Pandas之groupby( )用法笔记
groupby官方解释
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
Group series using mapper (dict or key function, apply given function to group, return result as series) or by a series of columns.
讲真的,非常不能理解pandas官方文档的这种表达形式,让人真的有点摸不着头脑,example给得又少,参数也不给得很清楚,不过没有办法,还是只能选择原谅他。
groupby我用过的用法
基本用法我这里就不呈现了,我觉得用过一次的人基本不会忘记,这里我主要写一下我用过的关系groupby函数的疑惑:
apply & agg
这个问题着实困扰了我很久,经过研究,找了一些可能帮助理解的东西。先举一个例子:
import pandas as pd
df = pd.DataFrame({'Q':['LI','ZHANG','ZHANG','LI','WANG'], 'A' : [1,1,1,2,2], 'B' : [1,-1,0,1,2], 'C' : [3,4,5,6,7]})
| A | B | C | Q | |
|---|---|---|---|---|
| 0 | 1 | 1 | 3 | LI |
| 1 | 1 | -1 | 4 | ZHANG |
| 2 | 1 | 0 | 5 | ZHANG |
| 3 | 2 | 1 | 6 | LI |
| 4 | 2 | 2 | 7 | WANG |
df.groupby('Q').apply(lambda x:print(x)) A B C Q
0 1 1 3 LI
3 2 1 6 LI
A B C Q
0 1 1 3 LI
3 2 1 6 LI
A B C Q
4 2 2 7 WANG
A B C Q
1 1 -1 4 ZHANG
2 1 0 5 ZHANG
df.groupby('Q').agg(lambda x:print(x)) 0 1
3 2
Name: A, dtype: int64
4 2
Name: A, dtype: int64
1 1
2 1
Name: A, dtype: int64
0 1
3 1
Name: B, dtype: int64
4 2
Name: B, dtype: int64
1 -1
2 0
Name: B, dtype: int64
0 3
3 6
Name: C, dtype: int64
4 7
Name: C, dtype: int64
1 4
2 5
Name: C, dtype: int64| A | B | C | |
|---|---|---|---|
| Q | |||
| LI | None | None | None |
| WANG | None | None | None |
| ZHANG | None | None | None |
从这个例子可以看出,使用apply()处理的对象是一个个的类如DataFrame的数据表,然而agg()则每次只传入一列。
不过我觉得这一点区别在实际应用中分别并不大,因为Ipython的Out输出对于这两个函数几乎没有差别,不管是处理一列还是一表。
我觉得agg()有一点让我很开心就是他可以同时传入多个函数,简直不要太方便哈哈:
df.groupby('Q').agg(['mean','std','count','max'])| A | B | C | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean | std | count | max | mean | std | count | max | mean | std | count | max | |
| Q | ||||||||||||
| LI | 1.5 | 0.707107 | 2 | 2 | 1.0 | 0.000000 | 2 | 1 | 4.5 | 2.121320 | 2 | 6 |
| WANG | 2.0 | NaN | 1 | 2 | 2.0 | NaN | 1 | 2 | 7.0 | NaN | 1 | 7 |
| ZHANG | 1.0 | 0.000000 | 2 | 1 | -0.5 | 0.707107 | 2 | 0 | 4.5 | 0.707107 | 2 | 5 |
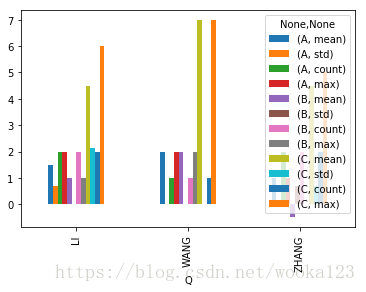
Plotting
这个也是我刚刚学会的,groupby的plot简直不要太方便了:(不过这个例子选的不是很好)
%matplotlib inline
df.groupby('Q').agg(['mean','std','count','max']).plot(kind='bar')<matplotlib.axes._subplots.AxesSubplot at 0x1133bd710>
MultiIndex
这个是困扰我最多的一个问题,因为如果我groupby的时候选择了两个level,之后的data总是呈现透视表的形式,如:
Muldf = df.groupby(['Q','A']).agg('mean')
print(Muldf) B C
Q A
LI 1 1.0 3.0
2 1.0 6.0
WANG 2 2.0 7.0
ZHANG 1 -0.5 4.5
我开始甚至以为这应该不是dataframe,是一个我可能没注意过的一个东西,可是后来我发现,这不过是MultiIndex形式的一种dataframe罢了。
Muldf.B Q A
LI 1 1.0
2 1.0
WANG 2 2.0
ZHANG 1 -0.5
Name: B, dtype: float64如果要选择某一个index,用`xs()`函数:
Muldf.xs('LI')| B | C | |
|---|---|---|
| A | ||
| 1 | 1.0 | 3.0 |
| 2 | 1.0 | 6.0 |
PS:有个问题困扰好久了,怎么把multiindex对象变回原来的形式呢。如:
Q A
LI 1 1.0
LI 2 1.0
WANG 2 2.0
ZHANG 1 -0.5求大佬解答,感激不尽~
Pandas之groupby( )用法笔记的更多相关文章
- Pandas高级教程之:GroupBy用法
Pandas高级教程之:GroupBy用法 目录 简介 分割数据 多index get_group dropna groups属性 index的层级 group的遍历 聚合操作 通用聚合方法 同时使用 ...
- jquery中关于append()的用法笔记---append()节点移动与复制之说
jquery中关于append()的用法笔记---append()节点移动与复制之说 今天看一本关于jquery的基础教程,看到其中一段代码关于append()的一行,总是百思不得其解.于是查了查官方 ...
- pandas获取groupby分组里最大值所在的行,获取第一个等操作
pandas获取groupby分组里最大值所在的行 10/May 2016 python pandas pandas获取groupby分组里最大值所在的行 如下面这个DataFrame,按照Mt分组, ...
- python处理数据的风骚操作[pandas 之 groupby&agg]
https://segmentfault.com/a/1190000012394176 介绍 每隔一段时间我都会去学习.回顾一下python中的新函数.新操作.这对于你后面的工作是有一定好处的.本文重 ...
- Py修行路 Pandas 模块基本用法
pandas 安装方法:pip3 install pandas pandas是一个强大的Python数据分析的工具包,它是基于NumPy构建的模块. pandas的主要功能: 具备对其功能的数据结构D ...
- pandas之groupby分组与pivot_table透视表
zhuanzi: https://blog.csdn.net/qq_33689414/article/details/78973267 pandas之groupby分组与pivot_table透视表 ...
- pandas之groupby分组与pivot_table透视
一.groupby 类似excel的数据透视表,一般是按照行进行分组,使用方法如下. df.groupby(by=None, axis=0, level=None, as_index=True, so ...
- Pandas之groupby分组
释义 groupby用来分组,调用groupby 之后返回pandas.core.groupby.generic.DataFrameGroupBy,其实就是由一个个格式为(key, 分组后的dataf ...
- [Python] Pandas 中 Series 和 DataFrame 的用法笔记
目录 1. Series对象 自定义元素的行标签 使用Series对象定义基于字典创建数据结构 2. DataFrame对象 自定义行标签和列标签 使用DataFrame对象可以基于字典创建数据结构 ...
随机推荐
- 发现DELL笔记本一个很弱智的问题
以前用联想的笔记本,最近联想笔记本坏了,用的是公司的DELL笔记本,发现DELL笔记本一个很弱智的问题. 关于禁用触摸板的问题. 起因: 由于要经常写程序,我配置的有有线鼠标,但是打字时经常碰到触摸板 ...
- Colossus: Successor to the Google File System (GFS)
Colossus is the successor to the Google File System (GFS) as mentioned in the recent paper on Spanne ...
- 中文字体名称对照表(unicode码)及20个web安全字体
在Web编码中,CSS默认应用的Web字体是有限的,虽然在新版本的CSS3,我们可以通过新增的@font-face属性来引入特殊的浏览器加载字体.但多数情况下,考虑各个因素的影响我们还是在尽量充分利用 ...
- php添加日志文件
记录一下. 有时候写测试代码的时候,不习惯直接在屏幕上输出反馈,那么可以配置日志文件,把需要输出的内容追加到日志文件里面,就很方便. Php自带日志系统,可以参考网上的博客配置. 我要说的是,如果你的 ...
- 神奇的ASCⅡ码图
神奇的ASCⅡ码图 可能在网上也常见了asc2码图,但你知道是怎么做出来的吗?(总不可能是人一个一个字码进去的吧,当然,不排除有这种神人的可能
- java数据库(MySQL)之增删改查
1.查询数据 先救从简单的来吧,之前我们实现了将数据库表格信息读取到一个List集合中,数据库的查询,实 际上就是对这个集合的查询: public class Show { public static ...
- phone number
problem description: you should change the given digits string into possible letter string according ...
- 分布式爬虫框架XXL-CRAWLER
<分布式爬虫框架XXL-CRAWLER> 一.简介 1.1 概述 XXL-CRAWLER 是一个分布式爬虫框架.一行代码开发一个分布式爬虫,拥有"多线程.异步.IP动态代理.分布 ...
- Java并发之AQS详解
一.概述 谈到并发,不得不谈ReentrantLock:而谈到ReentrantLock,不得不谈AbstractQueuedSynchronizer(AQS)! 类如其名,抽象的队列式的同步器,AQ ...
- 3d轮播图(另一种方式,可以实现的功能更为强大也更为灵活,简单一句话,比酷狗优酷的炫)
前不久我做了一个3d仿酷狗的轮播图,用的技术原理就是简单的jquery遍历+css样式读写. 这次呢,我们换一种思路(呵呵其实换汤不换药),看到上次那个轮播吗?你有没有发现用jquery的animat ...