第八篇:支持向量机 (Support Vector Machine)
前言
本文讲解如何使用R语言中e1071包中的SVM函数进行分类操作,并以一个关于鸢尾花分类的实例演示具体分类步骤。
分析总体流程
1. 载入并了解数据集;
2. 对数据集进行训练并生成模型;
3. 在此模型之上调用测试数据集进行分类测试;
4. 查看分类结果;
5. 进行各种参数的调试并重复2-4直至分类的结果让人满意为止。
参数调整策略
综合来说,主要有以下四个方面需要调整:
1. 选择合适的核函数;
2. 调整误分点容忍度参数cost;
3. 调整各核函数的参数;
4. 调整各样本的权重。
其中,对于特征比较多的情况一般用非线性核,比如高斯核。高斯核的特点是参数多,需要不断调试参数才能理想的效果。而线性核没什么参数可设置,一般适用于特征比较少的情况。
关于各核函数的参数,则一般是通过试探法来确定。最好可以将不同样本权重模型,不同核函数参数下的分类准确率做成一张可视化报表,以便于方案确定。
关于3的选择,一般可以通过MDS的可视化图,看有哪几个分类是纠缠不清的,然后就加大这两个分类的样本权重。
鸢尾花分类分析 - 使用支持向量机(SVM)
1. 安装SVM分析所需包:e1071
2. 载入并了解数据集:

可以看出,这个数据集比较理想化,避免了繁琐的数据预处理过程,非常适合作为案例讲解。
3. 建立SVM模型:

这个模型变量相当于是训练库,下面查看该模型的信息:
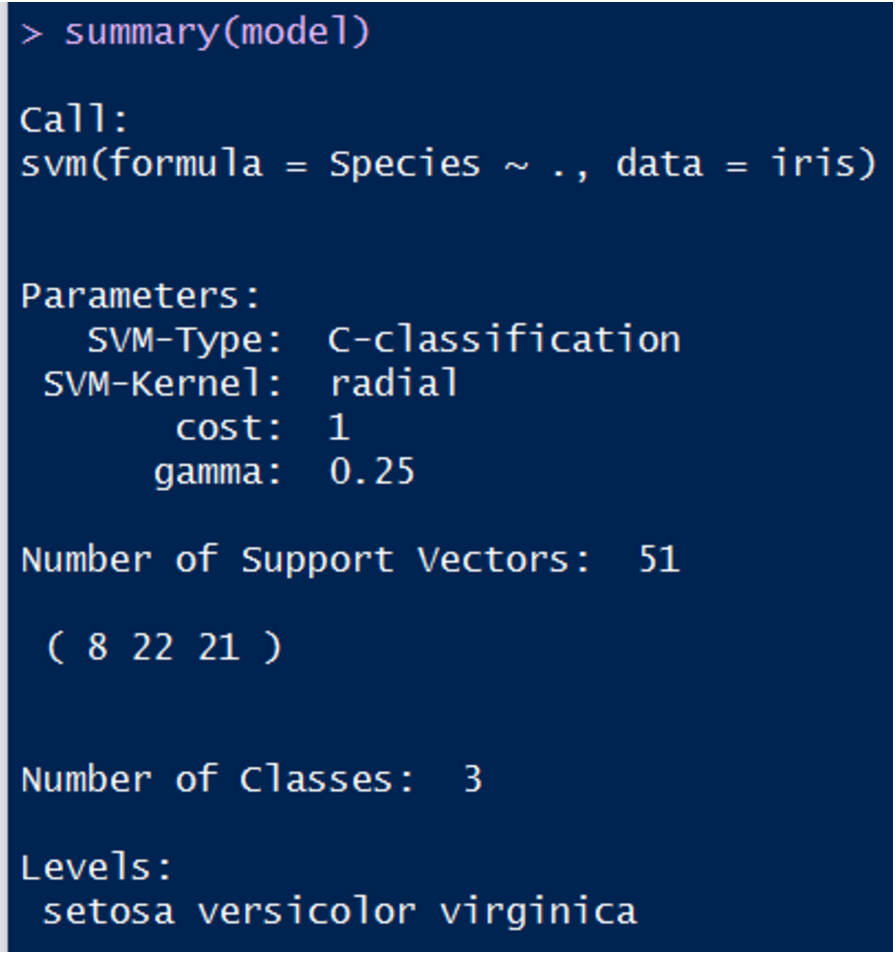
其中,SVM类型是C-classification,核函数是高斯核,cost是误分点容忍度参数,gamma是核函数参数。他们的具体含义请参考函数手册。
4. 利用该模型进行预测

5. 查看预测效果:
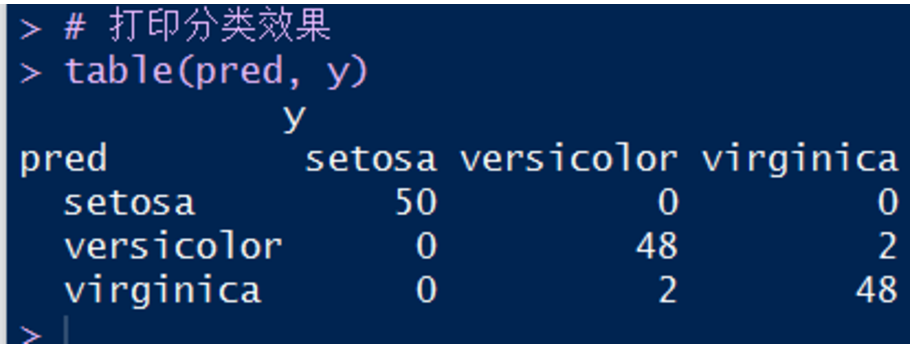
可见,有两个类型似乎混淆了。那怎么办?还有,如果变量多,我如何观察出哪几个变量纠缠不清呢?下面先来解决这个问题。
6. 使用MDS技术查看各变量分类情况
MDS技术可以根据所有样本之间的距离,根据各个变量之间距离不变的设定,将维度降低到两维。一般来说,它是用来分析整体分类的一个态势的:
plot(cmdscale(dist(iris[,-5])), col = c("blue", "green", "orange")[as.integer(iris[,5])], pch = c("o", "+")[1:150 %in% model$index+1])
legend(2, -0.7, c("setosa", "versicolor", "virginica"), col = c("blue", "green", "orange"), lty = 1)
显示效果如下:
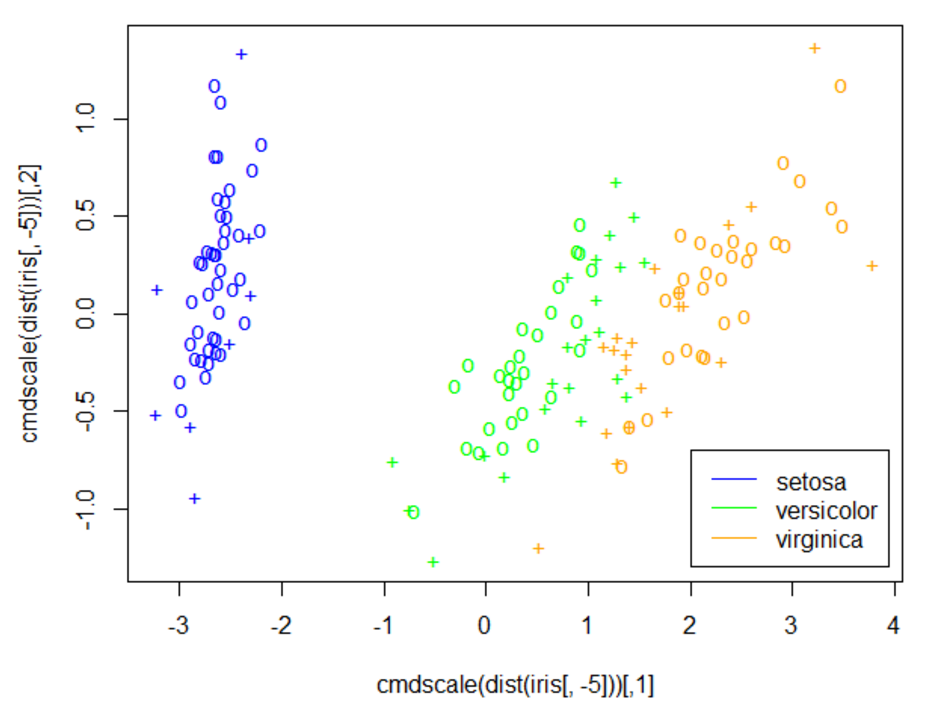
显然,后两个分类有点混淆。
7. 调整各样本权重系数:
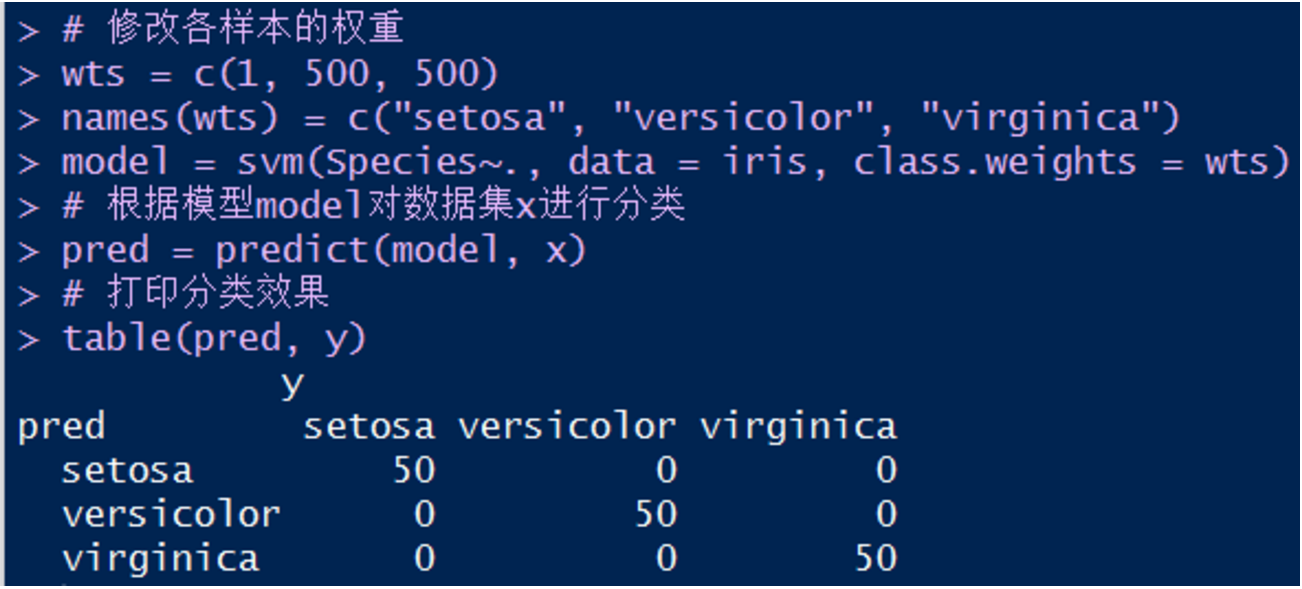
由上图可知,这样的模型产生了更好的分类效果。
小结
1. 本例中的场景比较简单,故未做复杂的参数调整。在实际项目中往往需要对方方面面都进行调整。
2. 虽然SVM在做了标准化后效果更好,但是不用手动标准化。因为SVM函数会自动进行标准化。
3. 对于维度比较少的情况,直接用线性核就好了。
4. SVM是综合指标最好的分类器,但是有它的局限之处,那就是容易过拟合。因此降维工作一定要做好。
第八篇:支持向量机 (Support Vector Machine)的更多相关文章
- 支持向量机 support vector machine
SVM(support Vector machine) (1) SVM(Support Vector Machine)是从瓦普尼克(Vapnik)的统计学习理论发展而来的,主要针对小样本数据进行学习. ...
- 支持向量机(Support Vector Machine)-----SVM之SMO算法(转)
此文转自两篇博文 有修改 序列最小优化算法(英语:Sequential minimal optimization, SMO)是一种用于解决支持向量机训练过程中所产生优化问题的算法.SMO由微软研究院的 ...
- 机器学习(八)--------支持向量机 (Support Vector Machines)
与逻辑回归和神经网络相比,支持向量机或者简称 SVM,更为强大. 人们有时将支持向量机看作是大间距分类器. 这是我的支持向量机模型代价函数 这样将得到一个更好的决策边界 理解支持向量机模型的做法,即努 ...
- 支持向量机(Support Vector Machine,SVM)
SVM: 1. 线性与非线性 核函数: 2. 与神经网络关系 置信区间结构: 3. 训练方法: 4.SVM light,LS-SVM: 5. VC维 u-SVC 与 c-SVC 区别? 除参数不同外, ...
- 支持向量机SVM(Support Vector Machine)
支持向量机(Support Vector Machine)是一种监督式的机器学习方法(supervised machine learning),一般用于二类问题(binary classificati ...
- 6. support vector machine
1. 了解SVM 1. Logistic regression 与SVM超平面 给定一些数据点,它们分别属于两个不同的类,现在要找到一个线性分类器把这些数据分成两类.如果用x表示数据点,用y表示类别( ...
- 斯坦福第十二课:支持向量机(Support Vector Machines)
12.1 优化目标 12.2 大边界的直观理解 12.3 数学背后的大边界分类(可选) 12.4 核函数 1 12.5 核函数 2 12.6 使用支持向量机 12.1 优化目标 到目前为 ...
- 机器学习课程-第7周-支持向量机(Support Vector Machines)
1. 优化目标 在监督学习中,许多学习算法的性能都非常类似,因此,重要的不是你该选择使用学习算法A还是学习算法B,而更重要的是,应用这些算法时,所创建的大量数据在应用这些算法时,表现情况通常依赖于你的 ...
- 5. support vector machine
1. 了解SVM 1. Logistic regression回顾 Logistic regression目的是从特征中学习出一个0/1二分类模型,而这个模型是将特性的线性组合作为自变量,由于自变量的 ...
随机推荐
- Maven中避开测试环节
两种方法 修改pom文件 添加<skipTests>true</skipTests>标签 <plugin> <groupId>org.apache.ma ...
- python并发编程之多进程(三):共享数据&进程池
一,共享数据 展望未来,基于消息传递的并发编程是大势所趋 即便是使用线程,推荐做法也是将程序设计为大量独立的线程集合 通过消息队列交换数据.这样极大地减少了对使用锁定和其他同步手段的需求, 还可以扩展 ...
- [工具]Microsoft To-Do,简约还是简陋?
1. 简介 微软收购奇妙清单后,由奇妙清单的原班人马打造了一个全新的待办事项应用,就叫"To-Do"(简单粗暴,好像新浪微博直接就叫"微博"的感觉).这个应该刚 ...
- CSS布局(六) 对齐方式
一.水平居中: (1). 行内元素的水平居中? 如果被设置元素为文本.图片等行内元素时,在父元素中设置text-align:center实现行内元素水平居中,将子元素的display设置为inline ...
- Yii2中后台用前台的代码设置验证码显示不出来?
我说的是直接修改advanced模板.细心人会发现模板里在contact里有,登录也想要就仿照contact中的做法.前台好了,后台登录也要验证码,就把前台代码拿过来,可惜前后台的SiteContro ...
- spring-boo hello world程序
作为一个程序猿,使用了spring好多年,现在有了spring-boot,也想尝尝鲜. 初听spring-boot,觉得很神秘,实际上就是集合了很多组件,再加上一些boot开发的启动和粘合程序. 个人 ...
- Selenium里可以自行封装与get_attribute对应的set_attribute方法
我们在做UI自动化测试的过程中,某些情况会遇到,需要操作WebElement属性的情况. 假设现在我们需要获取一个元素的title属性,我们可以先找到这个元素,然后利用get_attribute方法获 ...
- Java--JDBC连接数据库(二)
本篇文章接着上篇文章,还剩下一个知识点是,可滚动的结果接集和可更新的结果集.一般默认情况之下,多结果集是不可以显式滚动,移动选择的.如果想要做到,需要指定一些参数,那么本篇就接着介绍如何操作可滚动的结 ...
- linux 版本控制及rpm打包
版本控制 subversion:是一个自由/开源的版本控制系统,在subversion管理下,文件和目录可以超越时空subversion允许你数据恢复到早期版本,或者是检查数据修改历史许多人将版本控制 ...
- javascript form表单常用的正则表达式
form验证时常用的几个正则表达式 座机: \d{3,4}-\d{7,8} 手机号: /^1[34578][0-9]{9}$/ (\86)?\s+1[34578]\d{0-9} (\+86)?\s*1 ...