阿里面试官让我讲讲Unicode,我讲了3秒说没了,面试官说你可真菜
本文首发于微信公众号:程序员乔戈里




乔哥:首先说说什么是Unicode、码点吧~要想搞懂,这些概念必须清楚
什么是Unicode?
下图来自http://www.unicode.org/standard/WhatIsUnicode.html中的截图

Unicode编码定义了这个世界上几乎所有字符(就是你眼睛看的字符比如ABC,汉字等)的数字表示,而且Unicode还兼容了很多老版本的编码规范,例如你熟悉的 ASCII码。
什么是码点?
我们国家的每一个人都对应唯一的一个身份证号,而Unicode也为了每个字符发了一张身份证,这张“身份证”上有一串唯一的数字ID确定了这个字符。
这串数字在整个计算机的世界具有唯一性,Unicode给这串数字ID起了个名字叫[码点]。
码点是如何表示的呢?
先来说一声码点是如何表示的:
U+XXXXXX 是码点的表示形式,X 代表一个十六制数字,可以有 4-6 位,不足 4 位前补 0 补足 4 位,超过则按是几位就是几位。


字符A的ASCII码是众所周知是65吧,将65转换成16进制就是41(16×4+(16^0)×1 = 65),按照规则前面补0,那么字符A的码点表示就是U+0041,依次类推B的码点表示就是U+0042...等等,汉字"你"的字符表示是“U+4F60”...


这个网址就是神器~
http://www.fileformat.info/info/unicode/char/search.htm?q=%E4%BD%A0&preview=entity
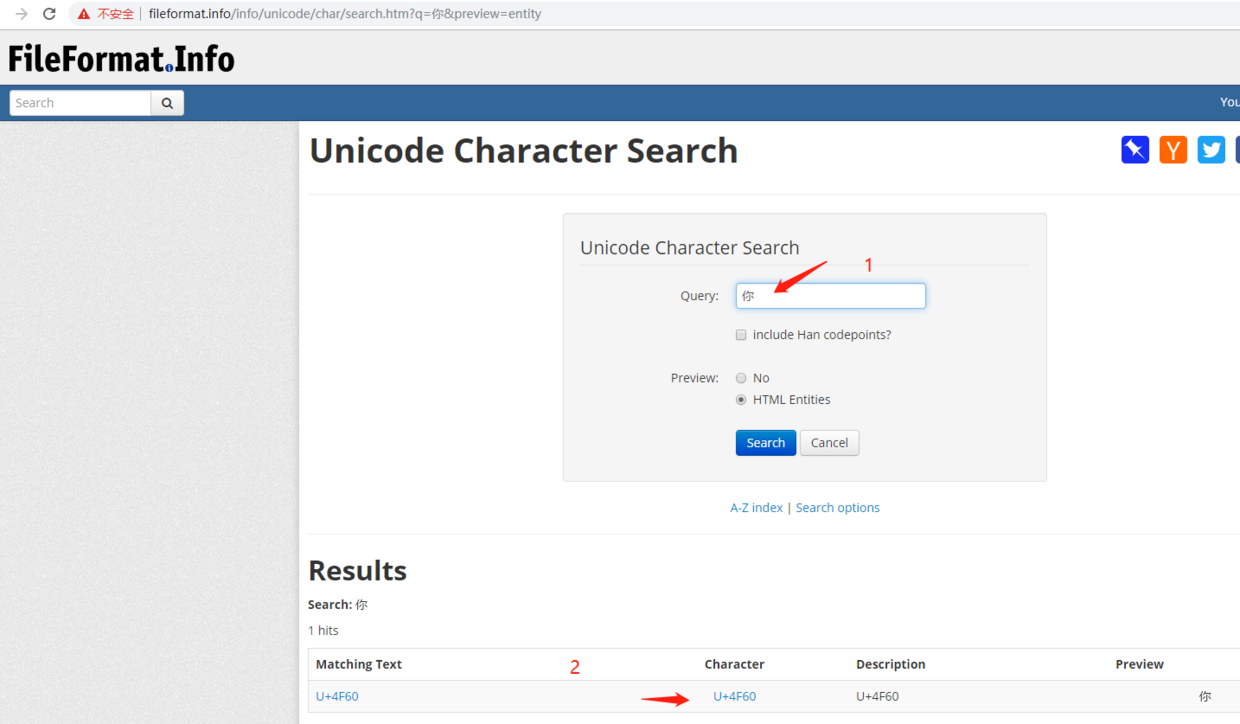
在输入框1中进行搜索,在出来的结果2中就是这个字符的unicode码点表示,不仅如此,结果2还可以继续进行点击查看更多详情!
我点一下结果2给你看看:
对于网址:
http://www.fileformat.info/info/unicode/char/4f60/index.htm
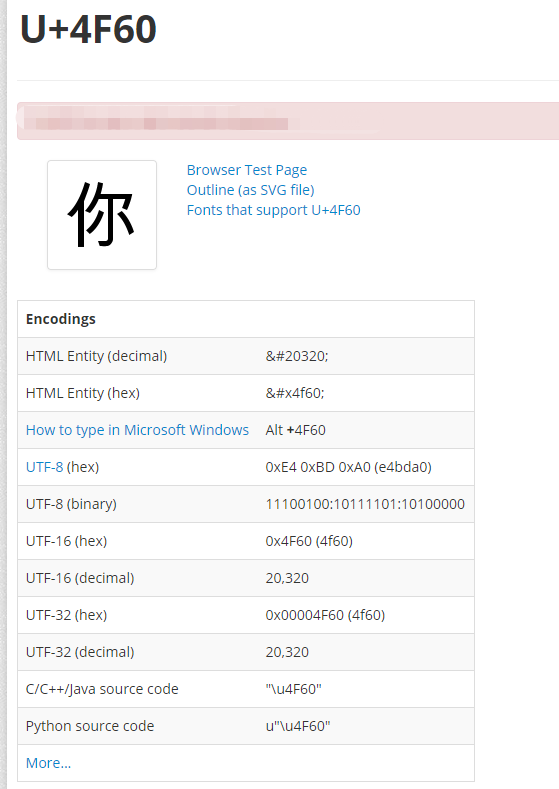
可以看到很详细的 字符 详情。



乔哥:比如我把这个网址中的unicode码点替换为dc00,看看它会出现什么
http://www.fileformat.info/info/unicode/char/dc00/index.htm

你看这个它就没有任何的码点表示,而是提示这个“Non Private Use High Surrogate, First”,Surrogate翻译过来是代理的意思,这个码点对应的是代理区了,这个就涉及到unicode的三种编码方式了(换句话就是码点如何转换为utf-8或者utf-16或者utf-32),utf-16中用到了代理区这个概念。


码点的取值范围
码点的取值范围目前是 U+0000 ~ U+10FFFF,理论大小为 10FFFF+1=110000(为啥+1,因为从0开始嘛~)。
16机制嘛~后一个 1代表是 65536(16的4次方),因为是 16 进制,所以前一个 1 是后一个 1 的 16 倍,所以总共有1×16+1=17 个的 65536 的大小,粗略估算为 17×6万=102 万,所以这是一个百万级别的数。
为了更好分类管理如此庞大的码点数,把每 65536 个码点作为一个平面,总共 17 个平面。
而我们说的代理区就在平面里面,而平面又有很多讲究。为了帮你搞懂代理区,先来聊一聊这平面的事
平面,BMP,SP
什么是平面?
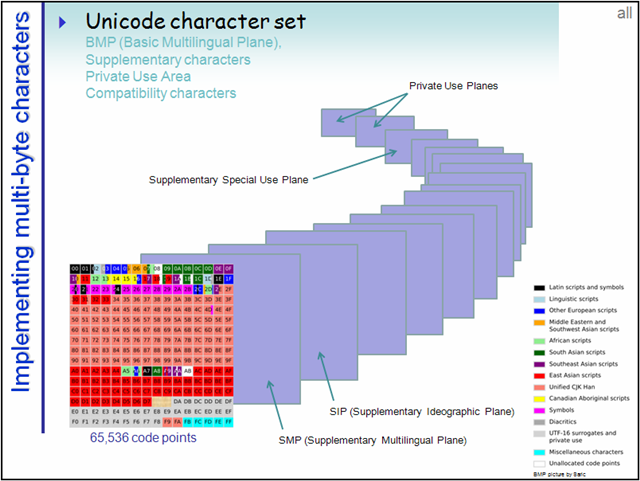
由前面可知,码点的全部范围可以均分成 17 个 65536 大小的部分,这里面的每一个部分就是一个平面(Plane)。编号从 0 开始,第一个平面称为 Plane 0。
下图来自http://rishida.net/docs/unicode-tutorial/part2
什么是 BMP?
第一个平面即是 BMP(Basic Multilingual Plane 基本多语言平面),也叫 Plane 0,它的码点范围是 U+0000 ~ U+FFFF。这也是我们最常用的平面,日常用到的字符绝大多数都落在这个平面内。
上图中第一个花花绿绿的平面就是 BMP。
UTF-16 只需要用两字节编码此平面内的字符。
最常用的 BMP,它的码点空间也有 6 万多,如果把这些字符都放到一张图片上,会是什么情况呢?GNU Unifont 就制作了一张这样的图片。见http://unifoundry.com/pub/unifont-7.0.03/unifont-7.0.03.bmp
{kind=link}
下图是它的一个缩略版本:

什么是增补平面?
后续的 16 个平面称为 SP(Supplementary Planes)。显然,这些码点已经是超过 U+FFFF 的了,所以已经超过了 16 位空间的理论上限,对于这些平面内的字符,UTF-16 采用了四字节编码。
代理区
你可能还注意到前面的 BMP 缩略图中有一片空白,这白花花一片亮瞎了我们的猿眼的是啥呢?这就是所谓的代理区(Surrogate Area)了。
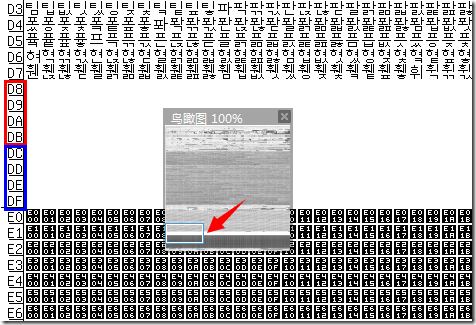
可以看到这段空白从 D8~DF。其中前面的红色部分 D800–DBFF 属于高代理区(High Surrogate Area),后面的蓝色部分 DC00–DFFF 属于低代理区(Low Surrogate Area),各自的大小均为 4×256=1024。


小萌:unicode码点替换为dc00的字符详情:“Non Private Use High Surrogate, First”,说明是高代理的意思,而 DC00 刚好就在 D800–DBFF这个高代理区里面,嘿嘿~


UTF-16如何用代理区编码?
UTF-16 是一种变长的 2 或 4 字节编码模式。对于 BMP 内的字符使用 2 字节编码,其它的则使用 4 字节组成所谓的代理对来编码。
在前面的鸟瞰图中,我们看到了一片空白的区域,这就是所谓的代理区(Surrogate Area)了,代理区是 UTF-16 为了编码增补平面中的字符而保留的,总共有 2048 个位置,均分为高代理区(D800–DBFF)和低代理区(DC00–DFFF)两部分,各1024,这两个区组成一个二维的表格,共有1024×1024=210×210=24×216=16×65536,所以它恰好可以表示增补的 16 个平面中的所有字符。
下面的图片来自 wiki
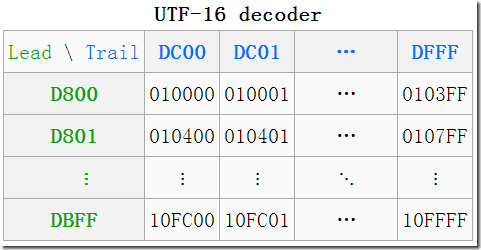
什么是代理对?
一个高代理区(即上图中的Lead(头),行)的加一个低代理区(即上图中的Trail(尾),列)的编码组成一对即是一个代理对(Surrogate Pair),必须是这种先高后低的顺序,如果出现两个高,两个低,或者先低后高,都是非法的。
在图中可以看到一些转换的例子,如
(D8 00 DC 00)—>U+10000,左上角,第一个增补字符
(DB FF DF FF)—>U+10FFFF,右下角,最后一个增补字符
那UTF-16为何要采用代理对?


最开始是采用定长二字节方案,但是无法满足容量增长,因为两个字节也就216 = 65536个而已,我们天朝的汉字就比这65536还多,那怎么办?扩呗~
于是转向定长四字节,但是转到4个字节虽然解决了容量的问题,又会引发了效率危机,比如一个字符A用一个字节就够存了,你非要用4个字节存,之前1G的·文件现在可能要4G去存,这不费钱吗~
那这咋办?于是各路大牛开天辟地,建立自己的编码方案,力图在效率和容量上取到一个平衡,其中一位大牛建立了UTF-16的编码方案!


看下面这个图,可以看到编码不是递增的,70-89的编码没有与之对应的字符。

这里挖出 70-89 间的码位,形成横竖 10×10 的编码空间,使得能再扩展 100 个编码空间。原来 2 位 100 个空间损失了 20,为啥这么说,因为70-89是20个,这部分不参与编码,那不就是少了20个吗
但是这20个编码通过形成 代理对 的方式又新增了100个代码空间,一来一回多了 80。这样一种变长方式也就是 UTF-16 所采用的。
小萌:哦,懂了~
小萌:UTF-16相当于牺牲了高代理区(D800–DBFF)和低代理区(DC00–DFFF)两部分空间,但是确新增了10241024=1665536的空间。依次来实现了扩容!


码点到 UTF-16 如何转换?
乔哥:继续上个例子。转换分成两部分:
1. BMP 中直接对应,无须做任何转换,也就是如果U<0x10000,U的UTF-16编码就是U对应的16位无符号整数;
2. 增补平面 SP 中,则需要做相应的计算。也就是如果U≥0x10000的情况
我们先计算U'=U-0x10000,然后将U'写成二进制形式:yyyy yyyy yyxx xxxx xxxx,U的UTF-16编码(二进制)就是:110110yyyyyyyyyy 110111xxxxxxxxxx。
Unicode编码0x20C30,减去0x10000后,得到0x10C30,写成二进制是:0001 0000 1100 0011 0000。用前10位依次替代模板中的y,用后10位依次替代模板中的x,就得到:1101100001000011 1101110000110000,转换为16进制即0xD843 0xDC30。
注意:以上计算方式仅用于说明转换原理,不代表实际采用的计算方式。


UTF-32
我们说码点最大的 10FFFF 也就 21 位,而 UTF-32 采用的定长四字节则是 32 位,所以它表示所有的码点不但毫无压力,反而绰绰有余,所以只要把码点的表示形式以前补 0 的形式补够 32 位即可。这种表示的最大缺点是占用空间太大。
再来看稍复杂一点的 UTF-8。
UTF-8
UTF-8的好处


小萌:按照数字递增进行编码,例如下图中,虽然简单,但起码也是一种编码,哈哈~。
| 编码方案1 | 字符 |
|---|---|
| 0 | h |
| 1 | e |
| 2 | l |
| 3 | a |
| 4 | v |
| 5 | z |
| 6 | y |
| 7 | i |
| ... | ... |

你的方案的想法很美好,它试图跟随编号来自然增长,它还是可以编码的,但在解码时则遇到了困难。
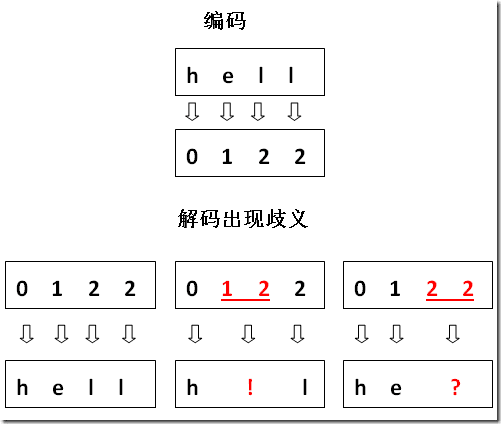
可见,由于低位的码位被“榨干”了,导致单个位与多位间无法区分,所以你的方案是行不通的。

下图中的编码方案2是我的改进方案。
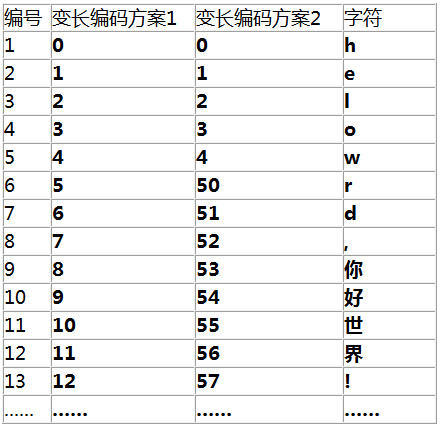
这是我的第二种编码方案,既然之前的无法区分,那我就把低位空间腾出来,5 及以上的就不使用了5,6,7...到49这些编码都不使用了,直接跳到50。然后引入一条变长解码规则:
从左向右扫描,读到 5 以下数字按单个位解码;读到 5 或以上数字时,把当前数字及下一个数字两位一起读上来解码。
看个实例

0和1是5以下的(5 以下数字按单个位解码),所以解码出来he,而当读取到了5(读到 5 或以上数字时,把当前数字及下一个数字两位一起读上来解码。),那么5和3连接起来就是53,查一下编码表53就是 “你”,这种方案避免了歧义。

乔哥:这还是非常粗糙的设计,如果我们想在这串字符中搜索“o”这个字符,它的编码是 3,
首先会找到3和53,这样在匹配时也会匹配上 53 中的 3,这种设计会让我们在实现匹配算法时不好实现啊。,



其实关键就在于用高位保留位来做区分,缺点就是有效编码空间少了
UTF-8 是变长的编码方案,可以有 1,2,3,4 四种字节组合。UTF-8 采用了高位保留方式来区别不同变长,如下:

可以看到,由于最高位不同,多字节中不会包含一字节的模式。对于 UTF-8 而言,二字节的模式也不会包含在三字节模式中,也不会在四字节中;三字节模式也不会在四字节模式中,这样就解决上面所说的搜索匹配难题。

可以看到,由于固定位上的 0 和 1 的差别,使得二字节既不会与三字节的前两字节相同,也不会它的后两字节相同。
这也每当进行搜索的时候,每个二字节和三字节的编码没有重叠,因为最高位不同呀~所以不会出现搜索同一个出现两个的结果。不过就是有效编码空间少了。


UTF-8如何与码点进行转换
| Unicode编码(十六进制) | UTF-8 字节流(二进制) |
|---|---|
| 000000-00007F | 0xxxxxxx |
| 000080-0007FF | 110xxxxx 10xxxxxx |
| 000800-00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 010000-10FFFF | 11110xxx10xxxxxx10xxxxxx10xxxxxx |
对于Unicode的编码首先确定它的范围,找到它是对应的几字节。
对于0x00-0x7F之间的字符,UTF-8编码与[ASCII编码]完全相同。
“汉”字的Unicode编码是0x6C49。0x6C49在0x0800-0xFFFF之间,使用3字节模板:1110xxxx 10xxxxxx 10xxxxxx。将0x6C49写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。





本文首发于微信公众号:程序员乔戈里
如果是头条用户,可以在我的头条号程序员乔戈里后台回复 资源获取价值59998元的编程和考研资料
觉得文章不错的欢迎关注我的WX公众号:程序员乔戈里
我是BAT大厂后台开发工程师,,专注分享技术干货/编程资源/求职面试/成长感悟等,关注送5000G编程资源和自己整理的一份帮助不少人拿下java的offer的面经附答案,免费下载CSDN资源。

阿里面试官让我讲讲Unicode,我讲了3秒说没了,面试官说你可真菜的更多相关文章
- 面试官让你讲讲acks参数对消息持久化的影响
(0)写在前面 面试大厂时,一旦简历上写了Kafka,几乎必然会被问到一个问题:说说acks参数对消息持久化的影响? 这个acks参数在kafka的使用中,是非常核心以及关键的一个参数,决定了很多东西 ...
- 面试官让你讲讲Linux内核的竞争与并发,你该如何回答?
@ 目录 内核中的并发和竞争简介 原子操作 原子操作简介 整型原子操作函数 位原子操作函数 原子操作例程 自旋锁 自旋锁简介 自旋锁操作函数 自旋锁例程 读写自旋锁 读写锁例程 顺序锁 顺序锁操作函数 ...
- 面试说熟练掌握各种MQ?那你先看看这道题,面试官必问!
写在前面 我们知道,目前市面上的MQ包括Kafka.RabbitMQ.ZeroMQ.RocketMQ等等. 那么他们之间究竟有什么本质区别,分别适用于什么场景呢? 上述抛出的问题,同样在不少公司的Ja ...
- 面试问烂的 MySQL 四种隔离级别,看完吊打面试官!
阅读本文大概需要 5.6 分钟. 来源:网络 什么是事务 事务是应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消.也就是事务具有原子性,一个事务中的一系列的操 ...
- 【大厂面试04期】讲讲一条MySQL更新语句是怎么执行的?
流程图 这是在网上找到的一张流程图,写的比较好,大家可以先看图,然后看详细阅读下面的各个步骤. 执行流程: 1.连接验证及解析 客户端与MySQL Server建立连接,发送语句给MySQL Serv ...
- 数据库面试技巧,通过JDBC展示自己专业性,摘自java web轻量级开发面试教程
这篇文章是我之前写的博文 数据库方面的面试技巧,如何从建表方面展示自己能力 和 面试技巧,如何通过索引说数据库优化能力,内容来自Java web轻量级开发面试教程是一个系列的,通过面试官的视角和大家分 ...
- 最近面试java后端开发的感受:如果就以平时项目经验来面试,通过估计很难——再论面试前的准备
在上周,我密集面试了若干位Java后端的候选人,工作经验在3到5年间.我的标准其实不复杂:第一能干活,第二Java基础要好,第三最好熟悉些分布式框架,我相信其它公司招初级开发时,应该也照着这个标准来面 ...
- 云计算之路-阿里云上:Web服务器遭遇奇怪的“黑色30秒”问题
今天下午访问高峰的时候,主站的Web服务器出现奇怪的问题,开始是2台8核8G的云服务器(ECS),后来又加了1台8核8G的云服务器,问题依旧. 而且3台服务器特地使用了不同的配置:1台是禁用了虚拟内存 ...
- 云计算之路-阿里云上:Wireshark抓包分析一个耗时20秒的请求
这篇博文分享的是我们针对一个耗时20秒的请求,用Wireshark进行抓包分析的过程. 请求的流程是这样的:客户端浏览器 -> SLB(负载均衡) -> ECS(云服务器) -> S ...
随机推荐
- AtCoder Grand Contest 019 B - Reverse and Compare【思维】
AtCoder Grand Contest 019 B - Reverse and Compare 题意:给定字符串,可以选定任意i.j且i<=j(当然i==j时没啥卵用),然后翻转i到j的字符 ...
- php 处理 大并发
小谈php处理 大并发 大流量 大存储 一.判断大型网站的标准: 1.pv(page views)网页的浏览量: 概念:一个网站所有的页面,在24小时内被访问的总的次数.千万级别,百万级别 2. uv ...
- TP-admin即基于ThinkPHP5拿来即用高性能后台管理系统
TP-Admin即基于ThinkPHP5的web后台管理系统(总结一套自己的后台管理系统,方便自己后续的项目开发.) 主要特性:自适应手机端.支持国际化.吸取其他CMF框架优点.多站点部署.日志记录. ...
- webkit浏览器下多行显示,有省略号效果
多行显示情况 display: -webkit-box; -webkit-line-clamp: 3; -webkit-box-orient: vertical; overflow: hidden; ...
- Fragment学习(二): 管理Fragment和Fragment通讯
一. 管理Fragment 首先,如果你想在Android3.0及以下版本使用Fragment,你必须引用android-support-v4.jar这个包 然后你写的activity不能再继承自Ac ...
- 零基础入门--中文命名实体识别(BiLSTM+CRF模型,含代码)
自己也是一个初学者,主要是总结一下最近的学习,大佬见笑. 中文分词说到命名实体抽取,先要了解一下基于字标注的中文分词.比如一句话 "我爱北京天安门”. 分词的结果可以是 “我/爱/北京/天安 ...
- tomcat access日志
每次看access log都会记不住pattern里的各个标识代表的什么意思,记录下,备忘! tomcat的access log是由实现了org.apache.catalina.AccessLog接口 ...
- tsung测试xmpp遇到no_free_userid
tsung里面可以配置xmpp的参数,设置一下 <option type="ts_jabber" name="userid_max" value=&quo ...
- 利用SpEL 表达式实现简单的动态分表查询
这里的动态分表查询并不是动态构造sql语句,而是利用SpEL操作同一结构的不同张表. 也可以参考Spring Data Jpa中的章节http://docs.spring.io/spring-data ...
- Roslyn 使用 Target 替换占位符方式生成 nuget 打包
本文告诉大家如何编写在编译过程修改打包文件 在项目文件的相同文件夹可以放一个 nuspec 用来告诉 VisualStudio 如何打包 现在尝试创建一个项目 NearjerbetearDeeyito ...