java集合专题 (ArrayList、HashSet等集合底层结构及扩容机制、HashMap源码)
一、数组与集合比较
数组:
1)长度开始时必须指定,而且一旦指定,不能更改
2)保存的必须为同一类型的元素
3)使用数组进行增加/删除元素-比较麻烦
集合:
1)可以动态保存任意多个对象,使用比较方便
2)提供了一系列方便的操作对象的方法: add、remove、set、 get等
3)使用集合添加,删除新元素-更加简洁
二、常见集合体系图
(1)常见单列集合
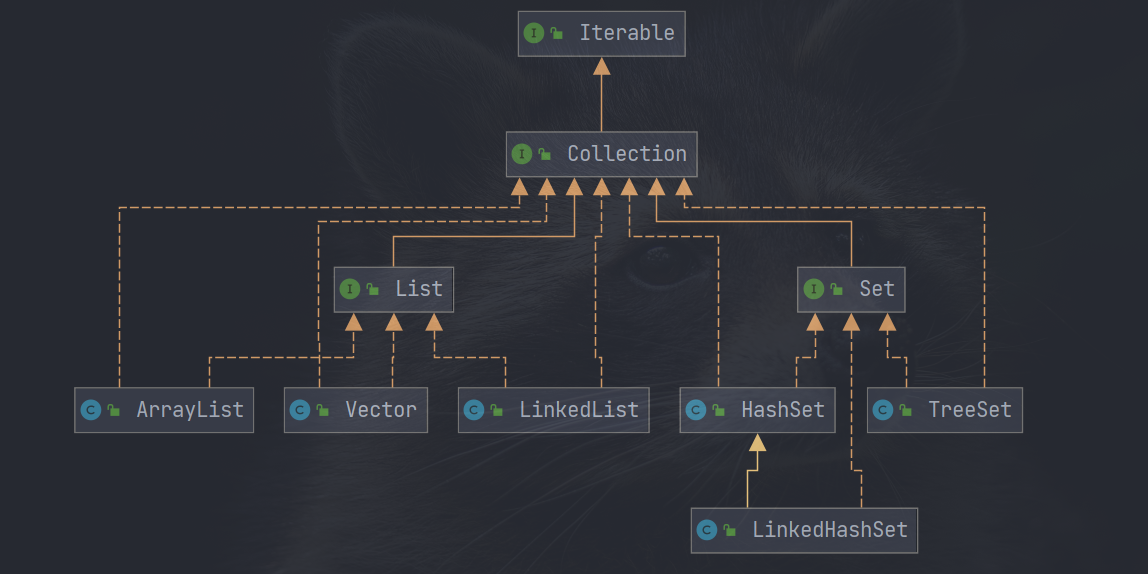
List: 有序可重复、支持索引、可根据索引值取数据、可以存入多个null值
Set: 无序不可重复、无索引、最多只包含一个null值
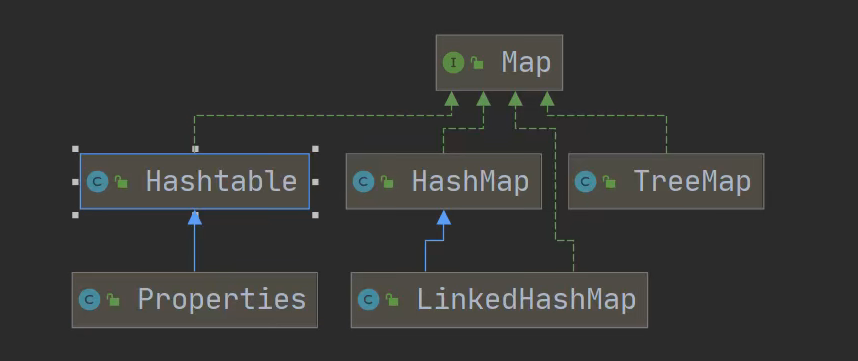
(2)常见双列集合
三、List集合
1.List接口介绍及常用方法
1) List集合类中元素有序(即添加顺序和取出顺序一致)、 且可重复[案例]
2) List集合中的每个元素都有其对应的顺序索引,即支持索引。[案例]
3) List容器中的元素都对应一 个整数型的序号记载其在容器中的位置,可以根
据序号存取容器中的元素。

2.ArrayList底层分析
2.1 ArrayList基本介绍
1) permits all elements, including null , ArrayList可以加入null,并且可以添加多个null
2) ArrayList底层是由可变数组来实现数据存储的
3) ArrayList基本等同于Vector ,除了ArrayList是线程不安全(执行效率高),在多线程情况下,不建议使用ArrayList
2.2 ArrayList的底层底层结构及扩容机制
1) ArrayList中维护了一个Object类型的数组elementData. [debug 看源码] transient Object[] elementData; //transient 表示瞬间、短暂的,表示该属性不会被序列化
2)当创建ArrayList对象时,如果使用的是无参构造器,则初始elementData容量为0, 第1次添加,则扩容elementData为10, 如大小不够需要再次扩容,则调用grow()扩容elementData为1.5倍。grow()内部数据拷贝使用Arrays.Copyof()。
3)如果使用的是指定大小的构造器,则初始elementData容量为指定大小, 如果需要扩容,则直接扩容elementData为1.5倍。
3.Vector底层分析
3.1 Vector基本介绍
1) Vector底层也是一个对象数组,protected Object[] elementData;
2) Vector是线程同步的,即线程安全,Vector类的操作方法带有synchronized
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);}
3)在开发中,需要线程同步安全时,考虑使用Vector
3.2 Vector与ArrayList的比较(扩容机制)

4.LinkedList底层分析
4.1 LinkedList基本介绍
1) LinkedList底层实现了双向链表和双端队列特点
2)可以添加任意元素(元素可以重复),包括null
3)线程不安全,没有实现同步
4.2 LinkedList底层结构
1) LinkedList底层维护了一个双向链表
2) LinkedList中维护了两个属性first和last分别指向首节点和尾节点
3)每个节点(Node对象) ,里面又维护了prev、next、 item三个属性,其中通过prev指向前一 个,通过next指向后个节点,而item就是真正存放数据的属性。最终实现双向链表
4)所以LinkedList的元素的添加和删除,不是通过数组完成的,相对来说效率较高,添加是添加在双向链表的尾部,remove()不指定索引默认删除的是第一个数据
4.3 ArrayList和LinkedList的比较

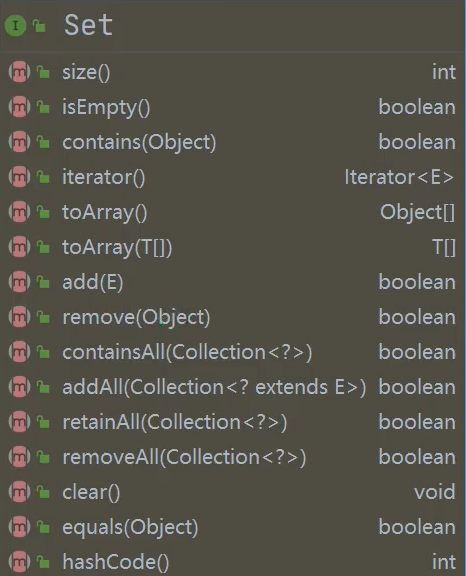
四、Set集合
1.Set接口介绍及常用方法
1)无序(添加和取出的顺序不一致) ,没有索引后面演示]
2)不允许重复元素,所以最多包含一个null
2.HashSet底层分析
2.1 HashSet基本介绍
1) HashSet实际上是HashMap(jdk1.7:数组+链表 jdk1.8:数组+链表+红黑树 ),看下源码
public HashSet() {
map = new HashMap<>();
}
2)可以存放null值,但是只能有一个null
3) HashSet不保证元素是有序的,取决于hash后,再确定索引的结果
4)不能有重复元素/对象在前面Set接口使用已经讲过
2.2 HashSet底层结构及源码解读
1. HashSet 底层是HashMap
2.添加一个元素时,先得到hash值-会转成->索引值
3.找到存储数据表table ,看这个索引位置是否已经存放的有元素
4.如果没有,直接加入
5.如果有,调用equals比较,如果相同,就放弃添加,如果不相同,则添加到最后
6.在Java8中,如果一条链表的元素个数到达TREEIFY THRESHOLD(默认是8),并且table的大小>=MIN TREEIFY CAPACITY(默认64),就会进行树化(红黑树)
public class Debug03 {
public static void main(String[] args) {
//添加实例
HashSet set = new HashSet();
set.add("java");
set.add("php");
set.add("java");
System.out.println(set);
/*
源码解读
1. 执行HashSet()
public HashSet() {
map = new HashMap<>();
}
2. 执行add()
public boolean add(E e) { //e="java"
return map.put(e, PRESENT)==null; // (static) PRESENT = new Object();
}
3. 执行put(),该方法会执行hash(key)得到key对应的hash值 算法 (h = key.hashCode()) ^ (h >>> 16) 避免碰撞
public V put(K key, V value) { //key="java" value=PRESENT 共享的
return putVal(hash(key), key, value, false, true);
}
4. 执行putVal()
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i; //定义了辅助变量
// table就是HashMap的一个数组,类型是Node[]
// if 语句表示如果当前table 是null或者 大小 = 0,就是第一次扩容,到16
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//(1)根据key,得到hash 去计算该key应该存放到table表的哪个索引位置,并把这个位置的对象,赋给 p
//(2)判断p 是否为null
//(2.1)如果p 为null,表示还没有存放元素,就创建一个Node(key="java",value=PRESENT)
//(2.2)就放在该位置 tab[i] = newNode(hash, key, value, null)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
// 一个开发技巧提示:在需要局部变量(辅助变量)时候,再创建
Node<K,V> e; K k;
// 如果当前索引位置对应的链表的第一个元素和准备添加的key的hash值一样
// 并且满足 下面两个条件之一:
//(1)准备加入的key 和 p 指向的Node节点的key是同一个对象
//(2)p指向的node节点的key的equals() 和准备加入的key比较后相同
// 就不能加入
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 再判断 p 是不是一颗红黑树,
// 如果是一颗红黑树,就调用 putTreeVal,来进行添加
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 如果table对应的索引位置,已经是一个链表,就使用for循环比较
//(1)依次和该链表的每一个元素比较后,都不相同,则加入到该链表的最后
// 注意在把元素添加到链表后,立即判断该链表是否已经达到8个结点
// 就调用treeifyBin() 对当前这个链表进行树化(转成红黑树)
// 注意,在转成红黑树时,要进行判断,判断条件
// if (tab == null | (n = tab.Length) < MIN_ TREEIFY_ CAPACITY(64) )
// resize() ;
// 如果上面条件成立,先table扩容。
// 只有上面条件不成立时,才进行转成红黑树
//(2)依次和该链表的每一个元素比较过程中,如果有相同情况,就直接break
else {
for (int binCount = 0; ; ++binCount) { //死循环
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//size 就是我们加入一个节点Node(k,v,h,next),size++
if (++size > threshold)
resize(); //扩容
afterNodeInsertion(evict);
return null;
}
*/
}
}
2.3 HashSet扩容及树化机制
1. HashSet底层是HashMap,第一次添加时,table 数组扩容到16,临界值(threshold)是16*加载因子(loadFactor)是0.75 = 12
2.如果table数组使用到了临界值12,就会扩容到16* 2 = 32,新的临界值就是32*0.75 = 24,依次类推正
3.在Java8中,如果条链表的元素个数到达TREEIFY THRESHOLD(默认是8 ),并且table的大小>=MIN TREEIFY CAPACITY(默认64),就会进行树化(红黑树),否则仍然采用数组扩容机制
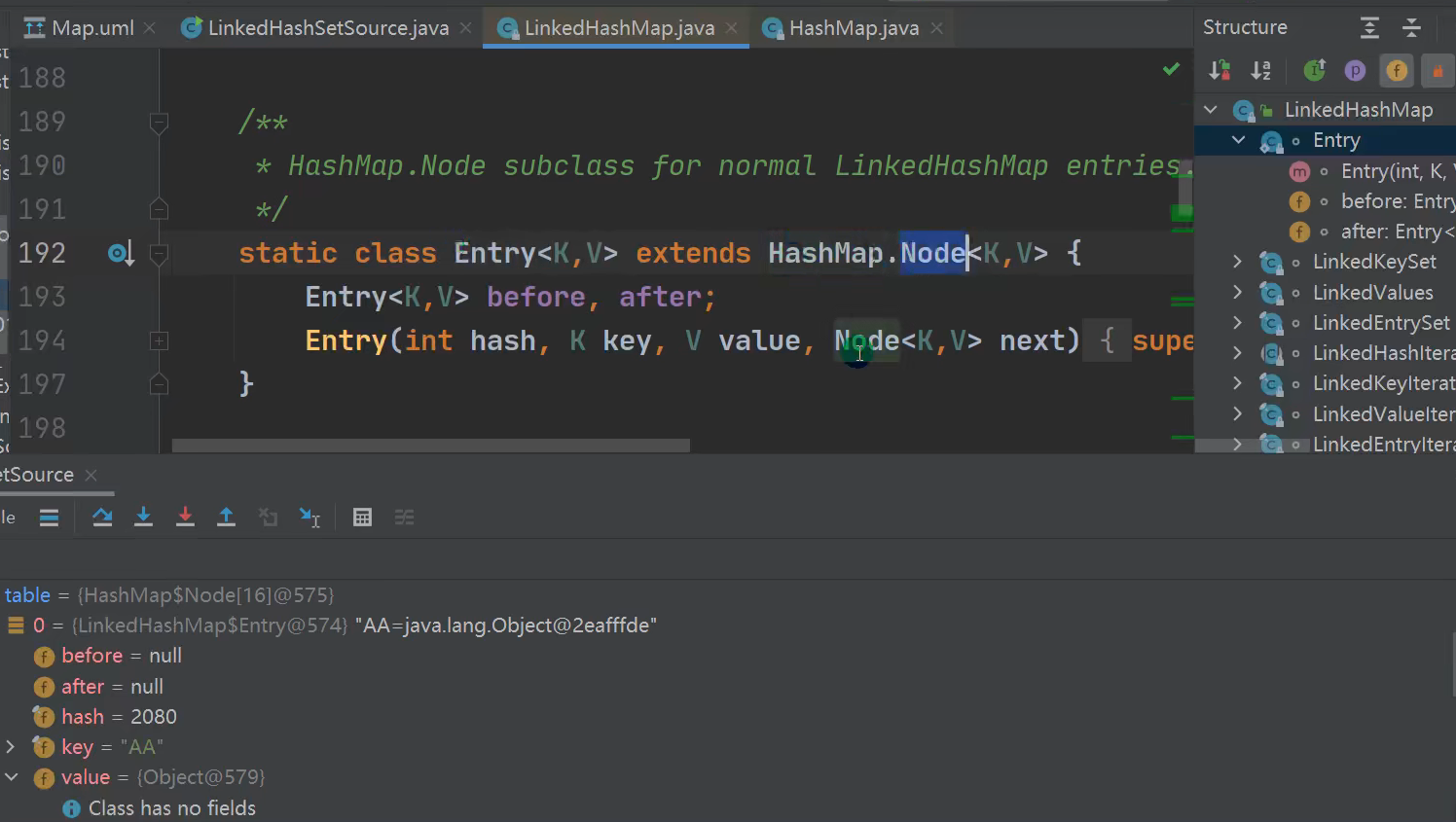
3.LinkedHashSet底层分析
1)LinkedHashSet加入顺序和取出元素,数据的顺序一致
2) LinkedHashSet 底层维护的是一个LinkedHashMap(是HashMap的子类)
3) LinkedHashSet 底层结构( 数组table+双向链表)
4) 第一次添加元素时,直接将数组tabLe扩容到16 ,存放的结点类型是LinkedHashMap$Entry 每一个节点有before、after分别指向前一个和后一个元素
5)数组是HashMap$Node[] 存放的元素/数据是L inkedHashMap$Entry类型
4.TreeSet底层分析
4.1 TreeSet基本介绍
1)当我们使用无参构造器, 创建TreeSet时,仍然是无序的,存储数据的底层结构是TreeMap$Entry
2)若希望添加的元素,按照字符串字典顺序来排序
3)使用Treeset提供的一一个构造器,可以传入-个比较器(匿名内部类) 并指定排序规则
4.2 TreeSet源码解读
public class TreeSet_ {
public static void main(String[] args) {//TreeSet treeSet = new TreeSet();
//4、简单看下源码
TreeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
// 下面 调用String的compareTo方法进行字符串 字典顺序 排序
// return ((String)o1).compareTo((String)o2);
// 如果按照长度大小排序 小-->大
return ((String)o1).length()-((String)o2).length();
}
});
treeSet.add("jack");
treeSet.add("tom");
treeSet.add("sp");
treeSet.add("a");
System.out.println(treeSet);
/*
源码解读:
1.构造器把传入的比较器对象,赋给了TreeSet的底层的TreeMap的属性this。comparator
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
2、在 调用treeSet.add("tom"),在底层会执行到
if (cpr != null) { //cpr 就是我们的匿名内部类(对象)
do {
parent = t;
//动态的绑定到我们的匿名内部类(对象)compare
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else { //如果相等,即返回0,这个key就没有加入
V oldValue = t.value;
if (replaceOld || oldValue == null) {
t.value = value;
}
return oldValue;
}
} while (t != null);
}
*/
}
}
五、Map集合
1.Map接口介绍及常用方法
1) Map与Collection并列存在。用于保存具有映射关系的数据:Key-Value
2) Map中的key和value 可以是任何引用类型的数据,会封装到HashMap$Node对象中
3) Map中的key不允许重复,原因和HashSet一样,前面分析过源码
4) Map中的value可以重复
5) Map的key可以为null, value也可以为null ,注意key为null,只能有一个,value 为null ,可以多个
6)常用String类作为Map的key
7) key和value之间存在单向一对一关系,即通过指定的key总能找到对应的value
8) Map存放数据的key-value示意图,一对k-v是放在一个HashMap$Node中的, 又因为Node实现了Entry 接口,有些书上也说一对k-v就是一个Entry



2.Map集合的六种遍历方式
public class Map01 {
public static void main(String[] args) {
Map map = new HashMap();
map.put(1, "张三");
map.put(2, "李四");
map.put(3, "王五");
map.put(4, "赵六");
map.put(5, "田七");
//第一组:先取出所有的key,通过key取出对应的value
Set set = map.keySet();
//(1)增强for
for (Object key : set) {
System.out.println(key + "-" + map.get(key));
}
//(2)迭代器
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(key + "-" + map.get(key));
}
//第二组:把所有的values取出
Collection values = map.values();
//这里可以使用所有的Collection使用的遍历方法
//(1)增强for
for (Object value : values) {
System.out.println(value);
}
//(2)迭代器
Iterator iterator1 = values.iterator();
while (iterator1.hasNext()) {
Object values2 = iterator1.next();
System.out.println(values2);
}
//第三组:通过EntrySet 获取 k-v
//(1)增强for
Set entrySet = map.entrySet();
for (Object entry : entrySet) {
//将entry 转成 Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey()+"-"+m.getValue());
}
//(2)迭代器
Iterator iterator2 = entrySet.iterator();
while (iterator2.hasNext()) {
Object entry = iterator2.next();
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey()+"-"+m.getValue());
}
}
}
3.HashMap底层分析
3.1 HashMap基本介绍
1) Map接口的常用实现类: HashMap、 Hashtable和Properties。
2) HashMap是Map接口使用频率最高的实现类。
3) HashMap是以key-val对的方式来存储数据[案例Entry ]
4) key不能重复,但是是值可以重复,允许使用null键和null值。
5)如果添加相同的key ,则会覆盖原来的key-val ,等同于修改.(key不会替换,val会替换)
6)与HashSet-样,不保证映射的顺序,因为底层是以hash表的方式来存储的.
7) HashMap没有实现同步,因此是线程不安全的
3.2 HashMap底层扩容(和HashSet相同)及源码解读
1) HashMap底层维护了Node类型的数组table,默认为null
2)当创建对象时,将加载因子(loadfactor)初始化为0.75.
3)当添加key-val时,通过key的哈希值得到在table的索引。然后判断该索引处是否有元素,如果没有元素直接添加。如果该索引处有元素,继续判断该元素的key和准备加入的key相是否等,如果相等,则直接替换val;如果不相等需要判断是树 结构还是链表结构,做出相应处理。如果添加时发现容量不够,则需要扩容
4)第1次添加,则需要扩容table容量为16,临界值(threshold)为12.
5)以后再扩容,则需要扩容table容量为原来的2倍,临界值为原来的2倍,即24,依次类推
6)在Java8中,如果条链表的元素个数超过TREEIFY THRESHOLD(默认是8),并且table的大小>= MIN TREEIFY CAPACITY(默认64),就会进行树化(红黑树)
public class HashMapDebug {
public static void main(String[] args) {
HashMap hashMap=new HashMap();
hashMap.put("java",10);
hashMap.put("php",20);
hashMap.put("java",30); //替换 10
System.out.println(hashMap);
/*HashMap源码解读
1、执行构造器 new HashMap()
初始化加载因子 loadfactor=0.75
HashMap$Node[] table = null
2、执行put() 调用 hash方法,计算key的hash值 (h = key.hashCode()) ^ (h >>> 16)
public V put(K key, V value) { key="java" value=10
return putVal(hash(key), key, value, false, true);
}
3、执行putVal()
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i; //辅助变量
//如果底层的table数组为空,或者长度等于0,就进行第一次扩容到16
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//取出hash值对应的table的索引位置的Node,如果为null,就直接把加入的k-v创建成一个Node,加入该位置即可
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k; //辅助变量
//如果tabLe的索引位置的key的hash相同和新的key的hash值相同,
//并 满足(tabLe现有的结点的key和准备添加的key是同一个对象 || equals返回真)
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode) //如果当前的table的已有的Node 是红黑树,就按照红黑树的方式处理
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else { //如果找到的节点 后面是链表,就循环比较
for (int binCount = 0; ; ++binCount) { //死循环
if ((e = p.next) == null) { //如果整个链表,没有和他相同,就加在该链表的最后
p.next = newNode(hash, key, value, null);
//加入后,判断当前链表的个数,是否到达8个,到达8个后
//就调用treeifyBin()进行红黑树的转化
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash && //如果在循环比较过程中,发现有相同,就break,替换value
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value; //替换,key对应的value
afterNodeAccess(e);
return oldValue;
}
}
++modCount; //每增加一个Node,就size++
if (++size > threshold) //如 size > 临界值,就扩容
resize();
afterNodeInsertion(evict);
return null;
}
5. 关于树化(转成红黑树)
//如果table为null,或者大小还没有到64,暂时不树化,而是进行扩容
//否则才会正真的树化 -> 剪枝
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
......
*/
}
}
4.HashTable底层分析
4.1 HashTable基本介绍
1) 存放的元素是键值对: 即K-V
2) hashtable的键和值都不能为null, 否则会抛出NullPointerException
3) hashTable使用方法基本上和HashMap-样
4) hashTable是线程安全的(synchronized), hashMap是线程不安全的
4.2 HashTable底层扩容机制
1) 底层有数组Hashtable$Entry[] 初始化大小为11
2) 临界值threshold 8 = 11 * 0.75
3) 扩容:按照自己的扩容机制来进行即可。
4) 执行方法addEntry(hashp key, value, index); 添加K-V 封装到Entry
5) 当if (count >= threshoLd) 满足时,就进行扩容
6) 按照int newCapacity = (oldCapacity << 1) + 1;的大小扩容。
4.3 HashTable和HashMap对比

5.TreeMap底层分析
5.1 TreeMap基本介绍
使用默认 的构造器,创建TreeMap, 是无序的( 也是没有排序的)
compare方法的比较条件若相同 则不添加 而不是替换
5.2 TreeMap底层源码
public class TreeMap_ {
public static void main(String[] args) {
//TreeMap treeMap= new TreeMap();
TreeMap treeMap = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//要求:按照传入的 k(String) 的 字典顺序 进行排序
//return ((String)o1).compareTo((String)o2);
//按照字符串的长度大小排序 小-->大
return ((String)o1).length()-((String)o2).length();
}
});
treeMap.put("jack","杰克");
treeMap.put("tom","汤姆");
treeMap.put("kiri","凯瑞");//"kiri"长度和"jack"长度相等无法加入
treeMap.put("smith","史密斯");
System.out.println(treeMap);
/*
源码解读:
1. 构造器:把实现了 Comparator接口的匿名内部类(对象),传给了TreeMap的comparator
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
2. 调用put方法
2.1 第一次添加,把k-v封装到Entry对象,放入root
Entry<K,V> t = root;
if (t == null) {
addEntryToEmptyMap(key, value);
return null;
}
2.2 以后添加
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do { //遍历所有的key,给当前的key找到适当的位置
parent = t;
cmp = cpr.compare(key, t.key); //动态的绑定到我们的匿名内部类的compare
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else { //如果遍历过程中,发现准备添加的key 和当前已有的key相等(compare比较),就不添加
V oldValue = t.value;
if (replaceOld || oldValue == null) {
t.value = value;
}
return oldValue;
}
} while (t != null);
}
*/
}
}
六、Collections工具类
1) Collections是个操作 Set、List和Map等集合的工具类
2) Collections中提供了一系列静态的方法对集合元素进行排序、查询和修改等操作
排序操作
1) reverse(List):反转List中元素的顺序
2) shuffle(List):对List集合元素进行随机排序
3) sort(List):根据元素的自然顺序对指定List集合元素按升序排序
4) sort(List, Comparator): 根据指定的Comparator产生的顺序对List集合元素进行排序
5) swap(List, int, int): 将指定list集合中的i处元素和j处元素进行交换
查找、替换
1) Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
2) Object max(Collection, Comparator): 根据Comparator指定的顺序,返回给定集合中的最大元素
3) Object min(Collection)
4) Object min(Collection, Comparator)
5) int frequency(Collection, Object): 返回指定集合中指定元素的出现次数
6)void copy(List dest,List src):将src中的内容复制到dest中
7) boolean replaceAll(List list, Object oldVal, Object newVal):使用新值替换List对象的所有旧值
本笔记参考视频:https://www.bilibili.com/video/BV1YA411T76k?p=55(其他的集合源码的debug可以去看老韩讲解的视频)
java集合专题 (ArrayList、HashSet等集合底层结构及扩容机制、HashMap源码)的更多相关文章
- Java集合---HashMap源码剖析
一.HashMap概述二.HashMap的数据结构三.HashMap源码分析 1.关键属性 2.构造方法 3.存储数据 4.调整大小 5.数据读取 ...
- [转载] Java集合---HashMap源码剖析
转载自http://www.cnblogs.com/ITtangtang/p/3948406.html 一.HashMap概述 HashMap基于哈希表的 Map 接口的实现.此实现提供所有可选的映射 ...
- Java集合:HashMap源码剖析
一.HashMap概述 HashMap基于哈希表的 Map 接口的实现.此实现提供所有可选的映射操作,并允许使用 null 值和 null 键.(除了不同步和允许使用 null 之外,HashMap ...
- 【转】Java集合:HashMap源码剖析
Java集合:HashMap源码剖析 一.HashMap概述二.HashMap的数据结构三.HashMap源码分析 1.关键属性 2.构造方法 3.存储数据 4.调 ...
- Java中的容器(集合)之HashMap源码解析
1.HashMap源码解析(JDK8) 基础原理: 对比上一篇<Java中的容器(集合)之ArrayList源码解析>而言,本篇只解析HashMap常用的核心方法的源码. HashMap是 ...
- 转:【Java集合源码剖析】HashMap源码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/36034955 您好,我正在参加CSDN博文大赛,如果您喜欢我的文章,希望您能帮我投一票 ...
- Java集合系列[3]----HashMap源码分析
前面我们已经分析了ArrayList和LinkedList这两个集合,我们知道ArrayList是基于数组实现的,LinkedList是基于链表实现的.它们各自有自己的优劣势,例如ArrayList在 ...
- 【Java集合源码剖析】HashMap源码剖析
转载出处:http://blog.csdn.net/ns_code/article/details/36034955 HashMap简介 HashMap是基于哈希表实现的,每一个元素是一个key-va ...
- java集合系列之HashMap源码
java集合系列之HashMap源码 HashMap的源码可真不好消化!!! 首先简单介绍一下HashMap集合的特点.HashMap存放键值对,键值对封装在Node(代码如下,比较简单,不再介绍)节 ...
随机推荐
- Java不限制从键盘输入一个数组
Java不限制从键盘输入一个数组 在写算法的时候,需要从键盘输入一个数组,一直不会,最近看了几篇博客学会了,下面用二分查找举例: package com.基础; import java.util.Sc ...
- YC-Framework版本更新:V1.0.5
分布式微服务框架:YC-Framework版本更新V1.0.5!!! 本次版本V1.0.5更新 所有模块依赖调整: 部分问题修复: Nacos模块化: Eureka模块化: 支持SOA(即WebSer ...
- 「Python实用秘技04」为pdf文件批量添加文字水印
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第4期 ...
- Android开发 定时任务清理数据
原文地址:Android开发 定时任务清理数据 | Stars-One的杂货小窝 公司项目,需要整定时任务,对数据进行清理,需要在每天凌晨0:00进行数据的清理,使用了Alarm和广播的方式来实现 P ...
- Linux创建运行C/C++代码
不同于在Windows操作系统下借助IDE运行C++程序,Linux操作系统可以使用g++编译 创建文件及编译文件的流程 1. 先进入某一文件目录下,创建一个文件(也可以用mkdir创建文件) to ...
- Kubernetes的Controller进阶(十二)
一.Controller 既然学习了Pod进阶,对于管理Pod的Controller肯定也要进阶一下,之前我们已经学习过的Controller有RC.RS和Deployment,除此之外还有吗,如果感 ...
- python11day
昨日回顾 函数的参数: 实参角度:位置参数.关键字参数.混合参数 形参角度:位置参数.默认参数.仅限关键字参数.万能参数 形参角度参数顺序:位置参数,*args,默认参数,仅限关键字参数,**kwar ...
- mvvm与mvc的定义与区别
mvvm: 即Model-View-ViewModel(模型-视图-视图模型)的简写. 模型(Model):后端传递的数据 视图(View):即前端渲染的页面 视图模型:是 mvvm 的核心,是连接 ...
- js 用 void 0 替代 undefined
underscore 源码没有出现 undefined,而用 void 0 代替之.为什么要这么做?我们可以从两部分解读,其一是 undefined 哪里不好了,你非得找个替代品?其二就是替代品为毛要 ...
- 如何使PreparedStatement支持命名参数
http://m.blog.csdn.net/wallimn/article/details/3734242