Logstash 的命令行入门 ( 附上相关实验步骤 )
Logstash 的命令行入门 ( 附上相关实验步骤 )
在之前的博客中,我们已经在 Macbook Big Sur 环境下安装了 ELK 的相关软件,并且已经可以成功运行对应的模块;
如果没有安装的同学,或者对于安装有困惑的朋友请点击下边的链接,仅限于 Mac OS 环境的安装指南,后期可能会补上在 Linux 下的安装步骤:
https://www.cnblogs.com/doherasyang/p/14629555.html
目前,我在 ELK方向 的主要的精力都在学习 Elasticsearch 的相关特性 以及 与 Kibana 的配合进行数据展示,但是 尝试写了一下 Elasticsearch 的相关博客内容,我真的觉得很难写,因为只是知识点,对于实际操作部分的内容撰写比较花时间,我也是在逐步摸索中,难以形成体系的内容,因此我决定先将这部分的内容放下,先集中精力 撰写 ELK 的数据处理部分 - Logstash
1. 数据准备
数据是你干啥都非常重要的事情,没有数据基本上做啥都没有用,并且数据的相关格式内容必须要贴近你自己的需求,对于我个人来说,对于 ELK 的需求有两个方面:
- 第一个方面:借鉴 Github 在代码、文档搜索功能中的集成,为即将开始搭建的博客网站提供文档搜索引擎以及相关性计算的支持;
- 第二个方面:使用 ELK 做到日志审计和安全审计分析,生成相关个姓化图片和报表,为 整个生产环境 提供安全态势感知的支持,这个方面的相关内容和思路,会在之后持续更新;
总之,使用 ELK 的技术 是为了应对大数据环境和做好日常的运维日志处理、审计工作的重要一环,也是未来数据中心IDC运维工程师技术发展的重要方向,因此我认为学习的重要性也是非常大的;‘
从这么长时间的学习上来看,我认为 ELK 具备未来技术的相关特性,简单来说有以下几个方面:
- 支持 Docker 和 集群部署、调度,为相关云化提供了解决方案,并且基于 jruby、Python 等语言,尤其是 Python 的相关支持,为成为云技术发展提供了支撑,目前 Go 语言在云计算领域的火热程度呈现上升的趋势,有 Python 作为支撑的前提,我认为这只是一个时间问题;
- 支持 REST API 的扩展,只要 Web 技术一日不倒,那么 ELK 就是非常棒的选择,在最近的学习中,我也体验了 REST API 的相关特性,我认为真的是非常的出色,只要你有Web 应用,你就可以轻松获得ELK技术的支持;
- 插件化 (Plug-in) 的管理,插件化的管理让整个技术上手非常容易,我之前做过 React Native 的开发,深知模块化对于快速开发和相关功能拓展的意义,因此 ELK 的插件化管理让我觉得上手非常快,非常容易上手,并且相关文档丰富,开源社区强大;
- 开源的优势,因为插件的开源,不论是个人还是开发团队都可以做到获得源码的二次开发,潜力不可预估;
说了这么多,我非常推荐你使用ELK技术栈来解决你在工作、或者个人兴趣开发上遇到的任何问题,因此我也会尽心来准备 和 编写关于这方面的内容的博客内容,如果有什么问题或者错误,请您发送问题和内容到: doherasyanng@gamil.com
1.1 开源数据库推荐
第一个是一个关于网络安全的数据库,被托管在 GIthub 网站上,免费使用:
https://github.com/shramos/Awesome-Cybersecurity-Datasets#network-traffic
第二个是一个名叫 Security Repo 的安全数据网站:
「后续将会继续补充我遇到的比较好的数据源」
当然,我也会后续自己上传自己制作的相关数据集,有兴趣的朋友可以关注一下这部分的内容;
1.2 本文中用到的数据集
@copyright Security Repo - auth.log - approx 86k lines, and mostly failed SSH login attempts
内容:
- 记录失败登录 SSH 的相关 syslog
- 涉及到的服务有:
SSHD和CRON的服务;
1.3 摘取部分日志内容 - auth.log
Dec 1 08:31:33 ip-172-31-27-153 sshd[24839]: Received disconnect from 67.205.20.23: 11: Bye Bye [preauth]
Dec 1 08:31:34 ip-172-31-27-153 sshd[24841]: Invalid user git from 67.205.20.23
Dec 1 08:31:34 ip-172-31-27-153 sshd[24841]: input_userauth_request: invalid user git [preauth]
Dec 1 08:31:34 ip-172-31-27-153 sshd[24841]: Received disconnect from 67.205.20.23: 11: Bye Bye [preauth]
Dec 1 08:31:35 ip-172-31-27-153 sshd[24843]: Received disconnect from 67.205.20.23: 11: Bye Bye [preauth]
Dec 1 08:31:35 ip-172-31-27-153 sshd[24845]: Received disconnect from 67.205.20.23: 11: Bye Bye [preauth]
2. Logstash 的命令行配置讲解
从之前的内容我们已经可以正常在 MacOS 环境下使用 Logstash 命令,从而启动 Logstash 服务为我们处理相关的数据流,本章的内容结构如下:
- 2.1 - 搞清楚 Logstash 服务在系统中存在的形式以及如何被调用的
- 2.2 - 通过命令行启动 Logstash 并 自定义相关配置参数
2.1 Logstash 服务
Logstash 是可以作为服务被托管在你的Linux系统上,详细如何了解怎么被托管,你可以参考 Elastic 的官方文档,在这里不做更加详细的介绍:https://www.elastic.co/guide/en/logstash/current/running-logstash.html
但是,需要了解 Logstash 是怎么工作的,下边的图片简单的揭示了 Logstash 的整体运作原理:
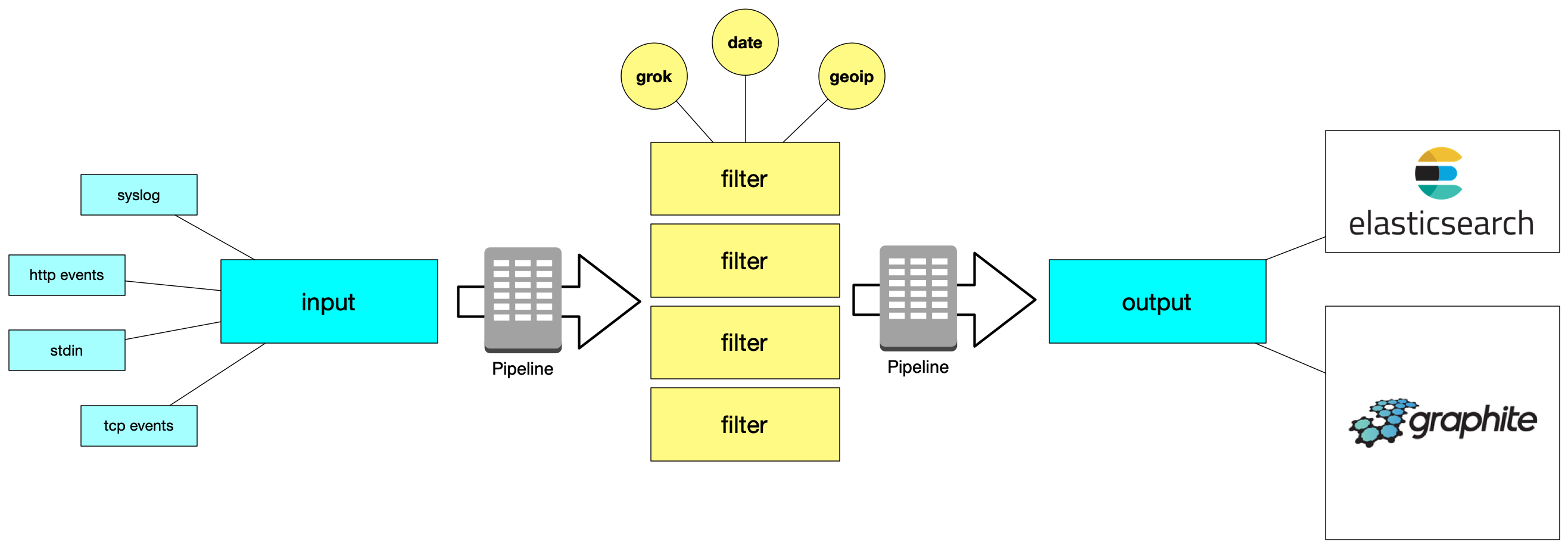
Logstash 被分成了三种部分:
第一个部分:input 负责处理数据流的输入,数据通过 input 插件(模块)输入到 Logstash 的引擎中 以供进一步进行处理;
第二个部分:filter 负责对 input 输入的数据流进行处理,处理的插件有:
- grok - 利用正则表达式 / 匹配模式 进行处理输入的数据流;
- date - 标准化处理时间格式: 将输入的时间处理成标准格式;
- geoip - IP 的地理位置数据库,用于获取和分析 IP的地理位置;
经过 filter 模块处理完的数据的格式是: 标准 JSON 数据格式 - 非常方便进行通信的数据格式;
第三个部分:output 负责将处理完的 JSON 数据传递给指定的服务或者输出到文件,因此 Logstash 可以将数据处理、分析、结构化完成之后可以将数据发送给 Elasticsearch 引擎 或者 Graphite 数据工具;
在不同部分中,Logstash 使用 pipeline 进行数据在不同插件(模块)的传递和处理, 你可以在 Logstash 的配置文件中,配置 pipeline 的相关参数,接下来的内容会讲到 pipeline 的参数配置;
其实对于 Elasticsearch 来说, Logstash 整体就是一个 pipeline 为 Elasticsearch 提供数据;
2.2 Logstash 命令的参数配置
在前边中,我们已经知道了 Logstash 是通过命令行或者自己配置服务进行启动的,那么通过命令行启动就一定要涉及到参数的配置问题,Logstash 支持指定参数配置文件从而运行相关服务;
你可以通过 --help 命令来打印 Logstash 的所有的参数信息配置,非常非常的长和复杂,在这里挑几个重要的说一下:
--node.name: 为 Logstash 的实例进行命名,默认值: 你的本机的 host name ;-f / --path.config: 为 Logstash 指定配置文件,这个配置文件是指你自己定义的关于处理文档的相关配置文件,包含 2.1 部分的三个主要插件:input / filter / output ,在这个配置文件当中,可以指定插件实现的具体功能;如果你想要制定多个文件,那么你可以尝试使用下边的格式:
logstash
-e / --config.string: 为 Logstash 指定配置内容,这个内容的格式是:String,与--path.config的比对一下,--path.config文件的内容是--config.string输入的内容;如果不配置这个参数的话:
- defalut input :
input {stdin {type => stdin}} - default output :
output { stdout {codec => rubydebug}}
- defalut input :
--path.logs / -l: 为 Logstash 指定默认的日志输出路径;logstash -l ./logstash_log.log
--log.level: 为 Logstash 输出的fatal- 非常严重的错误error- 错误warn- 报警info- 记录详细信息 ( 默认 )debug- 为开发者提供调试的相关信息trace- 记录除调试信息外的更细粒度的消息
--log.format: Logstash 提供了两种日志的相关格式:JSON和PLAIN, 可以自由被指定;--pipeline-workers / -w: 为output和filter插件指定运行的管道的个数 - “线程数”,默认的管道数是你的 CPU 的 核数,你可以适当的增加改值来有效利用服务器的核数,在你的服务器计算能力允许的情况下;--pipeline-ordered: 可以被设定的值是:autotruefalse,默认的值是default与上边的
--pipeline-workers进行配合,只有在workers=1时生效,做到对所有 Logstash 的事件流进行排序,当这个参数值设置成为
auto时,当pipeline-workers=1会自动启动事件排序( event ordering) 并回影响 filter 和 output 的性能;当这个参数值设置成为
true时,当pipeline-workers != 1时,那么 Logstash 就不会被启动,因此有阻止多个管道线程数启动的功能;当这个参数值设置成为
false时,可以在任何情况下都阻止事件排序;
--pipeline-batch-size/ -b: 设定每个 Logstash 管道 ( pipeline ) 的可以处理的事件数,每一个管道可以当成一个“线程”,可以为每一个“线程” 设定能够存储的最大事件条数( Maximum Events) ,默认的值是: 125 ;需要深入理解一下这个概念:
以 日志文件进行举例,每一个 日志文件都有很多行具体的日志信息,像
auth.log有8K+行;Logstash 在将这个文件放入 input 插件时会指定将会创建的管道数 (--pipeline-workers 指定);
指定了管道数 ( workers ) 之后,Logstash 需要创建 - 批量 ( batch ), 构成 批 的基本单位就是 事件 (events) ;
而
pipeline-batch-size设定的就是每一个批量 ( batch ) 的大小,这个大小当然是由每一个 批 (batch) 中的事件数来决定的,因此pipeline-batch-size就是设定每一个批中可以打包事件的数量;事件 (events) 是 日志文件中的每一行日志记录,即单行的日志信息就是单个事件;
默认的值: 125 ,即 Logstash 从 日志文件
auth.log读取1 25行日志条数 组成一个 批量( batch ),然后通过管道传递给filter和output插件进行处理;但是这个存在一个 内存消耗的问题,因为 Logstash 是运行在自己的 JVM 上的,因此需要配合修改配置文件:
/config/jvm.options--pipeline-batch-delay: 在 Logstah 打包 批量 传给fitter和output之前,需要等待 Logstash 将所有的事件进行打包,打包过程中需要等待每一个事件被打包到批量当中,需要给这个过程设置一个超时时间,默认的超时时间是: 50ms;在 50ms 之后,即使 批量没有达到最大的容量,都会给
--config.reload.automatic / -r: 自动判断配置文件是否更新;--http.host: 设定 Logstash 的 Web API 绑定的地址;--http.port: 设定 Logstash 的 端口,端口范围是 9600 - 9700 ;--config.debug: 配置的 Debug 模式, 可能会导致你输入的密码泄露;
简单的做一个简单的例子,首先创建一个实验的目录,我创建的实验目录如下:
DoHeras-Macbook-Pro ~/Desktop/Elastic/demo $pwd
/Users/doheras/Desktop/Elastic/demo
目前当前目录下所有的文件:
DoHeras-Macbook-Pro ~/Desktop/Elastic/demo $ls
auth.log demo.config
# auth.log 就是之前下载的关于 SSHD 和 CRON 服务的相关日志信息
# demo.config 是你需要去创建的一个 Logstash 的配置文件
demo.config 的内容如下:
input {
file {
# 必须是绝对路径
path => "/Users/doheras/Desktop/Elastic/demo/auth.log"
start_position => "beginning"
type => "syslog"
# 需要指定特定的文件
sincedb_path => "/Users/doheras/Desktop/Elastic/demo/.storedb"
}
}
filter {
grok {
# 第一步我们需要来提取日期这个非常关键的日志信息-下边的正则表达式可以
match => {
"message" => "^(?<Date_Time>\w+\s\d+\s\d+:\d+:\d+)"
}
}
}
output {
stdout {
codec => rubydebug {
}
}
}
上边文件的相关内容会在下一篇: Logstash 的配置文件内容详解 中讲到,这里不做介绍;
运行下边的命令:
DoHeras-Macbook-Pro ~/Desktop/Elastic/demo $sudo logstash -f ./demo.config -l ./logstash.log --log.format json --pipeline.batch.size 200 --pipeline.workers 5 --log.level debug --config.debug
上边的命令:
- 指定了一个配置文件:
-f demo.config - 指定 Logstash 输出的日志目录:
-l ./logstash.log - 指定的 Logstash 的输出日志格式 :
--log.format json - 指定批量包含的事件数:
--pipeline.batch.size 200 - 指定开通的管道数:
--pipeline.workers 5 - 指定需要记录的日志等级:
--log.level debug - 进入完全Debug 模式:
--config.debug
如果正常你的屏幕就可以打印相关的日志信息了,如下所示:
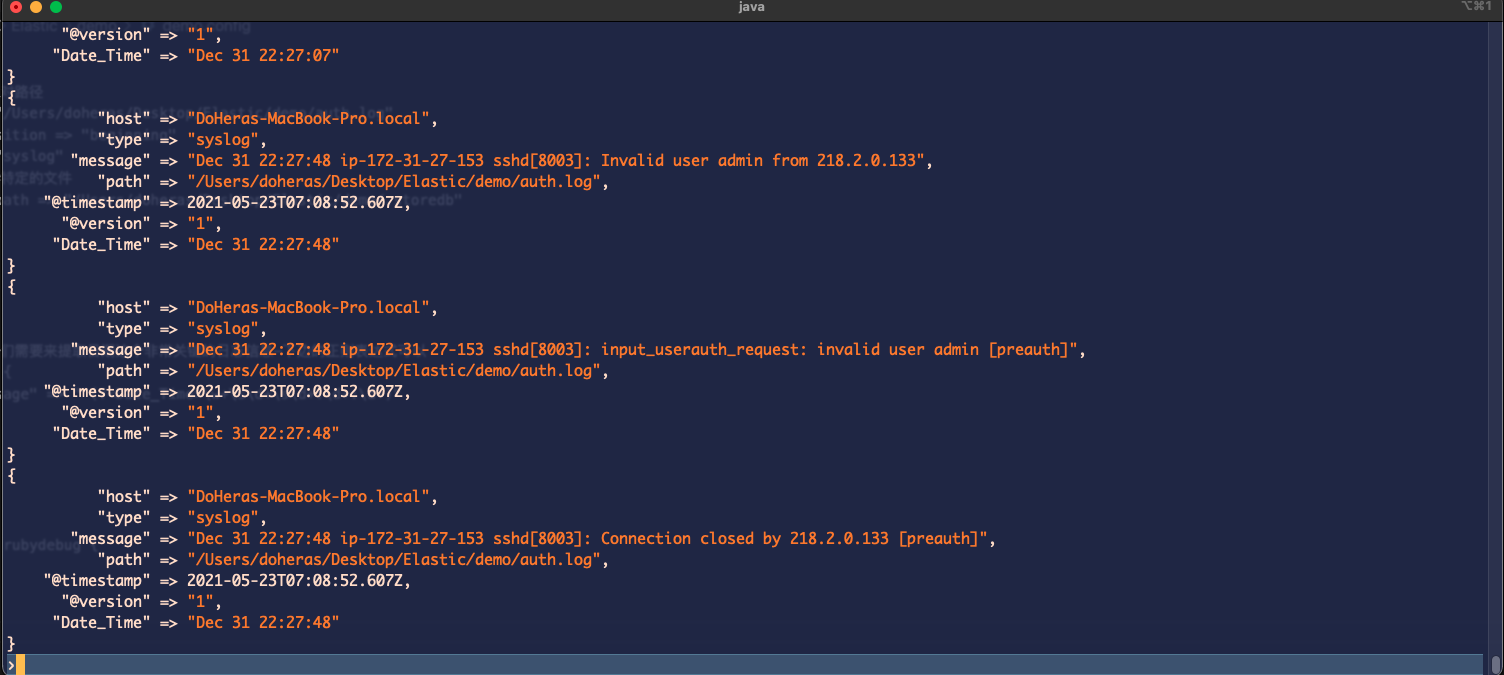
在配置文件中创建了 .storedb 来存放当前日志文件读取的日志文件的位置,当你的控制台没有任何输出时,需要删除这个文件:
DoHeras-Macbook-Pro ~/Desktop/Elastic/demo $ls -a
. .. .DS_Store .storedb auth.log demo.config logstash.log
DoHeras-Macbook-Pro ~/Desktop/Elastic/demo $rm -rf ./.storedb
我们还可以发现,Logstash 为我们创建了一个文件夹: logstash.log
该文件夹下边有三个文件:
logstash-deprecation.log: 被废弃功能的调用日志;logstash-json.log: 正儿八经运行的日志;logstash-slowlog-json.log: 对花费时间较长的管道进行记录;
Logstash 的命令行入门 ( 附上相关实验步骤 )的更多相关文章
- Git命令行入门
安装 下载与文档地址:https://git-scm.com/book/zh/v2 我使用的是linux系统,故使用命令行安装Git # apt-get install git 配置 # git co ...
- Git简易的命令行入门教程
简易的命令行入门教程: Git 全局设置: git config --global user.name "imsoft" git config --global user.emai ...
- mysql 命令行操作入门(详细讲解版)
之前分享过多次Mysql主题,今天继续分享mysql命令行入门 1. 那么多mysql客户端工具,为何要分享命令行操作? -快捷.简单.方便 -在没有客户端的情况下怎么办 -如果是mysql未开启 ...
- 打磨程序员的专属利器——命令行&界面
工欲善其事,必先利其器,程序员更是如此,如果没有一套与自己思维同步的工具,将非常难受并且编码效率会非常低. 但十个程序员就有对工具的十种不同理解,本人现在冒然将自己的“工具箱”拿出来晒晒.若对大家没帮 ...
- FileZilla命令行实现文件上传以及CreateProcess实现静默调用
应用需求: 用户在选择渲染作业时面临两种情况:一是选择用户远程存储上的文件:二是选择本地文件系统中的文件进行渲染.由于渲染任务是在远程主机上进行的,实际进行渲染时源文件也是在ftp目录 ...
- php命令行
转载(http://blog.jobbole.com/109093/) PHP作为一门web开发语言,通常情况下我们都是在Web Server中运行PHP,使用浏览器访问,因此很少关注其命令行操作以及 ...
- Windows命令行打开常用界面
本文主要介绍Windows下命令行操作打开常用界面,使用方法为在DOS命令行下输入相关命令.可以减少多次操作界面.可以尝试在命令行执行下面提到的命令感受下,快捷键主要内容包括: 1.查看计算机的基本信 ...
- 《Java 程序设计》课堂实践项目-命令行参数
<Java 程序设计>课堂实践项目 课后学习总结 目录 改变 命令行参数实验要求 课堂实践成果 课后思考 改变 修改了博客整体布局,过去就贴个代码贴个图很草率,这次布局和内容都有修改.加了 ...
- esxi主机用命令行强行关闭通过前端界面无法关闭的ESXI虚拟机
环境:esxi5.1-esxi6.5 背景:如果esxi下面某一台vm死机了,并且esxi的控制台卡死不能用,为了不影响同一个esx下其他的vm正常使用,那么我们只能用命令行来单独重启此vm,保证一定 ...
随机推荐
- Ingress-nginx工作原理和实践
本文记录/分享 目前项目的 K8s 部署结构和请求追踪改造方案 这个图算是一个通用的前后端分离的 k8s 部署结构: Nginx Ingress 负责暴露服务(nginx前端静态资源服务), 根据十二 ...
- 【Linux学习笔记1】-centos6.9部署django
一,centos6.9部署django 部署套件:centos6.9+nginx+mysql+uwsgi+python3+django 首先还是要明白这几个部分之间的关系(自己也是初学者,希望 ...
- 【linux】制作deb包方法 **
目录 前言 概念 ** 创建自己的deb包 文件源码 前言 制作deb的方式很多 使用 dpkg-deb 方式 使用 checkinstall 方式 使用 dh_make 方式 修改原有的 deb 包 ...
- 获取执行计划之Autotrace
Autotrace 简介 AUTOTRACE是一项SQL*Plus功能,自动跟踪为SQL语句生成一个执行计划并且提供与该语句的处理有关的统计. AUTOTRACE的好处是您不必设置跟踪文件的格式,并且 ...
- Python—关于Pandas缺失值问题(国内唯一)
获取文中的CSV文件用于代码编程以及文章首发地址,请点击下方超链接 获取CSV,用于编程调试请点这 在本文中,我们将使用Python的Pandas库逐步完成许多不同的数据清理任务.具体而言,我们将重点 ...
- Shell十三问更新总结版 -- 什么叫做 Shell?-- Shell十三问<第一问>
Shell十三问更新总结版 简介 ChinaUnix 论坛 Shell 版名为網中人的前辈于 2004 年发布的精华贴,最近回炉这块内容,觉得很多东西讲的实在透彻,非常感谢前辈網中人,同时我个人也对这 ...
- 全网最详细的Linux命令系列-less命令
less 工具也是对文件或其它输出进行分页显示的工具,应该说是linux正统查看文件内容的工具,功能极其强大.less 的用法比起 more 更加的有弹性.在 more 的时候,我们并没有办法向前面翻 ...
- Database | 浅谈Query Optimization (1)
综述 由于SQL是声明式语言(declarative),用户只告诉了DBMS想要获取什么,但没有指出如何计算.因此,DBMS需要将SQL语句转换成可执行的查询计划(Query Plan).但是对同样的 ...
- FastDFS一步步搭建存储服务器
一:FastDFS简介 1:FastDFS简介 FastDFS是一个开源的轻量级分布式文件系统,功能包括:文件存储.文件同步.文件访问(文件上传.文件下载)等,解决了大容量存储和负载均衡的问题.特别适 ...
- Molar mass UVA - 1586
An organic compound is any member of a large class of chemical compounds whose molecules contain c ...