neo4j 初探
neo4j 初探
参考 转载:http://shomy.top/2018/06/08/neo4j-start/
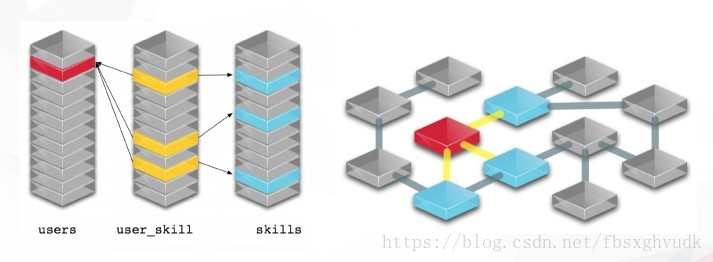
近期需要处理图数据,考察后打算使用neo4j, 相比其他一些图数据库,neo4j开源,跨平台,接口友好,文档齐全,完整支持ACID。 首先放一张网上的图片,关系型数据库与图数据库存储网络数据的差异:
初次接触neo4j 踩了不少坑,这里记录一下。
关于如何安装Neo4j和使用web ui进行查询操作就不再赘述。
Cypher基本操作
相比关系型数据库的SQL查询语言,Neo4j的查询语言为Cypher,语法更加友好,更适合图数据做查询操作。
概念
首先介绍在图数据里面几个概念:
- 节点(Node): 使用小括号表示
(n)表示n这个节点,同时一般都会赋予节点某个标签(Label), 等同于关系书库里面的表名。比如(n: Person)表示n是一个Person类的节点,当然一个节点可以同时有多个label. - 关系(Relation):关系使用中括号表示
[r:Knows]表示r是Knows这种关系。两个节点的关系用--表示,如果有方向的话,加个箭头即可。如(a)-[r:Knowns]->(b)表示节点a和b之间有r关系,其中Knowns为r的类型 - 属性(Property): 节点和关系都可以附带属性,这个也是图数据库的优势,储存属性非常方便,直接用key-value表示即可。比如
(n:Person{name:"John"})表示一个含有属性name值为John节点n。同样关系也可以有属性:**[r:Knows]{year: 2018}**表示为r赋予一个year属性。
关键字
几个常用的关键字介绍:
MATCH: 表示查询,是读数据库操作。比如查属于Person的节点:
MATCH (n:Person),查找姓名为“John”的节点:MATCH (n:Person){name: "John"}或者使用where语句:MATCH (n:Person) WHERE n.name="John"。当然这里面很多语法可以使用,比如正则匹配等,这里就不再赘述了。当然在实际使用中,MATCH不能单独使用,需要结合RETURN。CREATE: 表示创建,可以新增节点,关系,索引,约束等等,是一种写操作。比如
CREATE (n:Person{name:"Ana"})表示创建一个name为“Ana”的Person类的节点。在创建的同时可以设置属性:CREATE (n:Person{name:"Ana"}) set n.age=20。同样在某个属性上创建索引:CREATE INDEX ON :Person(name),这里需要提一下,尽量所有的Label都设置索引或者UNIQUE约束,在后续的读操作比如MATCH会大大提高性能(创建索引可以在导入节点之前执行)。DELETE: 表示删除节点,关系等,也是写操作。一般需要结合
MATCH匹配查询要删除的节点。MATCH (n:Person) DELETE n。如果在删除有关系的节点,这样删除会报错,可以先删除边MATCH (n:Person)-[r:KNOWS]->() DELETE r再删除节点。不过更推荐使用DETACH DELETE来级联删除,MATCH (n:Person) DETACH DELETE n可以同时删除节点及节点的关系。MERGE:合并节点或者关系,属于先读后写操作,相当于
MATCH + CREATE,先检查数据库中节点/关系是否存在,如果存在的话就不再创建,反之执行CREATE。如:MERGE(a:Person{name:“John”}) on create set a.age=20 //创建节点,先检测是否存在// 给节点a,b建立关系,如果a,b已经存在,就无需新建。
MATCH (a:Person{name:“John”}),(b:Person{name:“Ana”}) MERGE (a)-[:KNOWS]->(b)
这几个只是最基本的操作,在复杂查询中,会用到诸如WITH, UNWIND等命令。这里不再详细描述。
注意事项
- 节点名称与节点Label的定义容易混乱。比如
CREATE (n:Person)创建了一个属于Person的节点n。这里的n仅仅属于一个变量名,跟节点本身没有关系,命令执行结束,n的生命周期也就结束了,而Person则是节点本身的Label,会一直存在。 - 索引一定要建立(建立在某类的节点上当中),例如:CREATE INDEX ON :Person(id)
快捷键
关于Neo4j浏览器的初次使用有几个快捷键:
- 默认单行输入,按回车执行命令
- 输入一行命令之后,按
SHIFT + ENTER进入多行输入状态(也就是之后不用在多次按住shift+enter) - 在多行输入时,
CTRL + ENTER执行命令 **ESC可以放大输入框至屏幕大小,复杂查询的时候,很方便**。
内存配置
关于内存配置的几个参数内存配置:
dbms.memory.heap.initial_sizedbms.memory.heap.max_sizedbms.memory.pagecache.sizepagecache(页面缓存)- 可以使用
neo4j-admin memrec来根据当前数据库数据,查看推荐的内存配置(memory recommend) 分别取前三位
bin/neo4j-admin memrec --database=graph.db
file:///
就是用file:///加上对应文件的地址,打开对应的本地电脑(或者你所连接到的电脑的 ->估计指的是像windows中映射出来其他网络邻居中某个计算机为某个网盘的情况)中对应的文件。
用file:///+文件的地址,其实就等价于文件的地址,
即:
file:///C:/Users/CLi/AppData/Local/Temp/WindowsLiveWriter1627300719/supfiles52F410/wangdan-se-436963[2].jpg
其实就等价于;
C:/Users/CLi/AppData/Local/Temp/WindowsLiveWriter1627300719/supfiles52F410/wangdan-se-436963[2].jpg
使得(此处Html源码中所允许的地址,对应的WLW程序)可以访问对应的文件而已。
neo4j load csv导入问题
导入node时一般用create语句,导入关系时一般用merge语句,防止重复导入
WITH HEADERS表明csv文件的第一行是属性名。
neo4j的节点与标签关系:
MERGE (<node-name>:<label-name>
{
<Property1-name>:<Pro<rty1-Value>
.....
<Propertyn-name>:<Propertyn-Value>
})
节点模式的构成:(Variable:Lable1:Lable2{Key1:Value1,Key2,Value2}),实际上,每个节点都有一个整数ID,在创建新的节点时,Neo4j自动为节点设置ID值,在整个数据库中,节点的ID值是递增的和唯一的。
导入数据
这一部分主要记录下如何将图数据从文件中导入库,常见的格式为CSV和JSON格式。
导入CSV 格式数据
Neo4j内置了命令来导入CSV数据:使用方法也很简单。假设CSV格式如下:
"Id","Name","Year"
"1","ABBA","1992"
"2","Roxette","1986"
"3","Europe","1979"
"4","The Cardigans","1992"
直接使用如下命令导入并直接引用headers来表示属性并创建节点:
#WITH HEADERS 表示的是使用csv文件当中第一行的属性名,为之后的key:value映射做准备.(很重要)
LOAD CSV WITH HEADERS FROM 'FILE:/artists.csv' AS line
#可以没有节点名,直接:标签名
CREATE (:Artist { name: line.Name, year: toInteger(line.Year)})
注意事项:
- 分隔符默认是
,, 可以用FIELDTERMINATOR自定义分隔符:LOAD CSV WITH HEADERS FROM ‘FILE:/artists.csv’ AS line FIELDTERMINATOR “;” - 文件位置: 可以直接使用URL地址作为文件位置,如果是本地文件的话,直接使用“FILE:”表明,文件的位置是相对位置,在配置文件
neo4j.conf中的dbms.directories.import参数可以指定,默认是neo4j安装目录下的import文件夹,将CSV文件放到该目录下即可。 - 对于大规模数据,如果一次性导入可能会超内存,此时可以用
PERIODIC COMMIT来分批提交导入数据,默认是1000行提交一次,具体如下:
#PERIODIC:代表的是周期性的,commit:提交
USING PERIODIC COMMIT 500
LOAD CSV WITH HEADERS FROM...
....
- 文本内容存在
"的字段需要特殊处理
一般使用:
field terminated by ','
optionally enclosed by '"'
lines terminated by '\r'
导入JSON格式数据
图数据里面更常见的则是JSON数据, 假设数据格式如下:
[
{
"id":1, "friends":[2,3], "name": "Bob", "age": 27,
"book":[{"name":"book1", "year":2000}, {"name":"book3", "year":1990}]
},
{
"id":2, "friends":[1], "name": "Alice", "age": 29,
"book":[{"name":"book1", "year":2000}, {"name":"book2", "year":1999}]
},
{
"id":3, "friends":[2], "name": "John", "age": 20,
"book":[{"name":"book3", "year":1990}]
}
]
列表中每一个map都代表一个User, 其属性有id,name,age; 同时friends字段表示朋友关系,book字段表示读过某本书。 现在我们需要创建 Person 和 Book两类节点,同时Person和Book 之间有READ关系。
APOC
实际上就是一个用户过程存储库300+函数)
a package of component :组件包
变为
awesome procedure on cypher:超级棒的存储过程
Neo4j 并没有内置直接导入Json的函数,不过在Neo3.3版本之后,推出了一个函数存储包APOC,里面包含了非常丰富的函数和存储过程,如各种图计算算法,是Cypher的有力补充,其中就包含了从Json中导入数据。安装APOC很简单,只需要三步:
- 从github中下载与Neo4j对应版本的APOCjar包
- 将jar包拷贝到neo4j安装目录的plugins目录下
- 在配置文件neo4j.conf中加入一行允许APOC导入文件:apoc.import.file.enabled=true
- 重启Neo4j即可
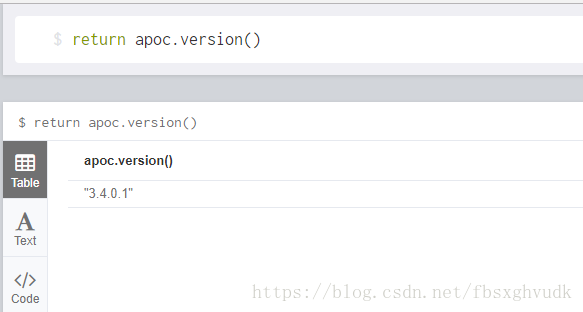
在Neo4j浏览器中,输入return apoc.version()即可查看版本号
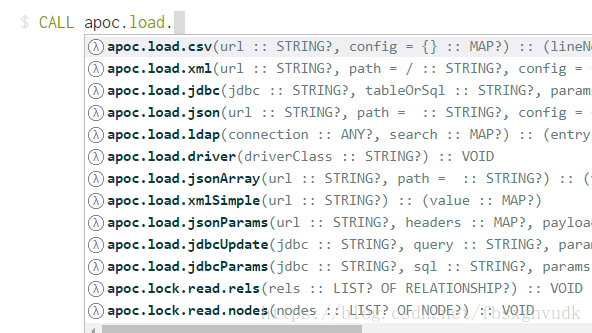
此外我们可以看到apoc支持导入非常多格式的数据:
导入方式很简单,我们要创建两类节点,首先创建索引,方便后续导入。
CREATE INDEX ON :Person(id)
#不能一起创建索引,需要分开分步执行.
CREATE INDEX ON :Book(name)
否则会报错:
Neo.ClientError.Statement.SyntaxError: Invalid input 'C': expected whitespace, comment, ';' or end of input (line 2, column 1 (offset: 28))
"CREATE INDEX ON :Book(name)"

导入代码如下:
// YIELD关键字表示每次导入json数据中的一组数据,即`[...]`中的每一个`{}`, 这里的person.json是系统绝对路径
CALL apoc.load.json("file:///D:/neo4j-community-3.4.0/import/person.json") YIELD value as person //这个最好是绝对路径,否则会报错.(重点注意)
// 需要对book属性进行列表展开,后续建立Person和Book关系的时候,需要用。
UNWIND person.book as book
// 创建Person节点
MERGE (p:Person{id:person.id})
SET p.name=person.name, p.age=person.age, p.friends=person.friends
//创建book节点
MERGE (b:Book{name:book.name})
SET b.year=book.year
//建立person->book关系
MERGE (p)-[:READ]->(b)
然后再根据已有的friends导入Friend关系:
//对每一个 person遍历
MATCH (p:Person)
// 对p的friends进行列表展开,
UNWIND p.friends as f
// 根据id搜索Person节点
MATCH (q:Person{id:f})
// 建立关系
MERGE (p)-[:Friend]-(q)
执行完成之后,可视化看一下 ,:
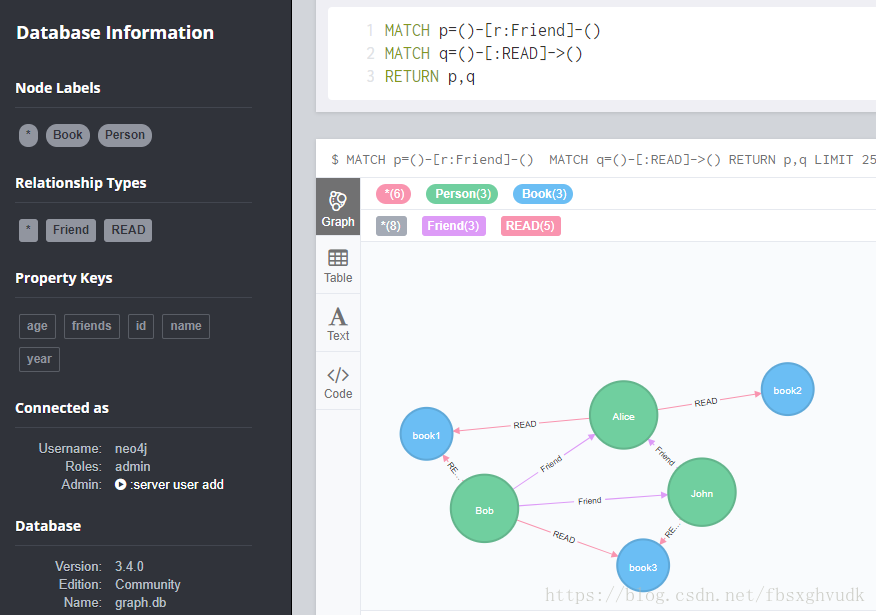
neo4j浏览器界面说明
左侧(看上图就可以)是数据库的基本信息:包括节点标签,连接类型,*代表全部情况(各个类型的全部情况),属性,当前连接者,neoj数据库版本信息:
第一行:(*)6:代表节点的总个数;person(3):代表person类节点的个数是3,
第二行:(*)8代表连接数的总个数,Friend(3)是friend连接类型的边数有三个,后面以此类推
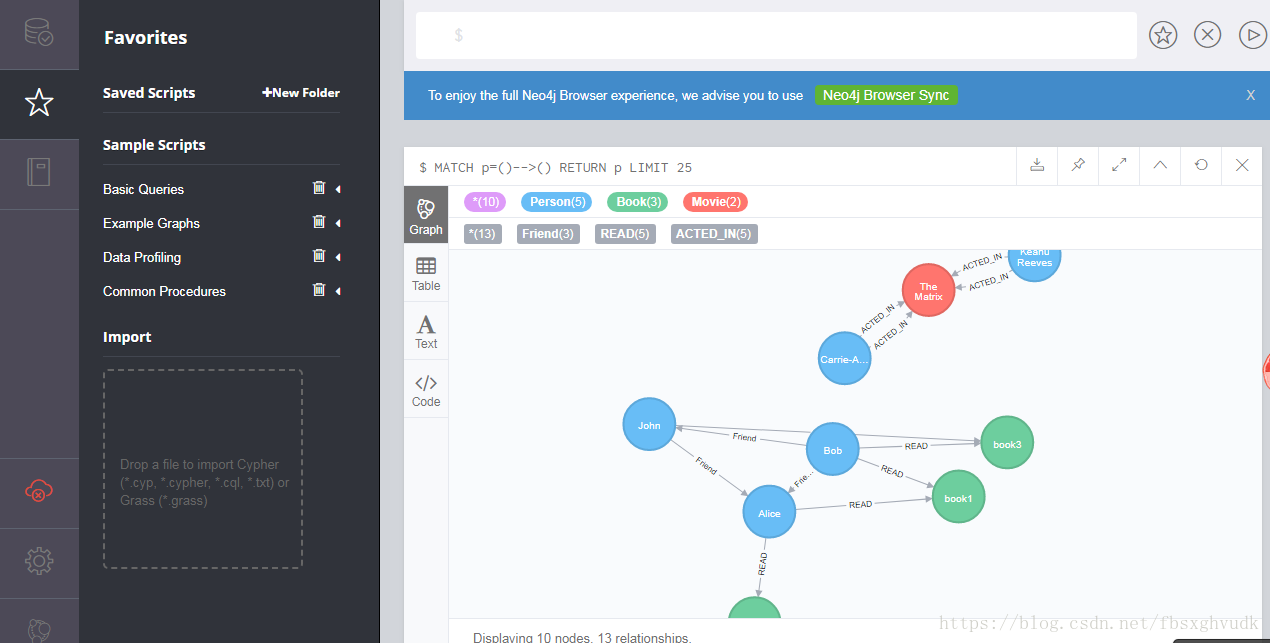
上图左侧五角星那项是专门用来 保存一些基本和自定义的脚本代码–cypher语句(在右侧左上角点击收藏之后刷新就会看到),便于加快速度,可以分类,添加的话可以拖拽相关类型文件添加.
类似书本那项则是关于neo4j的说明文档,cypher语句的技术手册.
红云朵那项则是用来云同步的(可选项,)可以清除当前登录信息.clear all data
- 左侧齿轮状选项则是用来设置neo4j的浏览器界面的(有主题,和显示结果的个数设置)
- 左侧最下角的是关于neo4j的版本信息
到这里导入基本完成了,不过还有一点问题,暂时没有解决,使用UNWIND person.book as book的时候,如果某个节点没有book这个一个属性,那么后续代码将不再执行,即该Person节点不会创建。但是如果将UNWIND放到创建Person之后,建立的READ关系会有问题,还在查找原因。
参考资源
neo4j 初探的更多相关文章
- Neo4j初探
neo4j-desktop-win64 exe https://neo4j.com/download-thanks-desktop/?edition=desktop&flavour=winst ...
- 图数据库-Neo4j-初探
图数据库-Neo4j-初探 2018-08-17 本次初探主要学习如何安装Neo4j,以及Cypher的基本语法. 1. 安装Neo4j Desktop版本 neo4j-desktop Server版 ...
- 图数据库初探之Neo4j
图数据库初试之Neo4j 自从进入了移动互联网时代,各种新事物出现的速度都好像坐上了宇宙飞船,几乎隔几天一个新概念.就拿数据库而言,什么Oracle.DB2.SQL Server.MySQL,这些你都 ...
- Neo4j入门-开始使用
前言 关系,指事物之间相互作用.相互影响的状态. 数据之间的关系也是如此,数据之间关系的存储在RDS就已经开始.从数据库支持的外键,到手动建立的关系表,人们采取了许多方法,只为了解决查询复杂.缓慢等问 ...
- 初探领域驱动设计(2)Repository在DDD中的应用
概述 上一篇我们算是粗略的介绍了一下DDD,我们提到了实体.值类型和领域服务,也稍微讲到了DDD中的分层结构.但这只能算是一个很简单的介绍,并且我们在上篇的末尾还留下了一些问题,其中大家讨论比较多的, ...
- 图形数据库Neo4J简介
最近我在用图形数据库来完成对一个初创项目的支持.在使用过程中觉得这种图形数据库实际上挺有意思的.因此在这里给大家做一个简单的介绍. NoSQL数据库相信大家都听说过.它们常常可以用来处理传统的关系型数 ...
- CSharpGL(8)使用3D纹理渲染体数据 (Volume Rendering) 初探
CSharpGL(8)使用3D纹理渲染体数据 (Volume Rendering) 初探 2016-08-13 由于CSharpGL一直在更新,现在这个教程已经不适用最新的代码了.CSharpGL源码 ...
- 从273二手车的M站点初探js模块化编程
前言 这几天在看273M站点时被他们的页面交互方式所吸引,他们的首页是采用三次加载+分页的方式.也就说分为大分页和小分页两种交互.大分页就是通过分页按钮来操作,小分页是通过下拉(向下滑动)时异步加载数 ...
- JavaScript学习(一) —— 环境搭建与JavaScript初探
1.开发环境搭建 本系列教程的开发工具,我们采用HBuilder. 可以去网上下载最新的版本,然后解压一下就能直接用了.学习JavaScript,环境搭建是非常简单的,或者说,只要你有一个浏览器,一个 ...
随机推荐
- 'utf-8' codec can't decode byte 0xd0 in position 0问题
今天利用pd.read_csv(url)从网络上读取数据时出现了如下错误: 'utf-8' codec can't decode byte 0xd0 in position 0 问题原因:网络上的这个 ...
- 【Leetcode】最长回文子串
启发 1)做题前一定要读懂题目 在本题中,首先要清楚地定义回文子串的概念,然后才能设计算法查找它. 如中心扩散法,其主要思想在于找到一个回文子串的定义——两侧互为镜像.进一步分为奇数长度和偶数长度进行 ...
- Python字典实现
这篇文章描述了在Python中字典是如何实现的. 字典通过键(key)来索引,它可以被看做是关联数组.我们在一个字典中添加3个键/值对: >>> d = {'a': 1, 'b': ...
- Shell test命令/流程控制
Shell test命令 Shell中的 test 命令用于检查某个条件是否成立,它可以进行数值.字符和文件三个方面的测试. 数值测试 参数,说明 -eq等于则为真 -ne不等于则为真 -gt 大于则 ...
- 前端iPhone X适配总结
屏幕尺寸 垂直方向上,iPhone X的显示宽度与iPhone 6,iPhone 7 和 iPhone 8 的 4.7 英寸一样,但是比4.7英寸的显示屏高145pt. 安全区域 安全区域指的是一个可 ...
- npm-package-lock.json
npm notice created a lockfile as package-lock.json. You should commit this file. https://docs.npmjs. ...
- [论文理解] LFFD: A Light and Fast Face Detector for Edge Devices
LFFD: A Light and Fast Face Detector for Edge Devices 摘要 从微信推文中得知此人脸识别算法可以在跑2K图片90fps,仔细一看是在RTX2070下 ...
- hibernate缓存机制与N+1问题
在项目中遇到的趣事 本文基于hibernate缓存机制与N+1问题展开思考, 先介绍何为N+1问题 再hibernate中用list()获得对象: /** * 此时会发出一条sql,将30个学生全部查 ...
- Putty - 免用户名密码登录
打开 Putty 时携带 -pw your_password your_username@your_host 参数即可.
- Unity3D 连接MySql
MySql安装如下: https://www.cnblogs.com/dlvguo/p/9671832.html Unity连接MySql首先要在Unity的安装目录D:\Unity2017\Edit ...