Java集合 - List介绍及源码解析
(源码版本为 JDK 8)
集合类在java.util包中,类型大体可以分为3种:Set、List、Map。
JAVA 集合关系(简图)
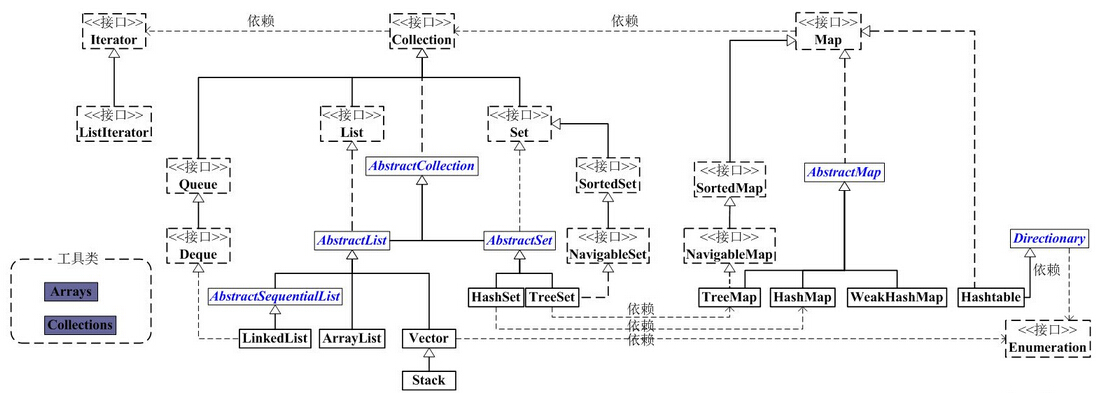
(图片来源网络)
List集合和Set集合都是继承Collection接口,是List和Set的最上级接口,包含如下方法:
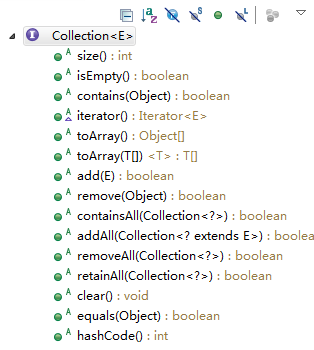
List 集合
List是一个有序集合(也称为序列),你可以控制每个元素被插入的位置,和根据索引访问列表中元素。List集合元素可以重复,也可以存入 null 元素。
List集合是可以根据索引来操纵集合,所以List接口在Collection接口基础增加了一些根据索引操纵集合的接口方法。
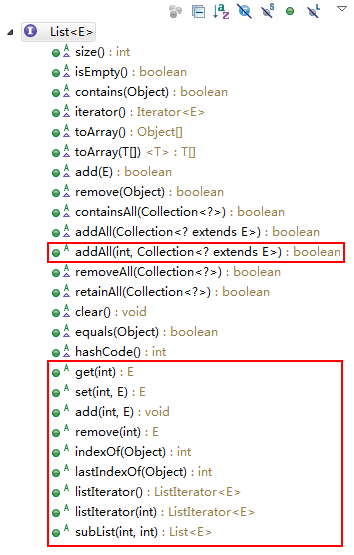
集合接口的实现类
List 集合有两个常用实现,ArrayList和LinkedList,内部采用不同数据结构来实现,不同场景下有不同的使用选择。
ArrayList
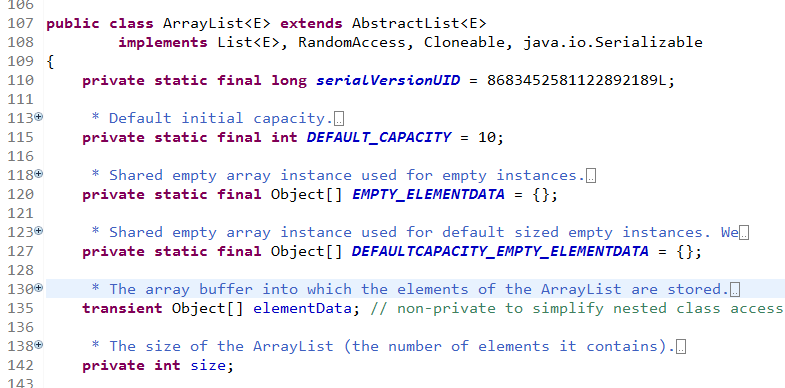
ArrayList类除了继承和实现集合接口外,还实现了RandomAccess, Cloneable接口。说明ArrayList支持克隆和快速随机访问。
ArrayList 的内部数据结构是数组。

默认初始化容量为10

从查找,增加,删除,修改元素方法看ArrayList集合
查找元素方法:get,indexOf
// 直接根据索引查找元素,效率较高
public E get(int index) {
rangeCheck(index);
return elementData(index); // 根据索引直接返回数组中元素
}
// 根据元素查索引位置,元素不存在返回 -1 ,使用了循环遍历查找元素,查找效率取决于集合大小,元素所处的位置。
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
增加元素方法:add
// 增加元素,存在扩容,数据拷贝等问题,效率会变低,如果要向集合中大量的添加元素可以通过构造方法指定较大的初始容量。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 增加 modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
// 计算容量
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
// 确保容量安全
private void ensureExplicitCapacity(int minCapacity) {
modCount++; // 集合结构修改计数器(结构修改是指那些改变列表的大小或位置等)
// 当所需最小容量比数组容量大需要扩容
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
// 扩容
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); // 容量变为原来的1.5倍
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
删除元素方法:remove
// 根据索引删除元素,如果从开头和中间位置删除元素,删除位置后面的元素会向前移动,效率会比删除末尾元素低。
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
// 元素的移动拷贝
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // 赋值为null 明确的让垃圾回收,--size 删除元素后修改集合长度
return oldValue;
}
// 根据集合元素删除,先循环找出要删除的元素位置索引,然后再根据索引删除。和根据索引删除方法比较,多了一步通过循环查找元素索引位置的过程。
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
// 删除集合元素
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
修改元素方法:set
// 根据索引修改元素,直接索引指向新的元素值。
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
通过上面代码可以发现,ArrayList 集合检索元素效率较高,比较适合,而对于增删效率较低。
LinkedList

LinkedList 类还实现了Deque 接口(Deque 代表算端队列,与 List 接口不同,此接口不支持通过索引访问元素),所以LinkedList 是一个List集合也是一个双端队列。
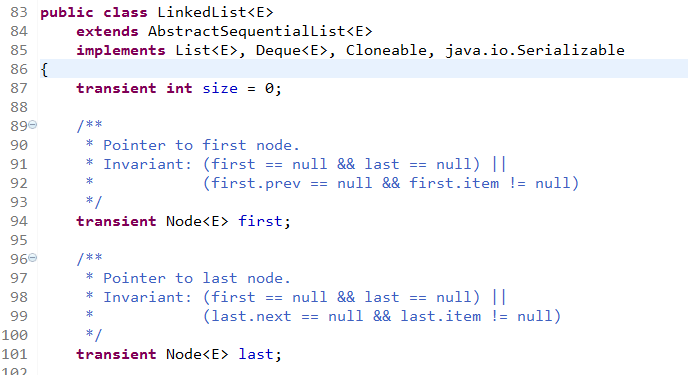
private static class Node<E> {
E item; // 当前元素
Node<E> next; // 下一个节点
Node<E> prev; // 上一个节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
LinkedList 是一个链表数据结构,其中维护了一个内部类Node做为链表中的节点,first 是指向首节点,last 是指向尾节点。每个Node节点都记录上一个节点、下一个节点的引用,和当前节点所存储的元素。
链表结构如图:
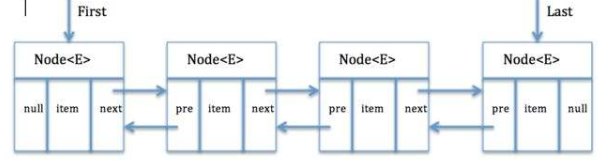
(图片来源网络)
从查找,增加,删除,修改元素部分方法看LinkedList集合适合哪些操作(从底层数据结构就能够发现)
查找元素方法:get
// 根据索引查找元素,由于链表没有索引,所以需要从头部或尾部遍历查找。ArrayList 和 LinkedList底层数据结构不同导致的 ArrayList集合中查找元素效率更高,因为ArrayList底层是数组,可以直接根据index索引获取元素。
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
// 如果要找的元素位置小于集合长度的1/2,就从前向后遍历,否则从后向前遍历,由此可知越向中间效率越低
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
增加元素方法:add
由于底层数据结构不同,LinkedList增加元素效率要比ArrayList效率高,ArrayList存在扩容和拷贝等操作。
// 向尾部添加元素
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null); // 创建一个新节点
last = newNode; // 将新节点指向尾节点(last)
if (l == null)
first = newNode;// 如果newNode是集合中唯一元素(初始是空集合),那么也将newNode指向首节点(first)
else
l.next = newNode; // 原last节点下一个元素的引用指向新的节点(newNode)
size++;
modCount++;
}
// 在指定位置添加元素,index 位置越靠近中间插入效率越低,随着集合长度增大而增大
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size) // index==size 说明集合为空或者在集合末尾添加元素
linkLast(element);
else
linkBefore(element, node(index));
}
// 链表和数组不同,不能直接根据索引获得元素,链表需要从头或尾部循环遍历到指定位置获得元素
Node<E> node(int index) {
// 如果要找的元素位置小于集合长度的1/2,就从前向后遍历,否则从后向前遍历,所以向中间效率越低
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
// 在 succ节点之前插入元素
void linkBefore(E e, Node<E> succ) {
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);// 创建一个新节点
succ.prev = newNode; //
if (pred == null)
// 说明 succ 是首节点
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
修改元素方法:set
LinkedList修改元素时需要先遍历找到元素,ArrayList可以直接根据索引获得元素,所以LinkedList效率较低,当元素越靠近中间位置越明显。
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
// 根据索引遍历出元素节点
Node<E> node(int index) {
// 如果要找的元素位置小于集合长度的1/2,就从前向后遍历,否则从后向前遍历,所以向中间效率越低
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}删除元素方法:remove
和ArrayList相比不存在移动拷贝情况,所以LinkedList删除元素效率比ArrayList高
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
// 根据索引遍历查找出目标节点
Node<E> node(int index) {
// 如果索引小于集合长度的一半
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
LinkedList 实现了Deque接口,是一个双端队列,所以LinkedList又包含如下常用方法:
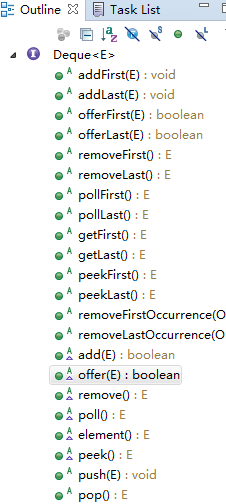
源码中“有趣”的设计
方法重复定义
源码中Collection接口中的多个方法在List接口中又重复定义了一次,既然List 已经继承了Collection接口,为什么重复定义,历史原因?先有List后有Collection?

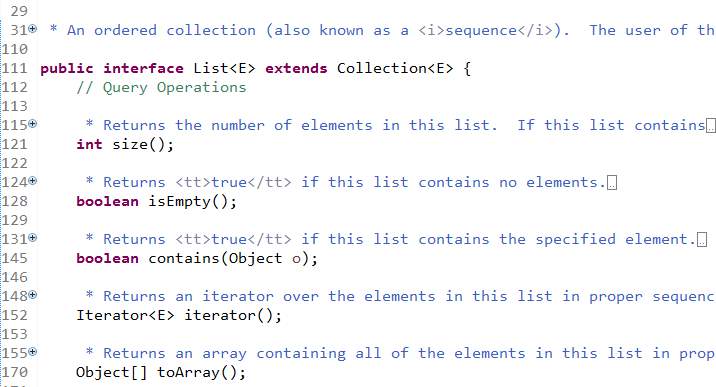
重复实现接口
AbstractList 已经实现List接口,ArrayList继承 AbstractList,然而ArrayList源码又实现了 List接口。
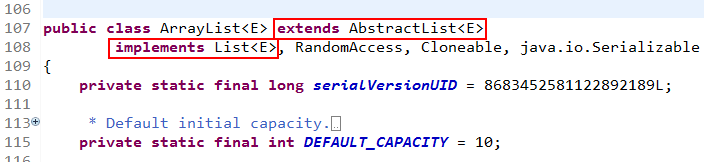

网上搜了下答案:
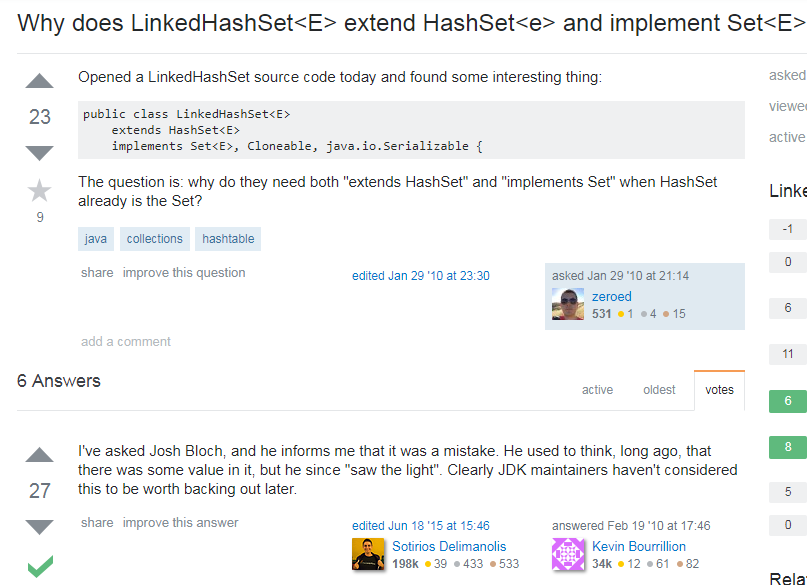
意思是他问过这块的开发者,这是一个错误。很久以前认为有价值的。
不知道这个答案是否正确?
小结
List集合和Set集合都是继承Collection接口,Collection是List和Set的最上级接口,List接口下有两个常用的实现类,分别为ArrayList和LinkedList,而LinkedList又实现Deque接口,所以LinkedList即是List集合也是一个双端队列。
ArrayList是基于数组数据结构而实现的,而LinkedList是基于链表数据结构实现的,从数据结构特点和源码实现上来看,ArrayList可以根据索引快速获取到元素,而增加元素时需要数组的扩容和拷贝,删除元素时需要数组的移动拷贝,因此ArrayList集合对查找和修改元素效率较好,对增删效率略低。
LinkedList的链表数据结构不能根据索引直接快速获取元素节点,必须从头部,或者尾部遍历到索引位置(如果索引值小于集合长度的1/2时就从头部开始遍历,否则从尾部开始遍历,因此索引值处于中间时遍历效率会比位于两端要差。)而增加或删除元素时只需要将上下节点重新指向新的节点对象引用即可,不存在扩容,移动等情况,因此LinkedList和ArrayList相比更适合增加和删除元素操作,对查找操作效率较低。
转载请注明出处: https://www.cnblogs.com/newobjectcc/p/10789188.html
欢迎关注公众号[NO编程]

Java集合 - List介绍及源码解析的更多相关文章
- 【java集合总结】-- ArrayList源码解析
一.前言 要想深入的了解集合就必须要通过分析源码来了解它,那如何来看源码,要看什么东西呢?主要从三个方面: 1.看继承结构 看这个类的继承结构,处于一个什么位置,不需要背记,有个大概的感觉就可以,我自 ...
- Java中的容器(集合)之HashMap源码解析
1.HashMap源码解析(JDK8) 基础原理: 对比上一篇<Java中的容器(集合)之ArrayList源码解析>而言,本篇只解析HashMap常用的核心方法的源码. HashMap是 ...
- Java集合系列[4]----LinkedHashMap源码分析
这篇文章我们开始分析LinkedHashMap的源码,LinkedHashMap继承了HashMap,也就是说LinkedHashMap是在HashMap的基础上扩展而来的,因此在看LinkedHas ...
- java集合系列之HashMap源码
java集合系列之HashMap源码 HashMap的源码可真不好消化!!! 首先简单介绍一下HashMap集合的特点.HashMap存放键值对,键值对封装在Node(代码如下,比较简单,不再介绍)节 ...
- java集合系列之LinkedList源码分析
java集合系列之LinkedList源码分析 LinkedList数据结构简介 LinkedList底层是通过双端双向链表实现的,其基本数据结构如下,每一个节点类为Node对象,每个Node节点包含 ...
- java集合系列之ArrayList源码分析
java集合系列之ArrayList源码分析(基于jdk1.8) ArrayList简介 ArrayList时List接口的一个非常重要的实现子类,它的底层是通过动态数组实现的,因此它具备查询速度快, ...
- Android IntentService使用介绍以及源码解析
版权声明:本文出自汪磊的博客,转载请务必注明出处. 一.IntentService概述及使用举例 IntentService内部实现机制用到了HandlerThread,如果对HandlerThrea ...
- IPerf——网络测试工具介绍与源码解析(4)
上篇随笔讲到了TCP模式下的客户端,接下来会讲一下TCP模式普通场景下的服务端,说普通场景则是暂时不考虑双向测试的可能,毕竟了解一项东西还是先从简单的情况下入手会快些. 对于服务端,并不是我们认为的直 ...
- 死磕 java同步系列之CyclicBarrier源码解析——有图有真相
问题 (1)CyclicBarrier是什么? (2)CyclicBarrier具有什么特性? (3)CyclicBarrier与CountDownLatch的对比? 简介 CyclicBarrier ...
随机推荐
- Scrapy爬虫框架第四讲(Linux环境)
下面我们来学习Selector的具体使用:(参考文档:http://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/selectors.html) Selecto ...
- 40多行python代码开发一个区块链。
40多行python代码开发一个区块链?可信吗?我们将通过Python 2动手开发实现一个迷你区块链来帮你真正理解区块链技术的核心原理.python开发区块链的源代码保存在Github. 尽管有人认为 ...
- C Primer Plus 第6章 C控制语句:循环 编程练习
记录下写的最后几题. 14. #include <stdio.h> int main() { double value[8]; double value2[8]; int index; f ...
- java 字符常量池
一.题目: 问题:String str = new String(“hello”),“hello”在内存中是怎么分配的? 答案是:堆,字符串常量区. Java中的字符串常量池和JVM运行时数据区 ...
- aliyun TableStore相关操作汇总
总结:这个东西本身可能技术还不成熟,使用的人少,有问题很验证解决 遇到的问题:(1)没有一个GUI工具,使用门槛高(2)查询的GetRange不方便,把查询出来的数据使用System.out.prin ...
- mac里用PyCharm中引用MySqlDB始末
本来想用java来连数据库,然后调用python的,后来想了想,反正是个实验性质的小工程何必搞的这么复杂.直接全部python就好了,于是就为这个想法填了一晚上的坑. 装好了PyCharm的CE版,然 ...
- 通过配置tomcat实现项目免部署
对于一些比较大的项目,比如说使用了EXTJS这种重量级UI框架的项目,在部署的时候,eclipse会卡崩的,所以可以通过配置tomcat来实现免部署,直接运行即可: 首先找到tomcat的localh ...
- CentOS 6.2+Nginx+Nagios,手机短信和qq邮箱提醒
http://chenhao6.blog.51cto.com/6228054/1323192 标签:软件包 配置文件 nagios 服务端 监控 原创作品,允许转载,转载时请务必以超链接形式标明文章 ...
- python的加、减、乘、除、取整、取余计算
加法: 输入以下代码: >>>1+1 >>>1.0+1 减法: 输入以下代码: >>>1-2 >>>1.0-2 乘法: 输入以下 ...
- BZOJ_3252_攻略_线段树+dfs序
BZOJ_3252_攻略_线段树+dfs序 Description 题目简述:树版[k取方格数] 众所周知,桂木桂马是攻略之神,开启攻略之神模式后,他可以同时攻略k部游戏.今天他得到了一款新游戏< ...