MySQL高级学习笔记
1. 变量相关
- 临时变量
-- 定义在函数体或存储过程中的变量
-- 用法在讲函数时会提到
- 用户变量,也称会话变量
-- 用户变量只对当前连接用户有效,其他连接用户无法访问
-- 使用 @ 标识符声明用户变量
SET @age = 20; -- 定义一个值为 20 的 age 变量
-- 使用 SELECT 来查看用户
SELECT @age;
-- 使用 := 来在查询语句中进行赋值
SELECT @maxage := MAX(age) FROM student;
-- 注意事项:
-- 不区分大小写
-- 同一个账户,一旦退出,用户变量也不会再存在
-- 如果用户变量不存在,使用 SELECT 查看会返回 NULL
- 系统变量
-- 任何一个用户都可以访问
-- 使用 @@ 来作为标识符
-- 查看所有的系统变量
SHOW VARIABLES;
SHOW VARIABLES\G; -- 可以使用显示不用过长
-- 同样使用 SELECT 语句来进行查询
SELECT @@age;
-- 修改系统变量
-- 临时修改,只有当前用户使用这个值
SET variable_name = new_value; -- 一需要 @@
SET wait_timeout = 20;
-- 永久修改
SET GLOBAL variable_name = new_value;
SET GLOBAL wait_timeout = 20;
-- 不能自己定义一个新的系统变量
-- 不区分大小写
2. 账户管理
账户管理的应用场景
- 在实际项目开发中,不可能让每个开发人员都使用 root 账户进行登录
- 根据开发人员角色的不同,会分配具有不同权限的账户
MySQL 账户体系
- 服务实例级账户:启动了一个 mysqld,即为启动一个数据库实例。如果某用户拥有服务实例分配的权限,那么该账号就可以删除所有的数据库,连同这些库中的表
- 数据库级别账户:对特定数据库执行增删改查 (CRUD) 的所有操作,最常用的一种级别
- 数据表级别账户:对特定表执行 CRUD 的所有操作
- 字段级别账户:对某些表的特定字段进行操作
- 存储程序级别账户:对存储程序进行 CRUD 的操作
查看账户
-- 需要有 服务实例级 的权限登录后进行操作
-- 账户都存储在 mysql.user 表中
DESC mysql.user; -- 查看 mysql.user 表的结构
-- 关注字段:host, user, authentication_string(即 password)
SELECT host, user, authentication_string FROM mysql.user;
-- 这里看到的密码是加密后的
- 创建账户
-- 需要使用实例级别账户登录后操作 []表示可省略
CREATE USER user_name [IDENTIFIED BY 'password'];
-- 需要注意的是,这里有 user_name 是区分大小写的,并且不能重复创建
-- 示例:
CREATE USER demon; -- 无密码,输入 mysql -u demon 即可登录
CREATE USER demon IDENTIFIED BY 'demon';
- 授权权限
-- 需要使用实例级别账户登录后操作
-- 常用权限主要包括:CREATE、ALTER、INSERT、UPDATE、DELETE、SELECT
-- 如果需要分配所有权限,使用 ALL PRIVILEGES
-- 创建账户并授权
GRANT privilege1,p2.... ON database_name to 'username'@'hostname' [IDENTIFIED 'password'];
-- 对已经存在用户进行授权
GRANT privilege1,p2.... ON database_name to username1, username2,... WITH GRANT OPTION;
-- 注意这个语句只能增加权限,不能修改权限
-- 示例
-- 创建一个新账户 semon 并对 test 数据库授予所有权限
GRANT ALL PRIVILEGES ON test.* TO 'semon'@'%' IDENTIFIED BY 'semon';
-- 注意这里数据库名后需要加 .*,表示对数据库中的所有都授予权限,包括表名,函数等
-- % 表示任意主机,一般不写死
-- 增加 demon 账户的 CREATE 权限
GRANT CREATE ON test.* TO demon WITH GRANT OPTION;
- 查看账户权限
SHOW GRANTS FOR username;
- 刷新权限设置
-- 使用这个命令使权限生效
-- 尤其是你对那些权限表user、db、host等做了update或者delete更新的时候。
-- 如果遇到使用grant后权限没有更新的情况,只要对权限做了更改就使用FLUSH PRIVILEGES命令来刷新权限。
FLUSH PRIVILEGES;
- 回收权限
-- 需要使用实例级别账户登录后操作
-- 使用 revoke 可以将用户的权限进行撤销
REVOKE privilege1, p2 ... ON database_name FROM 'usernmae'@'hostname';
-- 示例
-- 回收 semon 账户的 CREATE 权限
REVOKE CREATE ON test.* FROM 'semon'@'%';
- 删除账户
-- 语法1:使用 root 登录
DROP USER 'username'@'hostname';
-- 语法2:使用 root 登录,操作 mysql.user 表
DELETE FROM mysql.user WHERE user = 'username';
-- 修改后需要刷新
FLUSH PRIVILEGES;
- 修改密码
-- 不需要登录
-- 一般用于自己修改自己账户的密码
mysqladmin -u username -p password 'new-password';
-- 使用实例级别账户登录,如root
-- 一般用于修改自己或别人的密码,一般是级别高的人管理其他人的密码
UPDATE mysql.user SET authentication_string = PASSWORD('new-password') WHERE user = 'username';
-- 修改完后需要刷新权限
FLUSH PRIVILEGES;
3.函数
- 函数的创建
CREATE FUNCTION function_name(paramlist) RETURNS return_type function_body
/*
1. 其中,参数列表的格式:
参数名 参数类型, 参数名 参数类型...
2. function_body
用 begin... end 包裹
3. 临时变量的声明
所谓临时变量,就是 begin..end 间的变量
delare 变量名 变量类型 [default 默认值,可选]
4. 临时变量赋值
set 变量名 = 表达式
5. 函数体中的语句用英文的 ; 隔开
但是由于 MySQL 中标志一个 SQL 语句的结束用的就是 ;
所以,在执行函数时,遇到第一个带 ; 的语句,就结束了
因此,如果想函数正常执行,需要临时修改 SQL 语句的结束标志符
DELIMITER 要修改的新的标志符
*/
-- 一个完整的函数创建的语法
DELIMITER // -- 将 SQL 语句结束符改为 //
CREATE FUNCTION function_name(p1 type1, p2 type2...) RETURNS type
BEGIN
statement1; -- 语句之间用 ; 隔开
...
RETURN result; -- 函数是一定有返回值的
END
// -- 整体函数的结束
DELIMITER ; -- 改回为 ;
- 查看函数是否创建成功
-- 函数创建之后,会存在 mysql.proc 表
-- mysql 是 database
SELECT name, type, db FROM mysql.proc [WHERE name = 'function_name'];
- 调用函数
SELECT 函数名();
- 删除函数
-- 由上面知道,函数是在 mysql.proc 表中
-- 所以如果想删除函数,也只需要在该表中进行操作即可
DELETE FROM mysql.proc WHERE name = 'function_name';
- 简单示例
-- 定义一个实现加法的函数
DELIMITER //;
-- 注意方法名不要与 mysql.proc 中内置的一些方法名重复,会报错
CREATE FUNCTION my_add(a INT, b INT) RETURNS INT
BEGIN
DECLARE res INT;
SET res = a + b;
RETURN res;
END
//
DELIMITER ;
-- 输出 0~100 中的偶数
-- 用这个例子来介绍 while 循环语句与 if 语句
DELIMITER //
CREATE FUNCTION my_printodd() RETURNS VARCHAR(500)
BEGIN
DECLARE i INT DEFAULT 0;
DECLARE res VARCHAR(500) DEFAULT '';
WHILE i < 100 DO
IF i % 2 = 0 THEN -- 注意这里判断相等,只有一个 = 号
SET res = CONCAT(res, ' ', i); -- CONCAT 是内置函数
END IF;
END WHILE;
RETURN res;
END
//
DELIMITER ;
- 使用 SELECT … INTO 定义一个函数
-- 函数中不能调用 SQL 语句,但是 SELECT INTO 除外
-- 示例
DELIMITER //
CREATE FUNCTION my_f() RETURNS INT
BEGIN
DECLARE res INT DEFAULT 0;
SELECT COUNT(*) FROM student INTO res;
RETURN res;
END
//
DELIMITER ;
4. 存储过程
- 什么是存储过程以及为什么需要存储过程
/*
1. 什么是存储过程?
存储过程是存储在数据库服务器中的一组 SQL 语句。
我们可以通过在查询中调用一个特定的名称来执行这些 SQL 语句。
2. 为什么需要存储过程?
存储过程可以简单理解为“数据库中的程序”。
它可以在不借助外部程序的情况下,让数据库自己解决一个复杂的问题,比如批量处理 SQL 语句等。
*/
- 存储过程的创建
/*
存储过程的特点:
1. 存储过程与函数很相似,但比函数更加灵活
2. 它没有返回值,只注重过程
3. 它比函数更加灵活,可以在里面使用 SQL 语句
*/
-- 通用结构:
DELIMITER //
CREATE PROCEDURE procedure_name(params)
BEGIN
BODY
END
//
DELIMITER ;
- 参数定义
/*
存储过程比函数略复杂的地方,体现在存储过程中接受的参数定义类型要比函数多。
函数中,函数的参数定义是(p1, p1_type...)
而存储过程中,参数分为三种类型:
1. IN :表示传入类型的参数,如果不写默认就是 IN
2. OUT :表示传出类型的参数
3. INOUT :既能传入又能传出。一般不用,会造成语义不明确
这里其实也很好理解,因为存储过程没有 RETURN 语句,
OUT 类型的参数其实就相当于 RETURN 的作用
*/
- 临时变量定义 (BEGIN…END之间的变量)
-- 和函数中临时变量的定义相同
- 示例
-- 实现传入一个学生的 id,删除对应 id 的学生,然后返回删除后学生表的学生总人数
/*
实现分析:
1. 首先考虑用函数实现,但是删除学生,需要用到 delete 语句,所以函数不行
2. 考虑用存储过程实现,但是存储过程没有返回值
3. 可以考虑用到 out 类型的参数来实现返回数值的作用
综上,这个需求可以使用存储过程来实现
*/
-- 实现代码
DELIMITER //
CREATE PROCEDURE proc_delStuByIDAndGetCount(sid INT, OUT scount INT)
BEGIN
DELETE FROM student WHERE id = sid;
SELECT COUNT(*) FROM student INTO scount;
END
//
DELIMITER ;
- 存储过程的调用
-- 无参存储过程的调用
CALL procedure_name;
-- 如果有参数,特别是有 out 类型的参数时
-- 使用用户变量进行接受即可
-- 比如调用上述示例中的存储过程:proc_delStuByIDAndGetCount
SET @scount = 0; -- 定义一个用户变量,也可以不用定义直接传参
CALL proc_delStuByIDAndGetCount(9, @scount);
SELECT @scount;
5. 视图
- 什么是视图
/*
简单来说,视图就是对 SELECT 语句的封装。
对于复杂的查询,如果在多处使用,要想更改,就很麻烦。
这时候视图就能解决这一问题。
视图可以视为存储在数据库中一个张虚拟的表。
*/
- 视图的创建
CREATE VIEW view_name AS SELECT...
-- 创建视图,查询学生所在班级信息
CREATE VIEW v_stu_cls AS SELECT s.id AS '学号', s.name AS '姓名', c.name AS '班级名称'
FROM student AS s
JOIN class AS c ON s.class_id = c.id;
- 视图的查看
-- 查看创建的视图
SHOW TABLES; -- 由此也可以看出,视图就是一张表
-- 调用视图
SELECT * FROM v_stu_cls;
SELECT 学号 FROM v_stu_cls;
SELECT 学号 FROM v_stu_cls WHERE 学号 = 10;
- 视图的删除
DROP VIEW view_name;
- 函数、存储过程、视图的比较
- 函数是对一个方法的封装,在 MySQL 中可分为自定义函数与内置函数
- 函数中的参数只是一种类型,就是输入类型,函数必须有返回值
- 存储过程是数据库用于处理复杂 SQL 的一段程序,它可以实现一般 SQL 实现不了的程序
- 存储过程可以简单认为是 SQL 与程序代码的结合体
- 存储过程中的参数类型有三种,OUT 类型可类比于函数中的返回值,我们一般用一个用户变量来接受它
- 视图是对一个复杂 SELECT 语句的封装
- 视图可以简单的认为是一张表,一张由 SELECT 查询结果而组成的一张数据表
6. 事务
为什么要有事务
- 简单的转账示例,转账操作至少涉及两方,A方扣钱,B方得钱。如果扣钱方成功,而得钱方失败。这样会导致重复扣钱的问题
- 事务就是为了解决这一问题而出现的,事务将整个类似 "转账" 的操作看成是一个操作集合,对整体集合进行操作规定
事务的特点 (ACID)
- 原子性 (Atomicity) :事务中的全部操作,要么全部完成 ,要么全部不做
- 一致性 (Consistency) :几个并行执行的事务,其执行结果必须与按某一顺序串行执行结果一致
- **隔离性 (Isolation) **:一个事务不受另一事务的影响,拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是5000,这就是事务的一致性。
- 持久性 (Durability) :对于已提交事务,系统必须保证该事务对数据库的改变不被丢失,即使数据库出现故障
名词解释
- Commit :事务提交,表示整个事务下的操作集全部有效
- Rollback :事务回滚,表示整个事务下的操作集全部作废,数据将还原到操作前的状态
事务不隔离,在并发访问时带来的问题
- 脏读:一个事务读到了另一个事务未提交的数据。比如事务一将 A 账户的钱由100改为 500,而此时一个并发的事务二读取 A 账户的钱,这时事务二读到的数据是 500 。而事务一这时又将事务回滚,导致 A 账户钱变加 100。此时若事务二再次读取,会发现数据是 100。这样,之前读取到的 500 就是脏数据。
- 不可重复读:一个事务读取到另一个事务已经提交的数据,并且这个数据是在 UPDATE 的操作下被修改的。比如上述例子,事务二先读取 A 账户的钱,发现是 100,接着事务一将钱数进行 **UPDATE ** 成 500 并提交整个事务。此时事务二再读取时,会发现得到的结果是 500。这就出现了一个事务多次查询同一个属性却得到了不同的结果值。
- 虚读/幻读:一个事务读取到另一个事务已经提交的数据,并且这个数据是在 INSERT 的操作下被修改的。比如,事务一先读取 A 账户的钱,得到 100 ,同时将 A 账户的名称改为 B。此时事务二新增一个账户 A ,并将 A 账户的钱设置为 100 。这时当事务一再次查询时,会发现 A 账户还没有修改,产生了 '幻觉'。
- 三者的区别:总体来说,可以分为两大类问题:读未提交和读已提交。脏读是读未提交事务数据;后两者则是读已提交数据。而后两者的区别在于已提交数据是如何操作的,不可重复读是执行 UPDATE 操作,而后者是执行 INSERT 操作。
事务的隔离级别
- 读未提交 (read uncommitted) :一个事务读到另一个事务没有提交的数据。上述三个问题都存在
- 读已提交 (read committed) :一个事务在写时禁止其他事务读写,表示必须提交后的数据才能被读取
- 未解决:不可重复读、虚读/幻读
- 解决:脏读
- 可重复读 (repeatable read):一个事务在写时禁止其他事务读写,一个事务在读时,禁止其他事务写
- 未解决:虚读/幻读
- 解决:脏读,不可重复读
- 串行化 (serializable) :每次只能执行一个事务,上述问题全部解决。但是这种级别效率低,一般不用
常见的数据库事务隔离:
| 数据库 | 默认级别 |
|---|---|
| MySQL | 可重复读(Repeatable Read) |
| Oracle | 读提交(Read Committed) |
| SQLServer | 读提交(Read Committed) |
| DB2 | 读提交(Read Committed) |
| PostgreSQL | 读提交(Read Committed) |
- 事务命令
-- 在 MySQL 中,表的引擎类型必须是 innodb 类型才能使用事务, innodb 是 MySQL 默认引擎
-- 修改数据的命令会触发事务,包括 INSERT、UPDATE、DELETE
-- 开启事务:开启事务后,变更会维护到本地缓存中,而不维护到物理表中
BEGIN;
-- 提交事务
COMMIT;
-- 回滚事务
ROLLBACK;
-- 在 MySQL 中我们执行 INSERT、UPDATE、DELETE 语句后,默认是自动提交事务的
-- 这个自动提交的设置是系统变量 AUTOCOMMIT 来控制的,默认值是 1
-- 如果想要关闭可修改它的值
SET [GLOBAL] AUTOCOMMIT = 0;
-- 修改后,如果想要当前窗口(表示当前事务)做出的修改,其他窗口(表示其他事务)能看到,必须手动提交
7. 索引
- 问题引入:
-- 创建一个表 demo
CREATE TABLE demo(
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT NOT NULL,
name VARCHAR(50)
);
-- 使用存储过程来创建大量数据
DELIMITER //
CREATE PROCEDURE proc_create()
BEGIN
DECLARE i INT default 0;
WHILE i <= 100000 DO
INSERT INTO demo(name) VALUES (CONCAT('demo', i));
SET i = i + 1;
END WHILE;
END
//
DELIMITER ;
-- 调用存储过程执行插入操作
CALL proc_create();
-- 开启 SQL 运行时间监测
SET PROFILING = 1;
-- 查询 name 值为 demo10000 的数据
SELECT * FROM demo WHERE name = 'demo10000';
-- 查询执行时间
SHOW PROFILES; -- 0.02965800
-- 查询 id 值 为 10000 的数据
SELECT * FROM demo WHERE id = '10000';
-- 查询执行时间
SHOW PROFILES; -- 0.00109200
-- 执行上面语句,会发现,通过 id 查询比通过 name 查询时间要少很多。
-- 这是因为 id 是主键,有索引关联
-- 因此,如果当某个字段,经常用作查询的字段,而数据量又很大时,通常我们需要使用索引
- 索引的创建
-- 1. 如果指定字段是字符串,需要指定长度,建议长度与定义字段时的长度一致
-- 2. 如果不是字符串,可以不填写长度部分
-- 3. 语法格式如下:
-- create index 索引名称 on 表名(字符名称(长度))
-- 4. 索引的缺点:
-- 4.1 虽然它大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE,因为更新表时,MySQL不仅需要保存数据,还要保存索引文件
-- 4.2 建立索引会占用磁盘空间的索引文件
CREATE INDEX name_index ON demo(name(50));
-- 查询 name 值为 demo10000 的数据
SELECT * FROM demo WHERE name = 'demo10000';
-- 查询执行时间
SHOW PROFILES; -- 0.00082700
- 查看索引
SHOW INDEX FROM table_name;
- 删除索引
DROP INDEX index_name ON table_name;
8. 数据库的备份与恢复
- 备份
mysqldump -uroot -p database_name > url/xxx.sql;
- 恢复
mysql -uroot -p new_database_name < url/xxx.sql;
9. 执行外部的 sql 文件
-- 登录 MySQL 环境
mysql -u root -p
-- source url/xxx.sql
10. Python 与 MySQL 交互
Python 中操作 MySQL 步骤图解
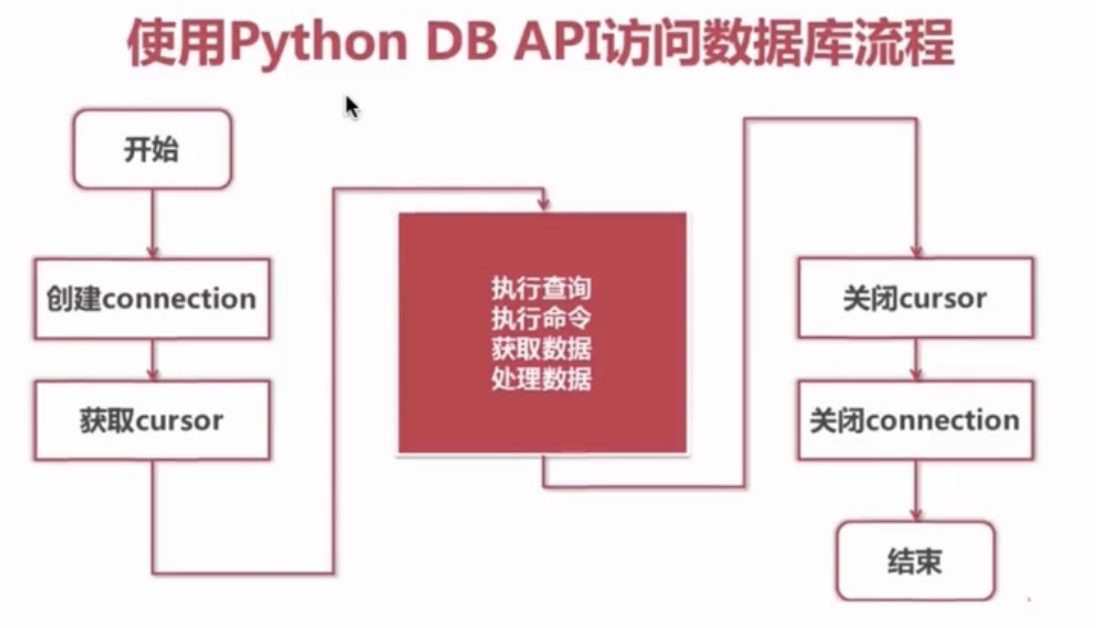
安装 MySQL 模块
# 以 mac + python3 环境为例
pip install pymysql
- 代码示例
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# __author : Demon
# date : 2018-02-27 14:26
from pymysql import *
def insert():
# 1. get the connection object
# host, user, password, database, port, charset
conn = NULL
cur = NULL
try:
conn = connect(host="localhost",
user="root",
# use your own password
password="123456",
# use your own database name
database="test",
port=3306,
# notice that it's 'utf8' not 'utf-8'
# if use 'utf-8' will raise error 'NoneType has no attribute encoding'
charset="utf8"
)
# 2. get the db operation object
cur = conn.cursor()
# 3. write SQL and execute the SQL
# insert_sql = "INSERT INTO demo(name) VALUES ('demo10000000')"
# cur.execute(insert_sql)
# update_sql = "UPDATE demo SET name = 'demo' WHERE id = 1"
# cur.execute(update_sql)
delete_sql = "DELETE FROM demo WHERE id = 1"
cur.execute(delete_sql)
# fetchone
# res = cur.fetchone()
# print(res)
# 4. if data has been changed in Python, we need commit by ourself
conn.commit()
except Exception as e:
print(e)
finally:
if cur:
cur.close()
if conn:
conn.close()
def select():
# 1. get the connection object
# host, user, password, database, port, charset
conn = NULL
cur = NULL
try:
conn = connect(host="localhost",
user="root",
# use your own password
password="123456",
# use your own database name
database="test",
port=3306,
# notice that it's 'utf8' not 'utf-8'
# if use 'utf-8' will raise error 'NoneType has no attribute encoding'
charset="utf8"
)
# 2. get the db operation object
cur = conn.cursor()
# 3. write SQL and execute the SQL
params = [2]
select_sql = "SELECT * FROM demo WHERE id = %s"
cur.execute(select_sql, params)
# 4. get the result by cur.fetchone() and cur.fetchall()
res = cur.fetchone() # the result type is tuple
print(res)
# fetchall() return nested tuple ((), (), ())
# SELECT need not commit
# conn.commit()
except Exception as e:
print(e)
finally:
if cur:
cur.close()
if conn:
conn.close()
if __name__ == "__main__":
# insert()
select()
11. 数据库中常见的安全问题
- SQL 的注入
-- 一个简单的 SQL 插入语句
INSERT INTO student(name) VALUES ('Demon';DROP DATABASE test;');
-- 这里的用户名实际上是 Demon';DROP DATABASE test;
-- 但是我们都知道,SQL 的结束符是 ;
-- 当遇到第一个 ; 号时,第一个语句执行结束
-- 这样就会执行到 DROP 语句,那整个数据库就会被删除掉
-- 实际这里出现问题的是因为在 name 值中,多了一个引号,只要我们加上转义字符,即可达到本身的目的
INSERT INTO student(name) VALUES ('Demon\';DROP DATABASE test;');
- 撞库
- 根据在某个站点获得的用户名和密码,去登录其他站点,从而得到更多信息
- 因为通常我们的习惯是在不同网站注册,大多会使用相同的密码
- 如果某个网站设计得不好,被人窃取密码,再用相同的密码去登录其他网站,就会很危险
- 安全建议
- 对于 SQL 注入而言,容易发生在表单提交中,因此永远不要相信用户的输入,要对用户的输入先进行正则匹配,如果有特殊字符,要进行转义
- 对于撞库,最好不同网站使用不同的密码,特别是对重要的网站。同时要定期更换自己的密码

MySQL高级学习笔记的更多相关文章
- 尚硅谷MySQL高级学习笔记
目录 数据库MySQL学习笔记高级篇 写在前面 1. mysql的架构介绍 mysql简介 mysqlLinux版的安装 mysql配置文件 mysql逻辑架构介绍 mysql存储引擎 2. 索引优化 ...
- MySQL高级学习笔记(四):索引优化分析
文章目录 性能下降 SQL慢 执行时间长 等待时间长 查询语句写的烂 查询数据过多 关联了太多的表,太多join 没有利用到索引 单值 复合 服务器调优及各个参数设置(缓冲.线程数等)(不重要DBA的 ...
- MySQL高级学习笔记(七):MySql主从复制
文章目录 复制的基本原理 slave会从master读取binlog来进行数据同步 三步骤+原理图 复制的基本原则 复制的最大问题 一主一从常见配置 mysql版本一致且后台以服务运行(双方能够pin ...
- MySQL高级学习笔记(六):MySql锁机制
文章目录 概述 定义 生活购物 锁的分类 从对数据操作的类型(读\写)分 从对数据操作的粒度分 三锁 表锁(偏读) 特点 案例分析 建表SQL 加读锁 加写锁 结论 如何分析表锁定 行锁(偏写) 特点 ...
- MySQL高级学习笔记(五):查询截取分析
文章目录 慢查询日志 是什么 怎么玩 说明 查看是否开启及如何开启 默认 开启 那么开启了慢查询日志后,什么样的SQL才会记录到慢查询日志里面呢? Case 配置版 日志分析工具mysqldumpsl ...
- MySQL高级学习笔记(三):Mysql逻辑架构介绍、mysql存储引擎
文章目录 Mysql逻辑架构介绍 总体概览 总体概览 mysql存储引擎 查看命令 看你的 mysql 现在已提供什么存储引擎 : 看你的 mysql 当前默认的存储引擎 : 各个引擎简介 MyISA ...
- MySQL高级学习笔记(二):mysql配置文件、mysql的用户与权限管理、mysql的一些杂项配置
文章目录 mysql配置文件 二进制日志log-bin 错误日志log-error 数据文件 两系统 Myisam存放方式 innodb存放方式 如何配置 mysql的用户与权限管理 MySQL的用户 ...
- MySQL高级学习笔记(一):mysql简介、mysq linux版的安装(mysql 5.5)
文章目录 MySQL简介 概述 mysql高手是怎样炼成的 mysq linux版的安装(mysql 5.5) 下载地址 拷贝&解压缩 检查工作 检查当前系统是否安装过mysql 检查/tmp ...
- MySQL数据库学习笔记(十二)----开源工具DbUtils的使用(数据库的增删改查)
[声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/4 ...
随机推荐
- 单元测试系列:如何使用JUnit+JaCoCo+EclEmma完成单元测试
更多原创测试技术文章同步更新到微信公众号 :三国测,敬请扫码关注个人的微信号,感谢! 原文链接:http://www.cnblogs.com/zishi/p/6726664.html -----如 ...
- 使用exe4j工具制作简单的java应用程序
首先需要下载exe4j工具并进行安装,下面是利用exe4j工具制作应用程序的步骤. 1.首先将工程导出为可运行的jar包,选择extract required libralies into gener ...
- hdu 4609 3-idiots [fft 生成函数 计数]
hdu 4609 3-idiots 题意: 给出\(A_i\),问随机选择一个三元子集,选择的数字构成三角形的三边长的概率. 一开始一直想直接做.... 先生成函数求选两个的方案(注意要减去两次选择同 ...
- BZOJ 4408: [Fjoi 2016]神秘数 [主席树]
传送门 题意: 一个可重复数字集合S的神秘数定义为最小的不能被S的子集的和表示的正整数.例如S={1,1,1,4,13},8无法表示为集合S的子集的和,故集合S的神秘数为8.现给定n个正整数a[1]. ...
- BZOJ 1355: [Baltic2009]Radio Transmission [KMP 循环节]
1355: [Baltic2009]Radio Transmission Time Limit: 10 Sec Memory Limit: 64 MBSubmit: 792 Solved: 535 ...
- vue环境搭建与创建第一个vuejs文件
我们在前端学习中,学会了HTML.CSS.JS之后一般会选择学习一些框架,比如Jquery.AngularJs等.这个系列的博文是针对于学习Vue.js的同学展开的. 1.如何简单地使用Vue.js ...
- c++项目范例
#include<iostream> #include<string.h> #include<stdlib.h> using namespace std; clas ...
- 获取网站证书的两种方法(wireshark or firefox nightly)
一.使用Wireshark 截取数据包的方式 1. wireshark软件需要使用管理员权限运行,开始捕获后,按下ctrl + f,查找证书所在分组,从source 和destination 栏可以看 ...
- window 下生成NodeJs(v8.9.3) 的 VS2015 解决方案node.sln
window 下生成NodeJs(v8.9.3) 的 VS2015 解决方案node.sln 使用步骤 也可以参照 github: https://github.com/nodejs/node/blo ...
- 一步一步从原理跟我学邮件收取及发送 13.mime格式与常见字符编码
在前面的本系列文章中我们已经学会了邮件的发送和收取.但在收取中我们看到的是一串串的乱码,回忆前面的发送过程,我们会奇怪:我们前面的邮件是明文啊.为什么明文的邮件明明也可以正常工作,还要弄乱码似的字符串 ...