Python3对接华三CAS平台Api获取虚拟机监控信息-渐入佳境
--时间:2021年2月3日
--作者:飞翔的小胖猪
说明
使用python对接华三CAS虚拟化平台,通过厂商提供的api接口获取每个集群下所有虚拟机的监控信息,并保存数据在本地的mariadb数据库。
使用脚本时请读者根据自己的实际情况填入用户名、密码、cas平台地址。
设置线程时不要设置过多,脚本设置为20个在执行时明显能感觉到cas网页有点慢。
环境
华三CAS平台版本: V5.0(E0513H02)
Python版本:3.8.4
操作系统版本: Centos Linux release 7.5.1804
数据库版本:mariadb-server-5.5.65
数据库
创建数据库及用户
MariaDB [(none)] > create database cas_info;
MariaDB [(none)] > create user cas@'%' identified by 'Cas_123456#'
MariaDB [(none)] > grant all privileges on cas_info.* to cas@'%';
MariaDB [(none)] > flush privileges;
数据表创建语句
create table cas_trend(
id int(10) primary key not null auto_increment,
vm_id varchar(50),
vm_ip varchar(30),
cpu_rate varchar(15),
mem_rate varchar(15),
vm_stat varchar(6),
net_r varchar(20),
net_r_p varchar(20),
net_w varchar(20),
net_w_p varchar(20),
io_mbps varchar(20),
io_r_mbps varchar(20),
io_w_mpbs varchar(20),
io_r_iops varchar(20),
io_w_iops varchar(20),
timestamp varchar(30)
);
脚本
from http.cookiejar import CookieJar,MozillaCookieJar
import numpy
import _thread
import threading
import requests
import time
import pymysql
import re
import sys
import lxml.html
import urllib3.request
import urllib.request
from http.cookiejar import CookieJar,MozillaCookieJar def get_cas_session():
#定义获取到cas的token值。
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36'}
#其中的name和password值 可以手动使用浏览器访问一下cas然后去header里面截取出来。
url='http://X.X.X.X:8080/cas/spring_check?encrypt=true&lang=cn&name=TESTDBAVsRM&password=HLLWA8ATwKqvLWn94opBBB3ynOBrVKXXX'
cookiejar = CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookiejar)
opener = urllib.request.build_opener(handler)
data = {
'encrypt':'true',
'lang':'cn',
'name':'TESTDBAVsRM',
'password':'HLLWA8ATwKqvLWn94opBBB3ynOBrVKXXX'
}
request = urllib.request.Request(url,headers=headers)
respose = opener.open(request,data=urllib.parse.urlencode(data).encode())
return opener
#完成cookie值获取完成。 def get_all_vm_id(opener):
#获取地址池中的所有虚拟机id
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36'}
pool_vm = list()
aa=0
#drl1:8 ty1:10 ty2:11 ty3:12 ty4:14
pool_url="http://x.x.x.x:8080/cas/casrs/vm/vmList?hpId=14"
pool_vm_list_request = urllib.request.Request(pool_url,headers=headers)
pool_vm_list_respose = opener.open(pool_vm_list_request).read()
pool_vm_list_respose_utf = pool_vm_list_respose.decode("utf-8","ignore")
#pat_vm='<id>(.*?)</id>'
pat_vm='<domain>*<id>(.*?)</id>'
pool_all_vm_list=re.compile(pat_vm).findall(pool_vm_list_respose_utf)
for j in pool_all_vm_list:
pool_vm.append(j)
aa=aa+1
#print(pool_vm)
print("一共有虚拟机:",aa)
return pool_vm #获取主机ip地址
#传入虚拟机ID号列表和opener数据。输出id和ip地址组成字典。
def get_vm_ip(pool_vm,opener):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36'}
machine_id_ip_dir =dict()
pat_vm_ip='<ipAddr>(.*?)</ipAddr>'
for vm_id in pool_vm:
vm_info_url ='http://X.X.X.X:8080/cas/casrs/vm/network/'+str(vm_id)
vm_info_request = urllib.request.Request(vm_info_url,headers=headers)
vm_info_respose = opener.open(vm_info_request).read()
vm_info_respose_utf = vm_info_respose.decode("utf-8","ignore")
vm_info_ip=re.compile(pat_vm_ip).findall(vm_info_respose_utf)
#print("this id number:",vm_id)
if len(vm_info_ip) == 0:
machine_id_ip_dir[vm_id] = 'not values'
#print("this id machine ip null,not install tools .")
else:
machine_id_ip_dir[vm_id] = vm_info_ip[0]
#print("this machine ip address:",vm_info_ip[0])
#print("this id_ip_dir values:",machine_id_ip_dir);
return machine_id_ip_dir #获取主机特定的信息
def get_vm_info(vm_id,opener):
#定义一个保存虚拟机信息的列表
vm_info_n_dict=dict()
global dict_vm_info
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36'}
#定义正则匹配规则
pat_vm_cpu='<cpuRate>(.*?)</cpuRate>'
pat_vm_mem='<memRate>(.*?)</memRate>'
pat_vm_stat='<status>(.*?)</status>'
pat_vm_uptime='<uptime>(.*?)</uptime>'
pat_vm_net_r='<net>.*<readFlow>(.*?)</readFlow>'
pat_vm_net_r_pack='<net>.*<readPackets>(.*?)</readPackets>'
pat_vm_net_w='<net>.*<writeFlow>(.*?)</writeFlow>'
pat_vm_net_w_pack='<net>.*<writePackets>(.*?)</writePackets>' #定义获取磁盘信息正则匹配规则
pat_vm_disk_Mbps='<disk>.*<ioStat>(.*?)</ioStat>'
pat_vm_disk_r_Mbps='<disk>.*<readStat>(.*?)</readStat>'
pat_vm_disk_w_Mbps='<disk>.*<writeStat>(.*?)</writeStat>'
pat_vm_disk_r_ps='<disk>.*<readReqest>(.*?)</readReqest>'
pat_vm_disk_w_ps='<disk>.*<writeReqest>(.*?)</writeReqest>' #获取指定的ID的虚拟机的监控信息。
vm_xx_info_url = 'http://X.X.X.X:8080/cas/casrs/vm/id/'+str(vm_id)+'/monitor'
vm_xx_info_request = urllib.request.Request(vm_xx_info_url,headers=headers)
vm_xx_info_respose = opener.open(vm_xx_info_request).read()
vm_xx_info_respose_utf = vm_xx_info_respose.decode("utf-8","ignore") #正则表达式匹配,定义的数据。
#cpu及内存状态启动时间等数据
vm_info_cpu=re.compile(pat_vm_cpu).findall(vm_xx_info_respose_utf)
vm_info_mem=re.compile(pat_vm_mem).findall(vm_xx_info_respose_utf)
vm_info_stat=re.compile(pat_vm_stat).findall(vm_xx_info_respose_utf)
vm_info_uptime=re.compile(pat_vm_uptime).findall(vm_xx_info_respose_utf)
#主机网卡信息
vm_info_net_r=re.compile(pat_vm_net_r).findall(vm_xx_info_respose_utf)
vm_info_net_r_p=re.compile(pat_vm_net_r_pack).findall(vm_xx_info_respose_utf)
vm_info_net_w=re.compile(pat_vm_net_w).findall(vm_xx_info_respose_utf)
vm_info_net_w_p=re.compile(pat_vm_net_w_pack).findall(vm_xx_info_respose_utf)
#磁盘信息
vm_info_disk_Mbps=re.compile(pat_vm_disk_Mbps).findall(vm_xx_info_respose_utf)
vm_info_disk_r_Mbps=re.compile(pat_vm_disk_r_Mbps).findall(vm_xx_info_respose_utf)
vm_info_disk_w_Mbps=re.compile(pat_vm_disk_w_Mbps).findall(vm_xx_info_respose_utf)
vm_info_disk_r_ps=re.compile(pat_vm_disk_r_ps).findall(vm_xx_info_respose_utf)
vm_info_disk_w_ps=re.compile( pat_vm_disk_w_ps).findall(vm_xx_info_respose_utf) #print("单个字典为",vm_info_n_dict)
#判断如果匹配到多个值,就只获取第一个值哈哈哈哈。简单才是王道 好耶
#赋值CPU信息
if len(vm_info_cpu) > 1:
vm_info_n_dict['cpu_rate']=vm_info_cpu[0]
else:
vm_info_n_dict['cpu_rate']=vm_info_cpu
#赋值内存信息
if len(vm_info_mem) > 1:
vm_info_n_dict['mem_rate']=vm_info_mem[0]
else:
vm_info_n_dict['mem_rate']=vm_info_mem
#赋值主机状态信息
if len(vm_info_stat) > 1:
vm_info_n_dict['vm_stat']=vm_info_stat[0]
else:
vm_info_n_dict['vm_stat']=vm_info_stat
#赋值网络读流量值
if len(vm_info_net_r) > 1:
vm_info_n_dict['net_r']=vm_info_net_r[0]
else:
vm_info_n_dict['net_r']=vm_info_net_r
#赋值网络读包数量
if len(vm_info_net_r_p) > 1:
vm_info_n_dict['net_r_p']=vm_info_net_r_p[0]
else:
vm_info_n_dict['net_r_p']=vm_info_net_r_p
#赋值网络写流量
if len(vm_info_net_w) > 1:
vm_info_n_dict['net_w']=vm_info_net_w[0]
else:
vm_info_n_dict['net_w']=vm_info_net_w
#赋值网络包写数量
if len(vm_info_net_w_p) > 1:
vm_info_n_dict['net_w_p']=vm_info_net_w_p[0]
else:
vm_info_n_dict['net_w_p']=vm_info_net_w_p
#赋值磁盘总吞吐量
if len(vm_info_disk_Mbps) > 1:
vm_info_n_dict['io_mbps']=vm_info_disk_Mbps[0]
else:
vm_info_n_dict['io_mbps']=vm_info_disk_Mbps
#赋值磁盘读速率
if len(vm_info_disk_r_Mbps) > 1:
vm_info_n_dict['io_r_mbps']=vm_info_disk_r_Mbps[0]
else:
vm_info_n_dict['io_r_mbps']=vm_info_disk_r_Mbps
#赋值磁盘写速率
if len(vm_info_disk_w_Mbps) > 1:
vm_info_n_dict['io_w_mpbs']=vm_info_disk_w_Mbps[0]
else:
vm_info_n_dict['io_w_mpbs']=vm_info_disk_w_Mbps
#赋值磁盘读ps
if len(vm_info_disk_r_ps) > 1:
vm_info_n_dict['io_r_iops']=vm_info_disk_r_ps[0]
else:
vm_info_n_dict['io_r_iops']=vm_info_disk_r_ps
#赋值磁盘写ps
if len(vm_info_disk_w_ps) > 1:
vm_info_n_dict['io_w_iops']=vm_info_disk_w_ps[0]
else:
vm_info_n_dict['io_w_iops']=vm_info_disk_w_ps
#把单个字典以vm_id为key加入到全局字典中。
dict_vm_info[vm_id]=vm_info_n_dict
#print("测试全局变量:",dict_vm_info) def main():
#主函数调用
#global dict_vm_info
#dict_vm_info['111']="test1111"
opener = get_cas_session()
pool_vm = get_all_vm_id(opener)
id_ip_dict = get_vm_ip(pool_vm,opener)
#print("主机id号字典:",pool_vm)
#print("主机ip地址字典:",id_ip_dict) #测试多线程
str_len = len(pool_vm)
#定义线程数量,不要超过str_len字符串长度
thr_num=20
dict1=dict()
thread_num(str_len,thr_num,pool_vm,opener)
print('数据获取完毕,关闭opener连接..........................')
opener.close()
print('整合获取到的数据并入库................................')
#print("最后的字典是:", dict_vm_info)
into_vminfo_db(pool_vm,id_ip_dict,dict_vm_info)
print('cas平台虚拟机监控信息采集入库完成。') def func(arg,test_str,opener):
#线程掉用子函数
for i in arg:
#print(threading.currentThread().name, "----", i+1)
print("实际值为:",test_str[i])
get_vm_info(test_str[i],opener) def thread_num(total,num,test_str,opener):
#线程执行程序函数
result=numpy.array_split(range(total),num) #分段
for i in result:
#print("此时i的值为:",i)
t=threading.Thread(target=func,args=(i,test_str,opener,)) #声明线程
t.start() #启动线程
while threading.active_count()!=1: #等待子线程
pass def into_vminfo_db(pool_vm,id_ip_dict,vm_info_dict):
#数据入库函数
ticks = time.time()
db = pymysql.connect("127.0.0.1","cas","Cas_123456#","cas_info")
cursor = db.cursor()
for i in pool_vm:
sql="insert into cas_trend(vm_id,vm_ip,cpu_rate,mem_rate,vm_stat,net_r,net_r_p,net_w,net_w_p,io_mbps,io_r_mbps,io_w_mpbs,io_r_iops,io_w_iops,timestamp) values(\'" + str(i) +"\',\'" + str(id_ip_dict[i]) +"\',\'"+ str(dict_vm_info[i]["cpu_rate"]).lstrip('[\'').rstrip('\']') +"\',\'"+ str(dict_vm_info[i]["mem_rate"]).lstrip('[\'').rstrip('\']') +"\',\'"+ str(dict_vm_info[i]["vm_stat"]).lstrip('[\'').rstrip('\']') +"\',\'"+str(dict_vm_info[i]["net_r"]).lstrip('[\'').rstrip('\']') +"\',\'"+str(dict_vm_info[i]["net_r_p"]).lstrip('[\'').rstrip('\']') +"\',\'"+str(dict_vm_info[i]["net_w"]).lstrip('[\'').rstrip('\']') +"\',\'"+ str(dict_vm_info[i]["net_w_p"]).lstrip('[\'').rstrip('\']') +"\',\'"+ str(dict_vm_info[i]["io_mbps"]).lstrip('[\'').rstrip('\']') +"\',\'"+str(dict_vm_info[i]["io_r_mbps"]).lstrip('[\'').rstrip('\']') +"\',\'"+str(dict_vm_info[i]["io_w_mpbs"]).lstrip('[\'').rstrip('\']') +"\',\'"+str(dict_vm_info[i]["io_r_iops"]).lstrip('[\'').rstrip('\']') +"\',\'"+str(dict_vm_info[i]["io_w_iops"]).lstrip('[\'').rstrip('\']') +"\',\'"+ str(ticks) + "\')"
print("此时sql语句为:",sql)
try:
cursor.execute(sql)
db.commit()
except:
db.rollback()
db.close() if __name__ == "__main__":
dict_vm_info=dict()
lock = threading.Lock()
count = 0
main()
结果
命令执行结果
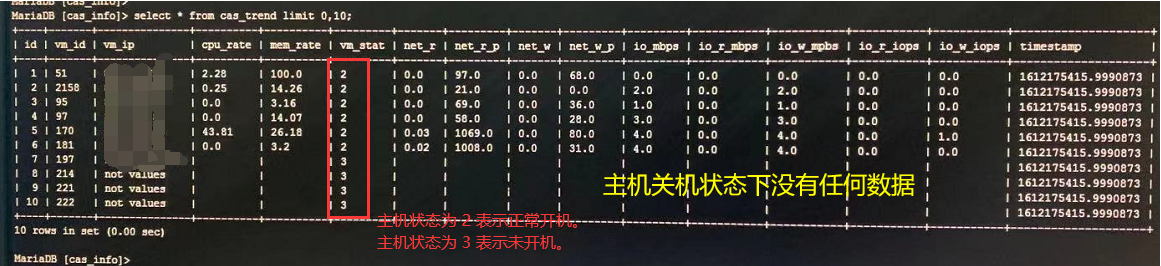
数据库结果展示
Python3对接华三CAS平台Api获取虚拟机监控信息-渐入佳境的更多相关文章
- PHP通过Zabbix API获取服务器监控信息
开源监控系统Zabbix提供了丰富的API,供第三方系统调用. 基本步骤如下: 1.获取合法认证:连接对应Zabbix URL,并提供用户名和密码,HTTP方法为"POST",HT ...
- Java对接拼多多开放平台API(加密上云等全流程)
前言 本文为[小小赫下士 blog]原创,搬运请保留本段,或请在醒目位置设置原文地址和原作者. 作者:小小赫下士 原文地址:Java对接拼多多开放平台API(加密上云等全流程) 本文章为企业ERP(I ...
- 04:获取zabbix监控信息
目录:Django其他篇 01: 安装zabbix server 02:zabbix-agent安装配置 及 web界面管理 03: zabbix API接口 对 主机.主机组.模板.应用集.监控项. ...
- .Net Web Api——获取client浏览器信息
第一次接触到web api,发现这个东西是REST风格的:---- 微软的web api是在vs2012上的mvc4项目绑定发行的.它提出的web api是全然基于RESTful标准的,全然不同于之前 ...
- 调用打码平台api获取验证码 (C#版)
一.打码平台很多,这里选择两个:联众和斐斐 联众开发文档: https://www.jsdati.com/docs/guide 斐斐开发文档: http://docs.fateadm.com/web/ ...
- .Net Core+Angular6 学习 第三部分(从api获取data)
. 现在开始需要集成angular6到VS项目中 1.1 打开Startup.cs文件, 在ConfigureServices方法中配置angular files的目录. 1.2 在Configure ...
- JS通过百度地图API获取当前定位信息
$(function(){ var latlon=null; //ajax获取用户所在经纬度 $.ajax({ url:"http://api.map.baidu.com/location/ ...
- WIN32 API 获取文件版本信息
CString strVersion; CString strPath(_T("xxxxxxxx.exe")); // 读文件信息 DWORD dwVerHnd = 0; DWOR ...
- 通过API获取统计信息时报Access denied错误处理记录
通过API获取HDFS统计信息时报Access denied错误信息,错误信息如下: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.s ...
随机推荐
- VC++线程同步之临界区(CriticalSection)
1.相关文件和接口 #include <windows.h> CRITICAL_SECTION cs;//定义临界区对象 InitializeCriticalSection(&cs ...
- Java编程中标识符注意点以及注释
标识符注意点 所有的标识符都应该以字母(A-Z或者a-z),美元符($),或者下划线(_)开始 首字符之后可以是字母(A-Z或者a-z),美元符($),下划线(_)或数 字的任何字符组合 不能使用关键 ...
- 使用 Frp 和 Docker 通过远程桌面和 SSH 来远程控制 Windows(反向代理)
最新博客文章链接 大体思路 使用 Docker 容器,在云服务器上部署 Frps 容器来中转流量,在被控制的 Windows 上部署 Frpc 容器来暴露内网的服务,在主控制端的 Windows 上直 ...
- CF388C Fox and Card Game
基于观察可以发现,双方都一定能保证取到每一列靠近自己的 \(\lfloor \frac{k}{2} \rfloor\) 个元素. 那么一旦一个人想要取另一个人能必然能取的部分,另一个人必然可以不让其取 ...
- VMware14安装windows7的详细过程
感谢大佬:https://blog.csdn.net/u012230668/article/details/81701893 一.安装VMware虚拟机,以及下载一份ghost win7系统 下载地址 ...
- 深入解析HashMap、HashTable (转)
集合类之番外篇:深入解析HashMap.HashTable Java集合类是个非常重要的知识点,HashMap.HashTable.ConcurrentHashMap等算是集合类中的重点,可谓&quo ...
- 导出SQL语句
转载请注明来源:https://www.cnblogs.com/hookjc/ if(!($db_conn=mysql_connect($db_server,$db_name,$db_pass))){ ...
- 为hade增加model自动生成功能
大家好,我是轩脉刃. 我们写业务的时候和db接触是少不了的,那么要生成model也是少不了的,如何自动生成model,想着要给hade框架增加个这样的命令. 看了下网上的几个开源项目,最终聚焦在两个项 ...
- 使用VMware安装win10虚拟机
(1)打开VMware: (2)打开左上角的文件,点击新建虚拟机: (3)选择典型,下一步: (4)选择稍后安装操作系统,下一步: (5)选择win10×64,下一步: (6)可随意修改虚拟机名称,位 ...
- Solution Set -「LOCAL」冲刺省选 Round XXIII
\(\mathscr{Summary}\) 有一说一,虽然我炸了,但这场锻炼心态的效果真的好.部分分聊胜于无,区分度一题制胜,可谓针对性强的好题. A 题,相对性签到题.这个建图确实巧妙,多见 ...