Redis的bolt组件,将数据写入redis中
//创建一个Redis的连接池 JedisPoolConfig.Builder builder = new JedisPoolConfig.Builder();
builder.setHost("192.168.153.11");
builder.setPort(6379);
JedisPoolConfig poolConfig = builder.build(); //storeMapper: 存入Redis中数据的格式
return new RedisStoreBolt(poolConfig, new RedisStoreMapper() { @Override
public RedisDataTypeDescription getDataTypeDescription() {
// 声明存入Redis的数据类型
return new RedisDataTypeDescription(RedisDataTypeDescription.RedisDataType.HASH,"wordcount");
} @Override
public String getValueFromTuple(ITuple tuple) {
// 从上一个组件接收的value
return String.valueOf(tuple.getIntegerByField("total"));
} @Override
public String getKeyFromTuple(ITuple tuple) {
// 从上一个组件接收的key
return tuple.getStringByField("word");
}
});
} }
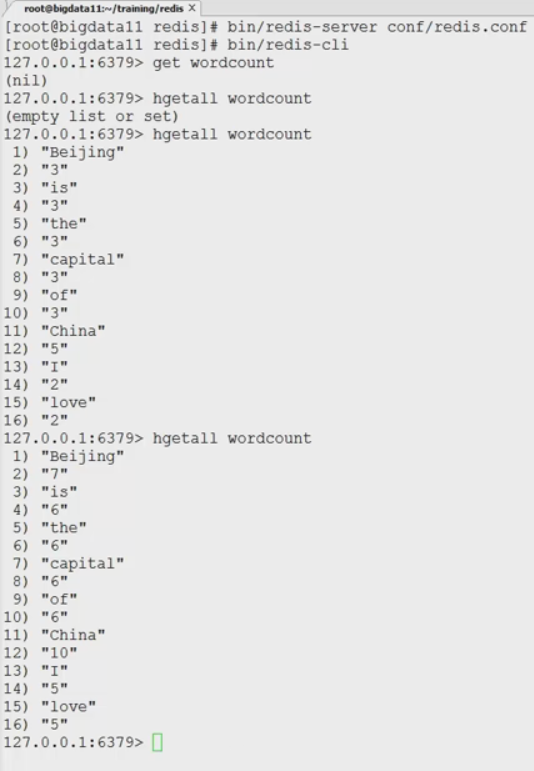
集成redis结果:
集成hdfs:

集成hbase:
WordCountHBaseBolt.java
package demo; import java.util.Map; import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.generated.master.table_jsp;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.IRichBolt;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple; /**
* 创建一个HBASE的表:create 'result','info'
*
*/
public class WordCountHBaseBolt extends BaseRichBolt { //定义一个Hbase的客户端
private HTable htable; @Override
public void execute(Tuple tuple) {
//得到上一个组件处理的数据
String word = tuple.getStringByField("word");
int total = tuple.getIntegerByField("total"); //创建一个put对象
Put put = new Put(Bytes.toBytes(word));
//列族:info 列:word 值:word
put.add(Bytes.toBytes("info"), Bytes.toBytes("word"), Bytes.toBytes(word));
put.add(Bytes.toBytes("info"), Bytes.toBytes("total"), Bytes.toBytes(String.valueOf(total)));
try {
htable.put(put);
} catch (Exception e) {
e.printStackTrace();
}
} @Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector arg2) {
// 初始化:指定HBASE的相关信息 } @Override
public void declareOutputFields(OutputFieldsDeclarer arg0) {
// TODO Auto-generated method stub } }
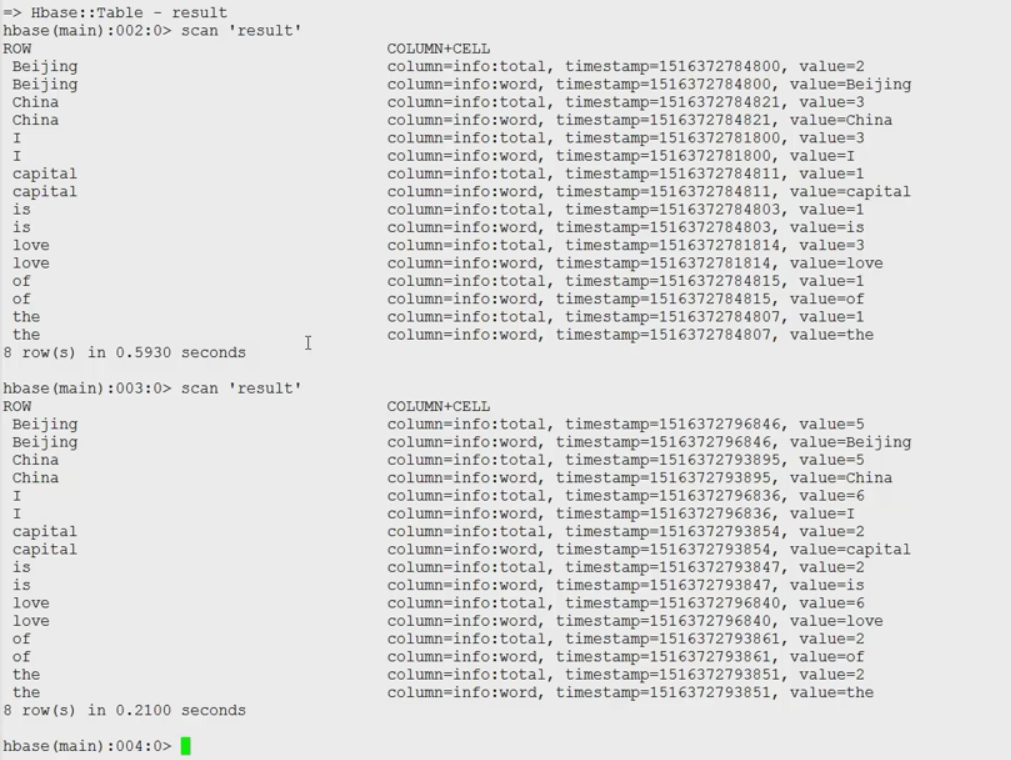
通过hbase shell打开hbase命令行
五.Strom任务提交的过程
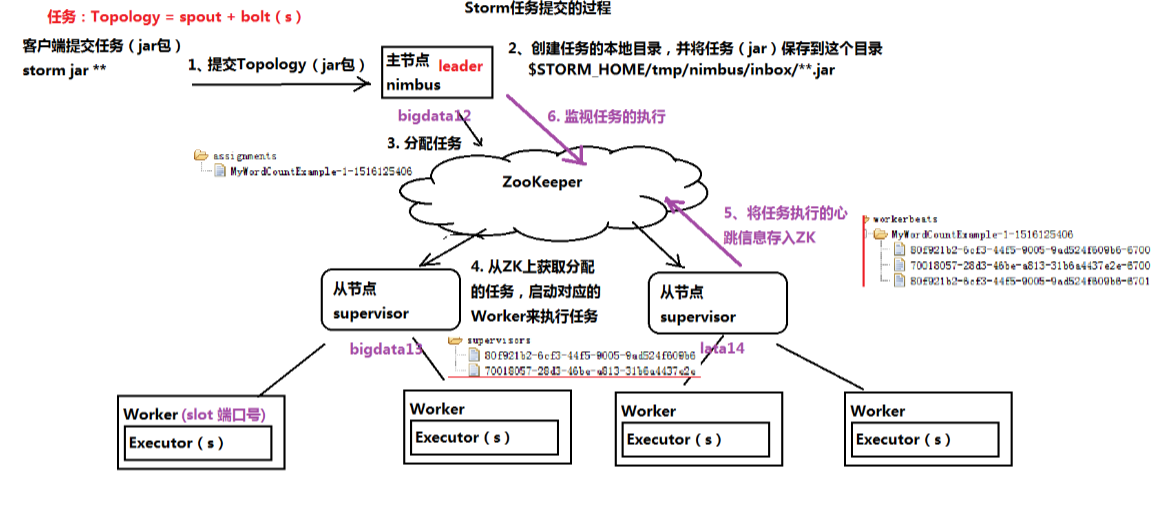
1.客户端提交任务
2.创建任务的本地目录
3.nimbus分配任务到zookeeper
4.supervisor从ZK获取分配的任务,启动对应的worker来执行任务
5.将任务执行的心跳存入ZK
6.nimbus监听任务的执行
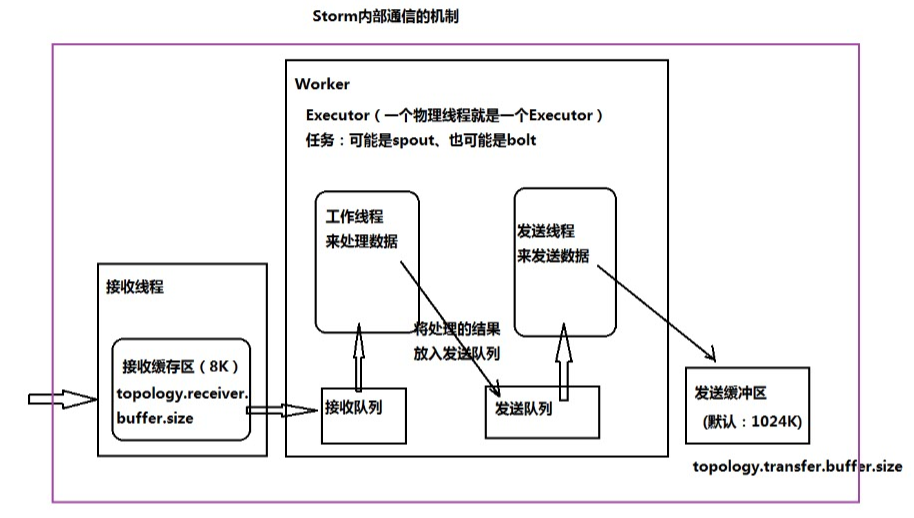
六、Storm内部通信的机制
任务的执行:worker中的Executor
大数据笔记(二十二)——大数据实时计算框架Storm的更多相关文章
- 大数据笔记(十二)——使用MRUnit进行单元测试
package demo.wc; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.io.IntW ...
- Android群英传笔记——第十二章:Android5.X 新特性详解,Material Design UI的新体验
Android群英传笔记--第十二章:Android5.X 新特性详解,Material Design UI的新体验 第十一章为什么不写,因为我很早之前就已经写过了,有需要的可以去看 Android高 ...
- (C/C++学习笔记) 二十二. 标准模板库
二十二. 标准模板库 ● STL基本介绍 标准模板库(STL, standard template library): C++提供的大量的函数模板(通用算法)和类模板. ※ 为什么我们一般不需要自己写 ...
- 深度学习课程笔记(十二) Matrix Capsule
深度学习课程笔记(十二) Matrix Capsule with EM Routing 2018-02-02 21:21:09 Paper: https://openreview.net/pdf ...
- 汇编入门学习笔记 (十二)—— int指令、port
疯狂的暑假学习之 汇编入门学习笔记 (十二)-- int指令.port 參考: <汇编语言> 王爽 第13.14章 一.int指令 1. int指令引发的中断 int n指令,相当于引 ...
- VSTO 学习笔记(十二)自定义公式与Ribbon
原文:VSTO 学习笔记(十二)自定义公式与Ribbon 这几天工作中在开发一个Excel插件,包含自定义公式,根据条件从数据库中查询结果.这次我们来做一个简单的测试,达到类似的目的. 即在Excel ...
- python3.4学习笔记(二十二) python 在字符串里面插入指定分割符,将list中的字符转为数字
python3.4学习笔记(二十二) python 在字符串里面插入指定分割符,将list中的字符转为数字在字符串里面插入指定分割符的方法,先把字符串变成list然后用join方法变成字符串str=' ...
- OllyDbg 使用笔记 (十二)
OllyDbg 使用笔记 (十二) 參考 书:<加密与解密> 视频:小甲鱼 解密系列 视频 演示样例程序下载地址:http://pan.baidu.com/s/1eQiV6aI 安装好程序 ...
- 学习笔记:CentOS7学习之二十二: 结构化命令case和for、while循环
目录 学习笔记:CentOS7学习之二十二: 结构化命令case和for.while循环 22.1 流程控制语句:case 22.2 循环语句 22.1.2 for-do-done 22.3 whil ...
随机推荐
- 洛谷 P3258 松鼠的新家 题解
题面 貌似这道题暴力加玄学优化就可以AC? 下面是正解: 1.树链剖分: 我们在u到v之间都放一个糖果,可以将松鼠它家u到v的糖果数都加1.每一次将a[i]到a[i+1] (a数组是访问顺序)的节点加 ...
- rust学习小记(1)
本文的学习资料来自 Rust 程序设计语言 简体中文版 推荐用idea来写rust,装好插件rust和toml即可 cargo(包管理) 可以使用 cargo build 或 cargo check ...
- hdu3829 二分匹配 最大独立集
Cat VS Dog Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 125536/65536 K (Java/Others) Problem ...
- vim编辑Dockerfile时语法高亮
参考Dockerfile构建容器---语法高亮 三个文件扔进相关的目录即可 1. /usr/share/vim/vimfiles/doc/dockerfile.txt *dockerfile.txt* ...
- RabbitMQ入门教程(十六):RabbitMQ与Spring集成
原文:RabbitMQ入门教程(十六):RabbitMQ与Spring集成 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https: ...
- .net 分布式锁
原文 : 浅解.Net分布式锁的实现 序言 我晚上有在公司多呆会儿的习惯,所以很多晚上我都是最后一个离开公司的.当然也有一些同事,跟我一样喜欢在公司多搞会儿.这篇文章就要从,去年年末一个多搞会的晚 ...
- centos python environment
3. 在Centos7的docker里装好了httpd,运行报错: $ systemctl start httpd.service Failed to get D-Bus connection: Op ...
- 玩转Android状态栏
前言 前段时间,突然收到一个状态栏颜色优化设计的任务,将原本应用整体的黑色状态栏修改为根据标题栏颜色进行沉浸式设计,显示效果如下: image 经过分析及踩过N多坑,终于完成了APP全局的修改.现 ...
- 【微信小程序】图片压缩-纯质量压缩,非长宽裁剪压缩
原理:利用canvas来实现,将图片绘制到canvas上,然后canvas转图片时,微信提供的一个方法wx.canvasToTempFilePath(Object object, Object t ...
- Elasticsearch:hanlp 中文分词器
HanLP 中文分词器是一个开源的分词器,是专为Elasticsearch而设计的.它是基于HanLP,并提供了HanLP中大部分的分词方式.它的源码位于: https://github.com/Ke ...