残差网络resnet理解与pytorch代码实现
写在前面
深度残差网络(Deep residual network, ResNet)自提出起,一次次刷新CNN模型在ImageNet中的成绩,解决了CNN模型难训练的问题。何凯明大神的工作令人佩服,模型简单有效,思想超凡脱俗。
直观上,提到深度学习,我们第一反应是模型要足够“深”,才可以提升模型的准确率。但事实往往不尽如人意,先看一个ResNet论文中提到的实验,当用一个平原网络(plain network)构建很深层次的网络时,56层的网络的表现相比于20层的网络反而更差了。说明网络随着深度的加深,会更加难以训练。
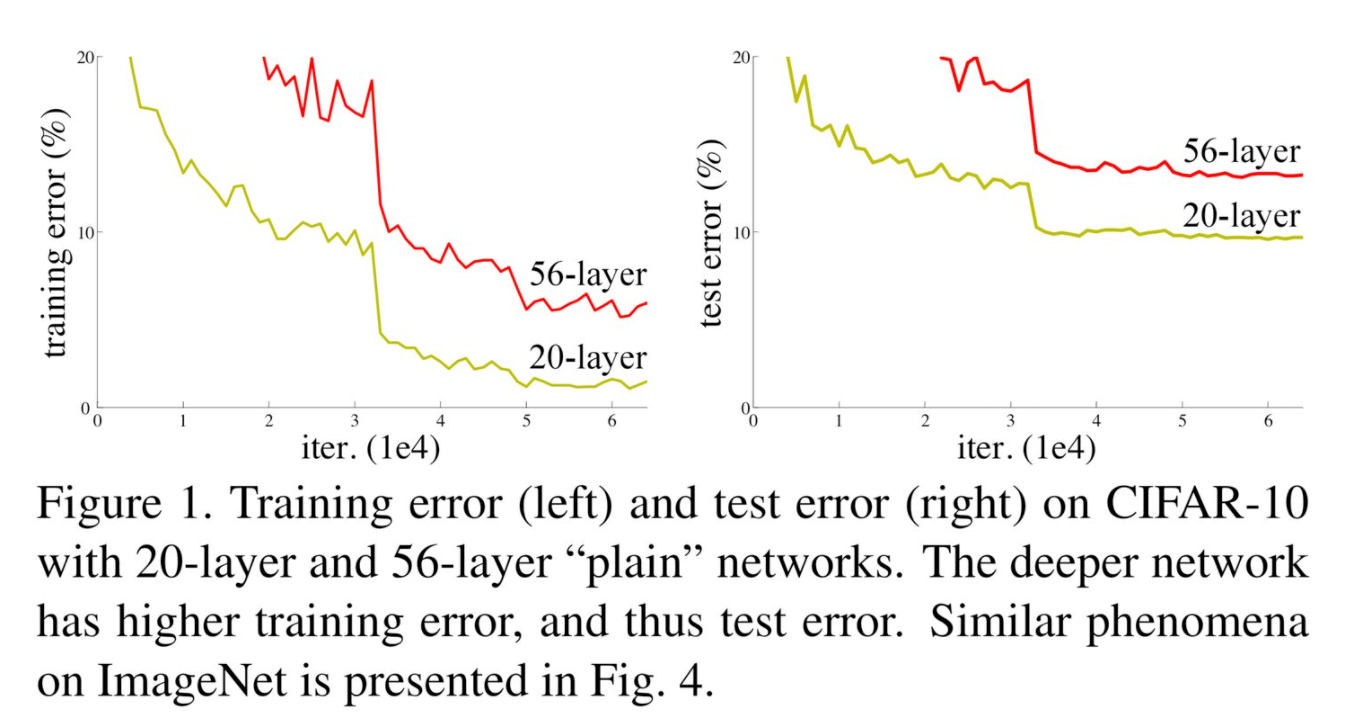
图一:模型退化问题
若模型随着网络深度的增加,准确率先上升,然后达到饱和,深度增加准确率下降。那么如果在模型达到饱和时,后面接上几个恒等变换层,这样可以保证误差不会增加,resnet便是这种思想来解决网络退化问题。
第一部分
模型
假设网络的输入是x, 期望输出为H(x),我们转化一下思路,把网络要学到的H(x)转化为期望输出H(x)与输出x之间的差值F(x) = H(x) - x。当残差接近为0时, 相当于网络在此层仅仅做了恒等变换,而不会使网络的效果下降。
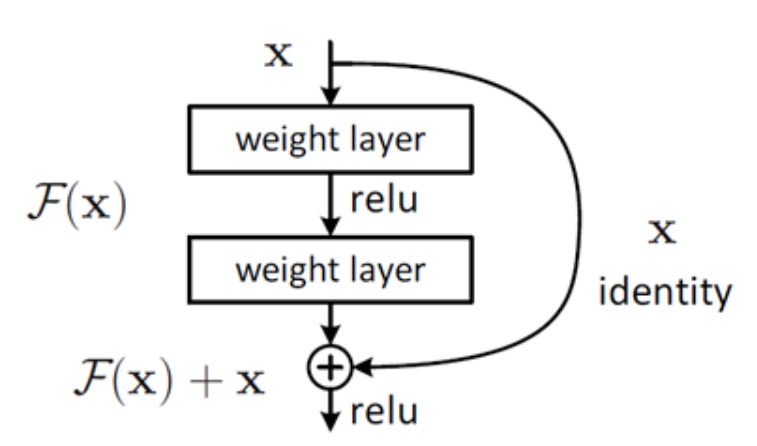
图二:残差结构
残差为什么容易学习?
此处参考一位知乎大佬的分析(原文在文末有链接),因为网络要学习的残差项通常比较小:
其中 和
分别表示的是第
个残差单元的输入和输出,注意每个残差单元一般包含多层结构。
是残差函数,表示学习到的残差,而
表示恒等映射,
是ReLU激活函数。基于上式,我们求得从浅层
到深层
的学习特征为:
利用链式规则,可以求得反向过程的梯度:
式子的第一个因子 表示的损失函数到达
的梯度,小括号中的1表明短路机制可以无损地传播梯度,而另外一项残差梯度则需要经过带有weights的层,梯度不是直接传递过来的。残差梯度不会那么巧全为-1,而且就算其比较小,有1的存在也不会导致梯度消失。所以残差学习会更容易。要注意上面的推导并不是严格的证明。
深度残差网络结构如下:
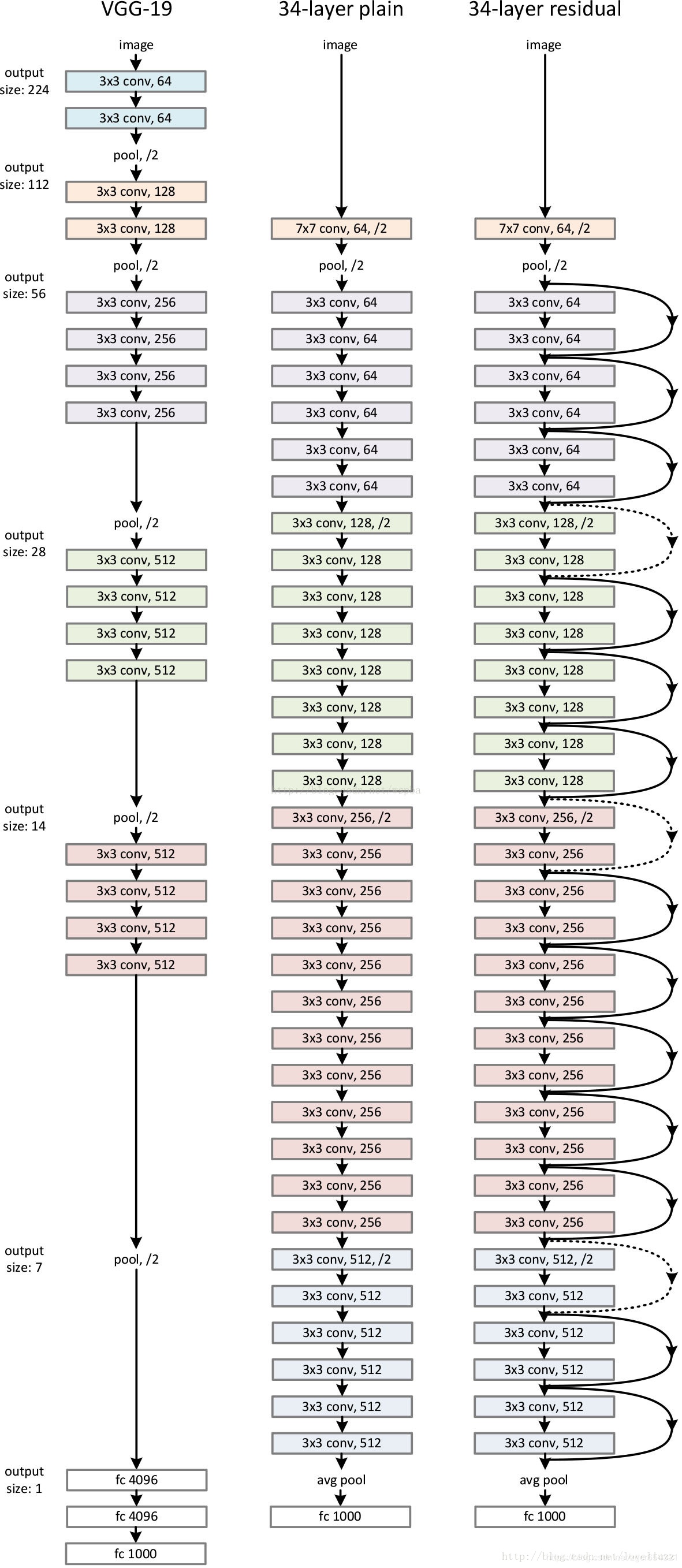
第二部分
pytorch代码实现
# -*- coding:utf-8 -*-
# handwritten digits recognition
# Data: MINIST
# model: resnet
# date: 2021.10.8 14:18
import math
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.utils.data as Data
import torch.optim as optim
import pandas as pd
import matplotlib.pyplot as plt
train_curve = []
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# param
batch_size = 100
n_class = 10
padding_size = 15
epoches = 10
train_dataset = torchvision.datasets.MNIST('./data/', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = torchvision.datasets.MNIST('./data/', train=False, transform=transforms.ToTensor(), download=False)
train = Data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=5)
test = Data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False, num_workers=5)
def gelu(x):
"Implementation of the gelu activation function by Hugging Face"
return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
class ResBlock(nn.Module):
# 残差块
def __init__(self, in_size, out_size1, out_size2):
super(ResBlock, self).__init__()
self.conv1 = nn.Conv2d(
in_channels = in_size,
out_channels = out_size1,
kernel_size = 3,
stride = 2,
padding = padding_size
)
self.conv2 = nn.Conv2d(
in_channels = out_size1,
out_channels = out_size2,
kernel_size = 3,
stride = 2,
padding = padding_size
)
self.batchnorm1 = nn.BatchNorm2d(out_size1)
self.batchnorm2 = nn.BatchNorm2d(out_size2)
def conv(self, x):
# gelu效果比relu好呀哈哈
x = gelu(self.batchnorm1(self.conv1(x)))
x = gelu(self.batchnorm2(self.conv2(x)))
return x
def forward(self, x):
# 残差连接
return x + self.conv(x)
# resnet
class Resnet(nn.Module):
def __init__(self, n_class = n_class):
super(Resnet, self).__init__()
self.res1 = ResBlock(1, 8, 16)
self.res2 = ResBlock(16, 32, 16)
self.conv = nn.Conv2d(
in_channels = 16,
out_channels = n_class,
kernel_size = 3,
stride = 2,
padding = padding_size
)
self.batchnorm = nn.BatchNorm2d(n_class)
self.max_pooling = nn.AdaptiveAvgPool2d(1)
def forward(self, x):
# x: [bs, 1, h, w]
# x = x.view(-1, 1, 28, 28)
x = self.res1(x)
x = self.res2(x)
x = self.max_pooling(self.batchnorm(self.conv(x)))
return x.view(x.size(0), -1)
resnet = Resnet().to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.SGD(params=resnet.parameters(), lr=1e-2, momentum=0.9)
# train
total_step = len(train)
sum_loss = 0
for epoch in range(epoches):
for i, (images, targets) in enumerate(train):
optimizer.zero_grad()
images = images.to(device)
targets = targets.to(device)
preds = resnet(images)
loss = loss_fn(preds, targets)
sum_loss += loss.item()
loss.backward()
optimizer.step()
if (i+1)%100==0:
print('[{}|{}] step:{}/{} loss:{:.4f}'.format(epoch+1, epoches, i+1, total_step, loss.item()))
train_curve.append(sum_loss)
sum_loss = 0
# test
resnet.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in test:
images = images.to(device)
labels = labels.to(device)
outputs = resnet(images)
_, maxIndexes = torch.max(outputs, dim=1)
correct += (maxIndexes==labels).sum().item()
total += labels.size(0)
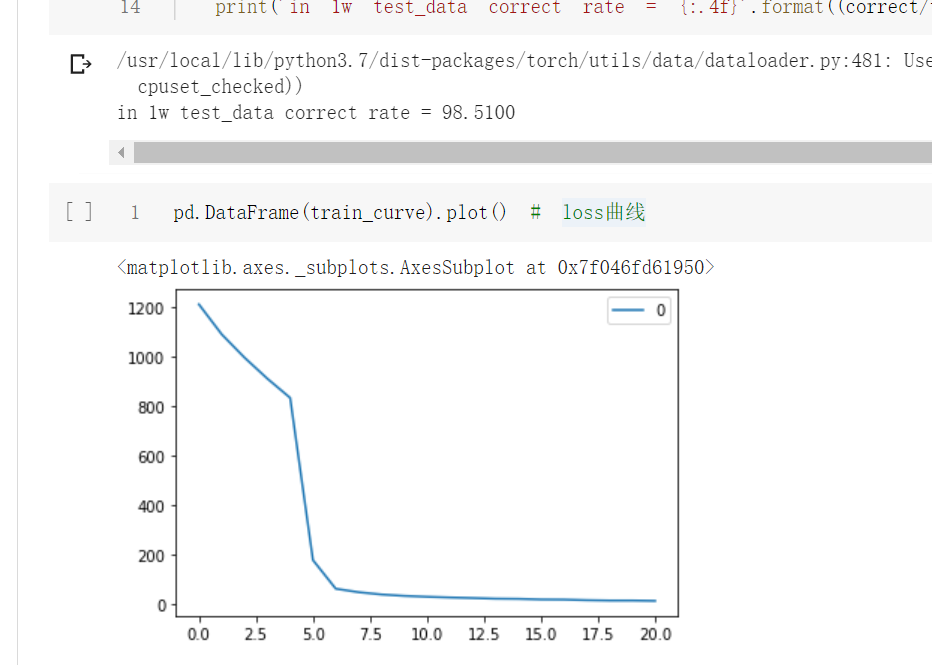
print('in 1w test_data correct rate = {:.4f}'.format((correct/total)*100))
pd.DataFrame(train_curve).plot() # loss曲线
测试了1万条测试集样本结果:
代码链接:
jupyter版本:https://github.com/PouringRain/blog_code/blob/main/deeplearning/resnet.ipynb
py版本:https://github.com/PouringRain/blog_code/blob/main/deeplearning/resnet.py
喜欢的话,给萌新的github仓库一颗小星星哦……^ _^
参考资料:
https://zhuanlan.zhihu.com/p/31852747
https://zhuanlan.zhihu.com/p/80226180
残差网络resnet理解与pytorch代码实现的更多相关文章
- 从头学pytorch(二十):残差网络resnet
残差网络ResNet resnet是何凯明大神在2015年提出的.并且获得了当年的ImageNet比赛的冠军. 残差网络具有里程碑的意义,为以后的网络设计提出了一个新的思路. googlenet的思路 ...
- 深度学习——手动实现残差网络ResNet 辛普森一家人物识别
深度学习--手动实现残差网络 辛普森一家人物识别 目标 通过深度学习,训练模型识别辛普森一家人动画中的14个角色 最终实现92%-94%的识别准确率. 数据 ResNet介绍 论文地址 https:/ ...
- 深度残差网络(ResNet)
引言 对于传统的深度学习网络应用来说,网络越深,所能学到的东西越多.当然收敛速度也就越慢,训练时间越长,然而深度到了一定程度之后就会发现越往深学习率越低的情况,甚至在一些场景下,网络层数越深反而降低了 ...
- 深度残差网络——ResNet学习笔记
深度残差网络—ResNet总结 写于:2019.03.15—大连理工大学 论文名称:Deep Residual Learning for Image Recognition 作者:微软亚洲研究院的何凯 ...
- 使用dlib中的深度残差网络(ResNet)实现实时人脸识别
opencv中提供的基于haar特征级联进行人脸检测的方法效果非常不好,本文使用dlib中提供的人脸检测方法(使用HOG特征或卷积神经网方法),并使用提供的深度残差网络(ResNet)实现实时人脸识别 ...
- 残差网络ResNet笔记
发现博客园也可以支持Markdown,就把我之前写的博客搬过来了- 欢迎转载,请注明出处:http://www.cnblogs.com/alanma/p/6877166.html 下面是正文: Dee ...
- CNN卷积神经网络_深度残差网络 ResNet——解决神经网络过深反而引起误差增加的根本问题,Highway NetWork 则允许保留一定比例的原始输入 x。(这种思想在inception模型也有,例如卷积是concat并行,而不是串行)这样前面一层的信息,有一定比例可以不经过矩阵乘法和非线性变换,直接传输到下一层,仿佛一条信息高速公路,因此得名Highway Network
from:https://blog.csdn.net/diamonjoy_zone/article/details/70904212 环境:Win8.1 TensorFlow1.0.1 软件:Anac ...
- 残差网络resnet学习
Deep Residual Learning for Image Recognition 微软亚洲研究院的何凯明等人 论文地址 https://arxiv.org/pdf/1512.03385v1.p ...
- 深度残差网络(DRN)ResNet网络原理
一说起“深度学习”,自然就联想到它非常显著的特点“深.深.深”(重要的事说三遍),通过很深层次的网络实现准确率非常高的图像识别.语音识别等能力.因此,我们自然很容易就想到:深的网络一般会比浅的网络效果 ...
随机推荐
- [SWMM]出现问题及解决
1,节点顺序 [错误]:如下图,在SWMM软件中普通节点到出水口的连接线不能正常连接,提示找不到出水口节点,但在inp文件中是存在的! [解决]:需要先写入点节点再写入线节点,即先写入[JUNCTIO ...
- docker下gitlab(redis)安装配置使用(完整版)
ps:如果是云主机,需添加安全组开放相应端口(关联相应实例),防火墙开放端口或直接关闭 https://www.jianshu.com/p/080a962c35b6 将其中external_url换为 ...
- ProjectEuler 005题
题目: 2520 is the smallest number that can be divided by each of the numbers from 1 to 10 without any ...
- 刷题-力扣-264. 丑数 II
264. 丑数 II 题目链接 来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/ugly-number-ii/ 著作权归领扣网络所有.商业转载请 ...
- 两种方式配置vue全局方法
目录 1,前言 2,第一种方式 3,第二种方式 1,前言 在Vue项目开发中,肯定会有这样一个场景:在不同的组件页面用到同样的方法,比如格式化时间,文件下载,对象深拷贝,返回数据类型,复制文本等等.这 ...
- JS边角料: NodeJS+AutoJS+WebSocket+TamperMonkey实现局域网多端文字互传
---阅读时间约 7 分钟,复现时间约 15 分钟--- 由于之前一直在用的扩展 QPush 停止服务了,苦于一人凑齐了 Window, Android, Mac, ios 四种系统的设备,Apple ...
- VUE006. 前端跨域代理服务器ProxyTable概述与配置
概述 使用 vue-cli 工具生成一个 vue 项目: vue init webpack my-project-vue 在生成的项目结构里,会有一个 index.js 文件.在这个文件里 ...
- 配置IIS Express 允许外部访问
修改applicationhost.config 配置允许外部访问 操作步骤: 1. 查看本机IP地址记录IP地址,例如:10.1.20.138 2. 如下图,找到要发布的站点的名称 记录站点的名称, ...
- MAC地址知识
1. 全球唯一无法保障. 软件工具可以修改网卡的MAC地址 2.不需要全球唯一. 只要保障局域网内不重复就行. 路由器 保证 数据在不同局域网内跳转. 如果局域网内使用集线器,那么可以设置相 ...
- djang2.1教育平台02
在次申明,之所以重做这个资料是因为原幕课教程漏洞太多,新手根本没有办法正常照些学习,我凭着老男孩python 课程基础,重做这个教程 ,更改版本为当前最新版本,为了方法以后的人学习,并不是照着原文照 ...