Spark学习笔记(四)—— Yarn模式
1、Yarn运行模式介绍
Yarn运行模式就是说Spark客户端直接连接Yarn,不需要额外构建Spark集群。如果Yarn是分布式部署的,那么Spark就跟随它形成了分布式部署的效果。有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点。
yarn-client:Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出
yarn-cluster:Driver程序运行在由RM(ResourceManager)启动的AP(APPMaster)适用于生产环境。
其实简单说来,就是用Spark替换掉了Hadoop中的MapReduce;或者理解成,用Yarn替换掉了Spark的资源调度器。都是一回事,取长补短的结果。
2、安装配置
1)修改hadoop配置文件yarn-site.xml,添加如下内容:
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
2)修改spark-env.sh,添加如下配置,指定Yarn的配置 :
[simon@hadoop102 conf]$ vi spark-env.sh
YARN_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop
3)分发配置文件
[simon@hadoop102 conf]$ xsync /opt/module/hadoop-2.7.2/etc/hadoop/yarn-site.xml
#spark-env.sh可分发可不分发,因为Yarn是集群模式,Spark运行在Yarn上
[simon@hadoop102 conf]$ xsync spark-env.sh
4)启动Hadoop集群:
[simon@hadoop102 hadoop-2.7.2]$ start-dfs.sh
#在ResourceManager上启动Yarn
[simon@hadoop103 module]$ start-yarn.sh
5)执行一个应用程序:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.11-2.1.1.jar \
100
我们比较一下,它和local模式有什么不一样的地方:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
./examples/jars/spark-examples_2.11-2.1.1.jar \
100
参数说明:
- --master 指定Master的地址,默认为Local
- --class: 你的应用的启动类 (如 org.apache.spark.examples.SparkPi)
- --deploy-mode: 是否发布你的驱动到worker节点(cluster) 或者作为一个本地客户端 (client) (default: client)*
- --conf: 任意的Spark配置属性, 格式key=value. 如果值包含空格,可以加引号“key=value”
- application-jar: 打包好的应用jar,包含依赖. 这个URL在集群中全局可见。 比如hdfs:// 共享存储系统, 如果是 file:// path, 那么所有的节点的path都包含同样的jar
- application-arguments: 传给main()方法的参数
- --executor-memory 1G 指定每个executor可用内存为1G
- --total-executor-cores 2 指定每个executor使用的cup核数为2个
不同的地方很明显:指定了master为Yarn模式,--deploy-mode,为client模式,缺省的代表是Local模式。
3、Yarn模式运行流程
画了一张图,感受一下:
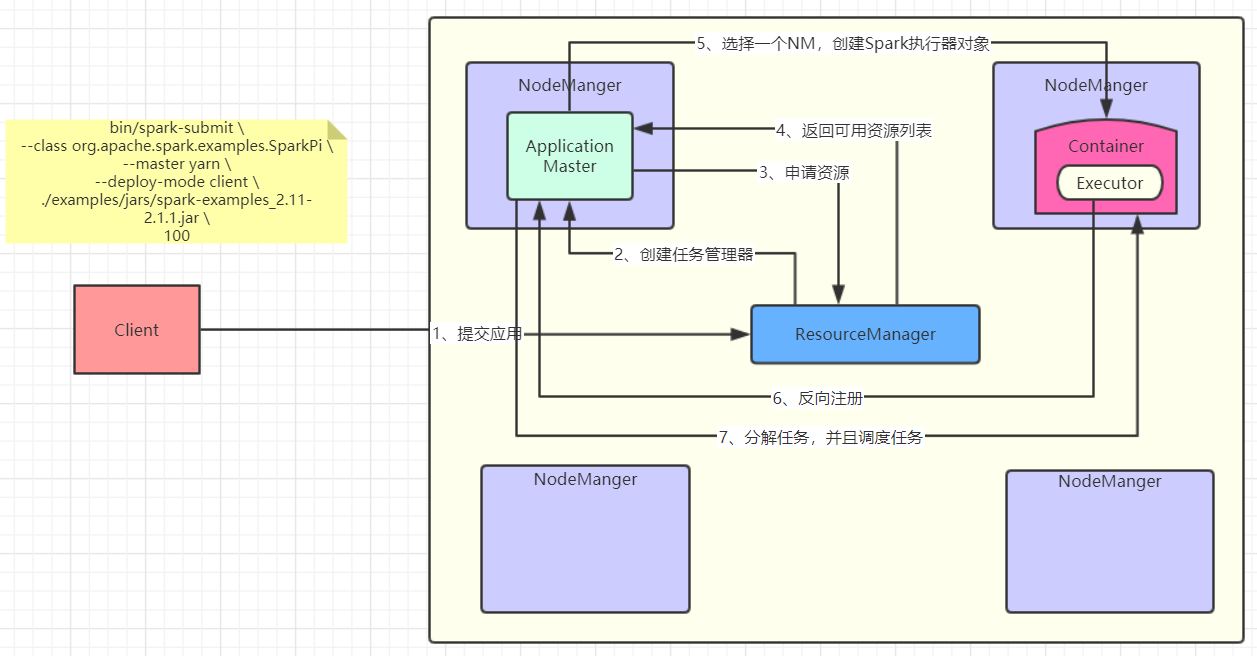
其实我感觉图画的已经挺清楚的了,再尝试用文字解释一下吧,以后看源码会对图的理解更加深刻:
1)客户端提交应用给Yarn的ResourceManager(RM);
2)RM选择一个NodeManager(NM)创建ApplicationMaster(AM);
3)AM向RM索要执行任务的资源;
4)RM返回给AM可用的资源列表(例如:NM1、NM2、NM3);
5)AM选择一个NM,创建Spark的执行器对象Executor;
6)那么AM怎么知道这个Executor创建了以及它的状态呢,这时候Executor反向注册到AM;
7)AM知道了Executor的状态,开始分解任务,交给它执行。
先有一个大致的印象,方便之后看源码去理解,这样整个代码的逻辑才更加清晰,反过来对整个流程也能理解的更加深刻。
4、日志查看
有时候我们需要对任务进行实时的监控,或者返回来看任务的执行流程,那么就需要查看日志了。由于我们现在使用的Yarn模式,那么就自然而然的想到,日志信息应该是在Yarn的web UI中查看。也就是:使得Yarn能够看到Spark的执行日志。
1)修改配置文件spark-defaults.conf
添加如下内容:
spark.yarn.historyServer.address=hadoop102:18080
spark.history.ui.port=18080
2)重启spark历史服务
[simon@hadoop102 spark]$ sbin/stop-history-server.sh
#输出
stopping org.apache.spark.deploy.history.HistoryServer
[simon@hadoop102 spark]$ sbin/start-history-server.sh
#输出
starting org.apache.spark.deploy.history.HistoryServer, logging to /opt/module/spark/logs/spark-simon-org.apache.spark.deploy.history.HistoryServer-1-hadoop102.out
3)提交任务到Yarn执行
[simon@hadoop102 spark]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.11-2.1.1.jar \
100
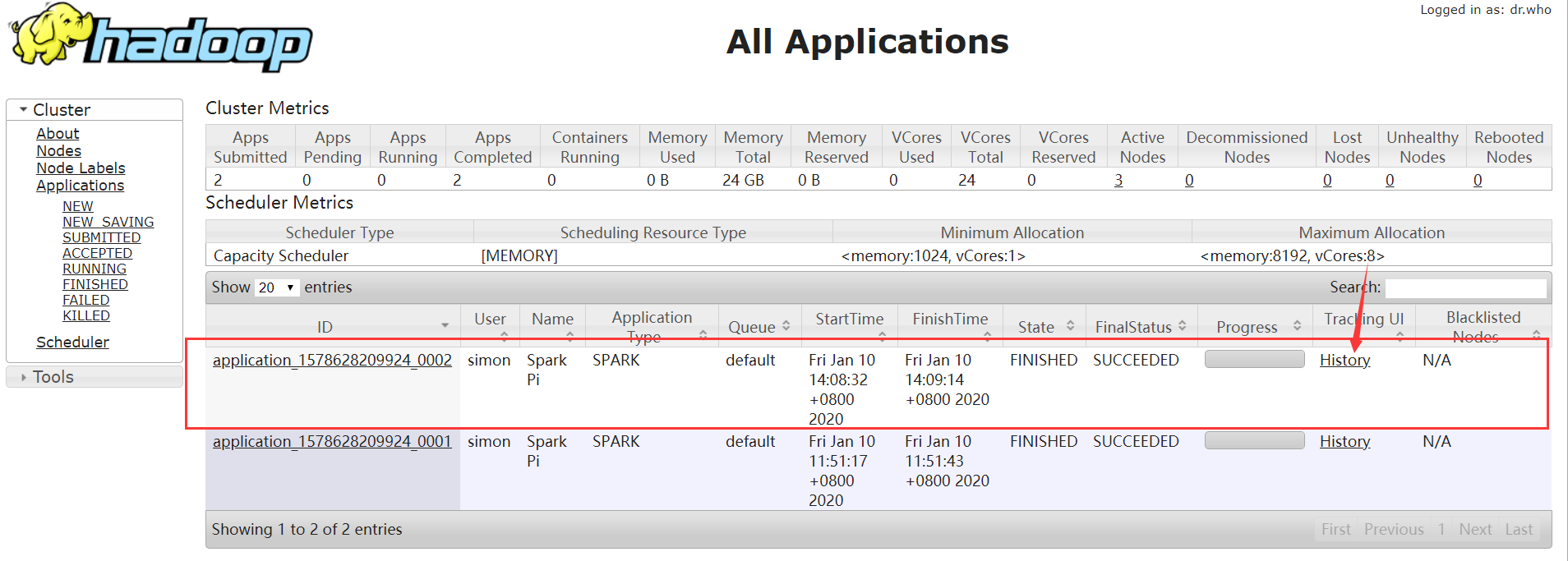
4)Web页面查看日志

Spark学习笔记(四)—— Yarn模式的更多相关文章
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- thinkphp学习笔记6—url模式
原文:thinkphp学习笔记6-url模式 入口文件是应用的唯一入口,因为可以多入口,每个应用可以对应一个入口文件,系统会从rul参数中解析当前请求的模块,控制器,操作.ThinkPHP是区分大小写 ...
- Typescript 学习笔记四:回忆ES5 中的类
中文网:https://www.tslang.cn/ 官网:http://www.typescriptlang.org/ 目录: Typescript 学习笔记一:介绍.安装.编译 Typescrip ...
- 零拷贝详解 Java NIO学习笔记四(零拷贝详解)
转 https://blog.csdn.net/u013096088/article/details/79122671 Java NIO学习笔记四(零拷贝详解) 2018年01月21日 20:20:5 ...
- Linux学习笔记(四) vi编辑器
一.vi 编辑器 vi 编辑器 (Visual Interface) 是所有 Unix 及 Linux 系统下标准的编辑器,相当于 Windows 系统中的记事本 它有三种模式,分别是: Comman ...
- Spark学习笔记0——简单了解和技术架构
目录 Spark学习笔记0--简单了解和技术架构 什么是Spark 技术架构和软件栈 Spark Core Spark SQL Spark Streaming MLlib GraphX 集群管理器 受 ...
- 官网实例详解-目录和实例简介-keras学习笔记四
官网实例详解-目录和实例简介-keras学习笔记四 2018-06-11 10:36:18 wyx100 阅读数 4193更多 分类专栏: 人工智能 python 深度学习 keras 版权声明: ...
- Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1--第一个Spark程序:单词数统计 笔记摘抄自 [美] Holden Karau 等著的<Spark快速大数据分析> 添加依赖 通过 Maven 添加 Spark-c ...
- C#可扩展编程之MEF学习笔记(四):见证奇迹的时刻
前面三篇讲了MEF的基础和基本到导入导出方法,下面就是见证MEF真正魅力所在的时刻.如果没有看过前面的文章,请到我的博客首页查看. 前面我们都是在一个项目中写了一个类来测试的,但实际开发中,我们往往要 ...
随机推荐
- 2018-11-19-Roslyn-NameSyntax-的-ToString-和-ToFullString-的区别
title author date CreateTime categories Roslyn NameSyntax 的 ToString 和 ToFullString 的区别 lindexi 2018 ...
- uni-app 生命周期函数
应用生命周期 函数名 说明 onLaunch 当uni-app 初始化完成时触发(全局只触发一次) onShow 当 uni-app 启动,或从后台进入前台显示 onHide 当 uni-app 从前 ...
- SpringBoot 上传文件到linux服务器 异常java.io.FileNotFoundException: /tmp/tomcat.50898……解决方案
SpringBoot 上传文件到linux服务器报错java.io.FileNotFoundException: /tmp/tomcat.50898-- 报错原因: 解决方法 java.io.IOEx ...
- Linux数据对齐
编写可移植代码而值得考虑的最后一个问题是如何存取不对齐的数据 -- 例如, 如何读取 一个存储于一个不是 4 字节倍数的地址的 4 字节值. i386 用户常常存取不对齐数据项, 但是不是所有的体系允 ...
- CentOS服务器安装mysql
1.配置YUM源 下载mysql源安装包 [root@localhost~]#wget http://dev.mysql.com/get/mysql57-community-release-el7-8 ...
- D3.js力导向图(适用于其他类型图)中后添加元素遮盖已有元素的问题解决
上一篇说了在D3.js中动态增加节点及连线的一种实现方式,但是有后添加元素遮盖原节点的现象,这一篇说一下出现这个现象的解决办法. 在D3.js中后添加的元素是会遮盖先添加的元素的,同时还有一个设定:后 ...
- SVG基础绘图实例
SVG可缩放矢量图(Scalable Vector Graphics),是使用 XML 来描述二维图形和绘图程序的语言,图像在放大或改变尺寸的情况下其图形质量不会有所损失,是万维网联盟的标准. 下面整 ...
- Linux 内核热插拔事件产生
一个热插拔事件是一个从内核到用户空间的通知, 在系统配置中有事情已经改变. 无论何 时一个 kobject 被创建或销毁就产生它们. 这样事件被产生, 例如, 当一个数字摄像头 使用一个 USB 线缆 ...
- Linux 内核引用计数的操作
一个 kobject 的其中一个关键函数是作为一个引用计数器, 给一个它被嵌入的对象. 只 要对这个对象的引用存在, 这个对象( 和支持它的代码) 必须继续存在. 来操作一个 kobject 的引用计 ...
- js 快速取整
我们要将23.8转化成整数 有哪些方法呢 比如 Math.floor( ) 对数进行向下取整 它返回的是小于或等于函数参数,并且与之最接近的整数 Math.floor(5.1) 返回值 //5 M ...