Java基础(一):I/O多路复用模型及Linux中的应用
IO多路复用模型广泛的应用于各种高并发的中间件中,那么区别于其他模式他的优势是什么、其核心设计思想又是什么、其在Linux中是如何实现的?
I/O模型
I/O模型主要有以下五种:
- 同步阻塞I/O:I/O操作将同步阻塞用户线程
- 同步非阻塞I/O:所有操作都会立即返回,但需要不断轮询获取I/O结果
- I/O多路复用:一个线程监听多个I/O操作是否就绪,依然是阻塞I/O,需要不断去轮询是否有就绪的fd
- 信号驱动I/O:当I/O就绪后,操作系统发送SIGIO信号通知对应进程,避免空轮询导致占用CPU(linux中的信号驱动本质还是使用的epoll)
- 异步I/O:应用告知内核启动某个操作,并让内核在整个操作完成之后,通知应用,这种模型与信号驱动模型的主要区别在于,信号驱动IO只是由内核通知我们可以开始下一个IO操作,而异步IO模型是由内核通知我们操作什么时候完成
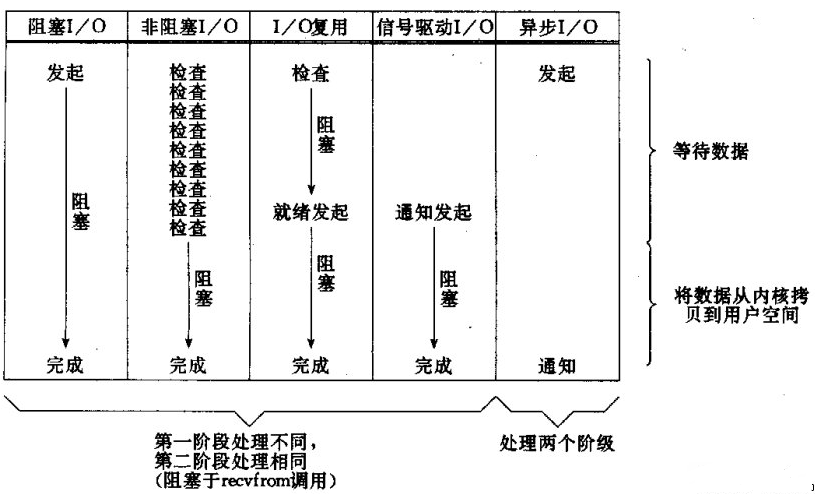
其中应用最广的当属I/O多路复用模型,其核心就是基于Reactor设计模式,仅一个线程就可以监听多个I/O事件,使得在高并发场景下节约大量线程资源
Reactor设计模式
处理WEB通常有两种请求模型:
- 基于线程:每个请求都创建一个线程来处理。并发越高,线程数越多,内存占用越高,性能也会越低,线程上下文切换造成性能损耗,线程等待IO也会浪费CPU时间。一般应用于并发量少的小型应用。
- 事件驱动:每个请求都由Reactor线程监听,当I/O就绪后,由Reactor将任务分发给对用的Handler。
显然事件驱动模型更适用于目前动辄几十万并发的场景。
网络服务器的基本处理模型如下:建立连接->读取请求->解析请求->处理服务->编码结果->返回结果。
基于网络服务器的基本模型,Reactor衍生出了以下三种模型。
1.单线程模型
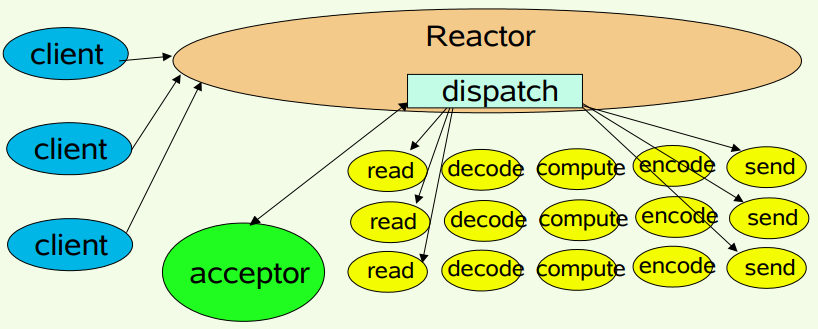
Reactor单线程模型,指的是所有的I/O操作都在同一个NIO线程上面完成,NIO线程的职责如下:
- 作为NIO服务端,接收客户端的TCP连接
- 作为NIO客户端,向服务端发起TCP连接
- 读取通信对端的请求或者应答消息
- 向通信对端发送消息请求或者应答消息
Reactor线程负责多路分离套接字,Accept新连接,并分派请求到处理器链中。该模型 适用于处理器链中业务处理组件能快速完成的场景。不过,这种单线程模型不能充分利用多核资源,所以实际使用的不多。
2.多线程模型
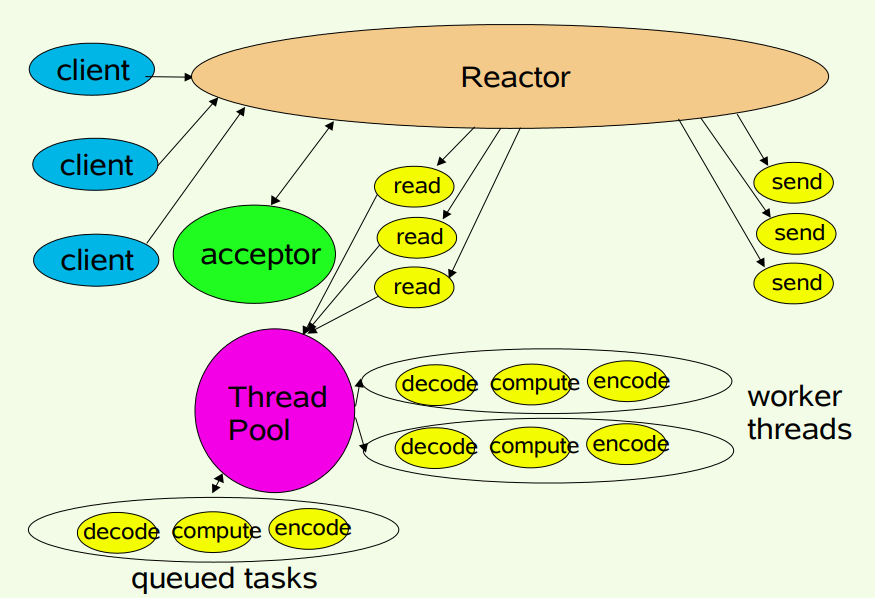
Reactor多线程模型与单线程模型最大区别就是引入了线程池,负责异步调用Handler处理业务,从而使其不会阻塞Reactor,它的流程如下:
- Reactor 对象通过 select 监控客户端请求事件,收到事件后,通过 dispatch 进行分发
- 如果是建立连接请求,则由 Acceptor 通过 accept 处理连接请求,然后创建一个 Handler 对象处理完成连接后的各种事件
- 如果不是连接请求,则由 Reactor 对象会分发调用连接对应的 Handler 来处理
- Handler 只负责响应事件,不做具体的业务处理,通过 read 读取数据后,会分发给后面的 Worker 线程池的某个线程处理业务
- Worker 线程池会分配独立线程完成真正的业务,并将结果返回给 Handler
- Handler 收到响应后,通过 send 将结果返回给 Client
3.主从多线程模型
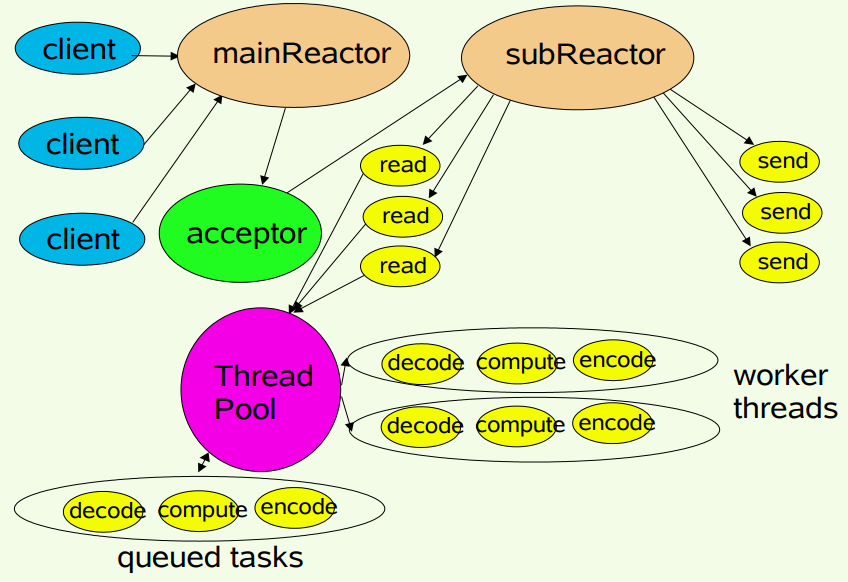
将连接请求句柄和数据传输句柄分开处理,使用单独的Reactor来处理连接请求句柄,提高数据传送句柄的处理能力。
服务端用于接收客户端连接的不再是1个单独的NIO线程,而是一个独立的NIO线程池。Acceptor接收到客户端TCP连接请求处理完成后(可能包含接入认证等),将新创建的SocketChannel注册到I/O线程池(sub reactor线程池)的某个I/O线程上,由它负责SocketChannel的读写和编解码工作。
著名的Netty即采用了此种模式
Linux中的I/O多路复用
linux实现I/O多路复用,主要涉及三个函数select、poll、epoll,目前前两个已经基本不用了,但作为面试必考点还是应该知晓其原理。
几个重要概念:
- 用户空间和内核空间:为保护linux系统,将可能导致系统崩溃的指令定义为R0级别,仅允许在内核空间的进程使用,而普通应用则运行在用户空间,当应用需要执行R0级别指令时需要由用户态切换到内核态(极其耗时)。
- 文件描述符(File descriptor):当应用程序请求内核打开/新建一个文件时,内核会返回一个文件描述符用于对应这个打开/新建的文件,其fd本质上就是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。
select
int select(int maxfd1, // 最大文件描述符个数,传输的时候需要+1
fd_set *readset, // 读描述符集合
fd_set *writeset, // 写描述符集合
fd_set *exceptset, // 异常描述符集合
const struct timeval *timeout);// 超时时间select通过数组存储用户关心的fd并通知内核,内核将fd集合拷贝至内核空间,遍历后将就绪的fd集合返回
其缺点主要有以下几点:
- 最大支持的fd_size为1024(有争议?),远远不足以支撑高并发场景
- 每次涉及fd集合用户态到内核态切换,开销巨大
- 遍历fd的时间复杂度为O(n),性能并不好
poll
int poll(struct pollfd *fds, // fd的文件集合改成自定义结构体,不再是数组的方式,不受限于FD_SIZE
unsigned long nfds, // 最大描述符个数
int timeout);// 超时时间
struct pollfd {
int fd; // fd索引值
short events; // 输入事件
short revents; // 结果输出事件
};poll技术与select技术实现逻辑基本一致,重要区别在于其使用链表的方式存储描述符fd,不受数组大小影响
说白了对于select的缺点poll只解决了第一点,依然存在很大性能问题
epoll
// 创建保存epoll文件描述符的空间,该空间也称为“epoll例程”
int epoll_create(int size); // 使用链表,现在已经弃用
int epoll_create(int flag); // 使用红黑树的数据结构
// epoll注册/修改/删除 fd的操作
long epoll_ctl(int epfd, // 上述epoll空间的fd索引值
int op, // 操作识别,EPOLL_CTL_ADD | EPOLL_CTL_MOD | EPOLL_CTL_DEL
int fd, // 注册的fd
struct epoll_event *event); // epoll监听事件的变化
struct epoll_event {
__poll_t events;
__u64 data;
} EPOLL_PACKED;
// epoll等待,与select/poll的逻辑一致
epoll_wait(int epfd, // epoll空间
struct epoll_event *events, // epoll监听事件的变化
int maxevents, // epoll可以保存的最大事件数
int timeout); // 超时时间为了解决select&poll技术存在的两个性能问题,epoll应运而生
- 通过epoll_create函数创建epoll空间(相当于一个容器管理),在内核中存储需要监听的数据集合,通过红黑树实现,插入删除的时间复杂度为O(nlogn)
- 通过epoll_ctl函数来注册对socket事件的增删改操作,并且在内核底层通过利用mmap技术保证用户空间与内核空间对该内存是具备可见性,直接通过指针引用的方式进行操作,避免了大内存数据的拷贝导致的空间切换性能问题
- 通过ep_poll_callback回调函数,将就绪的fd插入双向链表fd中,避免通过轮询的方式获取,事件复杂度为O(1)
- 通过epoll_wait函数的方式阻塞获取rdlist中就绪的fd
EPOLL事件有两种模型 Level Triggered (LT) 和 Edge Triggered (ET):
- LT(level triggered,水平触发模式)是缺省的工作方式,并且同时支持 block 和 non-block socket。在这种做法中,内核告诉你一个文件描述符是否就绪了,然后你可以对这个就绪的fd进行IO操作。如果你不作任何操作,内核还是会继续通知你的,所以,这种模式编程出错误可能性要小一点。
- ET(edge-triggered,边缘触发模式)是高速工作方式,只支持no-block socket。在这种模式下,当描述符从未就绪变为就绪时,内核通过epoll告诉你。然后它会假设你知道文件描述符已经就绪,并且不会再为那个文件描述符发送更多的就绪通知,等到下次有新的数据进来的时候才会再次出发就绪事件。
Don't let emotion cloud your judgment.
不要让情绪影响你的判断。
Java基础(一):I/O多路复用模型及Linux中的应用的更多相关文章
- 【java基础 13】两种方法判断hashmap中是否形成环形链表
导读:额,我介绍的这两种方法,有点蠢啊,小打小闹的那种,后来我查了查资料,别人都起了好高大上的名字,不过,本篇博客,我还是用何下下的风格来写.两种方法,一种是丢手绢法,另外一种,是迷路法. 这两种方法 ...
- Java基础之写文件——将素数写入文件中(PrimesToFile)
控制台程序,计算素数.创建文件路径.写文件. import static java.lang.Math.ceil; import static java.lang.Math.sqrt; import ...
- Java基础之写文件——在通道写入过程中的缓冲区状态(BufferStateTrace)
控制台程序,在Junk目录中将字符串“Garbage in, garbage out\n”写入到名为charData.txt的文件中. import static java.nio.file.Stan ...
- Java基础---集合框架---迭代器、ListIterator、Vector中枚举、LinkedList、ArrayList、HashSet、TreeSet、二叉树、Comparator
为什么出现集合类? 面向对象语言对事物的体现都是以对象的形式,所以为了方便对多个对象的操作,就对对象进行存储,集合就是存储对象最常用的一种方式. 数组和集合类同是容器,有何不同? 数组虽然也可以存储对 ...
- Java基础加强之并发(三)Thread中start()和run()的区别
Thread中start()和run()的区别 start() : 它的作用是启动一个新线程,新线程会执行相应的run()方法.start()不能被重复调用.run() : run()就和普通的成 ...
- [Java基础] 深入jar包:从jar包中读取资源文件
转载: http://hxraid.iteye.com/blog/483115?page=3#comments 我们常常在代码中读取一些资源文件(比如图片,音乐,文本等等).在单独运行的时候这些简单的 ...
- (Linux基础学习)第五章:Linux中的screen应用
第1节:安装screen1.加载系统镜像文件,因为screen的安装包在系统镜像文件中图001 2.列出系统上所有的磁盘[root@centos6 ~]# lsblk图002 3.安装screen应用 ...
- 大话java基础知识一之为什么java的主函数入口必须是public static void
为什么java的主函数入口必须是public static void main (String[] args); 很多写javaEE好几年的程序员经常会记得java的主函数就是这么写的,但实际上为什么 ...
- 第4节:Java基础 - 必知必会(中)
第4节:Java基础 - 必知必会(中) 本小节是Java基础篇章的第二小节,主要讲述抽象类与接口的区别,注解以及反射等知识点. 一.抽象类和接口有什么区别 抽象类和接口的主要区别可以总结如下: 抽象 ...
随机推荐
- 第三方模块npm
npm介绍 npm 全名 node package manager node包管理工具,增删查改 如果npm操作太慢,可以安装npm镜像 npm的下载 比如全局下载一个jquery文件,全局下载的 ...
- Flex中利用事件机制进行主程序与子窗体间参数传递
在开发具有子窗体,或者itemrenderer的应用时,常常涉及到子窗体向父窗体传递参数或者从itemrenderer内的控件向外部的主程序传递参数的需求.这些都可以通过事件机制这一统一方法加以解决. ...
- 闲聊,Python中的turtle
写在前面 其实我也不知道为什么我会写这个,本文涉及信号与传递,Python 正题 近期看到一个3年前的视频,1000个圆一笔画出一个Miku 在观看完源码了以后,我发现这是这调用的是基本的goto,用 ...
- Java:代码高效优化
本文转自阿里技术站,感谢阿里前辈提供的技术知识,微信关注 "阿里技术" 公众号即可实时学习. 1.常量&变量 1.1.直接赋值常量值,禁止声明新对象 直接赋值常量值,只是创 ...
- Redis为什么变慢了?常见延迟问题定位与分析
Redis作为内存数据库,拥有非常高的性能,单个实例的QPS能够达到10W左右.但我们在使用Redis时,经常时不时会出现访问延迟很大的情况,如果你不知道Redis的内部实现原理,在排查问题时就会一头 ...
- XSS challenges 1-10
学长发的xss靶场,刚好js学完了,上手整活. 这个提示说非常简单,直接插入就完事了 <script>alert(document.domain)</script> 第二关. ...
- XCTF(MISC) 坚持60s
题目描述:菜狗发现最近菜猫不爱理他,反而迷上了菜鸡 下载附件,发现是一个游戏,同时要玩到60s才能得到flag(可恶,完全玩不到60s,被疯狂嘲讽) ------------------------- ...
- Java 在Word中创建邮件合并模板并合并文本和图片
Word里面的邮件合并功能是一种可以快速批量操作同类型数据的方式,常见的如数据填充.打印等.其中必不可少的步骤包括用于填充的模板文档.填充的数据源以及实现邮件合并的功能.下面,通过Java程序展示如何 ...
- 开源的负载测试/压力测试工具 NBomber
负载测试和压力测试对于确保 web 应用的性能和可缩放性非常重要. 尽管它们的某些测试是相同的,但目标不同. 负载测试:测试应用是否可以在特定情况下处理指定的用户负载,同时仍满足响应目标. 应用在正常 ...
- adb 记录ADB执行记录
自动化测试需要获得当前的activity,来判断处于的页面是否正确: hierarchy view经常连不上真机,无法获得activity,所以直接用 adb命令来查看当前运行的 activity就可 ...