Hibernate(4)——主键生成策略、CRUD 基础API区别的总结 和 注解的使用
俗话说,自己写的代码,6个月后也是别人的代码……复习!复习!复习!涉及的知识点总结如下:
- hibernate的主键生成策略
- UUID
- 配置的补充:hbm2ddl.auto属性用法
- 注解还是配置文件
- hibernate注解的基本用法
- 使用Session API CRUD操作对象,以及对象状态的转换
- hibernate缓存的概念
- get()/load()的区别到底是什么,源码分析
- 代理模式实现的懒加载
- saveOrUpdate()/merge()的区别
Assigned(常用,一般情况使用很方便):
由程序生成主键值,并且在save()之前指定,否则会抛出异常。
特点:主键的生成值完全由用户决定,与底层数据库无关。用户需要维护主键值,在调用session.save()之前要指定主键值。唯一的例外:int auto_increment类型主键除外,在程序中不用指定主键值,直接看代码:

sid是主键,且是int类型,设置为自动增长。
/**
* StudentDao
*
* @author Wang Yishuai.
* @date 2016/3/11 0011.
* @Copyright(c) 2016 Wang Yishuai,USTC,SSE.
*/
public class StudentDao {
private static final Logger LOG = LoggerFactory.getLogger(StudentDao.class); private Session session; @Before
public void init() {
Configuration configuration = new Configuration().configure();
SessionFactory sessionFactory = configuration.buildSessionFactory();
this.session = sessionFactory.getCurrentSession();
} @After
public void clear() { } @Test
public void save() {
Transaction transaction = session.beginTransaction(); Student student = new Student(); try {
//student.setSname("dashuai");
student.setSname("dadadad");
session.save(student);
transaction.commit();
} catch (Exception e) {
LOG.error("save error", e);
transaction.rollback();
}
}
}
配置文件设置:
<hibernate-mapping>
<!-- class 里面的属性必须和对应的类名,表名保持一致,实现映射-->
<class name="zhujian.vo.Student" table="students">
<!-- id代表数据库表的主键, name="userId",对应数据库表里的字段column="userId"-->
<id name="sid" column="sid" type="string">
<generator class="assigned"/>
</id>
<!-- 数据库里其他普通字段和实体属性的映射,属性的类型需要小写-->
<property name="sname" column="sname" type="string"/>
</class>
</hibernate-mapping>
先后保存两个学生对象,没有错误,如下:

即使我设置了主键生成策略为assigned,因为学生表的sid是自动增长且为int类型,所以程序中不用人工指定sid值,这是一个例外情况。其他情况如果设置主键为asigned策略,必须手动设主键值,否则会出问题。
把sid的自动增长设置取消,再运行之前的代码,会发生问题:如果不设置sid(主键)值,则无法成功插入数据,且会生成主键为0的数据记录(if之前没有),本地测试没有报错,但是无法成功插入。
把主键改为String(varchar)类型(对象映射文件和实体类也需要修改),再运行之前的代码,同样只能插入sid为0的记录(if之前没有),其他的无法继续插入。若改为手动设置主键值,则恢复正常。
Increment(MySQL不适用,集群不适用,多进程不适用,与底层数据库有关)
Increment方式对主键值采取自动增长的方式生成新的主键值,但要求底层数据库支持Sequence序列。如Oracle,DB2等。需要在映射文件xxx.hbm.xml中加入Increment标志符的设置。
特点:由Hibernate本身维护,适用于所有的数据库,不适合多进程并发更新数据库,适合单一进程访问数据库。不能用于群集环境。
比如现在有4个数据库的集群,共享一张学生表,我从中查找某个编号(主键)为1000的学生,如果使用的hibernate的主键生成策略为increment,则无法保证编号1000的学生在集群里是唯一的。
Identity根据底层数据库支持自动增长,无需手动设置主键,但不同的数据库用不同的主键增长方式,移植性不好。
特点:与底层数据库有关,适用于MySQL、DB2、MS SQL Server,采用数据库生成的主键,用于为long、short、int类型生成唯一标识。使用SQL Server 和 MySQL 的自增字段,这个方法不能放到 Oracle 中,Oracle 不支持自增字段,要设定sequence(MySQL 和 SQL Server 中很常用),Identity无需Hibernate和用户的干涉,使用较为方便,但不便于在不同的数据库之间移植程序。
Sequence (常用)
Sequence需要底层数据库支持Sequence方式,例如Oracle数据库等。
特点:需要底层数据库的支持序列,支持序列的数据库有DB2、PostgreSql、Qracle、SAPDb等在不同数据库之间移植程序,特别从支持序列的数据库移植到不支持序列的数据库需要修改配置文件。比如:Oracle:create sequence seq_name increment by 1 start with 1; 需要主键值时可以调用seq_name.nextval或者seq_name.curval得到,数据库会帮助我们维护这个sequence序列,保证每次取到的值唯一,如:insert into tbl_name(id, name) values(seq_name.nextval, ‘Jimliu’);
配置:
<id name="id" column="id" type="long">
<generator class="sequence">
<param name="sequence">seq_name</param>
</generator>
</id>
Native(常用,推荐使用,移植性好,也适合多数据库)
Native主键生成方式会根据不同的底层数据库自动选择Identity、Sequence、Hilo主键生成方式。
特点:根据不同的底层数据库采用不同的主键生成方式。由于Hibernate会根据底层数据库采用不同的映射方式,因此便于程序移植,项目中如果用到多个数据库时,可以使用这种方式。
配置:
<id name="id" column="id">
<generator class="native" /></id>
UUID(常用在网络环境,但是耗费存储空间)
UUID使用128位UUID算法生成主键,能够保证网络环境下的主键唯一性,也就能够保证在不同数据库及不同服务器下主键的唯一性。
特点;能够保证数据库中的主键唯一性,生成的主键占用比较多的存贮空间。
配置:
<id name="id" column="id">
<generator class="uuid.hex" /></id>
Hilo(不常用)
使用高低位算法生成主键,高低位算法使用一个高位值和一个低位值,然后把算法得到的两个值拼接起来作为数据库中的唯一主键。Hilo方式需要额外的数据库表和字段提供高位值来源。默认请况下使用的表是hibernate_unique_key,默认字段叫作next_hi。next_hi必须有一条记录否则会出现错误。
特点:和底层数据库无关,但是需要额外的数据库表的支持,能保证同一个数据库中主键的唯一性,但不能保证多个数据库之间主键的唯一性。Hilo主键生成方式由Hibernate 维护,所以Hilo方式与底层数据库无关,但不应该手动修改hilo算法使用的表的值,否则会引起主键重复的异常。
配置的补充:hbm2ddl.auto属性用法
在项目的配置文件里设置:<property name="hbm2ddl.auto">update</property>,属性含义的解释:
- create:表示启动的时候先drop数据库,再create。
- create-drop: 也表示创建,只不过再系统关闭前执行一下drop。
- update: 这个操作启动的时候会去检查schema是否一致,如果不一致会做scheme更新。
- validate: 启动时验证现有schema与你配置的hibernate是否一致,如果不一致就抛出异常,并不做更新。
在Hibernate是用映射文件好还是用注解的方式好?
两种方式本质上没区别。使用元数据可以在写实体的同时配好映射,而 XML 则需要来回切换配置和实体,不太方便。从维护上来说,注解更好。因为代码和“配置”在一起,不容易漏掉信息。从这一点上来说,注解必须是第一选择。但是也有人说到这样一个问题,如果使用注解,有很大可能会违反开闭原则,使用配置文件则不会。闲言少叙,看代码:
<?xml version='1.0' encoding='UTF-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="MySQL">
<property name="connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="connection.url">jdbc:mysql://localhost:3306/bbs</property>
<property name="connection.username">root</property>
<property name="connection.password">123</property>
<property name="dialect">org.hibernate.dialect.MySQL5Dialect</property>
<property name="show_sql">true</property>
<property name="format_sql">true</property>
<property name="hbm2ddl.auto">update</property>
<property name="current_session_context_class">thread</property> <mapping class="net.nw.vo.Students"/>
</session-factory>
</hibernate-configuration>
写好配置文件,代码如下:
package net.nw.vo; import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id; //学生实体类
@Entity
public class Students {
private int sid; private String sname; @Id
@GeneratedValue(strategy=GenerationType.AUTO)
public int getSid() {
return sid;
} public void setSid(int sid) {
this.sid = sid;
} public String getSname() {
return sname;
} public void setSname(String sname) {
this.sname = sname;
}
}
测试:
import net.nw.vo.Students;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.Transaction;
import org.hibernate.cfg.AnnotationConfiguration; public class HibernateTest { public static void main(String[] args) {
AnnotationConfiguration annotationConfiguration = new AnnotationConfiguration().configure();
SessionFactory sessionFactory = annotationConfiguration.buildSessionFactory();
Session session = sessionFactory.getCurrentSession();
Transaction transaction = session.beginTransaction(); try {
Students s = new Students();
//s.setSid(1);
s.setSname("xxxx");
session.save(s);
transaction.commit();
} catch (Exception ex) {
transaction.rollback();
ex.printStackTrace();
}
}
}
执行成功!本地测试成功插入xxxxx(接之前的bbs数据库表students):
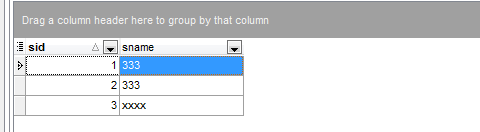
小结:
- 使用AnnotationConfiguration创建config对象代替之前的Configuration方式(hibernate3的方式)。
- hibernate4中新增了ServiceRegistry接口。4.0以后改为使用ServiceRegistry 注册:
Configuration cfg = new Configuration().configure();
ServiceRegistry serviceRegistry = new ServiceRegistryBuilder().applySettings(cfg.getProperties()).buildServiceRegistry();
SessionFactory factory = cfg.buildSessionFactory(serviceRegistry);
Session s = factory.openSession();
- @Entity——必选的注解,在class类体上面,注解将一个类声明为一个实体bean。属性 name 可选,对应数据库中的一个表。若表名与实体类名相同,则可以省略。
@Table(name="",catalog="",schema="") ——该注解可选,通常和@Entity 配合使用,只能标注在实体的 class 定义处,表示实体对应的数据库表的信息。属性:
name - 可选,表示表的名称,默认地,表名和实体名称一致,只有在不一致的情况下才需要指定表名
catalog - 可选,表示Catalog名称,默认为 Catalog("").
schema - 可选 , 表示 Schema 名称 , 默认为Schema("").
- @Id——必选,一般加在getter方法上面, 定义了映射到数据库表的主键的属性,一个实体只能有一个属性被映射为主键,置于get方法前。
- @GeneratedValue(strategy=GenerationType,generator="") ——可选,用于定义主键生成策略。属性:
- Strategy - 表示主键生成策略,取值有:
- GenerationType.AUTO - 根据底层数据库自动选择(默认),若数据库支持自动增长类型,则为自动增长。
GenerationType.INDENTITY - 根据数据库的Identity字段生成,支持DB2、MySQL、MS、SQL Server、SyBase与HyperanoicSQL数据库的Identity类型主键。
GenerationType.SEQUENCE - 使用Sequence来决定主键的取值,适合Oracle、DB2等 ,支持Sequence的数据库,一般结合@SequenceGenerator使用。(Oracle没有自动增长类型,只能用Sequence)
GenerationType.TABLE - 使用指定表来决定主键取值,结合@TableGenerator使用。如:
@Id @TableGenerator(name="tab_cat_gen",allocationSize=1) @GeneratedValue(Strategy=GenerationType.Table)
Generator - 表示主键生成器的名称,这个属性通常和ORM框架相关 , 例如:Hibernate 可以指定 uuid 等主键生成方式
- Strategy - 表示主键生成策略,取值有:
@Version——可以在实体bean中使用@Version注解,通过这种方式可添加对乐观锁定的支持。
@Basic ——用于声明属性的存取策略:
@Basic(fetch=FetchType.EAGER) 即时获取(默认的存取策略)
@Basic(fetch=FetchType.LAZY) 延迟获取
@Temporal ——用于定义映射到数据库的时间精度:@Temporal(TemporalType=TIME) 时间、@Temporal(TemporalType=DATE) 日期、@Temporal(TemporalType=TIMESTAMP) 两者兼具
注解太多了,以后一一说明。
- 使用注解,在Hibernate.cfg.xml中同样也需要注册实体类。当然配置文件不用配,只是还是需要引入实体类的关系,<mapping class="net.nw.vo.Students"/>,配置文件方式的resource=改为了class=。
使用session api实现crud
结合之前的总结,看看crud时对象状态的转换关系。直接看代码:
- create,session.save(obj);,注意这里面的玄机:
- 如果当前对象是持久态,则执行save方法,会自动触发Update语句的执行,而不是insert语句。
- 如果当前对象为瞬时态,则执行save方法,会立刻执行insert语句,使得对象从瞬时态转换为持久态。
@Test
public void save() {
Transaction transaction = session.beginTransaction();
Student student = new Student(); try {
student.setSname("xiaoli");
// 之前的student是瞬时态的
session.save(student);
// 之后变为持久态
transaction.commit();
} catch (Exception e) {
LOG.error("save error", e);
transaction.rollback();
}
}
debug一下,验证之前的理论:在sava处断点,step over之后,立即控制台打印了insert into students(sname) values(?)。后台数据库也插入了xiaoli。

下面看如果当前对象是持久态的情况:
@Test
public void save() {
Transaction transaction = session.beginTransaction();
// Student student = new Student(); try {
// student.setSname("xiaoli"); // 从数据库读取xiaoli,该对象是持久态的
Student student = (Student) session.get(Student.class, 7);
// 重新赋值,再保存
student.setSname("小李");
session.save(student);
transaction.commit();
} catch (Exception e) {
LOG.error("save error", e);
transaction.rollback();
}
}
还是在save处debug,发现首先发送SQL语句:
select
student0_.sid as sid2_0_,
student0_.sname as sname2_0_
from
students student0_
where
student0_.sid=?
执行save之后,发送的SQL是:
update
students
set
sname=?
where
sid=?
道理很明显,如果还是插入语句,则会插入新的记录,显然不对了。
- retrive,hibernate基本的查询api是get和load(只根据主键查询,不能根据其它字段查询,如果想根据非主键查询,可以使用HQL),之前也看了get的用法了,使用get查询对象,执行之后,对象变为持久态的,立刻发送SQL语句select……而且也可以直接填写实体类名,get查找返回的是真正的实体对象,如果找不到则返回null,代码如下:
Student student = (Student) session.get("zhujian.vo.Student", 1);
LOG.info("sid = {}, sname = {}", student.getSid(), student.getSname());
debug一下:

执行48句之后:

再看load方法,参数写法和get一样的,但是load是一种懒加载的方式,只有使用的时候才生成sql语句:
@Test
public void retrive() {
Transaction transaction = session.beginTransaction(); try {
Student student = (Student) session.load(Student.class, 2);
student.setSname("小李");
session.save(student);
transaction.commit();
} catch (Exception e) {
LOG.error("save error", e);
transaction.rollback();
}
}
load方法查询的对象是代理对象,且执行此方法时不会立即发出查询语句。因为使用load加载对象去查询某一条数据的时候并不会直接将这条数据以指定对象的形式来返回,而是在真正需要使用该对象里面的一些属性的时候才会去查找对象。他的好处就是可以减少程序本身因为与数据库频繁的交互造成的处理速度缓慢的问题。
而hibernate的load方法延迟加载实现原理是使用代理(代理设计模式在hibernate的的应用),Hibernate的懒加载,是通过在内存中对类、集合等的增强(即在内存中扩展类的特性[继承])来实现的,这些类通常称为代理类。比如我们通过session.load(class, id)操作,加载一个对象的时候,hibernate返回的实际上是实体类的代理类实例。如图:
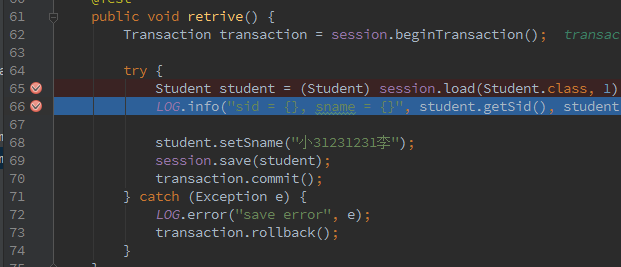
执行65句之后:

但如通过session.get操作,则返回实际的对象实例(不是代理类实例),对上例而言,get操作返回实体类的实例。采用load()方法加载数据,如果数据库中没有相应的记录,则会抛出异常:org.hibernate.ObjectNotFoundException: No row with the given identifier exists:……所以如果我知道该id在数据库中一定有对应记录存在,那么我就可以使用load方法来实现延迟加载。
session缓存(hibernate一级缓存)概念
在继续探讨这个问题之前,必须先提前总结下缓存的一些东西。
Hibernate缓存包括两大类:Hibernate一级缓存和Hibernate二级缓存。
一级缓存就是Session级别的缓存,一个Session做了一个查询操作,它会把这个操作的结果放在一级缓存中,如果短时间内这个session(一定要同一个session)又做了同一个操作,那么hibernate直接从一级缓存中拿,而不会再去连数据库取数据。它是属于事务范围的缓存,Session对象的生命周期通常对应一个数据库事务或者一个应用事务,一级缓存中,持久化类的每个实例都具有唯一的OID。这一级别的缓存由hibernate管理,无需主动干预即可工作。
二级缓存就是 SessionFactory 级别的缓存,查询的时候会把查询结果缓存到二级缓存中,如果同一个sessionFactory创建的某个session执行了相同的操作,hibernate就会从二级缓存中拿结果,而不会再去连接数据库,因为SessionFactory对象的生命周期和应用程序的整个过程对应,因此Hibernate二级缓存是进程范围或者集群范围的缓存,有可能出现并发问题,因此需要采用适当的并发访问策略,该策略为被缓存的数据提供了事务隔离级别,需要人工配置和更改,可以动态加载,卸载(二级缓存是一个可配置的插件,默认下SessionFactory不会启用这个插件。)。而一级缓存不可以卸载。
当Hibernate根据ID访问数据对象的时候,首先从Session一级缓存中查,查不到,如果配置了二级缓存,那么从二级缓存中查,如果都查不到,再查询数据库,把结果按照ID放入到缓存删除、更新、增加数据的时候,同时更新缓存。
Student student = (Student) session.get(Student.class, 6);
LOG.info("student sid = {}, student sname = {}", student.getSid(), student.getSname()); Student student1 = (Student) session.get(Student.class, 6);
LOG.info("student1 sid = {}, student1 sname = {}", student1.getSid(), student1.getSname());
debug查看效果:执行完第一个get语句,立即发送了SQL语句,执行第二个一样的get语句时,我发现并没打印SQL语句,而是直接打印了log,只能说明,它第二次一样的对象查询是在缓存中查找到的。

网上有人说get不从缓存中查找,这是不对的,还有人说get不会去二级缓存中查找,其实也不对。或者严格的说必须指定哪个版本的hibernate再来讨论这个问题,下面还会分析源码来再次佐证(hibernate 3)。
再看load的方式:
Student student = (Student) session.load(Student.class, 6);
LOG.info("sid = {}, sname = {}", student.getSid(), student.getSname()); Student student1 = (Student) session.load(Student.class, 6);
LOG.info("student1 sid = {}, student1 sname = {}", student.getSid(), student.getSname());
也是第二次查找同一个对象的时候,没有再生成SQL语句,直接打印的两个log,只能说明它是在缓存中查询了。load方法也是走缓存的。那么具体怎么走,下面看源码级别的分析。
load和get的源码分析:
先看get和load的api源码,位于SessionImpl类,它是Session接口的一个实现类:

上面是load方法的,下面是get方法:

两种方式类似,那么继续看重载的load和get方法源码:
public Object get(String entityName, Serializable id) throws HibernateException {
LoadEvent event = new LoadEvent(id, entityName, false, this);
boolean success = false;
Object var5;
try {
this.fireLoad(event, LoadEventListener.GET);
success = true;
var5 = event.getResult();
} finally {
this.afterOperation(success);
}
return var5;
}
public Object load(String entityName, Serializable id) throws HibernateException {
LoadEvent event = new LoadEvent(id, entityName, false, this);
boolean success = false;
Object var5;
try {
this.fireLoad(event, LoadEventListener.LOAD);
if(event.getResult() == null) {
this.getFactory().getEntityNotFoundDelegate().handleEntityNotFound(entityName, id);
}
success = true;
var5 = event.getResult();
} finally {
this.afterOperation(success);
}
return var5;
}
关键区别是this.fireLoad(event, LoadEventListener.LOAD);和this.fireLoad(event, LoadEventListener.GET);这两句代码,官方文档说,使用fireLoad方法把加载事件event和事件加载的监听器(一个接口)的方式组合,也就是这两个方法触发事件的方式不一样。下面先看看这两个代表不同触发方式的常量:
LoadEventListener.LoadType GET = (new LoadEventListener.LoadType("GET")).setAllowNulls(true).setAllowProxyCreation(false).setCheckDeleted(true).setNakedEntityReturned(false);
LoadEventListener.LoadType LOAD = (new LoadEventListener.LoadType("LOAD")).setAllowNulls(false).setAllowProxyCreation(true).setCheckDeleted(true).setNakedEntityReturned(false);
区别就是:在allowNulls上get允许空,也就是get找不到就返回null,而load不允许空,所以抛出异常!而在allowProxyCreation上get不允许代理创建,而load允许代理的创建,记住这点。继续看fireload方法源码:
private void fireLoad(LoadEvent event, LoadType loadType) {
this.errorIfClosed();
this.checkTransactionSynchStatus();
LoadEventListener[] loadEventListener = this.listeners.getLoadEventListeners();
for(int i = 0; i < loadEventListener.length; ++i) {
loadEventListener[i].onLoad(event, loadType);
}
}
使用的内部的LoadEventListener[] loadEventListener数组去调用loadEventListener[i].onLoad(event, loadType);方法,加载方式和事件作为参数传入,下面看onload方法:
public void onLoad(LoadEvent event, LoadType loadType) throws HibernateException {
EventSource source = event.getSession();
EntityPersister persister;
if(event.getInstanceToLoad() != null) {
persister = source.getEntityPersister((String)null, event.getInstanceToLoad());
event.setEntityClassName(event.getInstanceToLoad().getClass().getName());
} else {
persister = source.getFactory().getEntityPersister(event.getEntityClassName());
}
if(persister == null) {
throw new HibernateException("Unable to locate persister: " + event.getEntityClassName());
} else {
if(!persister.getIdentifierType().isComponentType() || EntityMode.DOM4J != event.getSession().getEntityMode()) {
Class keyToLoad = persister.getIdentifierType().getReturnedClass();
if(keyToLoad != null && !keyToLoad.isInstance(event.getEntityId())) {
throw new TypeMismatchException("Provided id of the wrong type for class " + persister.getEntityName() + ". Expected: " + keyToLoad + ", got " + event.getEntityId().getClass());
}
}
EntityKey keyToLoad1 = new EntityKey(event.getEntityId(), persister, source.getEntityMode());
try {
if(loadType.isNakedEntityReturned()) {
event.setResult(this.load(event, persister, keyToLoad1, loadType));
} else if(event.getLockMode() == LockMode.NONE) {
event.setResult(this.proxyOrLoad(event, persister, keyToLoad1, loadType));
} else {
event.setResult(this.lockAndLoad(event, persister, keyToLoad1, loadType, source));
}
} catch (HibernateException var7) {
log.info("Error performing load command", var7);
throw var7;
}
}
}
找到关键的代码,因为我的测试例子里,两个方法都没有调用带 lockMode 的 api,它们默认 null,执行这一句:
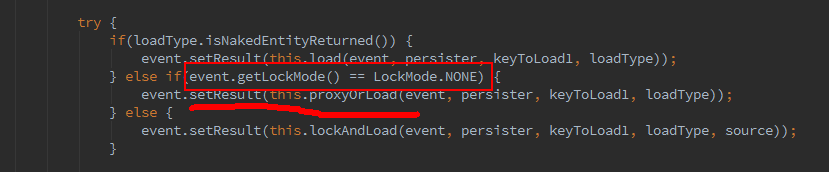
get和load查询方法都走该句,那么继续看proxyOrLoad方法:
protected Object proxyOrLoad(LoadEvent event, EntityPersister persister, EntityKey keyToLoad, LoadType options) {
if(log.isTraceEnabled()) {
log.trace("loading entity: " + MessageHelper.infoString(persister, event.getEntityId(), event.getSession().getFactory()));
}
if(!persister.hasProxy()) {
return this.load(event, persister, keyToLoad, options);
} else {
PersistenceContext persistenceContext = event.getSession().getPersistenceContext();
Object proxy = persistenceContext.getProxy(keyToLoad);
return proxy != null?this.returnNarrowedProxy(event, persister, keyToLoad, options, persistenceContext, proxy):(options.isAllowProxyCreation()?this.createProxyIfNecessary(event, persister, keyToLoad, options, persistenceContext):this.load(event, persister, keyToLoad, options));
}
}
关键语句 if(!persister.hasProxy()),大概机制就是当该方式没有发现代理存在,也就是get的加载方式,就return this.load(event, persister, keyToLoad, options) 方法的值,那么看load方法的源码:
protected Object load(LoadEvent event, EntityPersister persister, EntityKey keyToLoad, LoadType options) {
if(event.getInstanceToLoad() != null) {
if(event.getSession().getPersistenceContext().getEntry(event.getInstanceToLoad()) != null) {
throw new PersistentObjectException("attempted to load into an instance that was already associated with the session: " + MessageHelper.infoString(persister, event.getEntityId(), event.getSession().getFactory()));
}
persister.setIdentifier(event.getInstanceToLoad(), event.getEntityId(), event.getSession().getEntityMode());
}
Object entity = this.doLoad(event, persister, keyToLoad, options);
boolean isOptionalInstance = event.getInstanceToLoad() != null;
if((!options.isAllowNulls() || isOptionalInstance) && entity == null) {
event.getSession().getFactory().getEntityNotFoundDelegate().handleEntityNotFound(event.getEntityClassName(), event.getEntityId());
}
if(isOptionalInstance && entity != event.getInstanceToLoad()) {
throw new NonUniqueObjectException(event.getEntityId(), event.getEntityClassName());
} else {
return entity;
}
}
关键一句:Object entity = this.doLoad(event, persister, keyToLoad, options);,到这里就一目了然了:
protected Object doLoad(LoadEvent event, EntityPersister persister, EntityKey keyToLoad, LoadType options) {
if(log.isTraceEnabled()) {
log.trace("attempting to resolve: " + MessageHelper.infoString(persister, event.getEntityId(), event.getSession().getFactory()));
}
Object entity = this.loadFromSessionCache(event, keyToLoad, options);// 先从session缓存(一级缓存)中加载对象
if(entity == REMOVED_ENTITY_MARKER) {
log.debug("load request found matching entity in context, but it is scheduled for removal; returning null");
return null;
} else if(entity == INCONSISTENT_RTN_CLASS_MARKER) {
log.debug("load request found matching entity in context, but the matched entity was of an inconsistent return type; returning null");
return null;
} else if(entity != null) {// 在一级缓存里查找到对象就返回该对象
if(log.isTraceEnabled()) {
log.trace("resolved object in session cache: " + MessageHelper.infoString(persister, event.getEntityId(), event.getSession().getFactory()));
}
return entity;
} else { // 一级缓存找不到,get方法去二级缓存找
entity = this.loadFromSecondLevelCache(event, persister, options);
if(entity != null) {// 如果存在且找到就返回该对象
if(log.isTraceEnabled()) {
log.trace("resolved object in second-level cache: " + MessageHelper.infoString(persister, event.getEntityId(), event.getSession().getFactory()));
}
return entity;
} else { // 最后缓存找不到,才去数据库查询
if(log.isTraceEnabled()) {
log.trace("object not resolved in any cache: " + MessageHelper.infoString(persister, event.getEntityId(), event.getSession().getFactory()));
}
return this.loadFromDatasource(event, persister, keyToLoad, options);
}
}
}
显然,get的查询方式,首先查询session缓存,也就是一级缓存,没有就去查询二级缓存,如果没有二级缓存或者没找到,最后才去查数据库。
下面看看load方法,其实大同小异,和get的源码差不多,只不过走了其他一些分支,还是看方法proxyOrLoad里,如果找到了代理(也就是使用的load查找方式),进入如下分支:
PersistenceContext persistenceContext = event.getSession().getPersistenceContext();// load方式先从事件的上下文环境中查找(一级缓存session)
// 返回的对象赋值给proxy,名字都那么明显了,代理对象
Object proxy = persistenceContext.getProxy(keyToLoad);
// 如果是空的,就创建代理对象,不是空的,先判断是否允许创建代理(还记得之前的LOAD和GET常量么,就在这里起作用),load肯定允许,那么开始创建代理
return proxy != null?this.returnNarrowedProxy(event, persister, keyToLoad, options, persistenceContext, proxy):(options.isAllowProxyCreation()?this.createProxyIfNecessary(event, persister, keyToLoad, options, persistenceContext):this.load(event, persister, keyToLoad, options));
到这里肯定明确一点:load查找方式首先会去缓存里查找,那么load的代理对象在获取对象属性时究竟如何加载数据?
如果缓存中找不到对象,则进入该方法:
// 该内部的私有方法中第一个log就说了:实体代理类先从session中查找
private Object returnNarrowedProxy(LoadEvent event, EntityPersister persister, EntityKey keyToLoad, LoadType options, PersistenceContext persistenceContext, Object proxy) {
log.trace("entity proxy found in session cache");
// 执行的是懒加载
LazyInitializer li = ((HibernateProxy)proxy).getHibernateLazyInitializer();
if(li.isUnwrap()) {// 没有解包,就直接返回该代理对象
return li.getImplementation();
} else {
Object impl = null;
// load查找允许创建代理,那么这个if肯定不进入执行
if(!options.isAllowProxyCreation()) {
impl = this.load(event, persister, keyToLoad, options);
// 没有找到就返回异常信息
if(impl == null) {
event.getSession().getFactory().getEntityNotFoundDelegate().handleEntityNotFound(persister.getEntityName(), keyToLoad.getIdentifier());
}
} // 重写使用代理包装一下再返回
return persistenceContext.narrowProxy(proxy, persister, keyToLoad, impl);
}
}
也就是说,此时的load方式直接返回相应的对象,不会发送SQL语句查询数据库,也不管给定的id是否在数据库中存在数据对象。也就是此时此刻load不会直接访问数据库,只是简单地返回一个由底层封装的一个代理对象,永远不为null,null会抛出异常。当然了,当然了最后load也会查数据,只不过是在实际使用数据时才去查询二级缓存,二级缓存找不到,最后去数据库查找,否则抛出异常。
以上源码,来自hibernate 3。如果其他版本情况大同小异,大不了变化了就分析源码,看官方文档……再也不随便相信网上的一些不负责任转载的文章了。
Get()和Load()的区别小结
- get()方法默认不支持lazy(延迟加载)功能,而load支持延迟加载get方法,get方法首先查询session缓存,也就是一级缓存,没有找到查二级缓存,如果没二级缓存或者找不到,则查询数据库,而load方法创建时首先查询session缓存,没有就创建代理对象并返回,实际使用数据时才查询二级缓存,没有就查询数据库。
- 如果找不到符合条件的记录,get方法返回null,而load方法抛出异常(ObjectNotFoundException),load拥有不为null。
- 使用load方法,一般都假定你要取得对象肯定是存在的,才能使用,否则报错,而get方法则尝试查找,如果不存在,就返回null。
- get()和load()只根据主键查询,不能根据其它字段查询,如果想根据非主键查询,可以使用HQL或者原生SQL。
- 使用load()时如果在session关闭之后再查询此对象,会报异常:could not initialize proxy - no Session。处理办法:在session关闭之前初始化一下查询出来的对象:Hibernate.initialize(对象);
- 虽然好多书中都这么说:“get()永远只返回实体类”,但实际上这是不正确的,get方法如果在session缓存中找到了该id对应的对象,如果刚好该对象前面是被代理过的,如被load方法使用过,或者被其他关联对象延迟加载过,那么返回的还是原先的代理对象,而不是实体类对象,如果该代理对象还没有加载实体数据(就是id以外的其他属性数据),那么它会查询二级缓存或者数据库来加载数据,但是返回的还是代理对象,只不过已经加载了实体数据。
- 前面已经从源码角度讲了,get方法首先查询session缓存,没有的话查询二级缓存,最后查询数据库;load方法创建时首先查询session缓存,没有就创建代理,实际使用数据时才查询二级缓存和数据库。
这里比较细致了,继续看删除和修改:
- update,总结两点:
- 瞬时态不能执行update()。
- 持久态和游离态可以执行update()。
- 注意:代理对象在session关闭之后,不能执行update()。
第一个瞬时态对象,也就是数据库没有该对象保存,那么肯定更新不了啦!很好理解。看代码:

try {
Student student = new Student();
// 创建瞬时态对象student
student.setSid(9);
student.setSname("隔壁老王");
// 更新瞬时态对象
session.update(student);
transaction.commit();
} catch (Exception e) {
LOG.error("save error", e);
transaction.rollback();
}
报错:org.hibernate.StaleStateException: Batch update returned unexpected row count from update [0]
第二个持久态肯定能执行更新,毋庸置疑,先从数据库中把对象读取,变为持久态,在更新就ok。而游离态是存在于数据库,但是脱离session管理的对象,也是可以更新的。道理都一样。比如:
@Test
public void updateObj() {
Transaction transaction = session.beginTransaction(); try {
Student student = (Student) session.get(Student.class, 1);
transaction.commit(); // 读取一个持久对象,什么都不做,提交事务,session自动关闭(使用的线程封闭的session)
// 此时student变为游离态
// 重新开启session和事务
session = sessionFactory.getCurrentSession();
Transaction transaction1 = session.beginTransaction();
session.update(student); // ok
transaction1.commit();// ok
} catch (Exception e) {
LOG.error("save error", e);
transaction.rollback();
}
}
发送了SQL:
update
students
set
sname=?
where
sid=?
Process finished with exit code 0
- SaveOrUpdate():当对象从瞬时态转换为持久态时,如果不确定主键是否冲突,推荐使用SaveOrUpdate()。很简单,顾名思义,设置的主键在数据库存在,自动执行的是更新方法update,如果主键不存在,那么执行的是save方法保存这个对象,把对象从瞬时态变为持久态。站在用户角度,用户事先不知道该主键在数据库存在否,使用这个保险。当然了,主键生成策略不能是native,因为它会自增,根本不会冲突。使用assigned就可以。
- delete:持久态或者游离态对象都可以执行delete()方法。不过瞬时态对象也可以执行delete(),但Hibernate并不推荐使用delete()删除瞬时状态对象,因为这样做没有任何意义。
- merge方法:如果数据库中有该记录,则更新该记录,如果不存在该记录,则进行insert。乍一看很像saveOrUpdate方法,但是有区别,因为执行完merge(obj)后,它返回一个持久化对象的引用,而实参obj本身还是游离的。
merge和saveOrUpdate方法区别
使用saveOrUpdate,如果数据库中有记录,会无条件执行update,如果数据库中无记录,则执行insert操作。merge方法是把我们提供的对象变为游离状态的对象,只不过merger重新返回一个新的持久化对象的引用。而saveOrUpdate则把我们提供的对象转变为一个持久化对象。
也就是说saveOrUpdate后的对象会纳入session的管理,对象的状态会跟数据库同步,再次查询该对象会直接从session缓存中取,merge后的对象不会纳入session的管理,再次查询该对象还是会从数据库中取。
Students s1 = new Students(); s1.setSid(4);// 假设id=4的对象存在数据库 s1.setSname(“masi”);//s1是托管态的 Students s2 =(Students)session.merge(s1);
但是merge(s1)之后,返回的s2(引用)这个对象纳入了session管理,和数据库同步,变为持久化态,而s1还是托管态的,没有session管理它。
欢迎关注
dashuai的博客是终身学习践行者,大厂程序员,且专注于工作经验、学习笔记的分享和日常吐槽,包括但不限于互联网行业,附带分享一些PDF电子书,资料,帮忙内推,欢迎拍砖!

Hibernate(4)——主键生成策略、CRUD 基础API区别的总结 和 注解的使用的更多相关文章
- 大家一起撸代码之——Hibernate各种主键生成策略与配置详解
1.assigned 主键由外部程序负责生成,在 save() 之前必须指定一个.Hibernate不负责维护主键生成.与Hibernate和底层数据库都无关,可以跨数据库.在存储对象前,必须要使用主 ...
- Hibernate中主键生成策略
主键生成策略 increment identity sequence native uuid assigned 1) increment 由hibernate完成 主键递增, 原理:select ma ...
- Hibernate各种主键生成策略与配置详解
出自:http://www.cnblogs.com/kakafra/archive/2012/09/16/2687569.html 1.assigned 主键由外部程序负责生成,在 save() 之前 ...
- Hibernate各种主键生成策略与配置详解《转》
1.assigned 主键由外部程序负责生成,在 save() 之前必须指定一个.Hibernate不负责维护主键生成.与Hibernate和底层数据库都无关,可以跨数据库.在存储对象前,必须要使用主 ...
- hibernate的主键生成策略
一共是13种,其中包括native native: 对于 oracle 采用 Sequence 方式,对于MySQL 和 SQL Server 采用identity(自增主键生成机制),native就 ...
- Hibernate各种主键生成策略与配置详解【附1--<generator class="foreign">】
1.assigned 主键由外部程序负责生成,在 save() 之前必须指定一个.Hibernate不负责维护主键生成.与Hibernate和底层数据库都无关,可以跨数据库.在存储对象前,必须要使用主 ...
- 【转】Hibernate各种主键生成策略与配置详解
原文转自:Fra~~kaka's Blog 1.assigned 主键由外部程序负责生成,在 save() 之前必须指定一个.Hibernate不负责维护主键生成.与Hibernate和底层数据库都无 ...
- hibernate 各种主键生成策略(转)
http://www.cnblogs.com/kakafra/archive/2012/09/16/2687569.html 1.assigned 主键由外部程序负责生成,在 save() 之前必须指 ...
- Hibernate 之主键生成策略小总结
主键生成策略大致分两种: 手工控制策略 自动生成策略[框架自动生成和数据库自动生成] 手工控制策略: assigned:类型是任意的,需要在 save() 到数据库前,编码人员手工设置主键值,也就是调 ...
随机推荐
- C# 文章导航
1. C#相关文章 1.1 C# 基础(一) 访问修饰符.ref与out.标志枚举等等 1.2 C# 基础(二) 类与接口 1.3 C# DateTime日期格式化 1.4 C# DateTime与时 ...
- 《Django By Example》第五章 中文 翻译 (个人学习,渣翻)
书籍出处:https://www.packtpub.com/web-development/django-example 原作者:Antonio Melé (译者@ucag注:大家好,我是新来的翻译, ...
- Chrome出了个小bug:论如何在Chrome下劫持原生只读对象
Chrome出了个小bug:论如何在Chrome下劫持原生只读对象 概述 众所周知,虽然JavaScript是个很灵活的语言,浏览器里很多原生的方法都可以随意覆盖或者重写,比如alert.但是为了保证 ...
- CSS3 3D立方体效果-transform也不过如此
CSS3系列已经学习了一段时间了,第一篇文章写了一些css3的奇技淫巧,原文戳这里,还获得了较多网友的支持,在此谢过各位,你们的支持是我写文章最大的动力^_^. 那么这一篇文章呢,主要是通过一个3D立 ...
- jQuery学习之路(5)- 简单的表单应用
▓▓▓▓▓▓ 大致介绍 接下来的这几个博客是对前面所学知识的一个简单的应用,来加深理解 ▓▓▓▓▓▓ 单行文本框 只介绍一个简单的样式:获取和失去焦点改变样式 基本结构: <form actio ...
- Xamarin与Visual stuido2015离线安装包分享
最近看见大伙留言才知道国内安装Xamarin开发原来这么艰辛啊! 第一:网速不快 第二:Android SDK下载受限 等等... 鉴于这些原因,特写下这篇文章以及分享打包好的离线包以帮助大家尽快体验 ...
- 【架构设计】分布式文件系统 FastDFS的原理和安装使用
本文地址 分享提纲: 1.概述 2. 原理 3. 安装 4. 使用 5. 参考文档 1. 概述 1.1)[常见文件系统] Google了一下,流行的开源分布式文件系统有很多,介绍如下: -- mo ...
- JavaScript中String对象的方法介绍
1.字符方法 1.1 charAt() 方法,返回字符串中指定位置的字符. var question = "Do you like JavaScript?"; alert(ques ...
- 手机web如何实现多平台分享
话说App一般都带有分享到社交平台的入口,web网页的分享也有很不错的框架,但是随着HTML5的不断发展,手机web页面越来越多的进入到我们的生活中,那如何在我们的手机上完成分享呢?话说各大分享平台都 ...
- iOS -- CocoaPods
CocoaPods 是什么? CocoaPods 是一个负责管理 iOS 项目中第三方开源库的工具.CocoaPods 的项目源码在 GitHub( https://github.com/CocoaP ...