大数据学习(15)—— B+树和LSM
这一节介绍数据库存储引擎常用的两种数据结构。作为关系型数据库的代表,MySql的InnoDB使用B+树来存储索引。作为NoSQL的代表,HBase使用的LSM树,我们来看看两者有什么区别。
B+树
B+树是大学数据结构里的内容。要了解什么是B+树,先从简单的开始。
二叉排序树
简单的说,二叉排序树首先是一个二叉树,每个结点最多只有两个分支,每个结点存储一个数据。左子树的所有结点都比父结点小(或相等),右子树的所有结点都比父结点大(或相等)。两个括号里的“或相等”附加说明,只能存在一个。
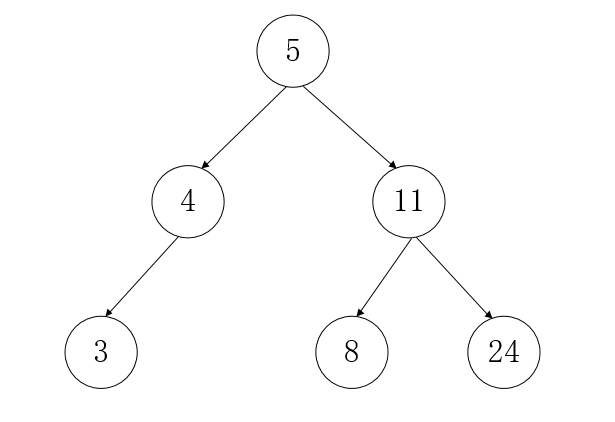
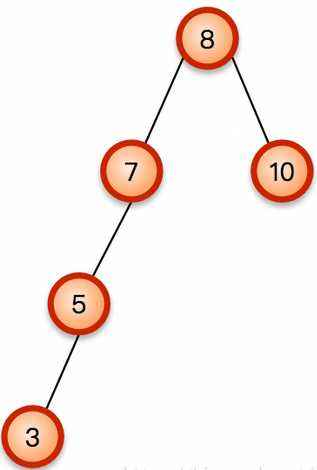
上面这两个图片都是二叉排序树。第一个树是平衡二叉树(任意结点左右子树高度差小于等于1,AVL),第二个树不平衡。不平衡会导致数据查询效率下降,因此要避免数据倾斜。
B树
二叉树的结点能保存数据,但是它存在缺点,如果数据量很大,它的深度会很大,查询效率低。比如:20层的满二叉树也只能存储100多万条数据。对于动辄数百万条记录的关系型数据库来说,要是查找一条记录如果要发生十几次IO,这个延时是不能接受的。
平衡树(B树,Balance Tree)是一种平衡多叉树,结点之间和结点内部也是有序的,每个结点有多个子结点,每个结点可以存储多个数据。二叉树因为瘦高,查询效率低。B树因为矮胖,降低了树的深度,查询效率快很多。具体定义自行百度。
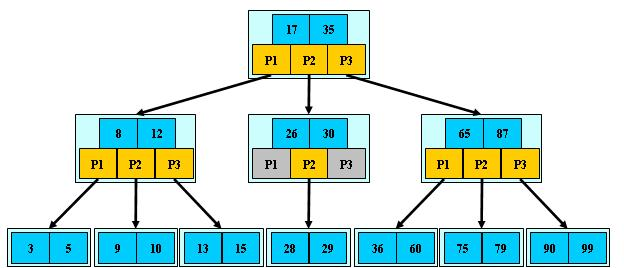
B+树
B+树是B树的一个变形,B+树的非叶子结点不存储数据,只作为索引。B+树的叶子结点内部,数据是有序排列的。
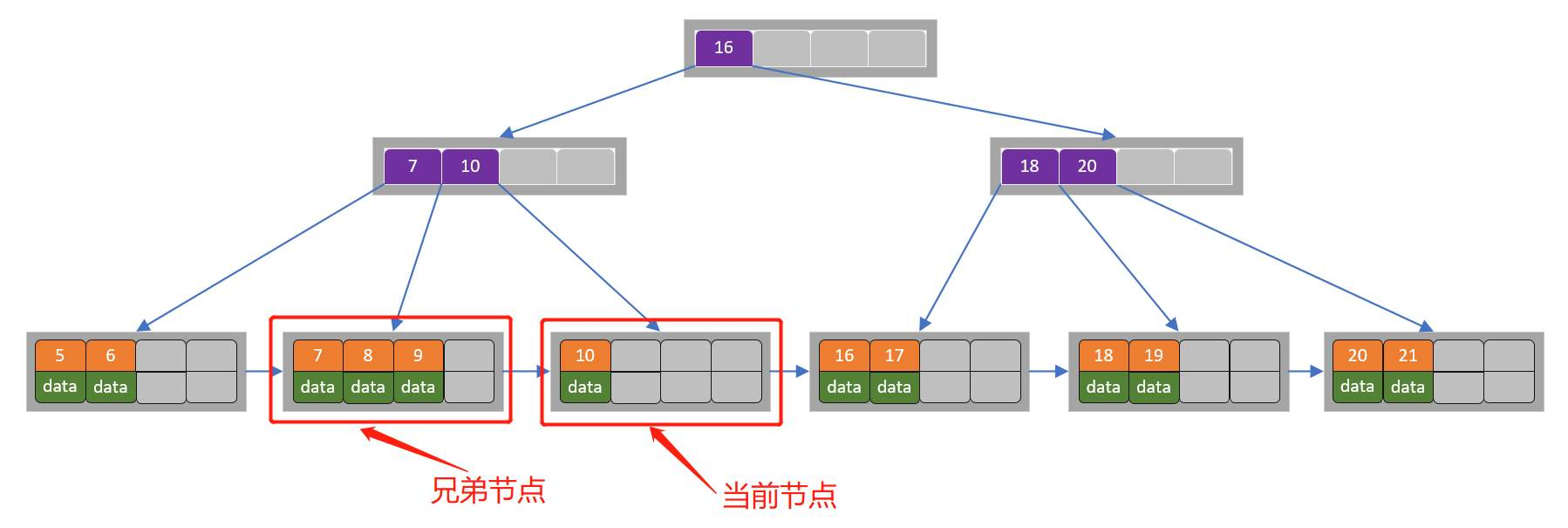
B+树的叶子结点兄弟之间有从左至右的指针,方便范围查询。
LSM
Log-Structured Merge-Tree,日志结构合并树,强调三点:一是这不是一个具体的数据结构只是一种做法,二是像写日志那样只追加,三是树会合并。
LSM为KV存储系统量身定做,只追加不修改不删除的特性很好地利用了机械硬盘顺序写入快、随机写入慢的特性。LSM首先是写内存,在内存中是一颗小树,内存要足够大,这比直接写磁盘也快了十万倍。内存写满了再落盘,追加到尾部,并且对大量的小文件做合并操作形成大树。为了将随机写转换为顺序写,LSM存储了大量的重复过时数据,这是空间换时间的做法。
上面这一点对于大量的写操作是非常高效的,但是读性能会略微受影响。读取数据的时候由于没有一颗完整有序的大树,所以要从最新的小树里查找数据,找不到的话就往前找。当然,这个缺陷可以使用布隆过滤器来优化。
我看了很多资料,都提到LSM是基于机械硬盘磁臂移动慢出现的,那么换成SSD还有这问题吗?老外对这个问题已经有研究了,看这里Separating Keys from Values in SSD-conscious Storage
当机械硬盘退出生产环境舞台的时候,LSM也许会迎来一波变革吧。
大数据学习(15)—— B+树和LSM的更多相关文章
- 大数据学习之BigData常用算法和数据结构
大数据学习之BigData常用算法和数据结构 1.Bloom Filter 由一个很长的二进制向量和一系列hash函数组成 优点:可以减少IO操作,省空间 缺点:不支持删除,有 ...
- 大数据学习(16)—— HBase环境搭建和基本操作
部署规划 HBase全称叫Hadoop Database,它的数据存储在HDFS上.我们的实验环境依然基于上个主题Hive的配置,参考大数据学习(11)-- Hive元数据服务模式搭建. 在此基础上, ...
- 大数据学习之 LINUX
##大数据学习 古斌6.6 01. linux系统的搭建: 选用 Contos 6.5 x64位系统 (CentOS-6.5-x86_64-minimal.iso) 我选择的为迷你版 模板机: bla ...
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习之Linux进阶02
大数据学习之Linux进阶 1-> 配置IP 1)修改配置文件 vi /sysconfig/network-scripts/ifcfg-eno16777736 2)注释掉dhcp #BOOTPR ...
随机推荐
- JAVA设计模式(6:单例模式详解)
单例模式作为一种创建型模式,在日常开发中用处极广,我们先来看一一段代码: // 构造函数 protected Calendar(TimeZone var1, Locale var2) { this.l ...
- python 字典和列表嵌套用法
python中字典和列表的使用,在数据处理中应该是最常用的,这两个熟练后基本可以应付大部分场景了.不过网上的基础教程只告诉你列表.字典是什么,如何使用,很少做组合说明. 刚好工作中采集promethe ...
- 『无为则无心』Python基础 — 13、Python流程控制语句(条件语句)
目录 1.流程控制基本概念 2.选择结构(条件语句) (1)条件语句概念 (2)if语句语法 (3)if...else...语句 (4)多重判断 (5)if语句嵌套 3.应用:猜拳游戏 4.三元运算符 ...
- react 工程目录简介
创建一个 todolist 项目,下图是其工程目录. node_modules文件夹 里面存放的是我们所建项目放所依赖的第三方的包 public文件夹 favicon.ico 图标文件,网页标题左上角 ...
- Linux 从头学 01:CPU 是如何执行一条指令的?
作 者:道哥,10+年的嵌入式开发老兵. 公众号:[IOT物联网小镇],专注于:C/C++.Linux操作系统.应用程序设计.物联网.单片机和嵌入式开发等领域. 公众号回复[书籍],获取 Linux. ...
- 《手把手教你》系列基础篇(五)-java+ selenium自动化测试- 创建首个自动化脚本(详细教程)
1.简介 前面几篇宏哥介绍了两种(java和maven)环境搭建和三大浏览器的启动方法,这篇文章宏哥将要介绍第一个自动化测试脚本.前边环境都搭建成功了,浏览器也驱动成功了,那么我们不着急学习其他内容, ...
- DL基础补全计划(一)---线性回归及示例(Pytorch,平方损失)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- 再看Lambda架构
博客原文地址 最*看了一本<大数据系统构建>的书,发现之前对于Lambda架构的理解还是不够深入和清晰. 之前对Lambda架构的理解 Azure文档上有一张Lambda架构的图, 同时也 ...
- Docker:Linux离线安装docker-compose
1)首先访问 docker-compose 的 GitHub 版本发布页面 https://github.com/docker/compose/releases 2)由于服务器是 CentOS 系统, ...
- Linux:从windows到linux的shell脚本编码和格式
从windows到linux的shell脚本编码和格式问题 异常问题 :set ff=unix 启动脚本在启动时报错比如执行sh start.sh,时会报Command not found等等的错误, ...