一次jvm调优过程
jvm调优实战
前端时间把公司的一个分布式定时调度的系统弄上了容器云,部署在kubernetes,在容器运行的动不动就出现问题,特别容易jvm溢出,导致程序不可用,终端无法进入,日志一直在刷错误,kubernetes也没有将该容器自动重启。业务方基本每天都在反馈task不稳定,后续就协助接手看了下,先主要讲下该程序的架构吧。
该程序task主要分为三个模块:
console进行一些cron的配置(表达式、任务名称、任务组等);
schedule主要从数据库中读取配置然后装载到quartz再然后进行命令下发;
client接收任务执行,然后向schedule返回运行的信息(成功、失败原因等)。
整体架构跟github上开源的xxl-job类似,也可以参考一下。
1. 启用jmx和远程debug模式
容器的网络使用了BGP,打通了公司的内网,所以可以直接通过ip来进行程序的调试,主要是在启动的jvm参数中添加:
JAVA_DEBUG_OPTS=" -Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket,address=0.0.0.0:8000,server=y,suspend=n "
JAVA_JMX_OPTS=" -Dcom.sun.management.jmxremote.port=1099 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false "
其中,调试模式的address最好加上0.0.0.0,有时候通过netstat查看端口的时候,该位置显示为127.0.0.1,导致无法正常debug,开启了jmx之后,可以初步观察堆内存的情况。
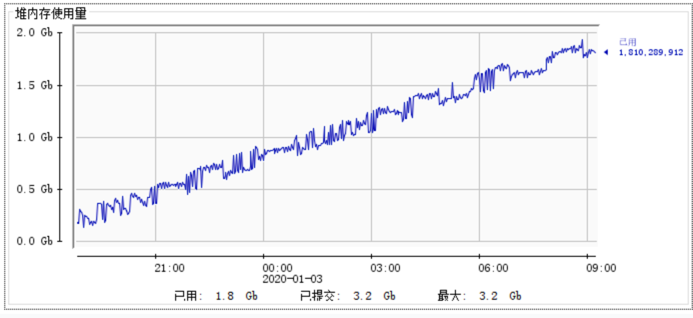
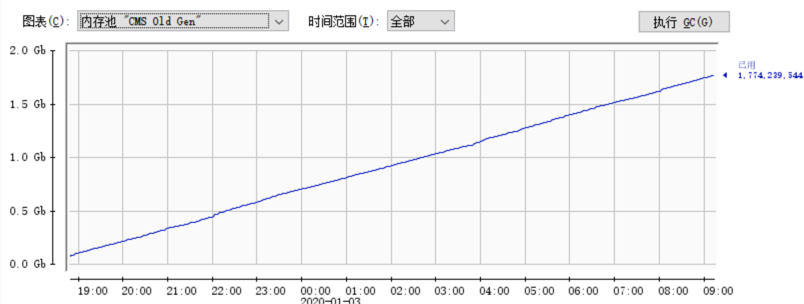
堆内存(特别是cms的old gen),初步看代码觉得是由于用了大量的map,本地缓存了大量数据,怀疑是每次定时调度的信息都进行了保存。
2. memory analyzer、jprofiler进行堆内存分析
先从容器中dump出堆内存
jmap -dump:live,format=b,file=heap.hprof 58

由图片可以看出,这些大对象不过也就10M,并没有想象中的那么大,所以并不是大对象的问题,后续继续看了下代码,虽然每次请求都会把信息放进map里,如果能正常调通的话,就会移除map中保存的记录,由于是测试环境,执行端很多时候都没有正常运行,甚至说业务方关闭了程序,导致调度一直出现问题,所以map的只会保留大量的错误请求。不过相对于该程序的堆内存来说,不是主要问题。
3. netty的方面的考虑
另一个小伙伴一直怀疑的是netty这一块有错误,着重看了下。该程序用netty自己实现了一套rpc,调度端每次进行命令下发的时候都会通过netty的rpc来进行通信,整个过程逻辑写的很混乱,下面开始排查。
首先是查看堆内存的中占比:
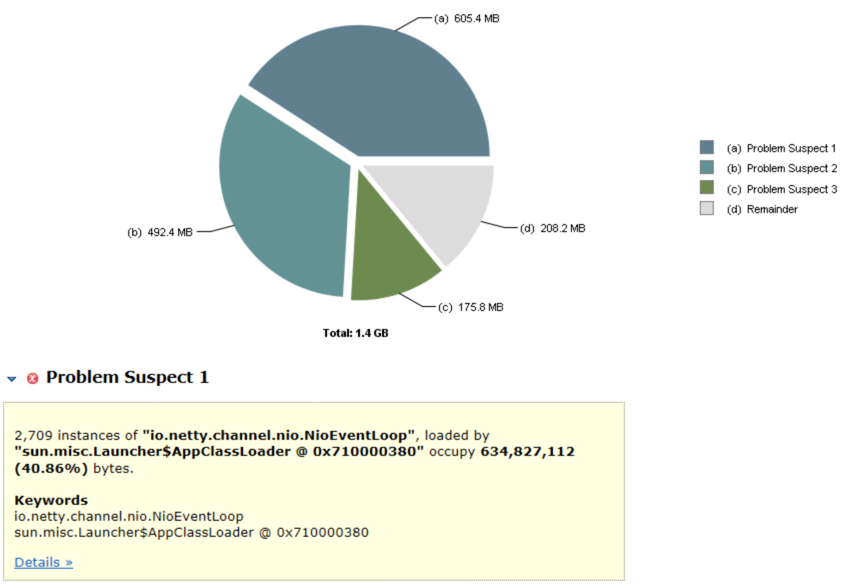
可以看出,io.netty.channel.nio.NioEventLoop的占比达到了40%左右,再然后是io.netty.buffer.PoolThreadCache,占比大概达到33%左右。猜想可能是传输的channel没有关闭,还是NioEventLoop没有关闭。再跑去看一下jmx的线程数:
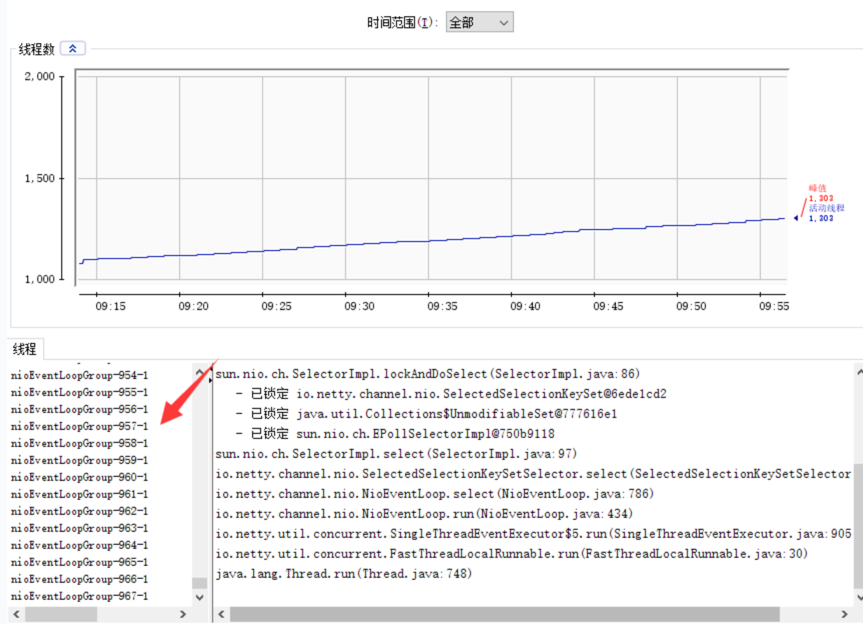
达到了惊人的1000个左右,而且一直在增长,没有过下降的趋势,再次猜想到可能是NioEventLoop没有关闭,在代码中全局搜索NioEventLoop,找到一处比较可疑的地方。
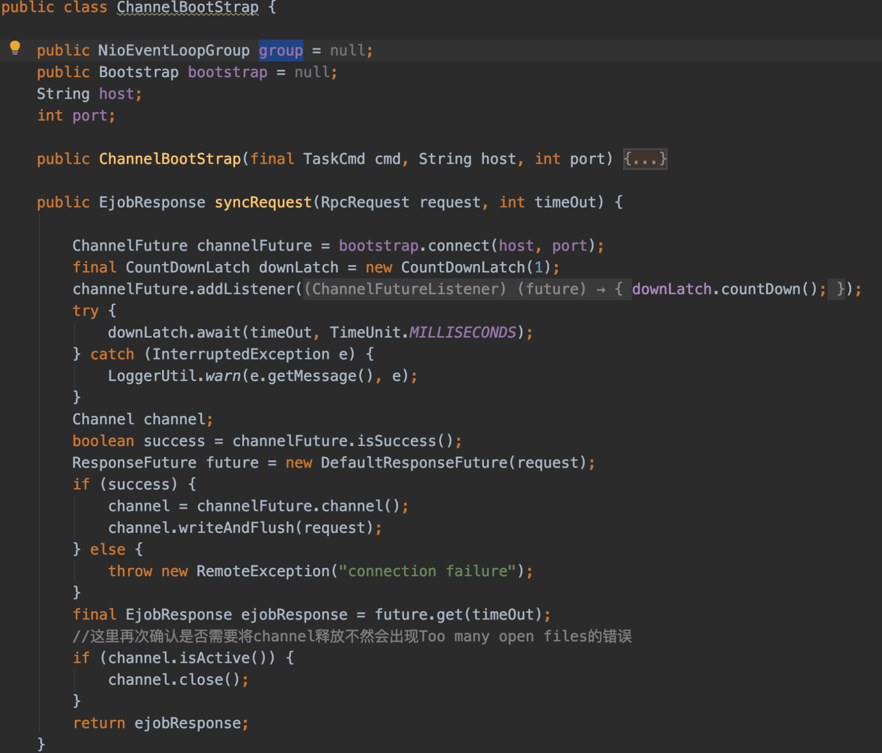
声明了一个NioEventLoopGroup的成员变量,通过构造方法进行了初始化,但是在执行syncRequest完之后并没有进行对group进行shutdownGracefully操作,外面对其的操作并没有对该类的group对象进行关闭,导致线程数一直在增长。
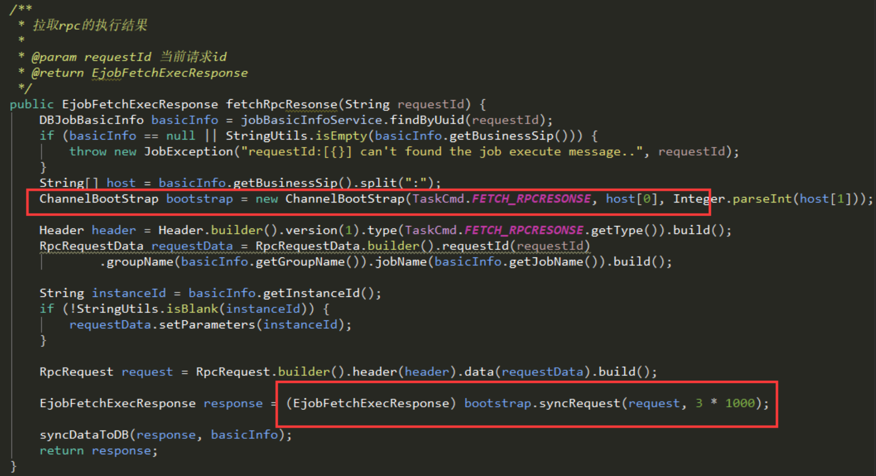
最终解决办法:
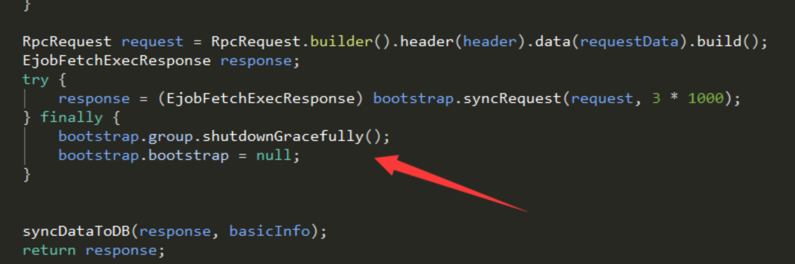
在调用完syncRequest方法时,对ChannelBootStrap的group对象进行行shutdownGracefully
提交代码,容器中继续测试,可以基本看出,线程基本处于稳定状态,并不会出现一直增长的情况了
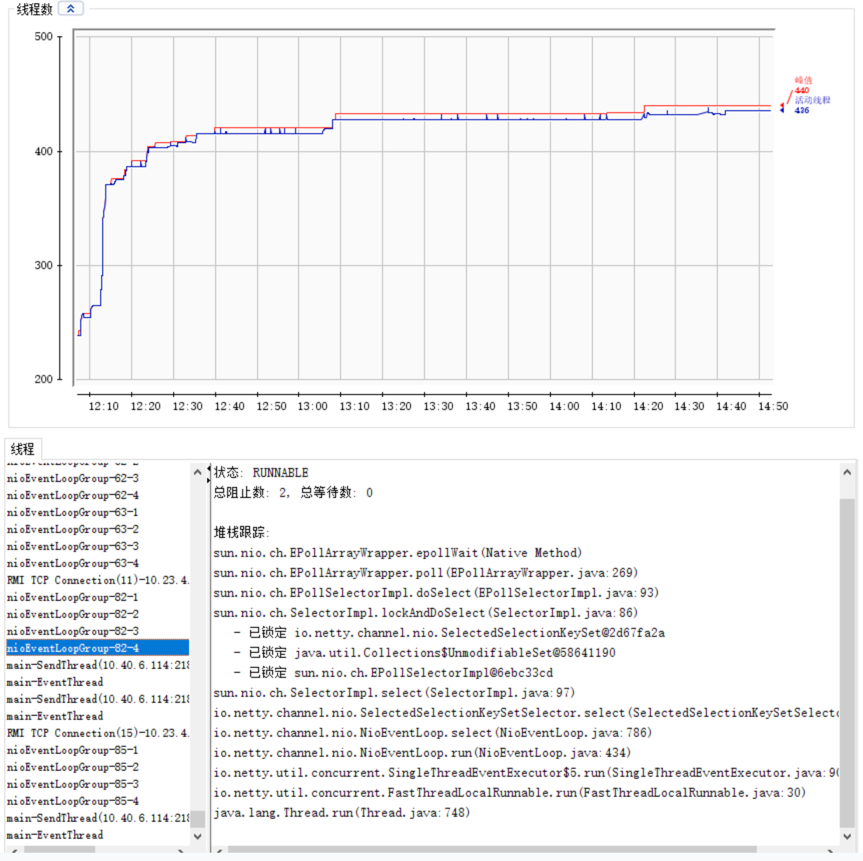
还原本以为基本解决了,到最后还是发现,堆内存还算稳定,但是,直接内存依旧打到了100%,虽然程序没有挂掉,所以,上面做的,可能仅仅是为这个程序续命了而已,感觉并没有彻底解决掉问题。
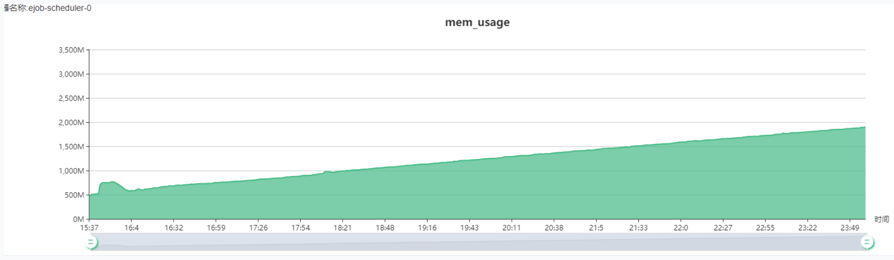
4. 直接内存排查
第一个想到的就是netty的直接内存,关掉,命令如下:
-Dio.netty.noPreferDirect=true -Dio.netty.leakDetectionLevel=advanced
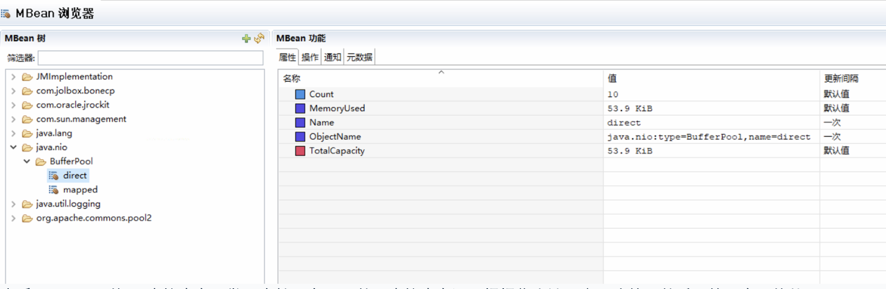
查看了一下java的nio直接内存,发现也就几十kb,然而直接内存还是慢慢往上涨。毫无头绪,然后开始了自己的从linux层面开始排查问题
5. 推荐的直接内存排查方法
5.1 pmap
一般配合pmap使用,从内核中读取内存块,然后使用views 内存块来判断错误,我简单试了下,乱码,都是二进制的东西,看不出所以然来。
pmap -d 58 | sort -n -k2
pmap -x 58 | sort -n -k3
grep rw-p /proc/$1/maps | sed -n 's/^\([0-9a-f]*\)-\([0-9a-f]*\) .*$/\1 \2/p' | while read start stop; do gdb --batch --pid $1 -ex "dump memory $1-$start-$stop.dump 0x$start 0x$stop"; done
这个时候真的懵了,不知道从何入手了,难道是linux操作系统方面的问题?
5.2 [gperftools](https://github.com/gperftools/gperftools)
起初,在网上看到有人说是因为linux自带的glibc版本太低了,导致的内存溢出,考虑一下。初步觉得也可能是因为这个问题,所以开始慢慢排查。oracle官方有一个jemalloc用来替换linux自带的,谷歌那边也有一个tcmalloc,据说性能比glibc、jemalloc都强,开始换一下。
根据网上说的,在容器里装libunwind,然后再装perf-tools,然后各种捣鼓,到最后发现,执行不了,
pprof --text /usr/bin/java java_58.0001.heap
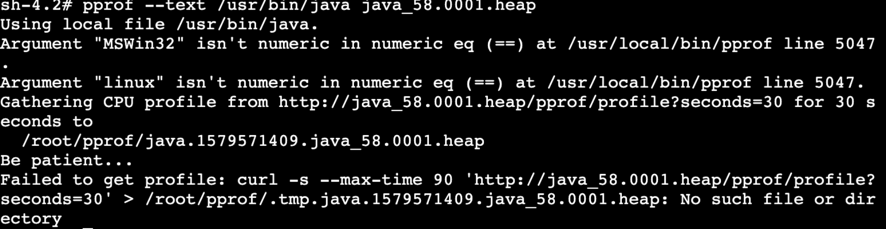
看着工具高大上的,似乎能找出linux的调用栈,
6. 意外的结果
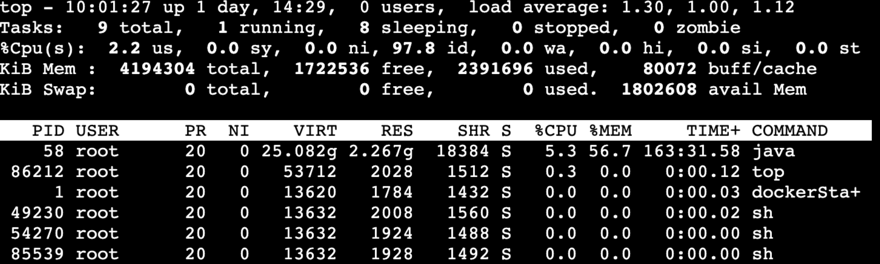
毫无头绪的时候,回想到了linux的top命令以及日志情况,测试环境是由于太多执行端业务方都没有维护,导致调度系统一直会出错,一出错就会导致大量刷错误日志,平均一天一个容器大概就有3G的日志,cron一旦到准点,就会有大量的任务要同时执行,而且容器中是做了对io的限制,磁盘也限制为10G,导致大量的日志都堆积在buff/cache里面,最终直接内存一直在涨,这个时候,系统不会挂,但是先会一直显示内存使用率达到100%。
修复后的结果如下图所示:

总结
定时调度这个系统当时并没有考虑到公司的系统会用的这么多,设计的时候也仅仅是为了实现上千的量,没想到到最后变成了一天的调度都有几百万次。最初那批开发也就使用了大量的本地缓存map来临时存储数据,然后面向简历编程各种用netty自己实现了通信的方式,一堆坑都留给了后人。目前也算是解决掉了一个由于线程过多导致系统不可用的情况而已,但是由于存在大量的map,系统还是得偶尔重启一下比较好。
参考:
1.记一次线上内存泄漏问题的排查过程
2.Java堆外内存增长问题排查Case
3.Troubleshooting Native Memory Leaks in Java Applications
一次jvm调优过程的更多相关文章
- jvm参数解析(含调优过程)
前阵 对底层账单系统进行了压测调优,调优的最后一步--jvm启动参数中,减小了线程的堆栈空间:-XX:ThreadStackSize=256K,缩减至原来的四分之一,效果明显,不过并没有调 ...
- jvm系列(四):jvm调优-命令大全(jps jstat jmap jhat jstack jinfo)
文章同步发布于github博客地址,阅读效果更佳,欢迎品尝 运用jvm自带的命令可以方便的在生产监控和打印堆栈的日志信息帮忙我们来定位问题!虽然jvm调优成熟的工具已经有很多:jconsole.大名鼎 ...
- jvm系列(六):jvm调优-从eclipse开始
jvm调优-从eclipse开始 概述 什么是jvm调优呢?jvm调优就是根据gc日志分析jvm内存分配.回收的情况来调整各区域内存比例或者gc回收的策略:更深一层就是根据dump出来的内存结构和线程 ...
- JVM调优-Java垃圾回收之分代回收
为什么要进行分代回收? JVM使用分代回收测试,是因为:不同的对象,生命周期是不一样的.因此不同生命周期的对象采用不同的收集方式. 可以提高垃圾回收的效率. Java程序运行过程中,会产生大量的对象, ...
- JVM调优浅谈
1.数据类型 java虚拟机中,数据类型可以分为两类:基本类型和引用类型.基本类型的变量保存原始值,即:它代表的值就是数值本身,而引用类型的变量保存引用值.“引用值”代表了某个对象的引用,而不是对象本 ...
- JVM调优总结 + jstat 分析(转)
[转] JVM调优总结 + jstat 分析 JVM调优总结 + jstat 分析 jstat -gccause pid 1 每格1毫秒输出结果jstat -gccause pid 2000 每格2秒 ...
- JVM调优总结(五)-分代垃圾回收详述1
为什么要分代 分代的垃圾回收策略,是基于这样一个事实:不同的对象的生命周期是不一样的.因此,不同生命周期的对象可以采取不同的收集方式,以便提高回收效率. 在Java程序运行的过程中,会产生大量的对象, ...
- JVM调优实战
JVM调优实战 文档修订记录 版本 日期 撰写人 审核人 批准人 变更摘要 & 修订位置 ...
- jvm系列(七):jvm调优-工具篇
16年的时候花了一些时间整理了一些关于jvm的介绍文章,到现在回顾起来还是一些还没有补充全面,其中就包括如何利用工具来监控调优前后的性能变化.工具做为图形化界面来展示更能直观的发现问题,另一方面一些耗 ...
随机推荐
- H3C 动态路由协议的基本原理
- H3C配置路由器作为TFTP客户端
- Linux 内核 低级 sysfs 操作
kobject 是在 sysfs 虚拟文件系统之后的机制. 对每个在 sysfs 中发现的目录, 有一个 kobject 潜伏在内核某处. 每个感兴趣的 kobject 也输出一个或多个属性, 它出现 ...
- rabbitmq template发送的消息中,Date类型字段比当前时间晚了8小时
前言 前一阵开发过程遇到的问题,用的rabbitmq template发送消息,消息body里的时间是比当前时间少了8小时的,这种一看就是时区问题了. 就说说为什么出现吧. 之前的配置是这样的: @B ...
- 服务端CURL请求
服务端与服务端之间,也存在接口编程. 比如我们网站服务端,需要发送短信.发送邮件.查询快递等,都需要调用第三方平台的接口. 1.php中发送请求 ①file_get_contents函数 :传递完整的 ...
- Java 工程师应该掌握的知识
以 Java 工程师应该掌握的知识为例,按重要程度排出六个梯度: 第一梯度:计算机组成原理.数据结构和算法.网络通信原理.操作系统原理. 第二梯度:Java 基础.JVM 内存模型和 GC 算法.JV ...
- select * from user 这条 SQL 语句,背后藏着哪些不可告人的秘密?
作为一名 Java开发人员,写 SQL 语句是常有的事,但是你知道 SQL 语句背后的处理逻辑吗?比如下面这条 SQL 语句: select * from user where id=1 执行完这条语 ...
- 构建锁与同步组件的基石AQS:深入AQS的实现原理与源码分析
Java并发包(JUC)中提供了很多并发工具,这其中,很多我们耳熟能详的并发工具,譬如ReentrangLock.Semaphore,它们的实现都用到了一个共同的基类--AbstractQueuedS ...
- 20191024-3 互评Alpha阶段作品——胜利点组
此作业要求参见 https://edu.cnblogs.com/campus/nenu/2019fall/homework/9860 基于NABCD评论作品,及改进建议 1.根据(不限于)NABCD评 ...
- 开源项目SMSS开发指南
SMSS是一个由我个人发起的开源项目,目的是建立一套轻量化,高可用,高安全和方便扩展的业务支撑框架.SMSS面向TCP/IP层开发,适合扩展上层业务接口.数据结构传输序列化通过Protobuf实现.传 ...