【机器学习基础】关于深度学习的Tips
继续回到神经网络章节,上次只对模型进行了简要的介绍,以及做了一个Hello World的练习,这节主要是对当我们结果不好时具体该去做些什么呢?本节就总结一些在深度学习中一些基本的解决问题的办法。
为什么说是“基本的办法”?因为这一部分主要是比较基础的内容,是一些常用的,比较容易理解的,不过多的去讨论各式各样的网络结构,只是介绍这些方法都做了些什么。
对于深度学习的探索后面会再开专题,专门去学习和讨论(突然发现要学的东西真的很多~)
深度学习技巧
0.不要总是让“过拟合”背锅
在机器学习中,当我们对我们最终的结果(testing data上的score)不满意时,总是认为模型可能overfitting了,其实这样是不对的,正确的步骤应该是下面这样的:
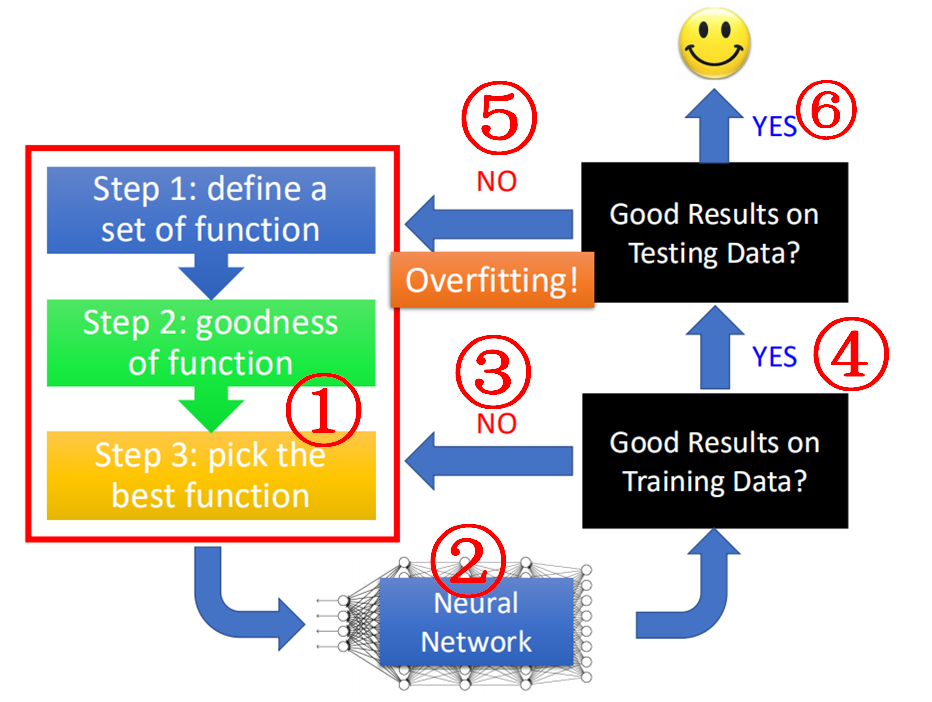
当我们经过三步走①建立好神经网络模型②后,需要去查验模型在训练集上的误差,如果这个误差较大(准确率很差),则需要重新调整模型或模型参数,转向③;
如果模型误差较小(准确率很好),则转向④,进一步在测试集上验证正确率和误差,当此时测试集上的误差很大,那么才能称之为过拟合,需要我们回头⑤重新设计模型或者模型参数;
如果在测试集上的误差也很小,那么恭喜你,一个好的模型就可以使用了。
所以,不能总怪过拟合的问题,因为针对不同原因产生效果差有不同的解决方法,我们要首先判断是否属于过拟合,才能进一步采取措施。
下面我们就针对上面两个问题(①在训练集上表现就不好,②在训练集上表现还可以,在测试集上表现很差)进行针对性地解决。
首先是当在训练集上的结果就不好的情况:
1.更换激活函数(Activation function)
首先我们先在前面的手写辨识的例子的基础上举个例子:
在上节中我们采用了中间有两层的隐藏层的网络结构,得到的准确率为99.53%的准确率,如果现在我增加隐藏层的层数,增加到10层:

可以看到,结果完全烂掉了,准确率只有11%了。
因此,网络并非越深越好,下图展示了不同的网络层数的训练准确率的变化情况:
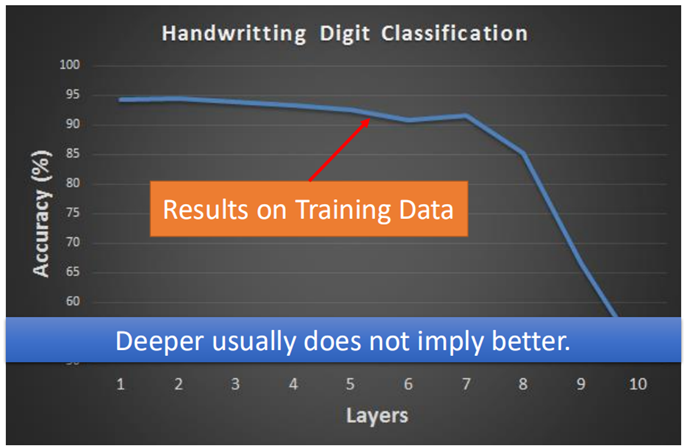
可以看出,并非随着网络层数的增加,准确率并非一直上升的。这里要提一句,在深度学习中,其实是很难将准确率提升至1.0的,这点与之前的模型是不同的,比如决策树,只要树的深度足够,很轻易能够达到1。
回到正题,为什么会出现模型越deep,准确率反而下降的情况呢?回头看一下网络的结构:

对于一个很深的网络结构,在前面网络层(靠近输出层)由于具有较大的梯度,当每层网络的学习率都相同时,前面的参数学习会很快,而后面的(靠近输入层)的参数由于梯度较小,导致学习速度很慢;
当前面的参数已经收敛时,前面的还没有开始更新,依然是初始的随机的参数,这种现象称之为梯度消失,也叫梯度弥散。
为什么会出现这种现象呢?
其实就是激活函数Sigmoid的问题,当激活函数为Sigmoid时,我们需要看一下为什么后面的梯度很小。
这里不需要具体算出具体的数值,只需要大概知道当前面的某一个参数w改变后,对Loss有多大的影响即可。如图所示:
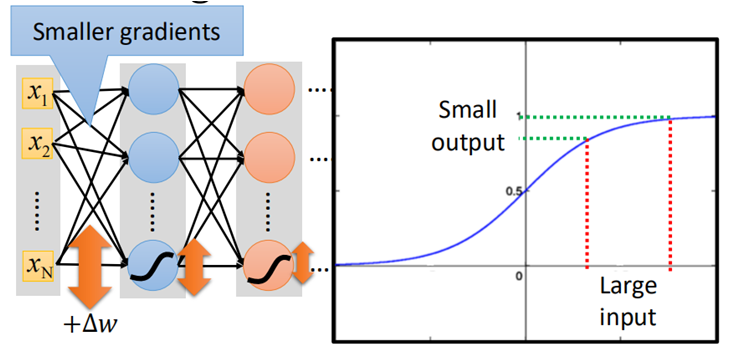
当前面的某一个参数增大Δw后,看下Loss的损失增大了多少,即ΔL,从图中看出,当经过第一层网络时,要经过一个sigmoid函数,该函数会将输入进行一次衰减,如右侧sigmoid函数图像
即使参数有一个很大的改变时(横轴),在经过sigmoid函数后,也会被缩放到一个很小的区间(纵轴),以此类推,每层如此,因此,当网络足够深的话,这个ΔL→0。
又因为在参数更新的过程是反向传播的,因此,在更新时,由于链式求导法则,需要不断乘上σ'(z),也是一个不断衰减的过程,因此到了后面,几乎梯度极小,导致梯度消失。
那么这个问题如何解决呢?
只需换掉激活函数就行了,在前面的Hello World程序中,在add(Activation)时,该参数是可选的,下面就介绍一种激活函数“RELU”。
RELU(Rectified Linear Unit)
RELU函数是一个很简单的函数,如图所示:
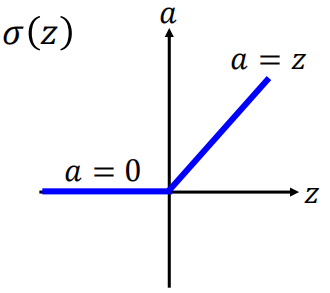
当输入<0时,输出为0,当输入>0时,输出为其本身。
为什么要用RELU作为激活函数呢,(1)由于其计算速度很快,相比于Sigmoid,不用计算exp了(2)生物学上有一定的道理(这个我也不太理解,但不重要)(3)最重要的是RELU可以解决梯度消失的问题。
那么RELU代入到网络中是如何运作的呢?
把原网络中的sigmoid函数换成RELU,网络结构如下:
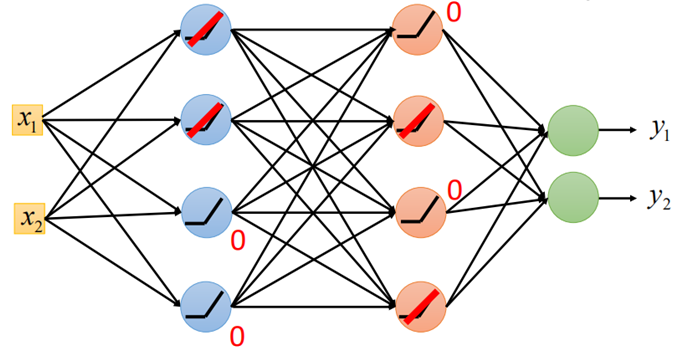
图中将所有的sigmoid换成RELU,那么当输入经过RELU时只会有两种输出,一种是0,另一种是是其本身,如上图所示,假设在第二层中后两个为0,第三次1、3神经元为0,其他都是其本身(圆圈内已用线性表示)。
那么最终我们的网络结构可以看作如下这样子:
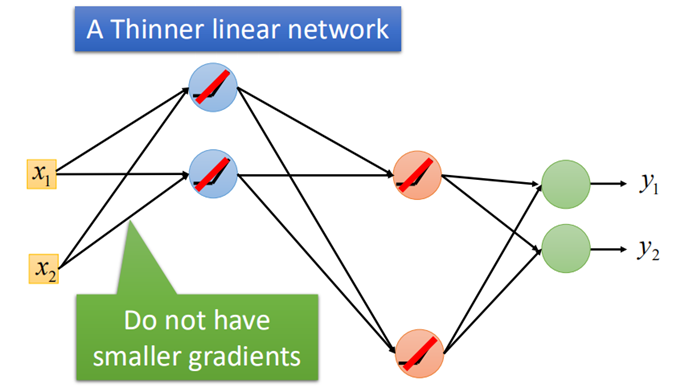
这样一方面不会再出现反向传播过程中导致的梯度消失问题,另一方面网络变成了一个更“瘦”的线性结构,提升了运算速度。
然而,当使用RELU时,对于上一层一部分输出小于0的值会直接置为0,这样对应的参数就不再更新了,这也会导致一部分神经“坏死”,如上面我们直接忽略掉的一些神经元,这可能有时造成特征的提取不够充分。
而当使用较大的学习率时,w更新过大,可能更新为负值,那么输出极可能为负值,再经过RELU时,会导致神经元处于坏死状态,永远都不会再被激活。
为了解决这一问题,另一种RELU的变形的激活函数Leakly ReLU就应运而生,其图像为:
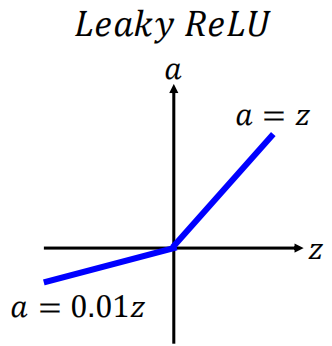
当输入小于0是,有一个极小的输出,这时使该神经元的作用变得很弱,几乎处于“昏死”状态,但一旦有机会,这个神经依然可能被激活。
以及另一种变形的ReLU,参数ReLU形式:

这里的α可以是任意参数,同时,α也可以作为网络的参数一起被学习。
Maxout激活函数
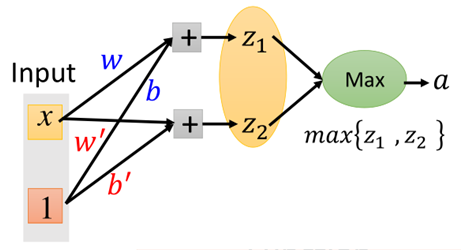
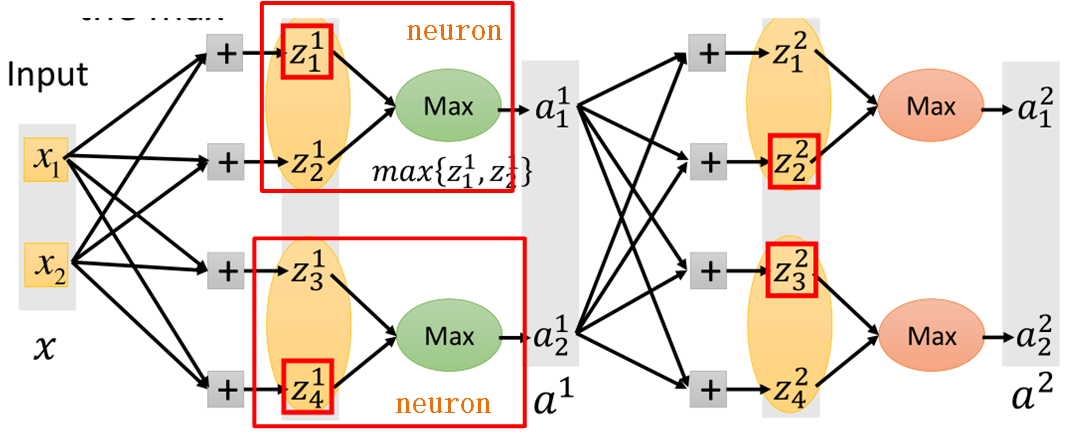
Maxout是一种自动学习激活函数的激活函数,就是能够自动学习激活函数的参数,具体的运作方式如图所示:
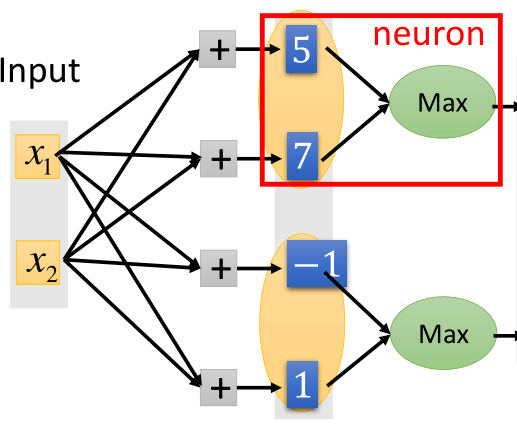
假设一个输入x是二维的,经过wx+b之后得到4个输出;
然后对输出进行分组,这个分组是事先定好的,如将前两个元素分为一组,后两个元素分为一组;
然后对每个组取出最大的值,作为输出,接下来输入到下一层网络中,以此类推。如图所示
红色框的部分即为一个神经元,这里需要注意的是,原本我们的网络中间层应该只有两个输出,现在要经过一层maxout,多出了两个输出,那么相当于多出了四个参数,
这四个参数就是靠学习出来的。因此说maxout是自己学习出来的激活函数。
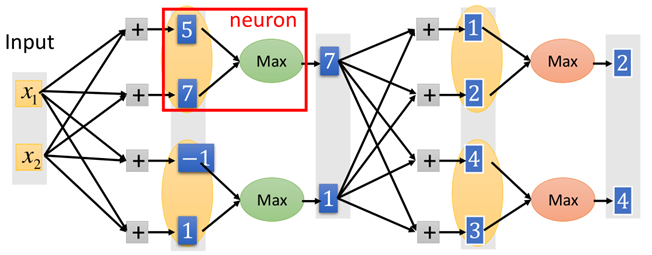
实际上,只要maxout愿意,一样可以变成ReLU激活函数:如下图:
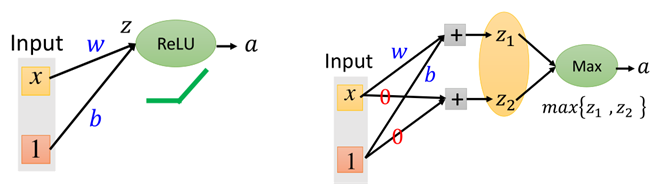
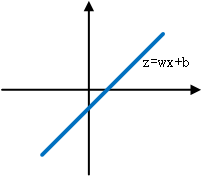
前一张为ReLU结构,假设x是一个一维的(注意图上的1是参数b,并非一个维度),那么在ReLU中:z=wx+b,画在图上为:
那么经过ReLU之后,大于0(x轴上方)的部分输出是其本身,小于0(x轴下方)的部分输出为0,那么则有:
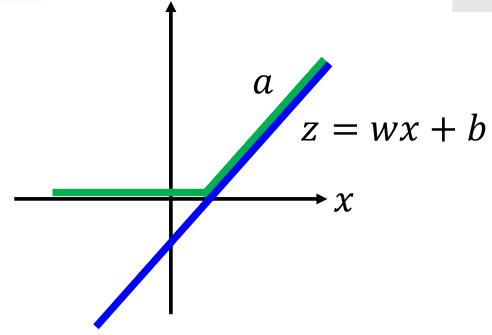
而在maxout中,后面那张图,除了原先的w和b参数,还要有一组参数w'和b',现在我们令w'和b'都为0,那么:z1=wx+b,z2=0*x+0=0,画在图上为:
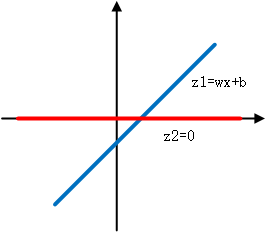
然后经过maxout函数,maxout是取二者之间最大值,所以始终取位于上方的那一部分,即为:

可以看到最终的绿色的线就是ReLU函数。
所以说ReLU只是maxout的一种特例。
而在实际中,maxout是自身要去学习参数w'和b'的,如图:
那么z1和z2在图中,画出来就是这样的:
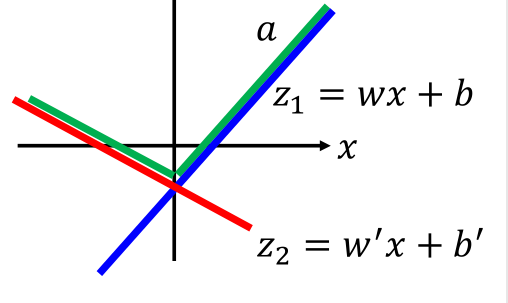
图中蓝色线是z1,红色线是z2,最终取max之后就是绿色的那条线。
当然,我们也可以取三个元素分为一组,那么会得到如下的激活函数形式:
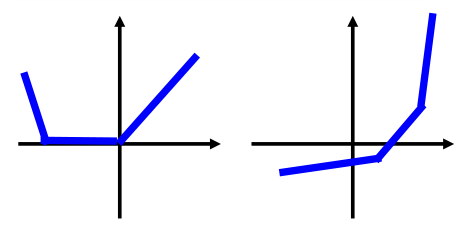
再来回顾一下maxout的结构:
这里会有一个问题,由于maxout函数是存在不可导点的,那是否可以用梯度下降的方法呢?
其实是可以的,对于每一个max的输出,我们直接将所得到的那一部分放进去训练即可,另一个就可以暂时忽略掉了,跟ReLU那个置为0的神经元一样:
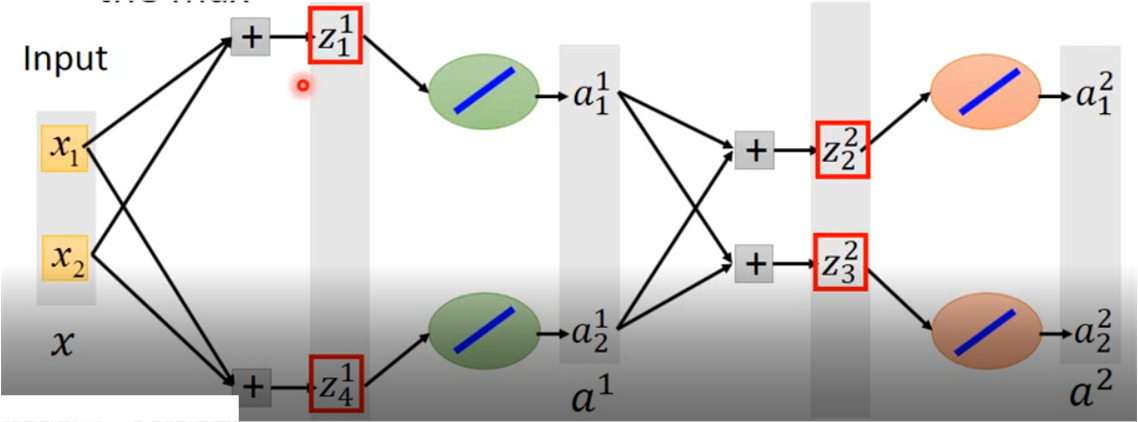
网络就变成了这样的结构,然后去训练就好了。
但这里要注意的是,这里并不是让某个神经元“坏死”,因为maxout的结构内(即在经过max之前)有两个输出,删掉一个之后这个神经元还是存在的(因为有一个输出本来就是多出来的),只不过此时只更新与这个最大值连接的参数。
那问题就来了,这样不是就不能更新那些删掉的元素相连接的参数了吗?
其实一样是可以更新的,因为对于一个样本而言,可能最大值是z1,那么对于另一个输入x而言,可能最大值就变成了z2,这时就会更新之前被删掉的元素z2所连接的参数了。
2.自适应学习率
这个就是前面提到的,当学习率都相同时,伴随着梯度消失(因为导致梯度消失的元凶是激活函数,不知道怎么描述,就写“伴随着”吧),有时使用动态的学习率确实能够改善梯度消失的问题;
另一方面,前面梯度下降章节说到,学习率在学习中自适应能够加快收敛,且更容易达到局部最优,因此自适应的学习率是必要的。
至于自适应学习率有哪些方法和原理,参加梯度下降章节中有关内容https://www.cnblogs.com/501731wyb/p/15322391.html。这里就不再说了。
上面就是对于在训练集上都表现不好,所要采取的策略,当然还包括最基本的模型的结构调整。
下面就是当模型在训练集上表现很好,但在测试集上反而下降了,这种情况就属于过拟合,一般情况下采取的策略。
3.正则化
正则化可谓是伴随着整个机器学习算法,过拟合一般离不了正则化,正则化在前面正则化的章节中也已介绍完了,一般就包括L1正则和L2正则,在深度学习中道理是一样的,在损失函数后面加上对应的正则项即可。
正则化有关内容详见:https://www.cnblogs.com/501731wyb/p/15436330.html。
4.Early Stopping
在训练过程中,模型从一开始啥都不知道,再到学习之后,开始逐渐表现越来愈好,到后面会更加倾向于细枝末节的学习,为了能够在训练集上表现的更加优秀,因此在测试集上的精度就会降低。
因此此时需要能够及早停止训练,防止过拟合,这种方法就称之为early stopping。
那么如何操作呢,这时就需要validation data了,当我们的模型在validation data上的准确率不再提高,就可以停止训练了。
具体做法是,每个epoch训练完成后,模型回到validation data上进行验证,当accuracy不再提高时,就停止训练。
这里所谓的“不再提高”,不能因为一两次的下降就停止,一般是记录当前在validation data上最好的accuracy,当连续10次epoch都没有达到这个accuracy时,则就可以停止了。这种方法也称为“No-improvement-in-n”
5.dropout
dropout可谓是深度学习中的一个特色,但又有点像集成学习中随机森林中随机抽取部分特征作为树的训练的味道,后面会进行一个说明。这里先介绍dropout。
所谓dropout就是在训练过程中随机去掉原本网络结构中的一部分神经元,当然也可以包括输入,再进行训练,如图所示:
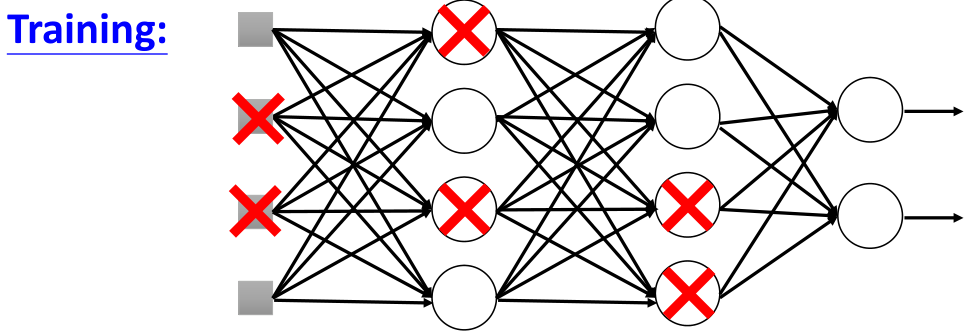
神经元被丢弃后,类似于上面的ReLU,网络结构也就发生了变化:
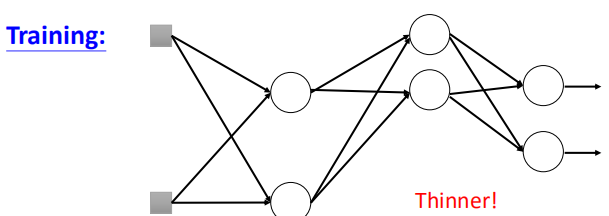
那么我们在进行参数更新之前,需要设定一个参数,这个参数决定了每个神经元被丢掉的几率p%,因此每个节点都有p%的概率被丢弃掉。
这个工作一般是在batch上做的,即对于每个mini_batch进行一次参数更新的时候,就会改变一次网络的结构。
要注意的是,当我们训练好所有的参数之后,在对样本进行预测时,此时是不再需要进行dropout的,即:
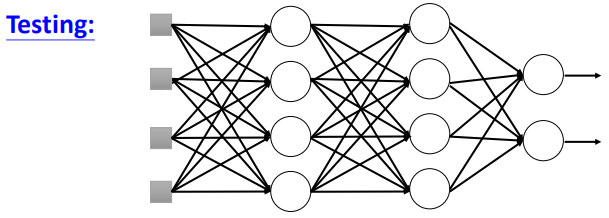
如果训练时设定的dropout的概率为p%,那么在进行测试时,需要对训练好的参数统统乘以1-p%。
至于为什么dropout能够提升效果呢,一个直观的解释就是如图所示:
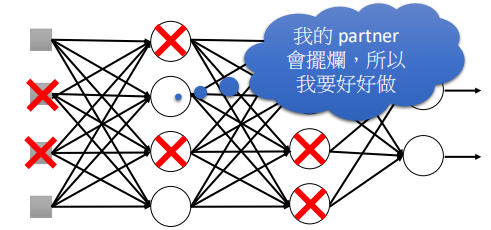
在进行dropout时,当一些神经元被丢弃掉(摆烂)之后,那么那些没有被丢弃的神经元会好好表现,争取做好。
而到了测试阶段,所有的神经元都会参与,这时没有会摆烂了,所以会得到比较好的结果。(略微牵强,但还是有一定的道理的)。
那么至于为什么要dropout在测试时要乘以补偿系数1-p,下面就从bagging的角度来探讨一下:
dropout可以说是一种bagging的集成学习方法,如下图所示:
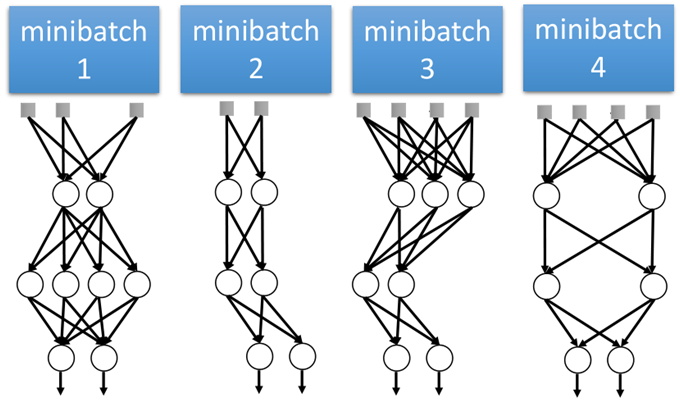
就相当于我们训练出来了很多个模型,只不过这些模型的参数都是共享的,那么当把模型应用于测试集时:
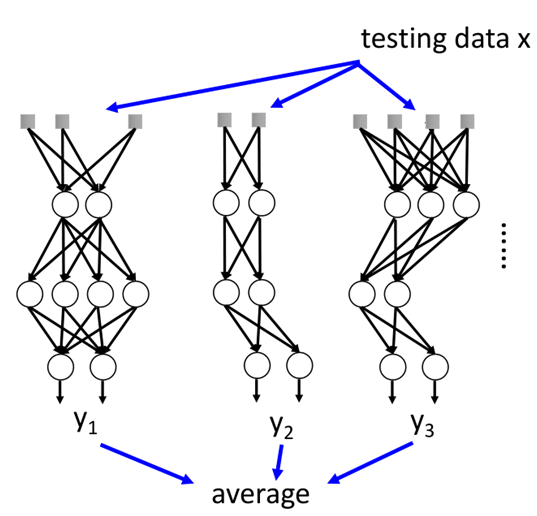
相当于我们拿一个测试数据,分别拿到每个模型中,然后根据每个模型的输出,求出平均值就是最终的输出。
然而这其实是不太可能的,因为网络结构太多了,假设有M个神经元,那个共有2M种可能的网络结构。
而dropout神奇的地方就是,当把训练参数weights都乘以1-p%之后,不进行dropout的话,经过网络所得到的结果和average是很接近的。下面举个例子说明一下:
假设一个网络结构只有输入到输出,dropout几率为50%,只能dropout输入的维度了,那么一共可能产生4中结构,如下:
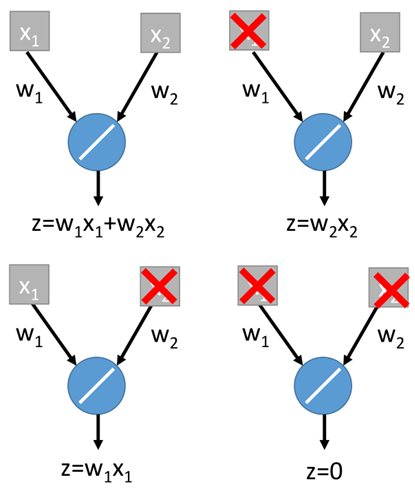
通过综合四个输出,最终得到z=1/4(2*w1*x1+2*w2*x2)=0.5*w1*x1+0.5*w2*x2,如果对于最终训练的权重直接乘(1-50%),则有:
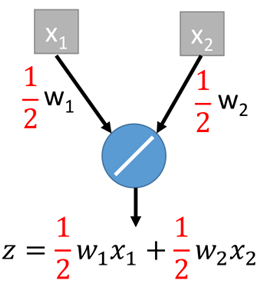
可以看出,两个是相等的。这只是作为一个例子说明,有时其实并非完全相等,只能说是近似相等。
好了,到这里有关深度学习中一些常用的技巧就到差不多了,由于这里仅是对深度学习有个初步的认知,知道其是什么,以及在做什么事,其他内容暂不深究。
后记:博客内容仅是自己的回顾和学习,可能有的地方描述不是很深刻,路过的如果有疑问可以看李宏毅老师的机器学习课程,无论是讲课还是PPT真的很良心~
有关深度学习的内容后面可能暂时就不更新了,等到后面基础部分介绍完毕后,再开一个深度学习的专题(也有可能一边更基础,一边学习深度学习,根据自己的学习进度吧~),下一更可能会介绍CNN,也可能到具体某一种算法。
【机器学习基础】关于深度学习的Tips的更多相关文章
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)
##机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)---#####注:机器学习资料[篇目一](https://github.co ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- (转)零基础入门深度学习(6) - 长短时记忆网络(LSTM)
无论即将到来的是大数据时代还是人工智能时代,亦或是传统行业使用人工智能在云上处理大数据的时代,作为一个有理想有追求的程序员,不懂深度学习(Deep Learning)这个超热的技术,会不会感觉马上就o ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料汇总 (上)
转载:http://dataunion.org/8463.html?utm_source=tuicool&utm_medium=referral <Brief History of Ma ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料(下)
转载:http://www.jianshu.com/p/b73b6953e849 该资源的github地址:Qix <Statistical foundations of machine lea ...
- 机器学习python*(深度学习)核心技术实战
Python实战及机器学习(深度学习)技术 一,时间地点:2020年01月08日-11日 北京(机房上课,每人一台电脑进行实际案例操作,赠送 U盘拷贝资料及课件和软件)二.课程目标:1.python基 ...
- Python机器学习库和深度学习库总结
我们在Github上的贡献者和提交者之中检查了用Python语言进行机器学习的开源项目,并挑选出最受欢迎和最活跃的项目. 1. Scikit-learn(重点推荐) www.github.com/sc ...
- 1.1机器学习基础-python深度机器学习
参考彭亮老师的视频教程:转载请注明出处及彭亮老师原创 视频教程: http://pan.baidu.com/s/1kVNe5EJ 1. 课程介绍 2. 机器学习 (Machine Learning, ...
随机推荐
- Fabric SSH链接时关于找不到主机的问题
先上一段简单的fabric代码: from __future__ import with_statementfrom fabric.api import *env.user = 'zhangsan'e ...
- 关于Python中的深浅拷贝
之前一直认为浅拷贝是拷贝内容的第一层,但是不开辟内存,只是增加新的指向原来的内容:深拷贝是拷贝是拷贝每一层并开辟内存. 其实这个是不严谨的不正确的. 从以上可以看出,浅拷贝中当时可变类型的时候,内存是 ...
- AOJ/高等排序习题集
ALDS1_5_B-MergeSort. Description: Write a program of a Merge Sort algorithm implemented by the follo ...
- TypeScript 条件类型精读与实践
在大多数程序中,我们必须根据输入做出决策.TypeScript 也不例外,使用条件类型可以描述输入类型与输出类型之间的关系. 本文同步首发在个人博客中,欢迎订阅.交流. 用于条件判断时的 extend ...
- JS中call,apply,bind的区别
1.关于this对象的指向,请看如下代码 var name = 'jack'; var age = 18; var obj = { name:'mary', objAge:this.age, myFu ...
- python单例模式设计
class MyTest(): my_obj = None def __new__(cls,*args,**kwargs): if not cls.my_obj: cls.my_obj =object ...
- 浅尝装饰器--property装饰器
[写在前面] 本帖归属于装饰器单元的学习,可以点击关键词'装饰器'查看其他博文讲解 [正文部分] property属性:将类方法用类属性的形式进行调用 class Good: def __init__ ...
- nmap常用命令汇总
nmap常用命令 选项 解释 使用举例 举例说明 Nmap主机发现 -sP Ping扫描 -P0 无Ping扫描 -PS TCP SYN Ping扫描 -PA TCP ACK ...
- ByteCTF2021 double sqli
double sqli easy sqli http://39.105.175.150:30001/?id=1 http://39.105.116.246:30001/?id=1 http://39. ...
- Java:并发笔记-03
Java:并发笔记-03 说明:这是看了 bilibili 上 黑马程序员 的课程 java并发编程 后做的笔记 3. 共享模型之管程-2 本章内容-2 Monitor wait/notify 3.6 ...