Python语言系列-05-模块和包
自定义模块
#!/usr/bin/env python3# author:Alnk(李成果)# 为什么要有模块?(内置函数不够用)# 和操作系统打交道# 和python解释器打交道# 和时间打交道# 如何利用python发邮件# 如何利用python图像识别# 都是完成好的功能# 可以被封装成函数# 可以成为内置的函数# 占用内存空间# 整理分类,把相同的功能放在一个文件中# 我们在开发的过程中,用到哪个功能直接导入使用就可以了# 不使用的功能不会进入内存占用不必要的空间# 使用的功能我们可以自由的选择# 模块的本质# 就是封装了很多很多函数、功能的一个文件# 导入模块 就是 import# 模块的分类# 内置模块 不需要我们进行额外的安装、随着解释器的安装直接就可以使用的模块# 扩展模块/第三方模块 我们安装了python解释器之后 如果要使用这些模块还要单独安装# https://pypi.org/# 豆瓣的 python源# 自定义模块# 自己写的模块
#!/usr/bin/env python3# author:Alnk(李成果)# 引用模块相当于执行这个模块# 重复引用会直接引用内存中已经加载好的模块结果# import tom# import tom# 模块被引用发生了三件事:# 1,创建一个以被导入模块的名字命名的名称空间# 2,自动执行模块中的代码(将模块中的所有内容加载到内存)# 3,要想执行模块中的代码必须通过模块名.的方式执行获取from tom import changeimport tomprint(tom.name) # 汤姆tom.read1() # tom模块: 汤姆name = '杰瑞'print(tom.name) # 汤姆print(name) # 杰瑞print("------------------ 1 ---------------------")# 模块的改名# 1,模块名过长,引用不方便,给模块改名,简化引用。import abcdpythonuser as abprint(ab.age) # 18ab.func() # 666print("------------------ 2 ---------------------")# 2, 优化代码。# import mysql# import oracle# db_sql = input('>>> ')# if db_sql == 'mysql':# mysql.sql_parse()# elif db_sql == 'orcle':# orcle.sql_parse()# 改版# db_sql = input('>>> ')# if db_sql == 'mysql':# import mysql as db# elif db_sql == 'oracle':# import orcle as db# db.sql_parse()# print("------------------ 3 ---------------------")# 引用多个模块# 标准的:# import mysql# import time# import sys# 不建议:# import mysql,time,os,sys# from ..... import .....# 执行过程:# 1,执行一遍tom的所有代码,加载到内存。# 2,将name,read1这些实际引用过来的变量函数在本文件复制一份。# globals()查看# 好处:使用简单# 坏处:容易与本文件的变量,函数名等发生冲突from tom import change,name,read1name = '小虎'def read1():print(666)print(name) # 小虎read1() #666from tom import change,name,read1print(name) # 汤姆read1() # tom模块: 汤姆# print(globals())print("------------------ 4 ---------------------")# 起别名:from tom import read1 as rr()print("------------------ 5 ---------------------")#导入多个:# 方式一# from tom import name# from tom import raed1# 方式2# from tom import name,read1,read2print("------------------ 6 ---------------------")# 导入所有:一般不用# from tom import *# print(globals())# 如果使用只有两点:# 1,将导入的模块中的所有的代码全部清楚的前提下,可以使用 *# from time import time# 2,只是用一部分# from tom import *# read1()# read2()# read3()# change()# import tom# 文件有个两个作用:# 1,作为脚本,直接运行# 2,作为模块供别人使用。# 3, __name__ == '__main__' 可以作为一个项目的启动文件用。# 模块的搜索路径# 先从内存中寻找 -----> built-in 内置模块 -----> sys.path找import sysprint(sys.path) # 返回一个列表 ,列表的第一个参数就当前目录。print("------------------ 7 ---------------------")
tom.py
# -*- coding: utf-8 -*-# __all__ = ['read1','read2'] # 控制 * 的范围。 from tom import * 只会导入 read1 read2print('from the tom.py')name = '汤姆'def read1():print('tom模块:', name)def read2():print('tom模块')read1()def read3():print('read3....')def read4():# dic = dict([('a', 1), ('b', 2), ('c', 3)])# print(dic)l1 = [1,2,3]l2 = ['a','b','c']print(dict(zip(l1,l2)))def change():global namename = 'tom'# print(666)# return name# read4()# print(__name__) # 在本文件运行,__name__ == __mian__if __name__ == '__main__':read3()
abcdpythonuser.py
#!/usr/bin/env python3# author:Alnk(李成果)age = 18def func():print(666)
mysql.py
#!/usr/bin/env python3# author:Alnk(李成果)def sql_parse():print('from mysql sql parse')
oracle.py
#!/usr/bin/env python3# author:Alnk(李成果)def sql_parse():print('from mysql sql parse')
常用内置模块
time模块
#!/usr/bin/env python3# author:Alnk(李成果)# time模块 和时间打交道的模块import time# 1.时间戳时间 time.time()print(time.time()) # 1618384314.988371 时间戳格式# float 小数# 为什么时间要用这种格式(1618384314.988371)表示?# 是给计算机看的# '2019/1/27 11:13'# 1970 1 1 0:0:0 英国伦敦的时间 0时区# 1970 1 1 8:0:0 北京的时间 东8区print("--------------- 1 ---------------------------")# 2.格式化时间 time.strftime('%Y-%m-%d %H:%M:%S')t1 = time.strftime('%Y-%m-%d %H:%M:%S')print(t1)t1 = time.strftime('%Y+%m+%d %H:%M:%S %a')print(t1)t1 = time.strftime('%Y+%m+%d %H:%M:%S %A %b %B')print(t1)t1 = time.strftime('%c')print(t1)print("--------------- 2 ---------------------------")# 3.结构化时间(时间元组) time.localtime()# time.struct_time(tm_year=2021, tm_mon=4, tm_mday=14, tm_hour=15, tm_min=18, tm_sec=52, tm_wday=2, tm_yday=104, tm_isdst=0)# print(time.localtime())# tm_year=2019 --- 年# tm_mon=1 ---月# tm_mday=28, ---日# tm_hour=11, ---时# tm_min=33, ---分# tm_sec=1, ---秒# tm_wday=0, --- 一周的第几天,星期一为0# tm_yday=28, --- 一年的第几天# tm_isdst=0 --- 是否是夏令时,默认不是# 转换只能通过结构化时间进行转换# 时间戳格式 <---> 结构化时间 <---> 格式化时间# 1548558746.5218766 '2019/1/27 11:13'# 计算机能看懂的 (为了进行数据转换) 人能看懂的# 时间戳时间 结构化时间 格式化时间# time.time() time.localtime() time.strftime('%Y-%m-%d %H:%M:%S')# 举例1# 格式化时间 2018-8-8 ---> 时间戳时间# 1.1,先把格式化时间 转化成 元组时间str_time = '2018-8-8'struct_time = time.strptime(str_time, '%Y-%m-%d')print(struct_time)# 1.2,在转化成时间戳stamp_time = time.mktime(struct_time)print(stamp_time)print("--------------- 3.1 ---------------------------")# 举例2# 2000000000 转化为格式化时间# 2.1,先把时间戳时间转化为元组时间stamp_t = 2000000000struct_t = time.localtime(stamp_t)print(struct_t)# 2.2,再把元组时间转为格式化时间strftime_t = time.strftime('%Y-%m-%d %H:%M:%S', struct_t)print(strftime_t)print("--------------- 3.2 ---------------------------")# 小练习1# 拿到本月时间1号的时间戳时间# 1,拿到本月的格式化时间strftime_t = time.strftime('%Y-%m')print(strftime_t)# 2,转化为结构化元组时间struct_t = time.strptime(strftime_t, '%Y-%m')print(struct_t)# 3,转化为时间戳时间stamp_t = time.mktime(struct_t)print(stamp_t)print("--------------- 4 ---------------------------")# 小练习2# '2017-09-11 08:30:00' '2018-09-13 08:30:10' 计算这两个时间段的时间差# 先把格式化时间--->元组时间--->时间戳时间t1 = time.mktime(time.strptime('2017-09-11 08:30:00', '%Y-%m-%d %H:%M:%S'))t2 = time.mktime(time.strptime('2018-09-13 08:30:10', '%Y-%m-%d %H:%M:%S'))print(t1)print(t2)ret = t2 - t1struct_t = time.gmtime(ret)print(struct_t)print('相差%d年%d月%d天%d小时%d分钟%d秒' % (struct_t.tm_year - 1970,struct_t.tm_mon - 1,struct_t.tm_mday - 1,struct_t.tm_hour - 0,struct_t.tm_min - 0,struct_t.tm_sec - 0,))
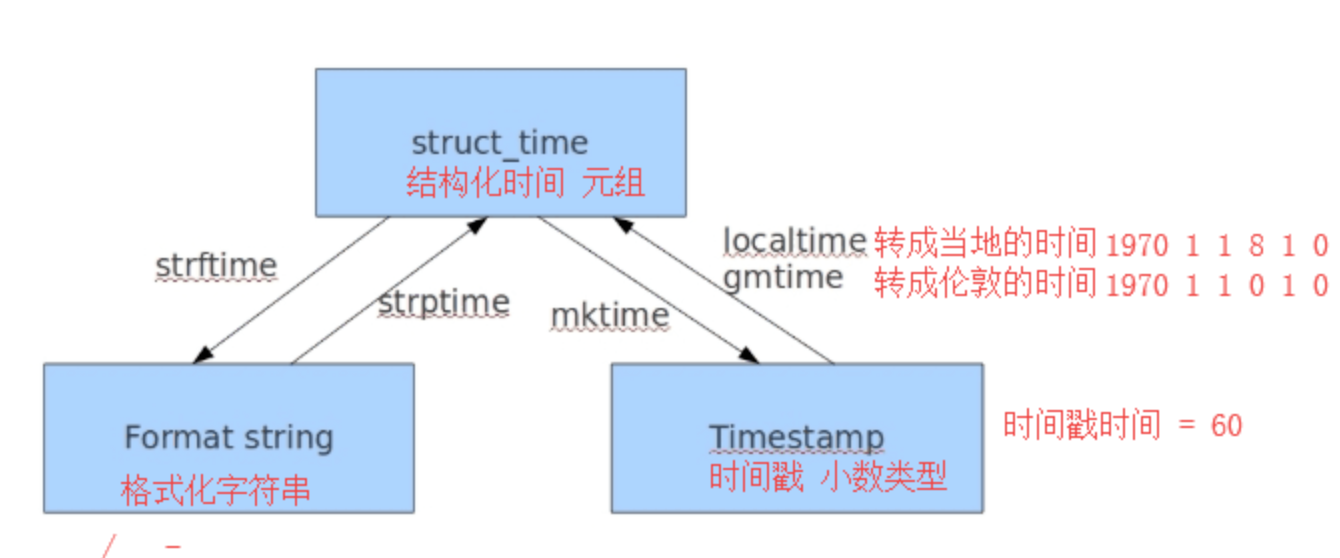
datetime模块
#!/usr/bin/env python3# author:Alnk(李成果)import datetimenow_time = datetime.datetime.now()print(now_time) # 2021-04-14 15:29:52.021695print(now_time + datetime.timedelta(weeks=3))print(now_time + datetime.timedelta(weeks=-3))print(now_time + datetime.timedelta(days=-3))print(now_time + datetime.timedelta(days=3))print(now_time + datetime.timedelta(hours=3))print("-------- 1 -----------")# 直接调整print(now_time.replace(year=2010))print(now_time.replace(month=10))print(now_time.replace(year=1989, month=4, day=25))print(now_time.replace(year=1989, month=4, day=25, hour=14, minute=10, second=10))print("-------- 2 -----------")print(datetime.date.fromtimestamp(time.time()))
logging模块
#!/usr/bin/env python3# author:Alnk(李成果)# logging# 什么时候需要打印日志?# 任何操作?# 个性化推荐,淘宝,京东,知乎,网易云音乐等等# 只要给你做记录,都可以当做广义的日志# 开发中的日志:# 1,日志帮助你调试代码# 2,代码的警告,危险提示作用# 3,你对服务器的操作命令# 4,重要的节点,需要日志提示# 低配# 低配版:不能同时屏幕输出和文件写入# import logging# import time# logging.debug('debug message') # 调试模式# logging.info('info message') # 正常运转模式# logging.warning('warning message 1') # 警告模式# logging.error('error message 2') # 错误模式# logging.critical('critical message 3') # 致命的 崩溃模式## while 1:# try:# num = input('>>>:')# int(num)# except ValueError:# logging.warning('输入非数字元素,警告!')# time.sleep(1)# break# print("-------------- 1 --------------------")# 制定显示信息格式# import logging# logging.basicConfig(# # level=logging.DEBUG,# level=20, # 设置级别# format='%(asctime)s %(filename)s [line:%(lineno)d] %(levelname)s %(message)s',# # datefmt='%a, %d %b %Y %H:%M:%S', # 显示时间格式# # filename='test.log',# # filemode='w'# )# logging.debug('debug message 1') # 调试模式 10# logging.info('info message 2') # 正常运转模式 20# logging.warning('warning message 3') # 警告模式 30# logging.error('error message 4') # 错误模式 40# logging.critical('critical message 5') #致命的 崩溃模式 50# print("-------------- 2 --------------------")# # 标配# # 1.产生logger对象# import logging# logger = logging.getLogger()## # 2 产生其他对象(屏幕对象,文件对象)# sh = logging.StreamHandler() # 屏幕对象# fh1 = logging.FileHandler('staff.log', encoding='utf-8') # 文件对象# fh2 = logging.FileHandler('boss.log', encoding='utf-8') # 文件对象## # 3,设置显示格式# formater = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # 执行设置显示格式# formater1 = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # 执行设置显示格式# formater2 = logging.Formatter('%(asctime)s-%(message)s') # 执行设置显示格式## # 4,给对象绑定格式# sh.setFormatter(formater)# fh1.setFormatter(formater1)# fh2.setFormatter(formater2)## # 5 给logger对象绑定其他对象# logger.addHandler(sh)# logger.addHandler(fh1)# logger.addHandler(fh2)## # 6 设置显示级别# # 其他对象的级别要高于logger的级别# logger.setLevel(40)# sh.setLevel(20)# fh1.setLevel(30)# fh2.setLevel(50)### logging.debug('debug message 1') # 调试模式 10# logging.info('info message 2') # 正常运转模式 20# logging.warning('warning message 3') # 警告模式 30# logging.error('error message 4') # 错误模式 40# logging.critical('critical message 5') #致命的 崩溃模式 50# print("-------------- 3 --------------------")# 高配 真正的工作中,是自定制个性化日志import osimport logging.config# 定义三种日志输出格式 开始# 标准版 格式standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \'[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字# 简单版 格式simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'# boss版格式id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s'# 定义日志输出格式 结束logfile_name = r'staff.log' # log文件名# log配置字典LOGGING_DIC = {'version': 1, # 版本'disable_existing_loggers': False, # 可否重复使用之前的logger对象'formatters': {'standard': {'format': standard_format},'simple': {'format': simple_format},'boss_formatter':{'format': id_simple_format},},'filters': {},'handlers': {# 打印到终端的日志'stream': {'level': 'DEBUG','class': 'logging.StreamHandler', # 打印到屏幕'formatter': 'simple'},# 打印到文件的日志,收集info及以上的日志 文件句柄'file': {'level': 'INFO','class': 'logging.handlers.RotatingFileHandler', # 保存到文件'formatter': 'standard', #标准'filename': logfile_name, # 日志文件'maxBytes': 30000, # 日志大小 30000 bit'backupCount': 5, # 轮转文件数'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了},},'loggers': {# logging.getLogger(__name__)拿到的logger配置'': {'handlers': ['stream', 'file'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕'level': 'DEBUG', # 总级别'propagate': True, # 向上(更高level的logger)传递},},}# 字典中第一层的所有key都是固定不可变的# import logging# logging.config.dictConfig(LOGGING_DIC)# logger = logging.getLogger() # 这个logger对象是通过自己个性化配置的logger对象# logger.debug('调试模式1')# logger.info('运转正常2')# logger.warning("警告 3")# logger.error("错误 4")# logger.critical("严重错误 5")def load_my_logging_cfg():logging.config.dictConfig(LOGGING_DIC) # 导入上面定义的logging配置logger = logging.getLogger(__name__) # 生成一个log实例logger.info('It works!') # 记录该文件的运行状态if __name__ == '__main__':load_my_logging_cfg()
模拟其他模块调用日志模块
logging_test.py
#!/usr/bin/env python3# author:Alnk(李成果)import loggingimport logging.config# 1 定义日志格式,分为标准版,简单版,low版,可以自定义# 标准版standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \'[%(levelname)s][%(message)s]' # 其中name为getlogger指定的名字# 简单版simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'# low版id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s'# 2 定义日志输出文件,也可以只定义一个文件logfile_name = r'stafftest.log'logfile_boss = r'bosstest.log'# 3 logging模块配置字典# 字典中第一层的所有key都是固定不可变的LOGGING_DIC = {'version': 1, # 版本'disable_existing_loggers': False, # 可否重复使用之前的logger对象'formatters': { # 日志格式,第一步定义的'standard': {'format': standard_format},'simple': {'format': simple_format},'boss_formatter': {'format': id_simple_format},},'filters': {}, # 过滤'handlers': {# 打印到终端的日志'stream': {'level': 'DEBUG','class': 'logging.StreamHandler', # 打印到屏幕'formatter': 'simple'},# 打印到文件的日志,收集info及以上的日志 文件句柄'file': {'level': 20,'class': 'logging.handlers.RotatingFileHandler', # 保存到文件'formatter': 'standard', # 标准'filename': logfile_name, # 日志文件'maxBytes': 3000000, # 日志大小 3000000 bit'backupCount': 5, # 轮转文件数'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了},'boss': {'level': 20,'class': 'logging.handlers.RotatingFileHandler', # 保存到文件'formatter': 'boss_formatter', # low版'filename': logfile_boss, # 日志文件'maxBytes': 300, # 日志大小 300 bit'backupCount': 5, # 轮转文件数'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了},},'loggers': {# logging.getLogger(__name__)拿到的logger配置'': {'handlers': ['stream', 'file', 'boss'], # 这里把上面定义的handler都加上,即log数据既写入文件又打印到屏幕'level': 'DEBUG', # 总级别'propagate': True, # 向上(更高level的logger)传递},},}# 4 定义一个函数,供其他模块调用def get_logger(taskid):logging.config.dictConfig(LOGGING_DIC)logger = logging.getLogger(taskid) # 这个logger对象是通过自己个性化配置的logger对象return logger # 返回logger对象供使用者调用if __name__ == '__main__':logger1 = get_logger('测试业务') # 调用函数,获取返回值logger对象logger1.info('打印日志logger1')# 其他业务模块调用logger2 = get_logger('其他业务')logger2.error('错误日志')
test.py
#!/usr/bin/env python3# author:Alnk(李成果)from logging_test import get_loggerlogger1 = get_logger('模拟其他模块调用日志模块')logger1.info('日志打印')
random模块
#!/usr/bin/env python3# author:Alnk(李成果)# 和随机相关的内容 random模块import random# 随机小数print(random.random()) # (0,1)print(random.uniform(1, 2)) # (n,m)print("------ 1 ---------------------------------------------")# 随机整数print(random.randint(1, 2)) # [1, 2] 包含了2print(random.randrange(1, 2)) # [1, 2) 不包含2print(random.randrange(1, 5, 2)) # 步长为2print("------ 2 ---------------------------------------------")# 随机从一个列表中取一个值ret = random.choice([1, 2, 3, ('k', 'v'), {'name': 'tom'}])print(ret)print("------ 3 ---------------------------------------------")# 随机从一个列表中取2个值ret2 = random.sample([1, 2, 3, ('k', 'v'), {'name': 'tom'}], 2)print(ret2)print("------ 4 ---------------------------------------------")# 打乱顺序 洗牌l1 = [1, 2, 3, 4, 5]random.shuffle(l1)print(l1)print("------ 5 ---------------------------------------------")# 验证码例子def my_code(n=6, flag=True):code = ''for i in range(n):num = random.randint(0, 9)# 注意这里的小技巧# 字母和数字混合if flag:alp = chr(random.randint(65, 90)) # A-Z 字母随机num = random.choice([num, alp]) # 字母和数字之中取一个code += str(num)return code# ret = my_code(n=4, flag=False)ret = my_code()print(ret)print("------ 6 ---------------------------------------------")# 红包例子# 思路:# 1.需要确定红包个数,红包总金额# 2.最低金额为0.01元# 3.每抽中一次,需要用红包当前总金额减去抽中的金额,然后在继续在该区间内随机抽取def hb(num, money):# 定义空列表用来存储抽奖金额lst = []# 金额乘以100,便于计算,后续加入到列表在除以100money = int(money * 100)# 判断传递参数的合法性if type(num) is int and num >=1 and (type(money) is int or type(money) is float):# for循环应该比num少一次,例如2个红包个数,for循环1次就可以for i in range(1, num):# 保证不出现抽中0元的现象p = random.randint(1, money - (num - i))lst.append(p / 100)# 需要减去已经抽取的红包金额money = money - pelse:# 循环结束了,把剩余的红包总金额放入到一个红包内lst.append(money / 100)return lstelse:print('参数有误!')ret = hb(3, 0.04)print(ret)
os模块
#!/usr/bin/env python3# author:Alnk(李成果)import os# os和操作系统打交道的# 和文件、文件夹相关的# os.makedirs('dirname1/dirname2') # 可生成多层递归目录# os.removedirs('dirname1/dirname2') # 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推# os.mkdir('dirname') # 生成单级目录;相当于shell中mkdir dirname# os.rmdir('dirname') # 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname# ret = os.listdir(r'/tmp') # 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印# print(ret)# os.remove('test.py') # 删除一个文件# os.rename("test.py", "test2.py") # 重命名文件/目录# ret = os.stat(r'test.py') # 获取文件/目录信息# print(ret)# print("------------- 1 ----------------")# 和执行系统命令相关# os.system("dir") # 运行shell命令,直接显示# ret = os.popen('dir').read() # 运行shell命令,获取执行结果# print(ret)# ret = os.getcwd() # 获取当前工作目录,即当前python脚本工作的目录路径# print(ret)# os.chdir(r"/tmp") # 改变当前脚本工作目录;相当于shell下cd# ret = os.getcwd()# print(ret)# # 所谓工作目录 文件在哪个目录下运行 工作目录就是哪里# # 和这个文件本身所在的路径没有关系# # 1.工作目录与文件所在位置无关# # 2.工作目录和所有程序中用到的相对目录都相关# print("------------- 2 ----------------")# 和路径相关的# os.path# ret = os.path.abspath(__file__) # 返回path规范化的绝对路径# print(ret)# ret = os.path.split(__file__) # 将path分割成目录和文件名二元组返回# print(ret)# os.path.dirname(path) # 返回path的目录。其实就是os.path.split(path)的第一个元素# os.path.basename(path) # 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素# ret = os.path.exists(r'E:\python') # 如果path存在,返回True;如果path不存在,返回False# print(ret)# ret = os.path.isabs('E:\python3周末班2期笔记\05 day05\03 笔记整理') # 如果path是绝对路径,返回True# print(ret)# ret = os.path.isfile('E:\python3周末班2期笔记\05 day05\03 笔记整理') # 如果path是一个存在的文件,返回True。否则返回False# print(ret)# ret = os.path.isdir('E:\python3周末班2期笔记') # 如果path是一个存在的目录,则返回True。否则返回False# print(ret)# ret = os.path.join('E:\python3周末班2期笔记', 'abc', 'def') # 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略# print(ret)# os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间# os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间# ret = os.path.getsize(r'E:\python3周末班2期笔记\05 day05\03 笔记整理\00 今日课程大纲.py')# 返回path的大小,文件夹的大小不准确# print(ret)# print("------------- 3 ----------------")# 练习题# 使用python代码 计算文件夹的大小# 文件夹里可能还有文件夹# import os# total_size=0# def file_size(path):# global total_size# path=os.path.abspath(path)# print('path',path)# file_list=os.listdir(path)# print('list',file_list)# for i in file_list:# i_path = os.path.join(path, i)# if os.path.isfile(i_path):# total_size += os.path.getsize(i_path)# else:# try:# file_size(i_path)# except RecursionError:# print('递归操作时超出最大界限')# return total_size## print(file_size(r'E:\02'))# print("------------- 4 ----------------")
sys模块
#!/usr/bin/env python3# author:Alnk(李成果)import sys# sys模块是和 python解释器打交道的# sys.exit() # 退出# print(123)# print(sys.version) # 版本# print(sys.platform) # 平台 操作系统# print(sys.path) # 模块搜索路径# 包含的内容# 1.内置的python安装的时候就规定好的一些内置模块所在的路径# 内置模块# 扩展模块# 2.当前被执行的文件所在的路径# 自定义的模块# 需要在CMD执行# python py文件的目录 参数1 参数2# print(sys.argv) # []# if sys.argv[1] == 'tom' and sys.argv[2] == '123':# print('登陆成功')# else:# print('登陆失败')# sys.exit()# print('登陆成功后的所有代码')
json模块
#!/usr/bin/env python3# author:Alnk(李成果)# 序列化模块# 序列化# 序列 list str tuple bytes# 可迭代的都是序列?字典?集合?无序的,散列。不是序列# 狭义的序列 str / bytes# 序列化?把...变得有序,把...变成str或者是bytes# 反序列化?把str/bytes 还原回原来的 ...# 为什么要有序列化?# 1.存储在文件中 长久保存到硬盘# 2.在网络上传递,只能用字节# 序列化模块import json# 能够支持所有的计算机高级语言# 对数据类型的要求非常严格dic = {"key": "value"}ret = json.dumps(dic) # 序列化方法print(dic, type(dic)) # {'key': 'value'} <class 'dict'>print(ret, type(ret)) # {"key": "value"} <class 'str'>with open('json_file', 'w') as f:f.write(ret)with open('json_file') as f:content = f.read()d = json.loads(content) # 反序列化方法print(d, type(d)) # {'key': 'value'} <class 'dict'>print(d['key'])print("------------ 1 ------------------------------")# 1:json格式规定所有的key必须是字符串数据类型dic = {1: 2}ret = json.dumps(dic)print(dic[1]) # 2print(ret) # {"1": 2}new_dic = json.loads(ret)print(new_dic) # {'1': 2}print("------------ 2 ------------------------------")# 2 : json中的所有tuple都会被当作list处理dic = {1: (1, 2, 3)}ret = json.dumps(dic)print(ret) # {"1": [1, 2, 3]}new_dic = json.loads(ret)print(new_dic) # {"1": [1, 2, 3]}print("------------ 3 ------------------------------")# 3: json能支持的数据类型非常有限,字符串 数字 列表 字典# dumps loads 字符串 和 其他基础数据类型之间转换# dump load 文件 和 其他基础数据类型之间转换# dump loaddic = {"key": "value"}with open('json_file2', 'w') as f:json.dump(dic, f)with open('json_file2') as f:ret = json.load(f)print(ret['key']) # valueprint("------------ 4 ------------------------------")# json不可以dump多次dic = {"key": "value"}with open('json_file3', 'w') as f:json.dump(dic, f)# json.dump(dic, f) # dump多次会报错with open('json_file3', 'r') as f:ret = json.load(f)print(ret)print("------------ 5 ------------------------------")# 如果需要dump多次,按照下面的方法str_dic = {"name": "tom", "sex": None}ret = json.dumps(str_dic)with open('json_file4', 'w') as f:f.write(ret+'\n')f.write(ret+'\n')with open('json_file4', 'r') as f:for line in f:print(json.loads(line), type(json.loads(line)))
pickle模块
#!/usr/bin/env python3# author:Alnk(李成果)import pickle# 1.支持几乎所有python中的数据类型# 2.只在python语言中通用# 3.pickle适合与bytes类型打交道的s = {1, 2, 3, 4}print(type(s)) # <class 'set'>ret = pickle.dumps(s)print(ret)ret2 = pickle.loads(ret)print(ret2)print("--------------- 1 -----------------")# pickle:序列化时候数据是什么类型,反序列化以后数据还是原来的类型,这点和 json 有点不一样d = {1: 2, 3: 4}ret = pickle.dumps(d)print(ret)new_d = pickle.loads(ret)print(new_d)print("--------------- 2 -----------------")# 写入文件s = {(1, 2, 3): 2, 3: 4}result = pickle.dumps(s)print(result)with open('pickle_file', 'wb') as f:f.write(result)with open('pickle_file', 'rb') as f:content = f.read()ret = pickle.loads(content)print(ret, type(ret))print("--------------- 3 -----------------")# pickle 可以支持多个对象放入文件# pickle 可以dump多次,也可以load多次s1 = {1, 2, 3}s2 = {1: 2, 3: 4}s3 = ['k', 'v', (1, 2, 3), 4]with open('pickle_file2', 'wb') as f:pickle.dump(s1, f)pickle.dump(s2, f)pickle.dump(s3, f)with open('pickle_file2', 'rb') as f:count = 1while count <= 3:try:content = pickle.load(f)print(content)count += 1except EOFError:breakprint("--------------- 4 -----------------")# json 实际上使用json更多 优先选择# 如果你是要跨平台沟通,那么推荐使用json# key只能是字符串# 不能多次load和dump# 支持的数据类型有限# pickle# 如果你是只在python程序之间传递消息,并且要传递的消息是比较特殊的数据类型# 处理文件的时候 rb/wb# 支持多次dump/load
re模块
正则表达式
#!/usr/bin/env python3# author:Alnk(李成果)# 正则表达式# re模块 是用来在python中操作 正则表达式 的# 要先知道正则表达式是什么?做什么用的?怎么用# 正则表达式检测网站# http://tool.chinaz.com/regex/# 邮箱地址# 用户名 密码# 要检测一个用户输入的内容是否符合我的规则# 用户输入的内容对于程序员来说都是字符串# 一个文件是一堆字符串,有很多内容# 检测某一个字符串是否符合规则 需求一# 从一大段文字中找到符合规则的字符串 需求二# 正则表达式 --> 字符串规则匹配的# 1.判断某一个字符串是否符合规则# 2.从一段文字中提取出符合规则的内容# 初识正则表达式# 字符组的概念# [ ]表示字符组,一个[ ]表示一个字符组# [1-9]# [0-9]# [1-5]# [a-z]# [a-f]# 1.对字母来说 区分大小写# 2.a-f可以 f-a不行# 一个字符位置上可以出现的内容是匹配数字或字母:[0-9a-zA-Z]# 匹配一个两位数:# [1-9][0-9]# 元字符# \d 数字# \w 数字 字母 下划线# \s 空格 回车 制表符# \t 制表符# \n 回车# \b 匹配一个单词的边界。例如 hello world o\b会匹配hello的o# \D 非数字# \W 非数字字母下划线# \S 非空白# ^ 一个字符串的开始# $ 一个字符串的结尾# ^xxxx$ 约束的了整个字符串中的内容必须一一与表达式对应上# 例如: hello hello hello# ^hello 只能匹配第一个hello# hello$ 只能匹配最后一个hello# hello^ 不能匹配任何字符串。因为 ^ 是开头,没有可能在开头在出现字符。# | 表示或# 例子:匹配ab或abc 要这样写 abc|ab 把长的表达式写在前面# () 分组# a(b|c)d# 例子:www.baidu.com www.baide.com 表达式 www.baid(u|e).com# . 表示除了换行符以外的任意字符# 非 字符组# [^ABC] 只要不是ABC都能匹配# 量词# {n} 在这个量词前面的一个元字符出现n次# {n,} 在这个量词前面的一个元字符出现n次或n次以上# {n,m} 在这个量词前面的一个元字符出现n次到m次以上## ? 在这个量词前面的一个元字符出现0次或者1次# + 在这个量词前面的一个元字符出现1次或者多次# * 在这个量词前面的一个元字符出现0次或者多次# 例子:# 1.匹配一个整数:\d+# 2.匹配一个小数:\d+\.\d+# 3.匹配整数或者小数: 表达式 \d+(\.\d+)? 括号里面的被量词?问号约束,约束了一组字符的出现次数# 小练习# 正则表达式默认都是贪婪匹配# 贪婪匹配:会尽量多的帮我们匹配内容# 例子 待匹配字符:李杰和李莲英和李二棍子 正则表达式:李.? 匹配结果:李杰 李莲 李二 匹配到这3条# 回溯算法下的贪婪匹配# 例子:待匹配字符:<a>bbbb<a> 正则表达式:<.*> 匹配结果:<a>bbbb<a># 非贪婪模式,# 在量词后面加一个问号,开启非贪婪模式# 惰性匹配:尽量少的匹配# 例子:待匹配字符:<a>bbbb<a> 正则表达式:<.*?> 匹配结果:<a> <a> 这两条# 例子 待匹配字符:李杰和李莲英和李二棍子 正则:李[杰莲英二棍子]* 匹配结果:李杰 李莲英 李二棍子# 例子 待匹配字符:李杰和李莲英和李二棍子 正则:李[^和]* 匹配结果:李杰 李莲英 李二棍子# 例子# 身份证号码是一个长度为15或18个字符的字符串,如果是15位则全部由数字组成,首位不能为0;# 如果是18位,则前17位全部是数字,末位可能是数字或x# ^[1-9]\d{14}(\d{2}[x\d])?$# ^([1-9]\d{16}[\dx]|[1-9]\d{14})$# 转义符例子# r'\\n' 匹配 '\n'# .*?x :爬虫常用 ,表示匹配任意字符,直到遇见x停止# 练习题# 1、 匹配一段文本中的每行的邮箱# http://blog.csdn.net/make164492212/article/details/51656638## 2、 匹配一段文本中的每行的时间字符串,比如:‘1990-07-12’;## 分别取出1年的12个月(^(0?[1-9]|1[0-2])$)、# 一个月的31天:^((0?[1-9])|((1|2)[0-9])|30|31)$## 3、 匹配qq号。(腾讯QQ号从10000开始) [1,9][0,9]{4,}## 4、 匹配一个浮点数。 ^(-?\d+)(\.\d+)?$ 或者 -?\d+\.?\d*## 5、 匹配汉字。 ^[\u4e00-\u9fa5]{0,}$## 6、 匹配出所有整数
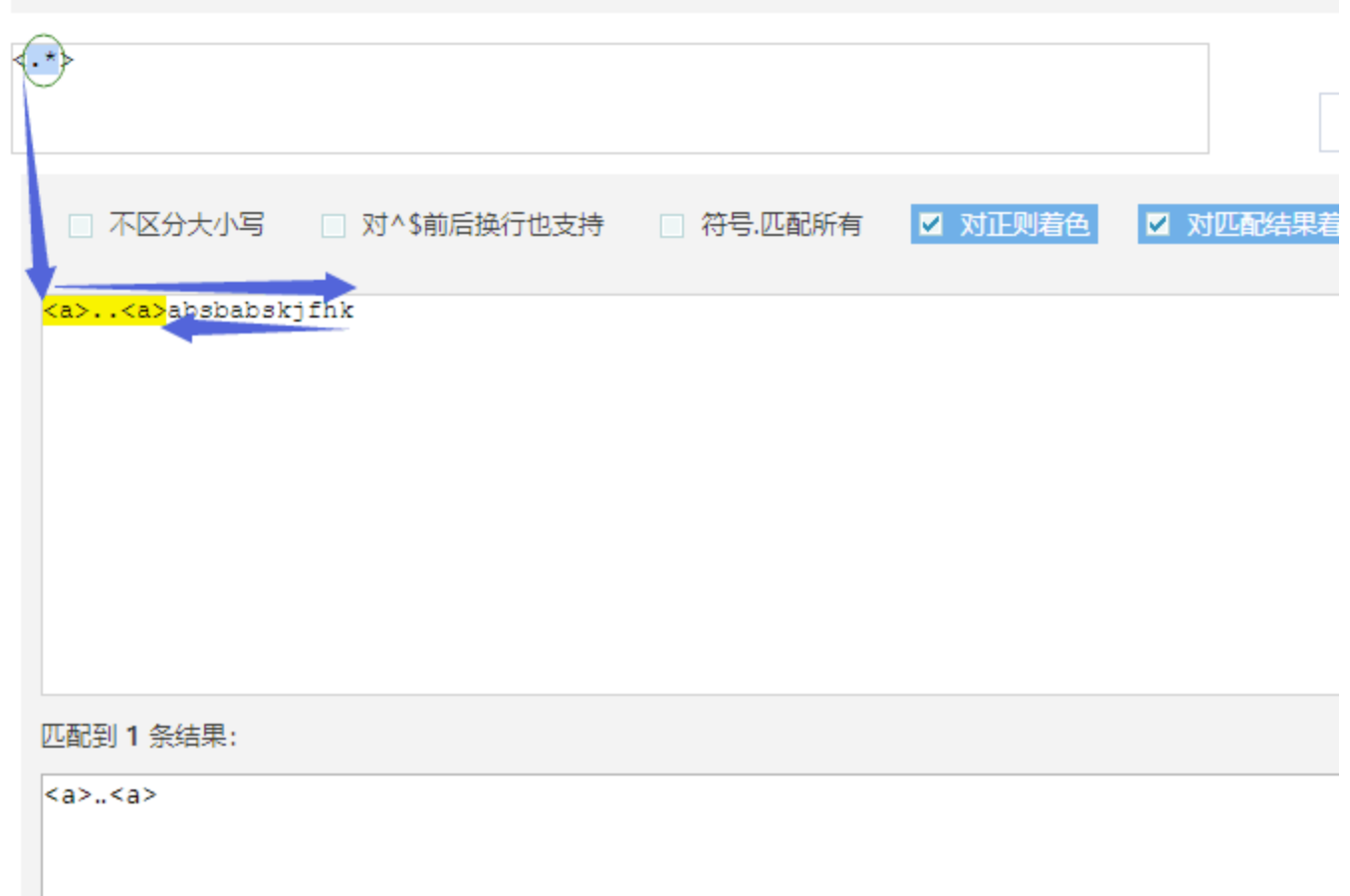
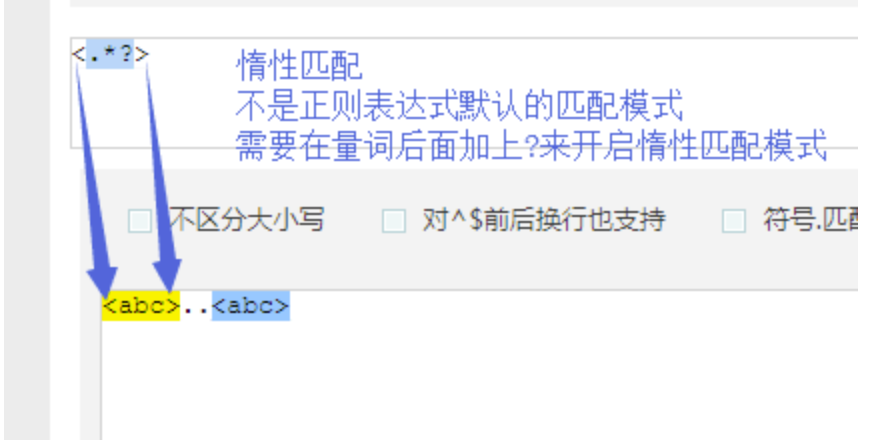
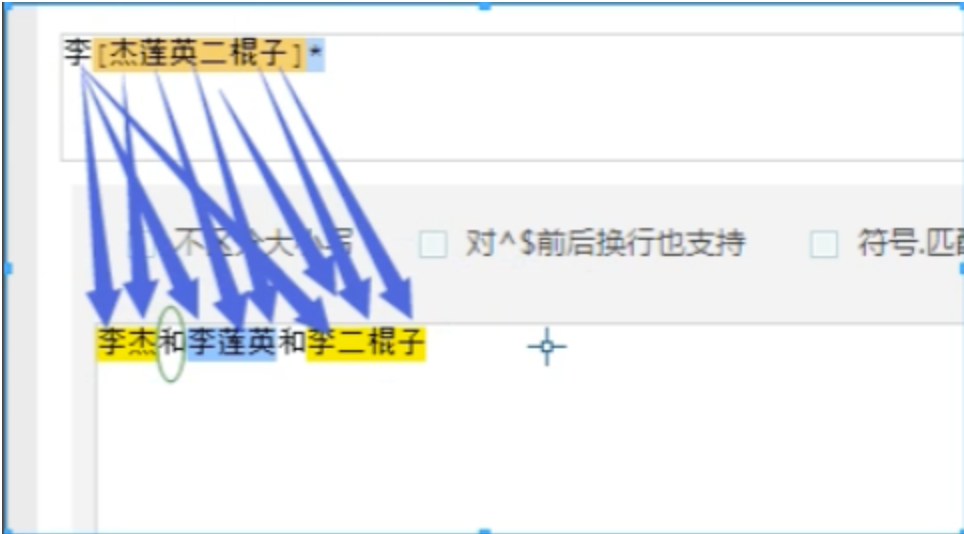
re模块
#!/usr/bin/env python3# author:Alnk(李成果)import re# 1 findall() 匹配所有ret = re.findall("\d+", 'h2b3123')print(ret, type(ret)) # ['2', '3123'] <class 'list'>print("------------ 1 --------------------")# 分组遇到findall,优先显示分组中匹配到的内容# ( ) 分组匹配ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com')print(ret) # ['oldboy']# 如何取消分组优先? ?:ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com')print(ret) # ['www.oldboy.com']print("------------ 2 --------------------")# 2 search() 只匹配从左到右的第一个ret = re.search('\d+','h2b3123')print(ret) # <_sre.SRE_Match object; span=(1, 2), match='2'>print(ret.group()) # 2print("------------ 3 --------------------")ret = re.search('\d+','aaaab123a1')if ret:print(ret.group()) # 123print("------------ 4 --------------------")# 3 compile() # 节省时间# compile 节省时间 一条正则表达式用多次# '\d+' --> 正则规则 --> python代码 --> 将字符串按照代码执行匹配ret = re.compile('\d+') # 先写好正则表达式r = ret.findall('ahkfgilWIVKJBDKvjgheo') # 匹配所有if r:print(r)print("------------ 5 --------------------")r = ret.search('ahkfgilsk0194750dfjWIVKJBDKvjgheo') # 只匹配从左到右的第一个if r:print(r.group()) # 0194750print("------------ 6 --------------------")# 4 finditer 节省空间 结果的条数很多的时候ret = re.finditer('\d+','dskh1040dsvk034fj048d3g5h4j')for r in ret:print(r.group())print("------------ 7 --------------------")# 练习题# 匹配标签s = '<h1>abc</h1>'ret = re.search('<(\w+)>', s)print(ret.group())print("------------ 8 --------------------")# 分组s = '<h1>abc</h1>'ret = re.search('<(\w+)>(.*?)<(/\w+)>', s)print(ret.group()) # <h1>abc</h1>print(ret.group(1)) # h1print(ret.group(2)) # abcprint(ret.group(3)) # /h1print("------------ 9 --------------------")# 分组标签s = '<h1>abc</h1>'ret = re.search('<(?P<tag>\w+)>(.*?)<(/\w+)>', s)print(ret.group('tag')) # h1print("------------ 10 --------------------")s = '<h1>abc</h1>'ret = re.search('<(?P<tag1>\w+)>(.*?)</(?P=tag1)>', s)print(ret) # <_sre.SRE_Match object; span=(0, 12), match='<h1>abc</h1>'>print(ret.group()) # <h1>abc</h1>print(ret.group('tag1')) # h1print("------------ 11 --------------------")# 还可以在分组中利用?<name>的形式给分组起名字# 获取的匹配结果可以直接用group('名字')拿到对应的值ret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>", "<h1>hello</h1>")print(ret.group('tag_name')) # 结果 :h1print(ret.group()) # 结果 :<h1>hello</h1>print("------------ 12 --------------------")# 如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致# 获取的匹配结果可以直接用group(序号)拿到对应的值ret = re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>")print(ret.group(1)) # h1print(ret.group()) # 结果 :<h1>hello</h1>
hashlib模块
#!/usr/bin/env python3# author:Alnk(李成果)import hashlib# 加密模块 摘要算法 一堆加密算法的集合体# import hashlib# 给密码加密# 文件的校验# hashlib: 将str类型 通过算法 -----> 一串等长度的数字# 1,不同的字符串 转化成数字肯定不同# 2,相同的字符串即使在不同的计算机上只要使用相同的加密方式 转化成的数字一定相同# 3,hashlib加密不可逆,不能破解# md5加密# md5加密效率快,通用,安全性相对差ret = hashlib.md5()ret.update('好123'.encode('utf-8')) # 51cb75f82eceb17b86f019e01618d75eprint(ret.hexdigest())print("-------------- 1 ----------------------------------------------")ret = hashlib.md5()ret.update('aabbccddeeff'.encode('utf-8')) # d6ce01d2e191f83c4396ee41eed4e076print(ret.hexdigest())print("-------------- 2 ----------------------------------------------")ret = hashlib.md5()ret.update('1'.encode('utf-8')) # c4ca4238a0b923820dcc509a6f75849bprint(ret.hexdigest())print("-------------- 3 ----------------------------------------------")# 撞库# 经常设置的 111111 000000 123456 password 等等,做了一个对应表,一一对去寻找ret = hashlib.md5()ret.update('123456'.encode('utf-8')) # e10adc3949ba59abbe56e057f20f883eprint(ret.hexdigest())print("-------------- 4 ----------------------------------------------")# 加盐# 让你的密码更复杂。ret = hashlib.md5('hello word!'.encode('utf-8')) # 盐ret.update('123456'.encode('utf-8')) # cad5c6823564df20c3fb53848a9b84efprint(ret.hexdigest())print("-------------- 5 ----------------------------------------------")# 动态的盐# username = input('请输入用户名:')# ret = hashlib.md5(username[::2].encode('utf-8'))# ret.update('123456'.encode('utf-8')) # 765b4e7ed31b8aa07755d1c24c69d48c# print(ret.hexdigest())# sha加密# sha加密,算法更好 安全性高,效率低,耗时长ret = hashlib.sha1()ret.update('gjfds;fldg'.encode('utf-8'))print(ret.hexdigest()) # 40098e7fbc4d85eba01695315e2dd896bd4d8ebbprint("-------------- 6 ----------------------------------------------")ret = hashlib.sha256()ret.update('gjfds;fldg'.encode('utf-8'))print(ret.hexdigest()) # b3a2d0e194c193ecd04a61a2b28863047b27b7b93c28b5fdab578aeab0f96dd9print("-------------- 7 ----------------------------------------------")ret = hashlib.sha512()ret.update('gjfds;fldg'.encode('utf-8'))# 9a5eea267dc6b7a7e3eb45f1f9345b735a26dea92787de5f356e87fe4efe635a1d7b27c8f321e9ec87ad03a7eab91d7bfbf7a753da01e3e6dda6a06b272485d6print(ret.hexdigest())print("-------------- 8 ----------------------------------------------")# 文件校验# 文件较小用下面代码def check_md5(file):ret = hashlib.md5()with open(file, mode='rb') as f1:ret.update(f1.read())return ret.hexdigest()print(check_md5('文件校验1'))print(check_md5('文件校验2'))print("-------------- 9 ----------------------------------------------")# 大文件的校验:ret1 = hashlib.md5()ret1.update("a".encode("utf-8"))print(ret1.hexdigest()) # 0cc175b9c0f1b6a831c399e269772661ret2 = hashlib.md5()ret2.update("b".encode("utf-8"))print(ret2.hexdigest()) # 92eb5ffee6ae2fec3ad71c777531578fret3 = hashlib.md5()ret3.update("a".encode("utf-8"))ret3.update("b".encode("utf-8"))print(ret3.hexdigest()) # 187ef4436122d1cc2f40dc2b92f0eba0print("-------------- 10 ----------------------------------------------")#def check_md5(file):ret = hashlib.md5()with open(file, mode='rb') as f1:while 1:content = f1.read(1024)if content:ret.update(content)else:breakreturn ret.hexdigest()print(check_md5('文件校验1'))print(check_md5('文件校验2'))
collections模块
#!/usr/bin/env python3# author:Alnk(李成果)from collections import namedtuplefrom collections import dequefrom collections import defaultdictfrom collections import Counter# 1 namedtuple 坐标point_tuple = namedtuple('point', ['x', 'y'])p = point_tuple(1, 2)print(p) # point(x=1, y=2)print(p[0]) # 1print(p.x) # 1print(p.x + p.y) # 3print("----------- 1 -----------------")# 2 deque 双向队列q = deque(['a', 'b', 'c'])print(q, type(q)) # deque(['a', 'b', 'c']) <class 'collections.deque'># 从右边增加值q.append('x')q.append('y')print(q, type(q)) # deque(['a', 'b', 'c', 'x', 'y']) <class 'collections.deque'># 从右边删除值q.pop()q.pop()print(q, type(q)) # deque(['a', 'b', 'c']) <class 'collections.deque'># 从左边增值q.appendleft('x')q.appendleft('y')print(q, type(q)) # deque(['y', 'x', 'a', 'b', 'c']) <class 'collections.deque'># 从左边删除q.popleft()ret = q.popleft()print(ret) # xprint(q, type(q)) # deque(['a', 'b', 'c']) <class 'collections.deque'>print("----------- 2 -----------------")# 3 defaultdict 默认值 字典my_dict = defaultdict(list) # 默认值 为listmy_dict['key1']my_dict['key2']my_dict['key3']print(my_dict) # defaultdict(<class 'list'>, {'key1': [], 'key2': [], 'key3': []})values = [11, 22, 33, 44, 55, 77, 88, 99, 90]for val in values:if val > 66:my_dict['key1'].append(val)else:my_dict['key2'].append(val)print(my_dict) # defaultdict(<class 'list'>, {'key1': [77, 88, 99, 90], 'key2': [11, 22, 33, 44, 55], 'key3': []})print("----------- 3 -----------------")# 构建一个字典,字典的key 从1~100,对应的值都是666# {1:666,2:666,3:666......}# 方法1dic = dict.fromkeys(range(1,101),666)print(dic)print("----------- 4 -----------------")# 方法2print({key:666 for key in range(1,101)})print("----------- 5 -----------------")# 方法3def func():return 666# my_dict = defaultdict(func)my_dict = defaultdict(lambda : 666)for i in range(1,101):my_dict[i]print(my_dict)print("----------- 6 -----------------")# Counter 统计元素个数# s1 = '电脑电脑sldfjslffdsaf's1 = ['电脑','电脑','电脑','电脑','书']c = Counter(s1)print(c, type(c)) # Counter({'电脑': 4, '书': 1}) <class 'collections.Counter'>print(c['f']) # 0print(c['d']) # 0print(c['电脑']) # 4print(dict(c), type(dict(c))) # {'电脑': 4, '书': 1} <class 'dict'>
shutil模块
#!/usr/bin/env python3# author:Alnk(李成果)import shutil# 将文件内容拷贝到另一个文件中shutil.copyfileobj(open('log1','r'),open('log2','w'))# 复制文件shutil.copyfile('log1','log.bak')# 递归拷贝文件夹# shutil.copytree('./NB1', './nbb', ignore=shutil.ignore_patterns('*.pyc', 'tmp*'))# 打包和压缩import timeimport tarfileshutil.make_archive('NB1-%s' % time.strftime('%Y-%m-%d'), 'gztar', root_dir='NB1')# 解压t = tarfile.open('NB12019-01-10.tar.gz', 'r')t.extractall('ttt')t.close()
包
目录结构
├── aaa│ ├── __init__.py│ └── m2.py│ ├── bbb│ │ ├── __init__.py│ │ └── m3.py├── main.py
main.py文件
#!/usr/bin/env python3# author:Alnk(李成果)import sys# 模块被引用发生了三件事# 1,创建一个以模块名命名的名称空间# 2,执行模块代码将模块里面的代码加载到模块名命名的名称空间的内存中# 3,调用模块内的名字必须通过模块名. 的方式调用print(sys.path)print("-------- 1 ------------------------------------")import aaa# 包也是模块,他是模块的集合体,所以引用包也会发生三件事情:# 1,创建一个以包名命名的名称空间。# 2,执行包中的__init__文件,将__init__里面的代码块加载到以包名明命的名称空间的内存中。# 3,调用包内的名字必须通过包名. 的方式调用。print(aaa.x)print(aaa.y)aaa.func1()print(aaa.m2)print(aaa.m2.xx)aaa.m2.func2()print("-------- 2 ------------------------------------")# 引用bbb这个包怎么做?print(aaa.bbb)print(aaa.bbb.oo)print(aaa.bbb.xxoo)print("-------- 3 ------------------------------------")# 想要在此文件引用 bbb包的m3模块 怎么做?# 第一步 在此文件 import aaa# 第二步:在aaa 的 __init__ 添加 from aaa import bbb# 第三步:在bbb 的 __init__ 添加 from aaa.bbb import m3# 完成以上三步,那么我在此执行文件就可以引用bbb包的m3模块里面的名字import aaaaaa.bbb.m3.func3()print("-------- 4 ------------------------------------")# 上面的需求满可以这么做:# from aaa.bbb import func3# func3()# 总结:# from a.b import c .的左边一定是个包,import 后面一定一个具体的名字# 包里面的__init__ 如果想要引用模块必须是 from ....import ... 不能直接 import# from a.b.c.d import e.f.g 错误# from a.b.c.d import e
aaa/__init__.py
#!/usr/bin/env python3# author:Alnk(李成果)x = 111y = 222def func1():print(555)# 如何让 main.py 这个执行文件找到m2文件?from aaa import m2# from aaa import *# 找到bbb这个包from aaa import bbb
aaa/m2.py
#!/usr/bin/env python3# author:Alnk(李成果)xx = '老鼠药'def func2():print('in m2 ')
aaa/bbb/__init__.py
#!/usr/bin/env python3# author:Alnk(李成果)from aaa.bbb import m3 # 从执行文件的当前目录开始# from aaa.bbb.m3 import * # 从执行文件的当前目录开始(上面的需求可以这么做)oo = 'tom'xxoo = 'www......'
aaa/bbb/m3.py
#!/usr/bin/env python3# author:Alnk(李成果)def func3():print('in m3')
相对导入和绝对导入
目录结构
lichengguo@lichengguodeMacBook-Pro day16 模块与包 random % tree├── main.py├── nb│ ├── __init__.py│ ├── m1.py│ └── m2.py
main.py
#!/usr/bin/env python3# author:Alnk(李成果)# 绝对导入: 以执行文件的sys.path为起始点开始导入,称之为绝对导入# 优点: 执行文件与被导入的模块中都可以使用# 缺点: 所有导入都是以sys.path为起始点,导入麻烦# import nb# nb.f1()# nb.f2()# nb.f3()# nb.f4()# 相对导入: 参照当前所在文件的文件夹为起始开始查找,称之为相对导入# 符号: .代表当前所在文件的文件加,..代表上一级文件夹,...代表上一级的上一级文件夹# 优点: 导入更加简单# 缺点: 只能在导入包中的模块时才能使用from nb import m1from nb import m1m1.f1()m1.f2()
nb/__init__.py
#!/usr/bin/env python3# author:Alnk(李成果)# 绝对导入# from nb.m1 import f1, f2# from nb.m2 import f3, f4# 相对导入from .m1 import f1, f2from .m2 import f3, f4
nb/m1.py
#!/usr/bin/env python3# author:Alnk(李成果)def f1():print('in f1')def f2():print('in f2')
nb/m2.py
#!/usr/bin/env python3# author:Alnk(李成果)def f3():print('in f3')def f4():print('in f4')
练习题1
#!/usr/bin/env python3# author:Alnk(李成果)# 1、计算两个格式化时间之间差了多少年月日时分秒# 例如 '1997-10-1 08:00:00' 和 '1997-10-2 09:00:00'import timedef diff_time(t1, t2):t1_struct = time.strptime(t1,'%Y-%m-%d %H:%M:%S')t1_stamp = time.mktime(t1_struct)t2_struct = time.strptime(t2,'%Y-%m-%d %H:%M:%S')t2_stamp = time.mktime(t2_struct)if t1_stamp > t2_stamp:diff_t = t1_stamp - t2_stampelse:diff_t = t2_stamp - t1_stampdiff_t_struct = time.gmtime(diff_t)print('两个时间相差了 [%s]年 [%s]月 [%s]日 [%s]时 [%s]分 [%s]秒'% (diff_t_struct.tm_year-1970, diff_t_struct.tm_mon-1,diff_t_struct.tm_mday-1, diff_t_struct.tm_hour,diff_t_struct.tm_min, diff_t_struct.tm_sec))t1 = '1997-10-1 08:00:00't2 = '1997-10-2 09:00:00'diff_time(t1, t2)print("------------------- 1 -----------------------------------------")# 2、计算当前时间所在月1号的时间戳import timedef get_time():now_t = time.strftime('%Y-%m')uct_t = time.strptime(now_t, '%Y-%m')stamp_t = time.mktime(uct_t)return stamp_tret = get_time()print(ret) # 1617206400.0# print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(ret))) # 2021-04-01 00:00:00print("------------------- 2 -----------------------------------------")# 3、生成一个6位随机验证码(包含数字和大小写字母)import randomdef get_code(n=6, flag=True):code = ''for i in range(n):selectd = random.randint(0, 9)if flag:alp = random.randint(65, 90)selectd = random.choice([selectd, chr(alp)])code += str(selectd)return coderet = get_code()print(ret)print("------------------- 3 -----------------------------------------")# 4、发红包、制定金额和个数,随机分配红包金额def hb(num, money):# 定义空列表用来存储抽奖金额lst = []# 金额乘以100,便于计算,后续加入到列表在除以100money = int(money * 100)# 判断传递参数的合法性if type(num) is int and num >=1 and (type(money) is int or type(money) is float):# for循环应该比num少一次,例如2个红包个数,for循环1次就可以for i in range(1, num):# 保证不出现抽中0元的现象p = random.randint(1, money - (num - i))lst.append(p / 100)# 需要减去已经抽取的红包金额money = money - pelse:# 循环结束了,把剩余的红包总金额放入到一个红包内lst.append(money / 100)return lstelse:print('参数有误!')ret = hb(3, 0.04)print(ret)print("------------------- 4 -----------------------------------------")# 5、分别列出给定目录下所有的文件和文件夹import osdef lis_file_path(path):dir_list = []file_list = []# 拼接路径ret_list = os.listdir(r'%s' % path)for i in ret_list:ret = os.path.join(path + '/%s' % i)if os.path.isfile(ret):file_list.append(i)elif os.path.isdir(ret):dir_list.append(i)return dir_list,file_listret = lis_file_path(r'/tmp')print('目录:', ret[0])print('文件:', ret[1])print("------------------- 5 -----------------------------------------")# 6、获取当前文件所在目录import osret = os.path.abspath(__file__)print(os.path.dirname(ret))print("------------------- 6 -----------------------------------------")# 7、在当前目录下创建一个文件夹、在这个文件夹下创建一个文件import osdef mk():# 获取被运行的PY文件绝对目录now_abs_dir = os.path.dirname(os.path.abspath(__file__))# 拼接路径ret_dir = os.path.join(now_abs_dir + '/new_dir')# 创建一个文件夹if not os.path.isdir(ret_dir):os.mkdir(ret_dir)# 拼接路径ret_file = os.path.join(ret_dir + '/test.txt')# 创建一个文件with open(r'%s' % ret_file, encoding='utf-8', mode='w') as f:passmk()print("------------------- 7 -----------------------------------------")# 8、计算某路径下所有文件和文件夹的总大小import os# 文件总大小total_size = 0def lis_file_path(path):global total_size# 获取指定目录下的文件和子目录,返回一个列表ret_list = os.listdir(r'%s' % path)for i in ret_list:# 拼接路径ret = os.path.join(path + '/%s' % i)# 如果是文件夹继续递归if os.path.isdir(ret):lis_file_path(ret)# 如果是文件就直接计算大小,算入总值elif os.path.isfile(ret):size = os.path.getsize(ret)total_size += sizereturn "%s%s" % (total_size/1024/1024, "MB")ret = lis_file_path('/Users/lichengguo/Documents/98-Python/python3-02/')print(ret)print("------------------- 8 -----------------------------------------")
练习题2
#!/usr/bin/env python3# author:Alnk(李成果)"""需求:实现加减乘除及拓号优先级解析用户输入1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )等类似公式后,必须自己解析里面的(),+,-,*,/符号和公式注意:不能调用eval等类似功能偷懒实现"""import redef calc(s):"""计算加减乘除"""# 去掉空格s = s.replace(' ', '')# 替换运算符号s = s.replace('--', '+').replace('++', '+').replace('-+', '-').replace('+-', '-')# 计算乘除while re.search('[.\d]+[*/]+[-+]?[.\d]+', s):# 匹配第一个乘除公式res = re.search('[.\d]+[*/]+[-+]?[.\d]+', s).group()# 判断乘除if res.count('*'):res_list = res.split('*')ret = float(res_list[0]) * float(res_list[1])else:res_list = res.split('/')ret = float(res_list[0]) / float(res_list[1])# 把结果替换回原来的公式中,并且替换运算符s = s.replace(res, str(ret)).replace('--', '+').replace('++', '+').replace('-+', '-').replace('+-', '-')# 计算加减# 找到所有的 正数或者负数,生成一个列表s_list = re.findall('[-]?[.\d]+', s)sum = 0# 循环列表,都做加法(减法可以看作加一个负数)for i in s_list:sum += float(i)return sumdef strip_kuohao(s):# 去掉空格s = s.replace(' ', '')# 替换运算符号s = s.replace('--', '+').replace('++', '+').replace('-+', '-').replace('+-', '-')# 匹配最里层的括号while re.search('\([^\(\)]+\)', s):# 替换运算符号s = s.replace('--', '+').replace('++', '+').replace('-+', '-').replace('+-', '-')# 获取匹配到的最里层的括号公式kuohao_res = re.search('\([^\(\)]+\)', s).group()# 去掉括号,传入calc函数进行加减乘除运算kuohao_res_strip = kuohao_res.strip('(,)')ret = calc(kuohao_res_strip)# 结果替换到原来的公式中s = s.replace(kuohao_res, str(ret))else:# 最后没有括号的公式还要进行一次加减乘除运算,算出最后的结果ret = calc(s)s = s.replace(s, str(ret))return ss = '1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )'ret = strip_kuohao(s)print(ret)print(eval(s))
Python语言系列-05-模块和包的更多相关文章
- Python 入门基础13 --模块与包
本节内容: 一.模块及使用 1.模块及使用 2.起别名.from导入 3.自执行与模块 二.包的使用 2.1 包中模块的使用:import 2.2 包的嵌套 2.3 包中模块的使用:from ...i ...
- 2015/9/15 Python基础(12):模块和包
模块是用来组织 Python 代码的方法,而包则是用来组织模块的. 当代码量很大时,我们一般会把代码分成几个有组织的代码段,然后每个代码段之间有一定的联系.代码单之间是共享的,所以Python允许调入 ...
- python(33)- 模块与包
一 模块 1 什么是模块? 一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. 2 为何要使用模块? 如果你退出python解释器然后重新进入,那么你之前定义的函 ...
- Python Revisited Day 05(模块)
目录 5.1 模块与包 5.1.1 包 5.2 Python 标准库概览 5.2.1 字符串处理 io.StringIO 类 5.2.3 命令行设计 5.2.4 数学与数字 5.2.5 时间与日期 5 ...
- python之旅:模块与包
一.模块介绍 前言:引用廖雪峰大神的,说的很好!!! 在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护. 为了编写可维护的代码,我们把很多函数分组,分别放 ...
- Python基础入门(模块和包)
1 模块 1.1 什么是模块 在 Python 中,一个 .py 文件就称之为一个模块(Module). 我们学习过函数,知道函数是实现一项或多项功能的一段程序 .其实模块就是函数功能的扩展.为什么这 ...
- Python学习笔记 - day9 - 模块与包
模块与包 一个模块就是一个包含了Python定义和声明的文件,文件名就是模块名加上.py的后缀,导入一个py文件,解释器解释该py文件,导入一个包,解释器解释该包下的 __init__.py 文件,所 ...
- 【python基础语法】模块和包管理,文件的操作(第8天课堂笔记)
''' 模块和包管理 模块和包的定义: 模块:模块是一个Python文件,以.py结尾,包含了Python对象定义和Python语句 包:Python中的包就是一个包含__init__.py文件的目录 ...
- Python语言学习:模块
一.模块 1. 模块(Module):以.py结尾的文件,包含python对象定义和python语句.使代码段更容易理解和使用. 模块分为两种:标准库(直接导入的库)和第三方库(需要下载安装的库). ...
随机推荐
- 对象池技术和通用实现GenericObjectPool
对象池技术其实蛮常见的,比如线程池.数据库连接池 他们的特点是:对象创建代价较高.比较消耗资源.比较耗时: 比如 mysql数据库连接建立就要先建立 tcp三次握手.发送用户名/密码.进行身份校验.权 ...
- Centos-Springboot项目jar包自启动
CentOS环境下部署Springboot项目的jar包开机自启动. 部署环境 Centos 7.5 Springboot 2.1.x 操作步骤 修改pom 在pom.xml文件中<plugin ...
- 增强采样软件PLUMED的安装与使用
技术背景 增强采样(Enhanced Sampling)是一种在分子动力学模拟中常用的技术,其作用是帮助我们更加快速的在时间轴上找到尽可能多的体系结构及其对应的能量.比如一个氢气的燃烧反应,在中间过程 ...
- 深入理解 SynchronizationContext
深入理解 SynchronizationContext 目录 深入理解 SynchronizationContext SynchronizationContext(后续以SC简称) 是什么? 1.1 ...
- 深入浅出图神经网络 第6章 GCN的性质 读书笔记
第6章 GCN的性质 第5章最后讲到GCN结束的有些匆忙,作为GNN最经典的模型,其有很多性质需要我们去理解. 6.1 GCN与CNN的区别与联系 CNN卷积卷的是矩阵某个区域内的值,图卷积在空域视角 ...
- ESP32构建系统 (传统 GNU Make)
概述: 一个 ESP-IDF 项目可以看作是多个不同组件的集合,ESP-IDF 可以显式地指定和配置每个组件.在构建项目的时候,构建系统会前往 ESP-IDF 目录.项目目录和用户自定义目录(可选)中 ...
- [刘阳Java]_Spring AOP入门_第7讲
AOP技术个人认为是能够完善(改善)面向对象编程OOP.为什么这么说,我们得先从AOP的概念说起,然后通过一段简单的例子加以佐证.这样子大家就可以慢慢地了解AOP 1. AOP概念 AOP为Aspec ...
- Spring Boot 2.x基础教程:使用Elastic Job实现定时任务
上一篇,我们介绍了如何使用Spring Boot自带的@Scheduled注解实现定时任务.文末也提及了这种方式的局限性.当在集群环境下的时候,如果任务的执行或操作依赖一些共享资源的话,就会存在竞争关 ...
- 每天五分钟Go - Map
map的定义 var m map[type]type fmt.Println(m) 此种方法定义的m为nil //打印的结果为: map[] map的创建 1.使用make创建 var m1 = ma ...
- 【排序+模拟】魔法照片 luogu-1583
题目描述 一共有n(n≤20000)个人(以1--n编号)向佳佳要照片,而佳佳只能把照片给其中的k个人.佳佳按照与他们的关系好坏的程度给每个人赋予了一个初始权值W[i].然后将初始权值从大到小进行排序 ...