【C# 集合】HashTable .net core 中的Hashtable的实现原理
上一篇我介绍了Hash函数
这篇我来说一下Hash函数在 HashTable中的应用。
HashTable的特性:
1、装载因子:.net core 0.72 ,java 0.75
2、冲突解决方案:Hashtable使用了闭散列法来解决冲突,java采用 开散列法解决冲突.
3、bucket(桶):用来转载hash函数的返回值和建立key和hash返回值的关系
4、Hash函数以及算法
5、HashTable是可以序列化的。是线程安全的。HashTable之所以是线程安全的,是因为方法上都加了synchronized关键字。
6、可枚举
7、在新的开发中不建议使用HashTable,建议使用Dictionary<Tkey,Tvalue>和ConcurrencyDictionary<Tkey,Tvalue>
.net core 中的Hashtable的实现原理
它通过一个结构体bucket来表示哈希表中的单个元素,这个结构体中有三个成员:
private struct Bucket
{
public object? key;
public object? val;
public int hash_coll; // bucket结构体的hash_coll字段所存储的是h(key, i)的值而不是哈希地址
}
(1) key :表示键,即哈希表中的关键字。
(2) val :表示值,即跟关键字所对应值。
(3) hash_coll :它是一个int类型,用于表示键所对应的哈希码,.net core bucket结构体的hash_coll字段所存储的是h(key, i)的值而不是哈希地址 。
int类型占据32个位的存储空间,它的最高位是符号位,为“0”时,表示这是一个正整数;为“1”时表示负整数。hash_coll使用最高位表示当前位置是否发生冲突,为“0”时,也就是为正数时,表示未发生冲突;为“1”时,表示当前位置存在冲突。之所以专门使用一个位用于存放哈希码并标注是否发生冲突,主要是为了提高哈希表的运行效率。关于这一点,稍后会提到。
Hashtable解决冲突使用了双重散列法,但又跟前面所讲的双重散列法稍有不同。它探测地址的方法如下:
h(key, i) = h1(key) + i * h2(key)
其中哈希函数h1和h2的公式如下:
h1(key) = key.GetHashCode()
h2(key) = 1 + (((h1(key) >> 5) + 1) % (hashsize - 1))
由于使用了二度哈希,最终的h(key, i)的值有可能会大于hashsize,所以需要对h(key, i)进行模运算,最终计算的哈希地址为:
哈希地址 = h(key, i) % hashsize
【注意】:bucket结构体的hash_coll字段所存储的是h(key, i)的值而不是哈希地址。
哈希表的所有元素存放于一个名称为buckets(又称为数据桶) 的bucket数组之中,下面演示一个哈希表的数据的插入和删除过程,其中数据元素使用(键,值,哈希码)来表示。注意,本例假设Hashtable的长度为11,即hashsize = 11,这里只显示其中的前5个元素。
(1)插入元素(k1,v1,1)和(k2,v2,2)。
由于插入的两个元素不存在冲突,所以直接使用h1(key) % hashsize的值做为其哈希码而忽略了h2(key)。其效果如图8.6所示。

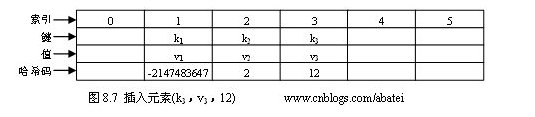
(2) 插入元素(k3,v3,12)
新插入的元素的哈希码为12,由于哈希表长为11,12 % 11 = 1,所以新元素应该插入到索引1处,但由于索引1处已经被k1占据,所以需要使用h2(key)重新计算哈希码。
h2(key) = 1 + (((h1(key) >> 5) + 1) % (hashsize - 1))
h2(key) = 1 + ((12 >> 5) + 1) % (11 - 1)) = 2
新的哈希地址为 h1(key) + i * h2(key) = 1 + 1 * 2 = 3,所以k3插入到索引3处。而由于索引1处存在冲突,所以需要置其最高位为“1”。
(10000000000000000000000000000001)2 = (-2147483647)10
最终效果如图8.7所示。
(3) 插入元素(k4,v4,14)
k4的哈希码为14,14 % 11 = 3,而索引3处已被k3占据,所以使用二度哈希重新计算地址,得到新地址为14。索引3处存在冲突,所以需要置高位为“1”。
(12)10 = (00000000000000000000000000001100)2 高位置“1”后
(10000000000000000000000000001100)2 = (-2147483636)10
最终效果如图8.8所示。

(4) 删除元素k1和k2
Hashtable在删除一个存在冲突的元素时(hash_coll为负数),会把这个元素的key指向数组buckets,同时将该元素的hash_coll的低31位全部置“0”而保留最高位,由于原hash_coll为负数,所以最高位为“1”。
(10000000000000000000000000000000)2 = (-2147483648)10
单凭判断hash_coll的值是否为-2147483648无法判断某个索引处是否为空,因为当索引0处存在冲突时,它的hash_coll的值同样也为-2147483648,这也是为什么要把key指向buckets的原因。这里把key指向buckets并且hash_coll值为-2147483648的空位称为“有冲突空位”。如图8.8所示,当k1被删除后,索引1处的空位就是有冲突空位。
Hashtable在删除一个不存在冲突的元素时(hash_coll为正数),会把键和值都设为null,hash_coll的值设为0。这种没有冲突的空位称为“无冲突空位”,如图8.9所示,k2被删除后索引2处就属于无冲突空位,当一个Hashtable被初始化后,buckets数组中的所有位置都是无冲突空位。

哈希表通过关键字查找元素时,首先计算出键的哈希地址,然后通过这个哈希地址直接访问数组的相应位置并对比两个键值,如果相同,则查找成功并返回;如果不同,则根据hash_coll的值来决定下一步操作。当hash_coll为0或正数时,表明没有冲突,此时查找失败;如果hash_coll为负数时,表明存在冲突,此时需通过二度哈希继续计算哈希地址进行查找,如此反复直到找到相应的键值表明查找成功,如果在查找过程中遇到hash_coll为正数或计算二度哈希的次数等于哈希表长度则查找失败。由此可知,将hash_coll的高位设为冲突位主要是为了提高查找速度,避免无意义地多次计算二度哈希的情况。
【C# 集合】HashTable .net core 中的Hashtable的实现原理的更多相关文章
- Java中的集合(十三) 实现Map接口的Hashtable
Java中的集合(十三) 实现Map接口的Hashtable 一.Hashtable简介 和HashMap一样,Hashtable采用“拉链法”实现一个哈希表,它存储的内容是键值对(key-value ...
- 特殊集合(stack、queue、hashtable的示例及练习)
特殊集合:stack,queue,hashtable stack:先进后出,一个一个的赋值一个一个的取值,按照顺序. .count 取集合内元素的个数 .push() ...
- HashTable和HashSet中的类型陷阱
HashTable和HashSet中的类型陷阱 发现这个陷阱的起因是这样的:我现在有上百万字符串,我准备用TopK算法统计出出现次数做多的前100个字符串. 首先我用Hashtable统计出了每个字符 ...
- java集合框架(二):HashTable
HashTable作为集合框架中的一员,现在是很少使用了,一般都是在面试中会问到其与HashMap的区别.为了能在求职的时候用上场,我们有必要对其原理进行解读. HashTable的实现原理跟Hash ...
- java集合框架collection(4)HashMap和Hashtable的区别
HashMap和Hashtable的区别 HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别.主要的区别有:线程安全性,同步(synchronizatio ...
- Java集合系列(四):HashMap、Hashtable、LinkedHashMap、TreeMap的使用方法及区别
本篇博客主要讲解Map接口的4个实现类HashMap.Hashtable.LinkedHashMap.TreeMap的使用方法以及三者之间的区别. 注意:本文中代码使用的JDK版本为1.8.0_191 ...
- Java中的HashTable详解
Hashtables提供了一个很有用的方法可以使应用程序的性能达到最佳. Hashtables(哈 希表)在计算机领域中已不 是一个新概念了.它们是用来加快计算机的处理速度的,用当今的标准来处理,速度 ...
- 在webservice中传递Hashtable
webservice中不支持hashtable的数据类型,那么如何在webservice中传递hashtable呢?我们可以通过将hashtable转化为webservice中支持的数组的类型来进行传 ...
- EF Core中如何通过实体集合属性删除从表的数据
假设在数据库中有两个表:Person表和Book表,Person和Book是一对多关系 Person表数据: Book表数据: 可以看到数据库Book表中所有的数据都属于Person表中"F ...
随机推荐
- 从带Per-Building数据的KML/COLLADA中创建3D Tiles
Cesium中文网:http://cesiumcn.org/ | 国内快速访问:http://cesium.coinidea.com/ 许多Cesium的使用者经常需要将整个城市的数十万个三维建筑可视 ...
- socket编程(struct报头)网络编程
目录 一:socket编程 1.简介 2.参数说明: 3.socket套接字方法 4.socket编程思路: 二:socket套接字编程 1.socket简易版编程 2.通信循环 三:通信循环及代码优 ...
- Vue2和Vue3技术整理1 - 入门篇 - 更新完毕
Vue2 0.前言 首先说明:要直接上手简单得很,看官网熟悉大概有哪些东西.怎么用的,然后简单练一下就可以做出程序来了,最多两天,无论Vue2还是Vue3,就都完全可以了,Vue3就是比Vue2多了一 ...
- ApacheCN Java 译文集 20210921 更新
新增了五个教程: Java 设计模式最佳实践 零.前言 一.从面向对象到函数式编程 二.创建型模式 三.行为模式 四.结构模式 五.函数式模式 六.让我们开始反应式吧 七.反应式设计模式 八.应用架构 ...
- Matplotlib 绘图秘籍·翻译完成
原文:Matplotlib Plotting Cookbook 协议:CC BY-NC-SA 4.0 欢迎任何人参与和完善:一个人可以走的很快,但是一群人却可以走的更远. 在线阅读 ApacheCN ...
- Redis-46面试题
1.什么是 Redis?简述它的优缺点? Redis 的全称是:Remote Dictionary.Server,本质上是一个 Key-Value 类型的内存数据库,很像 memcached,整个数据 ...
- Servlet中@WebServlet属性详解
感谢原文作者:想当一只小小攻城狮 原文链接:https://blog.csdn.net/weixin_45493751/article/details/100559683 在Servlet中,设置了@ ...
- Token+Redis实现接口幂等性
一.什么是 幂等性 在编程中,幂等性的特点就是其任意多次执行的效果和一次执行的效果所产生的影响是一样的. 二.Token+Redis的实现思路 1.数据提交前要向服务的申请 token(用户登录时可以 ...
- iOS 小技巧总结
1.获取准确的app启动所需时间 应用启动时间长短对用户第一次体验至关重要,同时系统对应用的启动.恢复等状态的运行时间也有严格要求,在应用超时的情况下系统会直接关闭应用.以下是几个常见场景下系统对Ap ...
- Python—列表元组和字典
Python-列表元组和字典 列表 元组 字典 列表: 列表是Python中的一种数据结构,他可以存储不同类型的数据.尽量存储同一种类型 列表索引是从0开始的,我们可以通过索引来访问列表的值. 列表的 ...