ansible自定义模块
参考官网:http://www.ansible.com.cn/docs/developing_modules.html#tutorial
阅读 ansible 附带的模块(上面链接)是学习如何编写模块的好方法。但是请记住,ansible 源代码树中的某些模块是内在的,因此请查看service或yum,不要太靠近async_wrapper 之类的东西,否则您会变成石头。没有人直接执行 async_wrapper。
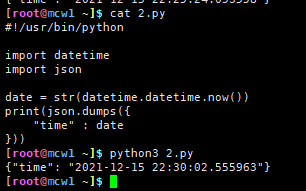
好的,让我们开始举例。我们将使用 Python。首先,将其保存为名为timetest.py的文件:


#!/usr/bin/python import datetime
import json date = str(datetime.datetime.now())
print(json.dumps({
"time" : date
}))
程序
自定义模块
创建模块目录
[root@mcw1 ~]$ mkdir /usr/share/my_modules #这个目录并不存在,ansible配置中存在这个注释掉的路径
编写模块返回内容
[root@mcw1 ~]$ vim uptime
#!/usr/bin/python import json
import os up = os.popen('uptime').read()
dic = {"result":up}
print json.dumps(dic)
执行结果:

启动模块目录
[root@mcw1 ~]$ grep library /etc/ansible/ansible.cfg #将配置中的这行内容注释,取消掉,不需要重启任何服务
library = /usr/share/my_modules/
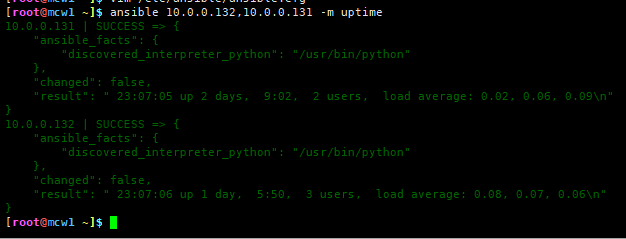
测试模块使用情况
这里显示它使用的解释器路径了,这个解释器是python2的解释器,如果我写的是python3的脚本,并且不支持python2执行,我可能需要修改ansible默认使用的python解释器。有点问题,我脚本里写的是python2的解释器,我写成python3应该就是python3了吧
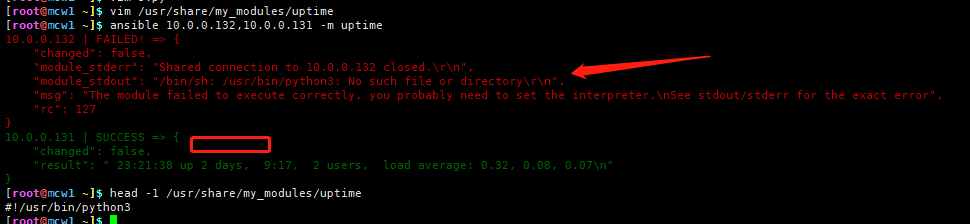
按照上面想法试了下,果然是的,我另一个主机是没有安装python3的,所以报错了。使用python3,貌似不会显示python的路径,跟之前python2有点区别
编写脚本:
程序如下:
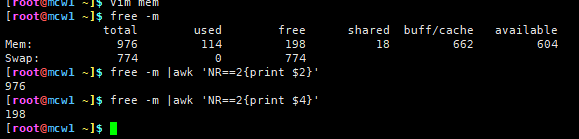
[root@mcw1 ~]$ cat /usr/share/my_modules/mem
#!/usr/bin/python3
import subprocess,json
cmd="free -m |awk 'NR==2{print $2}'"
p = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=True)
cmdres, err = p.communicate()
mcw=str(cmdres).lstrip("b'").rstrip("\\n'")
print(mcw) dic = {
"result":{
"mem_total": mcw
} ,
"err": str(err)
}
print(json.dumps(dic))
#print(dic)
上面程序中,python2和python3去掉\n换行符存在区别。python2:rstrip("\n"),python3:rstrip("\\n")
无论是否dumps,打印结果都是一行。当将字典dumps后,结果好看很多
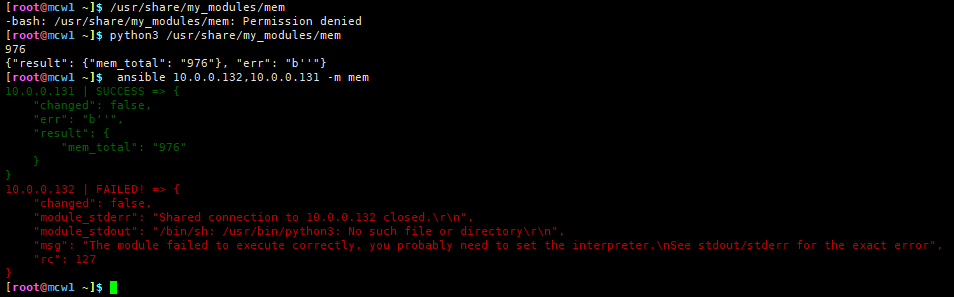
当不使用dumps时,都是报错,但是有标准输出的还是会一行打印出来
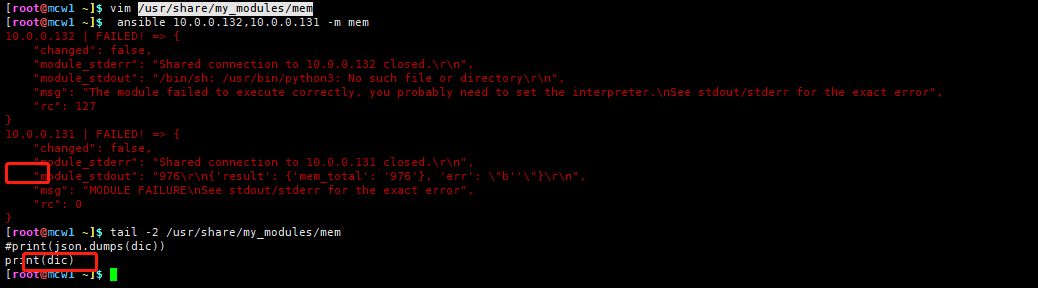
当我程序里将字典换成一行时,ansible输出内容还是有层次的显示出来。并且它把我们输出的字典所有键值对,相当于批量追加进ansible自己的输出字典中。同时它还会有自己的相关键值对,
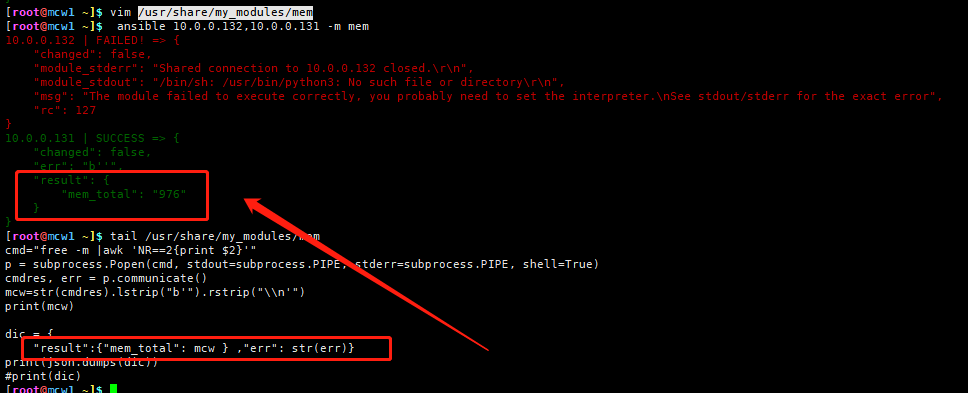
总结:我们可以写python(shell应该也可以)脚本,将需要的信息构建字典,打印出来。然后将脚本放到自定义模块目录下,无需添加执行权限,就可以使用ansible调用自定义模块,将输出结果显示在ansible的打印结果字典中
思考:上面总结打印的结果我怎么用?python中如何使用这个结果,ansible剧本中是否能使用这个模块,如何使用,这么用到它的打印结果?
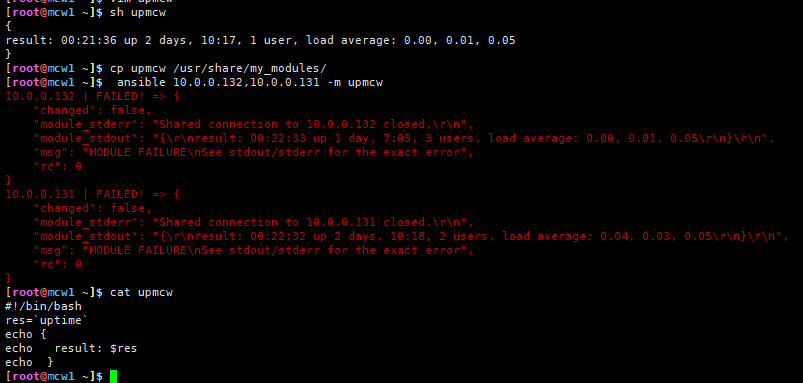
使用shell存在的问题
使用shell的方法还存在问题,有时间再看有办法解决这个问题
set_fact模块作用
设置变量,其它地方使用变量
- hosts: testB
remote_user: root
tasks:
- set_fact:
testvar: "testtest"
- debug:
msg: "{{testvar}}"
设置变量,其它地方使用变量
我们通过set_fact模块定义了一个名为testvar的变量,变量值为testtest,然后使用debug模块输出了这个变量:

设置变量接收其它变量的值,变量之间值的传递
如下:
- hosts: localhost
remote_user: root
vars:
testvar1: test1_string
tasks:
- shell: "echo test2_string"
register: shellreturn
- set_fact:
testsf1: "{{testvar1}}"
testsf2: "{{shellreturn.stdout}}"
- debug:
msg: "{{testsf1}} {{testsf2}}"
#var: shellreturn
剧本2
在剧本中定义变量testvar1,在剧本中可以引用这个变量。执行shell命令,将命令返回值注册为一个变量。set_fact模块设置两个变量,变量1让它等于前面设置的变量testvar1,变量2给它赋值shell命令的返回结果变量的标准输出。后面对这两个变量打印查看
剧本中想要查看信息,需要使用debug 模块(debug msg 打印)
set_fact:可以自定义变量,可以进行变量值的传递。可以用这个模块重新定义一个变量去接收其它变量的值,包括接收其它注册的变量值

上例中,我们先定义了一个变量testvar1,又使用register将shell模块的返回值注册到了变量shellreturn中,
之后,使用set_fact模块将testvar1变量的值赋予了变量testsf1,将shellreturn变量中的stdout信息赋值给了testsf2变量,(可以将注释去掉查看变量shellreturn的值)
最后,使用debug模块输出了testsf1与testsf2的值:
vars关键字变量,set_fact设置变量和注册变量。vars的只在当前play生效,另外两个可以跨play
如上述示例所示,set_fact模块可以让我们在tasks中创建变量,也可以将一个变量的值赋值给另一个变量。
其实,通过set_fact模块创建的变量还有一个特殊性,通过set_fact创建的变量就像主机上的facts信息一样,可以在之后的play中被引用。
默认情况下,每个play执行之前都会执行一个名为”[Gathering Facts]”的默认任务,这个任务会收集对应主机的相关信息,我们可以称这些信息为facts信息,我们已经总结过怎样通过变量引用这些facts信息,此处不再赘述,而通过set_fact模块创建的变量可以在之后play中被引用,就好像主机的facts信息可以在play中引用一样,这样说可能还是不是特别容易理解,不如来看一个小例子,如下
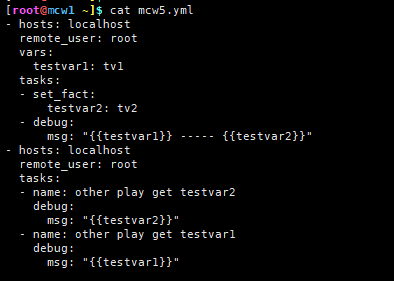
- hosts: localhost
remote_user: root
vars:
testvar1: tv1
tasks:
- set_fact:
testvar2: tv2
- debug:
msg: "{{testvar1}} ----- {{testvar2}}"
- hosts: localhost
remote_user: root
tasks:
- name: other play get testvar2
debug:
msg: "{{testvar2}}"
- name: other play get testvar1
debug:
msg: "{{testvar1}}"
剧本
变量1是vars关键字设置变量,在当前play生效,不能跨越play使用变量,但是变量2却可以跨越play使用变量,变量2是set_facts模块设置变量
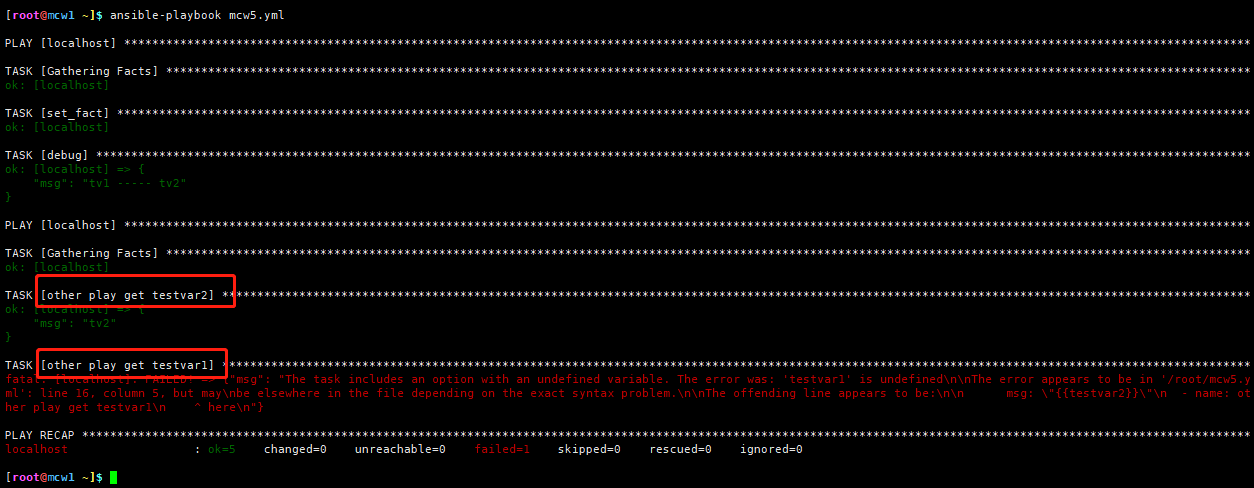
可以发现,这两个变量在第一个play中都可以正常的输出。但是在第二个play中,testvar2可以被正常输出了,testvar1却不能被正常输出,会出现未定义testvar1的错误,因为在第一个play中针对testB主机进行操作时,testvar1是通过vars关键字创建的,而testvar2是通过set_fact创建的,所以testvar2就好像testB的facts信息一样,可以在第二个play中引用到,而创建testvar1变量的方式则不能达到这种效果,虽然testvar2就像facts信息一样能被之后的play引用,但是在facts信息中并不能找到testvar2,只是”效果上”与facts信息相同罢了。
通过注册变量实现跨play调用变量
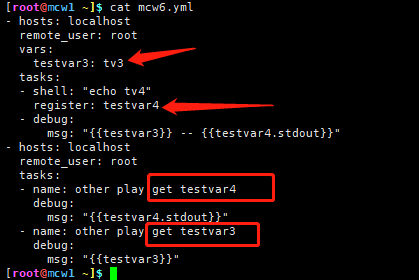
- hosts: localhost
remote_user: root
vars:
testvar3: tv3
tasks:
- shell: "echo tv4"
register: testvar4
- debug:
msg: "{{testvar3}} -- {{testvar4.stdout}}"
- hosts: localhost
remote_user: root
tasks:
- name: other play get testvar4
debug:
msg: "{{testvar4.stdout}}"
- name: other play get testvar3
debug:
msg: "{{testvar3}}"
剧本
3是vars定义变量,4是注册变量,4是可以跨play的,3却不行 。是需要4还是3看情况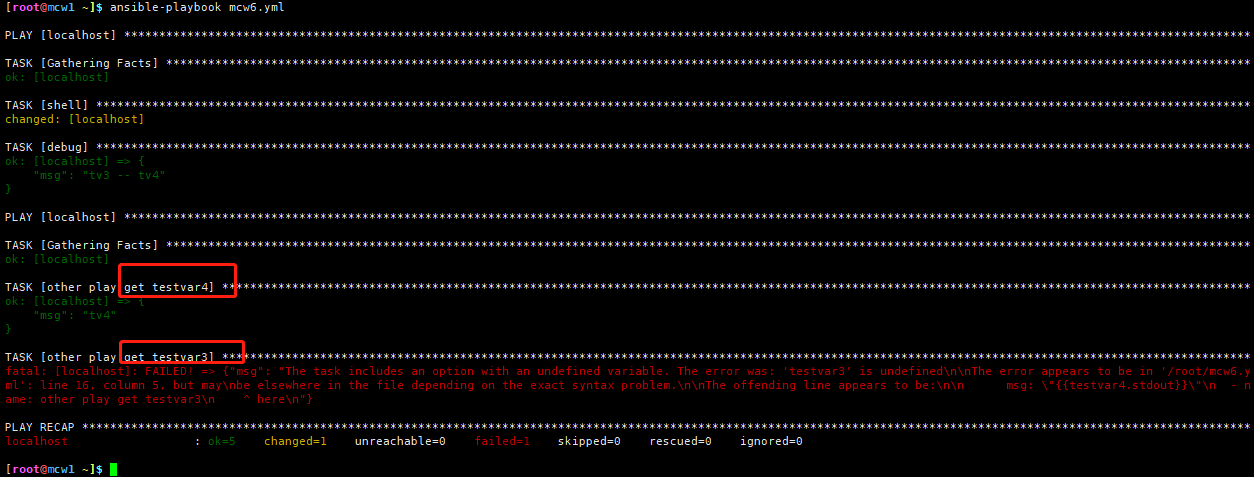
在第二个play中获取”testvar3″时会报错,而在第二个play中获取注册变量”testvar4″时则正常,但是,注册变量中的信息是模块的返回值,这并不是我们自定义的信息,所以,如果想要在tasks中给变量自定义信息,并且在之后的play操作同一个主机时能够使用到之前在tasks中定义的变量时,则可以使用set_facts定义对应的变量。
上述示例中,即使是跨play获取变量,也都是针对同一台主机。
自定义过滤插件
找到过滤插件所在的目录,当前没有任何过滤插件,新增一个插件deal_list_num.py
[root@mcw1 ~]$ ls /usr/share/ansible/plugins/filter
deal_list_num.py
插件的好处在于编写YML文件时可以减少我们的工作量,而且结果易于展示,只要学习一些比较重要的比如Filter、Callbacks等即可。
在普通情况下,我们主要是以{{somevars|filter}对somevars使用filter方法过滤,Ansible已经为我们提供了很多的过滤方法,比如找到列表中最大、最小数的max、min,把数据转换成JSON格式的fromjson等,但这还远远不够,我们还需要自定义一些过滤的方法来满足一些特殊的需求,比如查找列表中大于某个常数的所有数字等。以这个例子,展示如何编写。
首先,到ansible.cfg中去掉#,打开filter_plugins的存放目录,filter_plugins=/usr/share/ansible/plugins/filter。
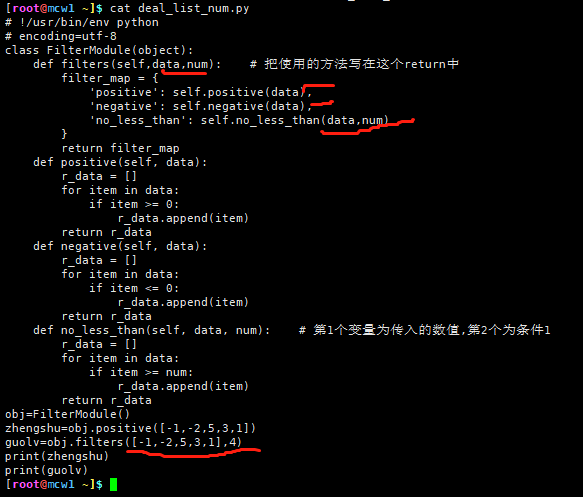
编写deal_list_num.py文件,他主要提供过滤列表中的正数、负数和查询列表大于某一个给定数值这3个方法。/usr/share/ansible/filter/deal_list_num.py。
# !/usr/bin/env python
# encoding=utf-8
class FilterModule(object):
def filters(self): # 把使用的方法写在这个return中
filter_map = {
'positive': self.positive,
'negative': self.negative,
'no_less_than': self.no_less_than
}
return filter_map
def positive(self, data):
r_data = []
for item in data:
if item >= 0:
r_data.append(item)
return r_data
def negative(self, data):
r_data = []
for item in data:
if item <= 0:
r_data.append(item)
return r_data
def no_less_than(self, data, num): # 第1个变量为传入的数值,第2个为条件1
r_data = []
for item in data:
if item >= num:
r_data.append(item)
return r_data
[root@mcw1 ~]$ cat deal_list_num.yml
- hosts: localhost
gather_facts: False tasks:
- name: set fact
set_fact:
num_list: [-1,-2,5,3,1] - name: echo positive
shell: echo {{num_list | positive}}
register: print_positive
- debug: msg="{{print_positive.stdout_lines[0]}}" - name: echo negative
shell: echo {{num_list | negative}}
register: print_negative
- debug: msg="{{print_negative.stdout_lines[0]}}" - name: echo negative
shell: echo {{num_list | no_less_than(4)}}
register: print_negative
- debug: msg="{{print_negative.stdout_lines[0]}}"
剧本
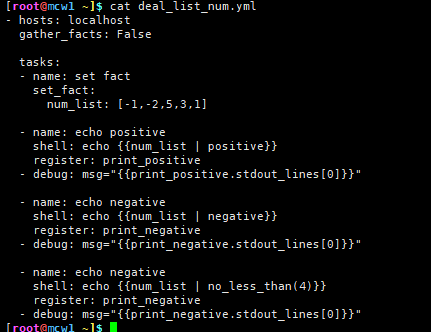
第一个是取列表中的正数,第二个是取列表中的负数。第三个是取列表中不小于4的数

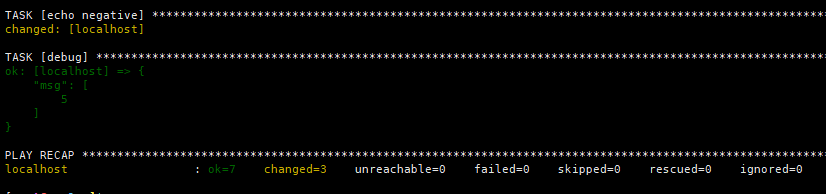
变量引用和查看获取shell命令结果作为注册变量,该如何取到命令结果

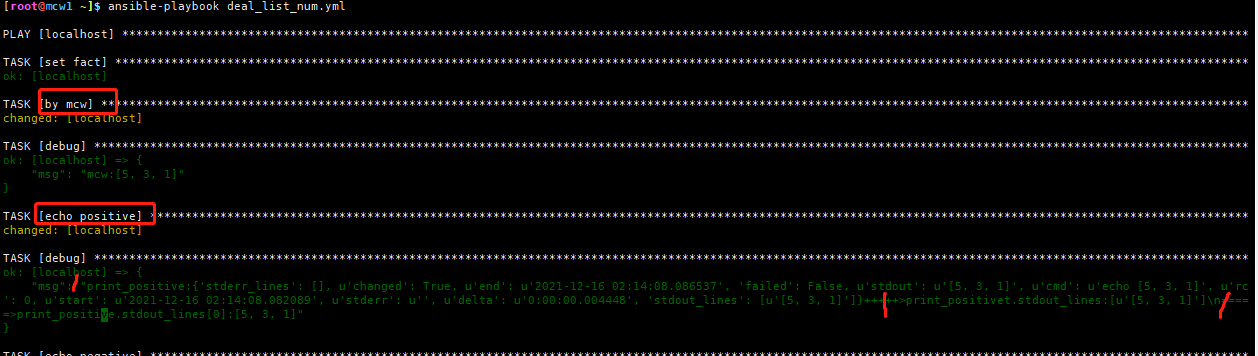
过滤方法这里做个修改

总结:
1、过滤插件定义类,类中定义方法,方法返回内容
2、将过滤插件放到ansible过滤插件目录下
3、剧本中{{变量}}的方式调用变量。然后变量后面|加过滤方法。这样就可以将变量传递进插件对应方法中,除了self之外的第一个位置参数就是这个剧本中的变量。
4、在过滤插件方法中对这个变量做过滤,然后返回结果(这里是定义空列表,然后将剧本变量列表遍历一次,筛选出指定条件的元素追加到新的列表中,方法返回新的列表这样剧本中就是使用过滤后的数据)
参考地址:
剧本编写和定义模块: https://blog.csdn.net/weixin_46108954/article/details/104990063
设置和注册变量:https://blog.csdn.net/weixin_45029822/article/details/105280206
自定义插件:过滤插件:https://blog.csdn.net/JackLiu16/article/details/82121044
ansible自定义模块的更多相关文章
- 使用python开发ansible自定义模块的简单案例
安装的版本ansible版本<=2.7,<=2.8是不行的哦 安装模块 pip install ansible==2.7 先导出环境变量 我们自定义模块的目录. 我存放的目录 export ...
- python基础知识8——模块1——自定义模块和第三方开源模块
模块的认识 模块,用一砣代码实现了某个功能的代码集合. 类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合.而对于一个复杂的功能来,可能需 ...
- Python 第五篇(下):系统标准模块(shutil、logging、shelve、configparser、subprocess、xml、yaml、自定义模块)
目录: shutil logging模块 shelve configparser subprocess xml处理 yaml处理 自定义模块 一,系统标准模块: 1.shutil:是一种高层次的文件操 ...
- Python爬虫与数据分析之模块:内置模块、开源模块、自定义模块
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- Ansible 常用模块(一)
一.Ansible简介 Ansible是新出现的自动化运维工具,基于python开发,集合了众多运维工具(puppet(ruby).cfengine.chef.func.fabric.)的优点,实现了 ...
- ansible核心模块playbook介绍
ansible的playbook采用yaml语法,它简单地实现了json格式的事件描述.yaml之于json就像markdown之于html一样,极度简化了json的书写.在学习ansible pla ...
- ansible的模块使用
转载于 https://www.cnblogs.com/franknihao/p/8631302.html [Ansible 模块] 就如python库一样,ansible的模块也分成了基本模块和 ...
- 【python】用setup安装自定义模块和包
python解释器查找module进行加载的时候,查找的目录是存放在sys.path变量中的,sys.path变量中包含文件的当前目录.如果你想使用一个存放在其他目录的脚本,或者是其他系统的脚本,你可 ...
- angular(3)服务 --注入---自定义模块--单页面应用
ng内部,一旦发生值改变操作,如$scope.m=x,就会自动轮询$digest队列,触发指定的$watch,调用其回调函数,然后修改dom树. 干货:https://github.com/xufei ...
随机推荐
- [loj3367]装饼干
先考虑如何判定一个$y$是否可行--从高位开始,记录这一位所需要的$2^{i}$数量$t$,若$y$的这一位为1,则$t+=x$,之后分两类讨论:1.$t\le a_{i}$,令$t=0$:2.$b& ...
- IDEA生成doc文档-生成chm文档
首先,打开IDEA,并找到Tools -> Generate JavaDoc- 可供查询的chm比那些HTML页面好看多了. 如果您用过JDK API的chm文档,那么您一定不会拒绝接受其它第三 ...
- 痞子衡嵌入式:深扒IAR启动函数流程之段初始化函数__iar_data_init3实现
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家分享的是IAR启动函数流程里的段初始化函数__iar_data_init3实现. 本篇是 <IAR启动函数流程及其__low_level_ ...
- GoF23种(部分)软件设计模式【核心理解】
设计模式复习 1. 面向对象设计原则 1.1 可维护性较低的软件设计 过于僵硬 过于脆弱 复用率低 黏度过高 1.2 一个好的系统设计 可扩展性 灵活性 可插入性 复用:一个软件的组成部分可以在同一个 ...
- 【3】蛋白鉴定软件之Mascot
目录 1.简介 2.配置 2.1在线版本 2.2 服务器版本 3.运行 3.1 在线版本 3.2 服务器版本 4.结果 1.简介 Mascot是非常经典的蛋白鉴定软件,被Frost & Sul ...
- jquery操作html中图片宽高自适应
在网站制作中如果后台上传的图片不做宽高限制,在前台显示的时候,经常会出现图片变形,实用下面方法可以让图片根据宽高自适应,不论是长图片或者高图片都可以完美显示. $("#myTab0_Cont ...
- kubernetes部署 flannel网络组件
创建 flannel 证书和私钥flannel 从 etcd 集群存取网段分配信息,而 etcd 集群启用了双向 x509 证书认证,所以需要为 flanneld 生成证书和私钥. cat > ...
- idea 启动debug的时候throw new ClassNotFoundException(name)
idea 启动debug的时候throw new ClassNotFoundException(name) 启动debug就跳转到此界面 解决办法 这个方法只是忽略了抛异常的点,并没有真正解决问题.后 ...
- day11 序列化组件、批量出入、自定义分页器
day11 序列化组件.批量出入.自定义分页器 今日内容详细 ajax实现删除二次提醒(普通版本) ajax结合第三方插件sweetalert实现二次提醒(样式好看些) ajax如何发送文件数据 aj ...
- 从分布式锁角度理解Java的synchronized关键字
分布式锁 分布式锁就以zookeeper为例,zookeeper是一个分布式系统的协调器,我们将其理解为一个文件系统,可以在zookeeper服务器中创建或删除文件夹或文件.设D为一个数据系统,不具备 ...