[算法] 数据结构 splay(伸展树)解析
前言
splay学了已经很久了,只不过一直没有总结,鸽了好久来写一篇总结。
先介绍 splay:亦称伸展树,为二叉搜索树的一种,部分操作能在 \(O( \log n)\) 内完成,如插入、查找、删除、查询序列第 \(k\) 大、查询前缀(比查询的数小的数中最大的数)、查询后缀(比查询的数大的数中最小的数)等操作,甚至能够实现区间平移。它由 Daniel Sleator 和 Robert Endre Tarjan 在1985年发明的。注:时间复杂度是均摊为 \(O(\log n)\) ,是经过严谨的证明的,单个操作可能退化成 \(O(n)\) 。
算法思想
先做一个小小的引入:输入法中,你经常使用词语,会在词条中靠前的位置。实现过程可以使用 splay。
splay 是二叉搜索树的一种,这里简单介绍一下二叉搜索树。
对于一棵二叉树,满足树上任意节点,它的左子树上任意节点满足比当前节点的权值小,右子树上任意节点的权值比当前节点的权值大。则称这棵树为二叉搜索树。
可以利用二叉搜索树的性质来进行操作,比当前节点的权值小就在左子树查找,权值大就在右子树查找。
理想状态下,若该二叉树为一颗完全二叉树,则单次操作时间复杂度为 \(O(\log n)\) 。但这颗二叉树可能退化成一条链,这样单次时间复杂度为 \(O(n)\) 。
splay 树在这上面进行了改进,通过不断改变树的形态来保证不会退化,均摊时间复杂度为 \(O(\log n)\) 。基本思想是把搜索频率高的点放在深度小的位置,为了操作方便,可以认为每次操作的点都是频率高的。常常把操作的点,或是操作区间的两个端点放在根或根的附近的位置,那么会涉及到旋转操作。
根据势能函数分析(我不会),splay 的时间复杂度上限为 \(O((m+n)\log n)\) ,但这个上限是有波动的。
基本操作
建议配合注释一起使用。
结构体中应包含以下信息:
struct Splay_Node {
int son[2], val, cnt, siz, fa;
//分别是:两个儿子,权值,副本数,子树大小,父亲节点
#define ls t[pos].son[0] //宏定义左儿子,方便一些
#define rs t[pos].son[1] //右儿子,同上
};
简单说明一下,副本数为权值为 val 的数的个数。
New
开辟新节点,里面的值随需求变化,以下是几个重要的值。
int New(int val, int fa) {
t[++tot].fa = fa, t[tot].cnt = t[tot].siz = 1, t[tot].val = val;
return tot;
}
Build
建立splay树,将极小值置为根节点,极大值作为根节点的右儿子,满足二叉搜索树的性质,代码:
void Build() {
root = New(-INF, 0); //极小值为根节点
t[root].son[1] = New(INF, root); //极大值为右儿子
}
写这段代码的主要原因是:使得 splay 的每个节点不会爆掉边界,否则很容易就 RE 。
Ident
判断该节点为父节点的左儿子还是右儿子,左儿子为 \(0\) ,右儿子为 \(1\) 。
bool Ident(int pos) { return t[t[pos].fa].son[1] == pos; }
Update
更新子树大小,还更新节点信息(由需求所定)。
void Update(int pos) {
t[pos].siz = t[ls].siz + t[rs].siz + t[pos].cnt; //子树大小为左右子树大小加上自己的副本数
}
Connect
将一对点变为父子关系。
void Connect(int pos, int fa, int flag) {//依次是:子节点,父节点,哪个儿子
t[fa].son[flag] = pos;//将fa的儿子置为pos
t[pos].fa = fa;//将pos的父亲置为fa
}
Rotate
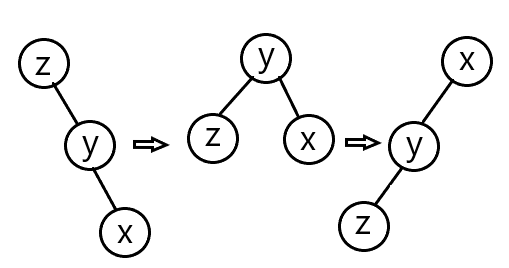
既然要把一个点旋转到根节点,那么就必须先掌握单旋操作,具体分两个情况讨论。
左儿子旋转至父节点

如上图,需要进行几次转换: \(x\) 的左儿子变为 \(y\) 的右儿子, \(y\) 的右儿子变为\(x\) , \(a\) 的子节点变为 \(y\) 。
那么程序可以写为:
void Rotate(int pos) {//这里的flag1=0,可以按照上述的三个转换进行验证这段程序是对的
int fa = t[pos].fa, grand = t[fa].fa;
int flag1 = Ident(pos), flag2 = Ident(fa);
Connect(pos, grand, flag2);
Connect(t[pos].son[flag1 ^ 1], fa, flag1);
Connect(fa, pos, flag1 ^ 1);
Update(fa); Update(pos);
}
右儿子旋转至父节点
可以视为上图的逆操作: \(y\) 的右儿子变为 \(x\) 的左儿子, \(x\) 的左儿子变为\(y\) , \(a\) 的子节点变为 \(x\) 。
那么程序依旧可以写为:
void Rotate(int pos) {//这里的flag1=1,可以按照上述的三个转换进行验证这段程序是对的
int fa = t[pos].fa, grand = t[fa].fa;
int flag1 = Ident(pos), flag2 = Ident(fa);
Connect(pos, grand, flag2);
Connect(t[pos].son[flag1 ^ 1], fa, flag1);
Connect(fa, pos, flag1 ^ 1);
Update(fa); Update(pos);
}
综上所述,Rotate 操作可以不用判断左右节点,写法为上述程序。
Splay
听名字就知道,这是splay树的核心操作。
函数 \(splay(pos,to)\) 定义为:将编号为 \(x\) 的节点,旋转至父亲为 \(to\) 的节点(即 \(to\) 的其中一个子节点,且进行 splay 后依然满足二叉搜索树的性质)。
显然有一种方法:对于当前节点 \(pos\) ,不停进行 \(Rotate(pos)\) ,知道 \(pos\) 的父节点为 \(to\) 为止。
但是这并不能使该 splay 树的形态发生太大的改变。splay 的目的是改变树的形态,有一种改进的方法:双旋。顺带说明一下,单旋会被卡成 \(O(nm)\) 。(具体我也不知道怎么卡)
双旋即一次旋转两次,设当前点为 \(x\) ,父亲节点为 \(y\) ,爷爷为 \(z\) 。具体分为两种情况,这里只证明正确性。
x、y、z 形成一条链
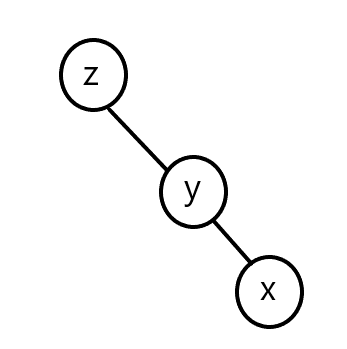
这种情况先单旋 \(y\) 在单旋 \(x\) 。过程见下图:
显然,在上述过程中,严谨地满足了 \(val[x]>val[y]>val[z]\) 。
x、y、z 形成“<”或 “>”
直接进行两次单旋操作,正确性显然。
Code
代码很短,只有三行。
void Splay(int pos, int to) {
for(int fa = t[pos].fa; t[pos].fa != to; Rotate(pos), fa = t[pos].fa)
if(t[fa].fa != to) Ident(pos) == Ident(fa) ? Rotate(fa) : Rotate(pos);
//Ident(pos) == Ident(fa)意味着pos和fa成为了一条链的形状,否则为“<”或“>”。
if(!to) root = pos;//更新根节点,根节点的父亲值为0
}
总结
这些是 splay 的基本操作,之后的所有操作都是建立在这些之上的。
引申操作
Find
定义 \(Find(val)\) :查询权值为 \(val\) 的点的编号,若没有该点就返回 \(0\) 。
利用 splay 为二叉搜索树的性质,若 \(val\) 小于当前节点的权值,则在左子树中查找;若大于则在右子树中查找。知道找到当前节点的编号为 \(0\) 或当前节点的权值等于 \(val\) 的时候返回改点的下标。
int Find(int pos, int val) {
if(!pos) return 0;//空节点直接返回
if(val == t[pos].val) return pos;//等于就直接返回节点编号
else if(val < t[pos].val) return Find(ls, val);//在左子树中查找
else return Find(rs, val);//在右子树中查找
}
Insert
即插入操作, 需要插入权值为 \(val\) 的值。
其思想跟 \(Find\) 函数差不多,利用二叉搜索树的性质直接就可以找到插入的位置。具体分为两类:
- 有权值为 \(val\) 的点 \(pos\) ,直接使得副本数加 \(1\) 即可。
- 没有权值为 \(val\) 的点 \(pos\) ,则开辟一个新的节点权值为 \(val\) 。
注意 \(pos\) 应传实参,因为若开辟了新的节点,其父节点的对应儿子也需要改变。
void Insert(int &pos, int val, int fa) {//pos为实参
if(!pos) Splay(pos = New(val, fa), 0);
else if(val == t[pos].val) { ++t[pos].cnt; Splay(pos, 0); }
else if(val < t[pos].val) Insert(ls, val, pos);
else Insert(rs, val, pos);
}
Erase
即删除操作, \(Erase(val)\) 定义为:删除所维护的序列中权值为 \(val\) 的一个节点(如果有的话)。
可以先找到权值为 \(val\) 的节点并定义其编号为 \(pos\) ,分两种情况。
- 若当前节点的副本数大于 \(1\) 时,即 \(t[pos].cnt>1\) 时,可以删除其中一个副本即可,但并没有删除这个节点。
- 否则,则需要删除该节点。需要先将 \(pos\) splay 到根节点。找到它的前缀的编号 \(l\) 和它的后缀的编号 \(r\) ,则 \(t[l].val\leq val \leq t[r].val\) 。显然, \((t[l].val,t[r].val)\) 区间内的数只有一个,即 \(pos\) 。将 \(l\) splay 至根节点, \(r\) splay 至 \(l\) 的右儿子,则 \(pos\) 必会在 \(r\) 的左儿子处,因为 \(l\) , \(r\) , \(pos\) 必回满足二叉搜索树的性质。然后直接删除 \(r\) 的左儿子即可。
void Erase(int val) {
int pos = Find(root, val);//找到权值为 val 的点。
if(!pos) return;//没有改节点直接返回,没有难倒删空气?
if(t[pos].cnt > 1) { --t[pos].cnt; Splay(pos, 0); return; }//对应情况1
Splay(pos, 0);
int l = ls, r = rs;
while(t[l].son[1]) l = t[l].son[1];//找到前缀
while(t[r].son[0]) r = t[r].son[0];//找到后缀
Splay(l, 0); Splay(r, l);//对应情况2
t[r].son[0] = 0;
}
这里在提供一种做法,与 \(Find\) 函数的做法类似,可以说是其的升级版。总体框架不变,主要是针对第二种情况,将其旋转到根节点在进行删除,这种写法还是比较常见的。
void Erase(int pos, int val) {
if(!pos) return;
if(val == t[pos].val) {
if(t[pos].cnt > 1) { t[pos].cnt--; Splay(pos, 0); return; }
if(ls) Rotate(ls), Erase(pos, val);//有左儿子跟左儿子交换
else if(rs) Rotate(rs), Erase(pos, val);//有右儿子就跟右儿子交换
else {//没有儿子就直接删除,注意必须删除其父亲的对应儿子
int newroot = t[pos].fa;
t[t[pos].fa].son[Ident(pos)] = 0;
Splay(newroot, 0);
}
return;
}
else if(val < t[pos].val) rase(ls, val);
else Erase(rs, val);
}
Query_kth
查询 \(val\) 在序列是第几大的树,即按照从小到大的顺序排序后, \(val\) 的排名,没有 \(val\) 输出返回 \(-1\)。
代码使用递归实现,考虑对于当前节点 \(pos\) ,比 \(val\) 小的数都在左子树内,即有 \(t[ls].siz\) 个树比 \(t[pos].val\) 小。
对于局部解,可以将 \(Querykth(pos,val)\) 函数理解为 \(pos\) 的子树中,小于 \(val\) 的值有多少。
则可以分为三种情况来讨论。
- 当 \(val=t[pos].val\) 时,即找到了该节点,返回比它小的数的个数即可,即左子树的节点数加 \(1\) 。
- 当 \(val<t[pos].val\) 时, \(val\) 左子树中,在左子树中查询该节点的排名。
- 当 \(val>t[pos].val\) 时, 是最麻烦的部分。 \(val\) 右子树中,左子树与当前节点都会为答案做贡献,先将其统计至答案中,在求出右子树对于答案的贡献。
注意,最后的答案是包含了极小值的,所以找到后的答案应该减一,这一部分我写在了主函数里,所以没找到会输出 \(-1\) 。
int Query_kth(int pos, int val) {
if(!pos) return 0;//没有输出-1
if(val == t[pos].val) { int res = t[ls].siz + 1; Splay(pos, 0); return res; }//对应情况1
else if(val < t[pos].val) return Query_kth(ls, val);//对于情况2
//下两行代码对应情况3
int res = t[ls].siz + t[pos].cnt;//找到后splay维护形态会导致子树的大小变化,因此先记录答案
return Query_kth(rs, val) + res;
}
Query_val
查询区间的第 \(k\) 小的数。
可以看做上一个操作的逆操作吧,若 \(k\) 都大于了区间的所有数的个数,就直接返回极大值。
同样,对于局部解,可以将 \(Queryval(pos,k)\) 函数理解为 \(pos\) 的子树中,第 \(k\) 大值为多少。
又可以分为三个情况:
- 当 \(t[ls].siz\geq k\) 时,即所求答案在左子树,在左边查询即可。
- 当 \(t[ls].siz+t[pos].cnt\geq k\) 时, 答案为 \(t[pos].val\) ,因为第 \(t[ls].siz+1\) 小至 \(t[ls].siz+t[pos].cnt\) 的数全部权值都为 \(t[pos].val\) 。
- 否则,答案全部会在右子树当中,查询右子树第 \(k-t[ls].siz-t[pos].cnt\) 大,因为当前节点与左儿子一定比右子树任何一个数小。
同样的需要注意,最后的答案是包含了极小值的,同样这一部分我写在了主函数里,查询的时候需要查询第 \(k+1\) 大的那个数。
int Query_val(int pos, int rank) {
if(!pos) return INF;
if(t[ls].siz >= rank) return Query_val(ls, rank);
else if(t[ls].siz + t[pos].cnt >= rank) { Splay(pos, 0); return t[pos].val; }
return Query_val(rs, rank - t[ls].siz - t[pos].cnt);
}
Get_Pre、Get_Nxt
在 \(Erase\) 操作中提到过,可以使用那样的做法。
亦可使用在文末的代码中稍快的做法,与 \(Find\) 函数相似,这里就不多说了。(其实是不想打字了)
也可以参照这段代码将一些操作写为非递归的写法,会更快一些。
总结
有些细心的同学可能已经发现了,几乎每个操作都有 splay 操作来维护当前树的形态,保证时间复杂度。
C++代码
只是将上述操作拼起来放在一个代码里。
说明一下操作的几种类型:
- 插入 \(x\) 数。
- 删除 \(x\) 数(若有多个相同的数,因只删除一个)。
- 查询 \(x\) 数的排名(排名定义为比当前数小的数的个数 \(+1\) )。
- 查询排名为 \(x\) 的数。
- 求 \(x\) 的前驱(前驱定义为小于 \(x\),且最大的数)。
- 求 \(x\) 的后继(后继定义为大于 \(x\),且最小的数)。
不是特别长,实现的方法也并不困难,打的时候必须得注意,完整没附上注释的代码:
#include <cstdio>
namespace Quick_Function {
template <typename Temp> void Read(Temp &x) {
x = 0; char ch = getchar(); bool op = 0;
while(ch < '0' || ch > '9') { if(ch == '-') op = 1; ch = getchar(); }
while(ch >= '0' && ch <= '9') { x = (x << 1) + (x << 3) + (ch ^ 48); ch = getchar(); }
if(op) x = -x;
}
template <typename T, typename... Args> void Read(T &t, Args &... args) { Read(t); Read(args...); }
template <typename Temp> Temp Max(Temp x, Temp y) { return x > y ? x : y; }
template <typename Temp> Temp Min(Temp x, Temp y) { return x < y ? x : y; }
template <typename Temp> Temp Abs(Temp x) { return x < 0 ? (-x) : x; }
template <typename Temp> void Swap(Temp &x, Temp &y) { x ^= y ^= x ^= y; }
}
using namespace Quick_Function;
#define INF 0x3f3f3f3f
const int MAXN = 1e6 + 5;
int n;
struct Splay_Node {
int son[2], val, cnt, siz, fa;
#define ls t[pos].son[0]
#define rs t[pos].son[1]
};
struct Splay_Tree {
int root, tot;
Splay_Node t[MAXN];
bool Ident(int pos) { return t[t[pos].fa].son[1] == pos; }
int New(int val, int fa) {
t[++tot].fa = fa, t[tot].cnt = t[tot].siz = 1, t[tot].val = val;
return tot;
}
void Build() { root = New(-INF, 0); t[root].son[1] = New(INF, root); }
void Update(int pos) { t[pos].siz = t[ls].siz + t[rs].siz + t[pos].cnt; }
void Connect(int pos, int fa, int flag) { t[fa].son[flag] = pos, t[pos].fa = fa; }
void Rotate(int pos) {
int fa = t[pos].fa, grand = t[fa].fa;
int flag1 = Ident(pos), flag2 = Ident(fa);
Connect(pos, grand, flag2);
Connect(t[pos].son[flag1 ^ 1], fa, flag1);
Connect(fa, pos, flag1 ^ 1);
Update(fa); Update(pos);
}
void Splay(int pos, int to) {
for(int fa = t[pos].fa; t[pos].fa != to; Rotate(pos), fa = t[pos].fa)
if(t[fa].fa != to) Ident(pos) == Ident(fa) ? Rotate(fa) : Rotate(pos);
if(!to) root = pos;
}
int Find(int pos, int val) {
if(!pos) return 0;
if(val == t[pos].val) return pos;
else if(val < t[pos].val) return Find(ls, val);
else return Find(rs, val);
}
void Insert(int &pos, int val, int fa) {
if(!pos) Splay(pos = New(val, fa), 0);
else if(val == t[pos].val) { ++t[pos].cnt; Splay(pos, 0); }
else if(val < t[pos].val) Insert(ls, val, pos);
else Insert(rs, val, pos);
}
void Erase(int val) {
int pos = Find(root, val);
if(!pos) return;
if(t[pos].cnt > 1) { --t[pos].cnt; Splay(pos, 0); return; }
Splay(pos, 0);
int l = ls, r = rs;
while(t[l].son[1]) l = t[l].son[1];
while(t[r].son[0]) r = t[r].son[0];
Splay(l, 0); Splay(r, l);
t[r].son[0] = 0;
}
int Query_kth(int pos, int val) {
if(!pos) return 0;
if(val == t[pos].val) { int res = t[ls].siz + 1; Splay(pos, 0); return res; }
else if(val < t[pos].val) return Query_kth(ls, val);
int res = t[ls].siz + t[pos].cnt;
return Query_kth(rs, val) + res;
}
int Query_val(int pos, int rank) {
if(!pos) return INF;
if(t[ls].siz >= rank) return Query_val(ls, rank);
else if(t[ls].siz + t[pos].cnt >= rank) { Splay(pos, 0); return t[pos].val; }
return Query_val(rs, rank - t[ls].siz - t[pos].cnt);
}
int Get_Pre(int val) {
int pos, res, newroot;
pos = newroot = root;
while(pos) {
if(t[pos].val < val) { res = t[pos].val; pos = rs; }
else pos = ls;
}
Splay(newroot, 0);
return res;
}
int Get_Nxt(int val) {
int pos, res, newroot;
pos = newroot = root;
while(pos) {
if(t[pos].val > val) { res = t[pos].val; pos = ls; }
else pos = rs;
}
Splay(newroot, 0);
return res;
}
};
Splay_Tree tree;
int main() {
tree.Build(); Read(n);
for(int i = 1, opt, x; i <= n; i++) {
Read(opt, x);
if(opt == 1) tree.Insert(tree.root, x, 0);
else if(opt == 2) tree.Erase(x);
else if(opt == 3) printf("%d\n", tree.Query_kth(tree.root, x) - 1);
else if(opt == 4) printf("%d\n", tree.Query_val(tree.root, x + 1));
else if(opt == 5) printf("%d\n", tree.Get_Pre(x));
else printf("%d\n", tree.Get_Nxt(x));
}
return 0;
}
[算法] 数据结构 splay(伸展树)解析的更多相关文章
- 【学时总结】◆学时·VI◆ SPLAY伸展树
◆学时·VI◆ SPLAY伸展树 平衡树之多,学之不尽也…… ◇算法概述 二叉排序树的一种,自动平衡,由 Tarjan 提出并实现.得名于特有的 Splay 操作. Splay操作:将节点u通过单旋. ...
- Splay伸展树学习笔记
Splay伸展树 有篇Splay入门必看文章 —— CSDN链接 经典引文 空间效率:O(n) 时间效率:O(log n)插入.查找.删除 创造者:Daniel Sleator 和 Robert Ta ...
- Splay 伸展树
废话不说,有篇论文可供参考:杨思雨:<伸展树的基本操作与应用> Splay的好处可以快速分裂和合并. ===============================14.07.26更新== ...
- [Splay伸展树]splay树入门级教程
首先声明,本教程的对象是完全没有接触过splay的OIer,大牛请右上角.. 首先引入一下splay的概念,他的中文名是伸展树,意思差不多就是可以随意翻转的二叉树 PS:百度百科中伸展树读作:BoGa ...
- Splay伸展树入门(单点操作,区间维护)附例题模板
Pps:终于学会了伸展树的区间操作,做一个完整的总结,总结一下自己的伸展树的单点操作和区间维护,顺便给未来的自己总结复习用. splay是一种平衡树,[平均]操作复杂度O(nlogn).首先平衡树先是 ...
- Codeforces 675D Tree Construction Splay伸展树
链接:https://codeforces.com/problemset/problem/675/D 题意: 给一个二叉搜索树,一开始为空,不断插入数字,每次插入之后,询问他的父亲节点的权值 题解: ...
- UVA 11922 Permutation Transformer —— splay伸展树
题意:根据m条指令改变排列1 2 3 4 … n ,每条指令(a, b)表示取出第a~b个元素,反转后添加到排列尾部 分析:用一个可分裂合并的序列来表示整个序列,截取一段可以用两次分裂一次合并实现,粘 ...
- 算法数据结构(一)-B树
介绍 B树的目的为了硬盘快速读取数据(降低IO操作次树)而设计的一种平衡的多路查找树.目前大多数据库及文件索引,都是使用B树或变形来存储实现. 目录 为什么B树效率高 B树存储 B树缺点 为什么B树效 ...
- [算法] 数据结构之AVL树
1 .基本概念 AVL树的复杂程度真是比二叉搜索树高了整整一个数量级——它的原理并不难弄懂,但要把它用代码实现出来还真的有点费脑筋.下面我们来看看: 1.1 AVL树是什么? AVL树本质上还是一棵 ...
随机推荐
- JAVAEE_Servlet_20_登录注册功能
实现登录注册功能 注册功能 import javax.servlet.ServletException; import javax.servlet.http.HttpServlet; import j ...
- 数据结构之Queue | 让我们一块来学习数据结构
前面的两篇文章分别介绍了List和Stack,下面让我们一起来学习Queue 数据结构之List | 让我们一块来学习数据结构 数据结构之Stack | 让我们一块来学习数据结构 队列的概况 队列是一 ...
- ubuntu 缺少动态依赖库
起因 困扰我好久的一个报错,终于解决了 之前我一直以为是 python代码的问题,以为是模块相互调引起的报错,忽略了最后一行这个错误 OSError: libGCBase_gcc421_v3_0.so ...
- js收藏展开与隐藏,返回顶部
var a = document.getElementById("more");var b = document.getElementById("moreList&quo ...
- 关于Spring Boot 多数据源的事务管理
自己的一些理解:自从用了Spring Boot 以来,这近乎零配置和"约定大于配置"的设计范式用着确实爽,其实对零配置的理解是:应该说可以是零配置可以跑一个简单的项目,因为Spri ...
- ACM JAVA大数
有的水题自己模拟下大数就过了,有的各种坑,天知道曾经因为大数wa了多少次....自己最近学者用JAVA,下面是自己总结的JAVA常用知识.. 框架 import java.util.Scanner; ...
- VRRP中的上层回的路由
如图,PC1和PC2处于不同网段,他们到AR3都有两条路可以选,现在要让他们到达AR3负载均衡,并且当AR1和 AR2的其中一个路由器挂了之后,他们仍然可以正常到达AR3. 他们去往AR3的VRRP的 ...
- Windows PE 第四章 导入表
第四章 导入表 导入表是PE数据组织中的一个很重要的组成部分,它是为实现代码重用而设置的.通过分析导入表数据,可以获得诸如OE文件的指令中调用了多少外来函数,以及这些外来函数都存在于哪些动态链接库里等 ...
- Windows核心编程 第四章 进程(中)
4.2 CreateProcess函数 可以用C r e a t e P r o c e s s函数创建一个进程: BOOL CreateProcessW( _In_opt_ LPCWSTR lpAp ...
- 攻防世界Web刷题记录(新手区)
攻防世界Web刷题记录(新手区) 1.ViewSource 题如其名 Fn + F12 2.get post 3.robots robots.txt是搜索引擎中访问网站的时候要查看的第一个文件.当一个 ...