记录python接口自动化测试--利用unittest生成测试报告(第四目)
前面介绍了是用unittest管理测试用例,这次看看如何生成html格式的测试报告
生成html格式的测试报告需要用到 HTMLTestRunner,在网上下载了一个HTMLTestRunner.py,然后放到python安装路径下的lib目录中。
(我用的python3,是下载的虫师写的那个,下载地址-->链接:https://pan.baidu.com/s/101y-X--o6iSd9WTDv5K4XQ 密码:24xh)
1.执行单个.py文件中的测试用例
# -*-coding:UTF:8-*- import unittest
from interface.demo import RunMain # 从之前封装的文件中,引入RunMain类
import HTMLTestRunner # 导入HTMLTestRunner模块
import json class TestMethod(unittest.TestCase): # 定义一个类,继承自unittest.TestCase def setUp(self):
self.run = RunMain() # 在初始化方法中实例化一个对象,这样就不需要在每个用例中再进行实例化了 def test01(self):
"""获取办件申请人信息""" #在用例名下添加接口描述,可以增加测试报告可读性
url = 'http://localhost:7001/XXX'
data = {
'controlSeq': ''
}
r = self.run.run_main(url, 'POST', data) # 调用RunMain类中run_main方法
print(r)
re = json.loads(r)
self.assertEqual(re['status'], '', '测试失败')
# globals()['userid'] = 22 #定义全局变量 def test02(self):
"""查询办件进度结果信息接口"""
# print(userid) #使用case1中的全局变量,执行时需要全部执行,不能只执行后面的,不然会报错
url = 'http://localhost:7001/XXX'
data = {
"controlSeq": ""
}
r = self.run.run_main(url, 'GET', data)
print(r)
re = json.loads(r)
self.assertEqual(re["status"], '', '测试失败') # @unittest.skip('test03') # 跳过用例test03
def test03(self):
"""保存办件快递信息接口(审批3.0)"""
url = 'http://localhost:7001/XXX'
data = {
'controlSeq': '',
'seq': '',
'type': ''
}
r = self.run.run_main(url, 'POST', data)
print(r)
# print(type(r)) # 查看返回对象r的类型
re = json.loads(r)
# print(type(re))
self.assertEqual(re['status'], '', '测试失败') if __name__ == "__main__":
# unittest.main()
# print('__name__==__main__')
filename = 'E:/CommonService/interface/report/testresult.html' #测试报告的存放路径及文件名
fp = open(filename, 'wb') # 创测试报告html文件,此时还是个空文件 suite = unittest.TestSuite() # 调用unittest的TestSuite(),理解为管理case的一个容器(测试套件)
suite.addTest(TestMethod('test01')) # 向测试套件中添加用例,"TestMethod"是上面定义的类名,"test01"是用例名
suite.addTest(TestMethod('test02'))
suite.addTest(TestMethod('test03'))
# runner = unittest.TextTestRunner() # 执行套件中的用例
runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title='接口测试报告', description='测试结果如下: ')
# stream = fp 引用文件流
# title 测试报告标题
# description 报告说明与描述
runner.run(suite) # 执行测试
fp.close() # 关闭文件流,将HTML内容写进测试报告文件

2.使用discover()方法批量加载多个.py文件中的测试用例
工程目录如下:
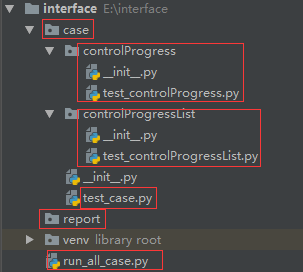
case是测试用例所在目录,里面包括2个二级目录,存放的都是测试用例;
report存放测试报告的目录;
最外层的run_all_case.py,用它来执行所有用例
(1)直接加载discover中的用例
run_all_case.py import time
from HTMLTestRunner import HTMLTestRunner
import unittest case_dir = 'E:/CommonService/interface/case' # 定义用例所在路径
"""定义discover方法"""
discover = unittest.defaultTestLoader.discover(case_dir,
pattern='test_*.py',
top_level_dir=None)
"""
1.case_dir即测试用例所在目录
2.pattern='test_*.py' :表示用例文件名的匹配原则,“*”表示任意多个字符,这里表示匹配所有以test_开头的文件
3.top_level_dir=None:测试模块的顶层目录。如果没顶层目录(也就是说测试用例不是放在多级目录
中),默认为 None
""" if __name__ == "__main__":
"""直接加载discover"""
now = time.strftime("%Y-%m-%d %H_%M_%S")
filename = 'E:/CommonService/interface/report/' + now + '_result.html'
fp = open(filename, 'wb')
runner = HTMLTestRunner(stream=fp,
title='UnifiedReporting Test Report',
description='Implementation Example with: ')
runner.run(discover)
fp.close()
(2)通过把discover中的用例加载到测试套件中执行
run_all_case.py import time
from HTMLTestRunner import HTMLTestRunner
import unittest case_dir = 'E:/CommonService/interface/case' # 定义用例所在路径 """定义discover方法"""
discover = unittest.defaultTestLoader.discover(case_dir,
pattern='test_*.py',
top_level_dir=None)
"""
1.case_dir即测试用例所在目录
2.pattern='test_*.py' :表示用例文件名的匹配原则,“*”表示任意多个字符
3.top_level_dir=None:测试模块的顶层目录。如果没顶层目录(也就是说测试用例不是放在多级目录
中),默认为 None
""" if __name__ == '__main__':
"""通过把discover中的用例加载到测试套件中执行"""
suite = unittest.TestSuite() # 定义一个测试套件
# discover 方法筛选出来的用例,循环添加到测试套件中
for test_suite in discover:
for test_case in test_suite:
suite.addTests(test_case)
print(suite) #打印一下可以看到suite中添加了哪些测试用例
now = time.strftime("%Y-%m-%d %H_%M_%S")
filename = 'E:/CommonService/interface/report/' + now + '_result.html'
fp = open(filename, 'wb')
runner = HTMLTestRunner(stream=fp,
title='UnifiedReporting Test Report',
description='Implementation Example with: ')
runner.run(suite)
(3)把discover加载测试用例的过程封装到一个函数中
run_all_case.py import time
from HTMLTestRunner import HTMLTestRunner
import unittest def allCase():
"""定义一个函数,封装discover加载测试用例的方法"""
case_dir = 'E:/CommonService/interface/case' # 定义用例所在路径
suite = unittest.TestSuite() # 定义一个测试套件
discover = unittest.defaultTestLoader.discover(case_dir,
pattern='test_*.py',
top_level_dir=None)
# discover 方法筛选出来的用例,循环添加到测试套件中
for test_suite in discover:
for test_case in test_suite:
suite.addTests(test_case)
return suite if __name__ == '__main__':
allsuite = allCase()
# runner = unittest.TextTestRunner()
now = time.strftime("%Y-%m-%d %H_%M_%S")
filename = 'E:/CommonService/interface/report/' + now + '_result.html'
fp = open(filename, 'wb')
runner = HTMLTestRunner(stream=fp,
title='UnifiedReporting Test Report',
description='Implementation Example with: ')
runner.run(allsuite)
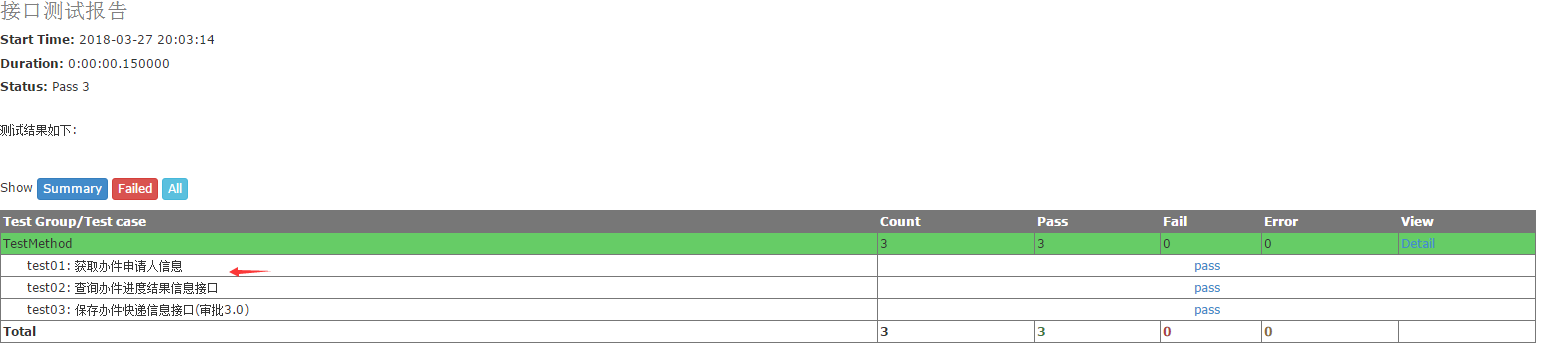
测试报告如下:

记录python接口自动化测试--利用unittest生成测试报告(第四目)的更多相关文章
- 记录python接口自动化测试--简单总结一下学习过程(第十目)
至此,从excel文件中循环读取接口到把测试结果写进excel,一个简易的接口自动化测试框架就完成了.大概花了1周的时间,利用下班和周末的时间来理顺思路.编写调试代码,当然现在也还有很多不足,例如没有 ...
- 记录python接口自动化测试--unittest框架基本应用(第二目)
在第一目里写了几个简单demo,并把调用get和post请求的方法封装到了一个类里,这次结合python自带的unittest框架,用之前封装的方法来写一个接口测试demo 1.unittest简单用 ...
- python接口自动化测试(八)-unittest-生成测试报告
用例的管理问题解决了后,接下来要考虑的就是报告我问题了,这里生成测试报告主要用到 HTMLTestRunner.py 这个模块,下面简单介绍一下如何使用: 一.下载HTMLTestRunner下载: ...
- Python+request 测试结果结合unittest生成测试报告《四》
测试报告示例图: 目录结构介绍: 主要涉及更改的地方: 1.导入 Common.HTMLTestRunner2文件 2.run_test.py文件中新增测试报告相关的代码 具体代码实现: 1 ...
- 记录python接口自动化测试--pycharm执行测试用例时需要使用的姿势(解决if __name__ == "__main__":里面的程序不生效的问题)(第三目)
1.只运行某一条case 把光标移动到某一条case后面,然后右键,选择"Run..."来运行程序 此时,pycharm会只运行光标所在位置的这一条case 2.如果想执行全部ca ...
- 记录python接口自动化测试--把测试结果写进excel文件(第九目)
python中一般使用xlrd(excel read)来读取Excel文件,使用xlwt(excel write)来生成Excel文件(可以控制Excel中单元格的格式),需要注意的是,用xlrd读取 ...
- 记录python接口自动化测试--从excel中读取params参数传入requests请求不生效问题的解决过程(第七目)
在第六目把主函数写好了,先来运行一下主函数 从截图中可以看到,请求参数打印出来了,和excel中填写的一致 但是每个接口的返回值却都是400,提示参数没有传进去,开始不知道是什么原因(因为excel中 ...
- 记录python接口自动化测试--requests使用和基本方法封装(第一目)
之前学习了使用jmeter+ant做接口测试,并实现了接口的批量维护管理(大概500多条用例),对"接口"以及"接口测试"有了一个基础了解,最近找了一些用pyt ...
- 记录python接口自动化测试--主函数(第六目)
把操作excel的方法封装好后,就可以用准备好的接口用例来循环遍历了 我的接口测试用例如下 主函数代码: run_handle_excel.py# coding:utf-8 from base.run ...
随机推荐
- 基于jQuery的一个提示功能的实现
最近有点忙,没有时间更新自己的博客,只能说我在原地踏步了,不知道你们进步了没有? 今天给大家分享一个提示的实现,有点简单,适合小白同学学习.下面是效果图 提示的功能: 当鼠标进入“我的菜单”的子菜单时 ...
- hdu5556 Land of Farms
我对于题目的一种理解 改造农场 1.建新农场 在空的点选 2.重建旧农场 选一个点属于这个农场的地方都要选 最后的农场都不能相连 所以枚举旧农场的个数并进行二分图匹配 #include<bits ...
- 简单使用Mysql-Cluster-7.5搭建数据库集群
阅读目录 前言 mysql cluster中的几个概念解释 架构图及说明 下载mysql cluster 安装mysql cluster之前 安装配置管理节点 安装配置数据和mysql节点 测试 启动 ...
- 让你的微信小程序具有在线支付功能
前言 最近需要在微信小程序中用到在线支付功能,于是看了一下官方的文档,发现要在小程序里实现微信支付还是很方便的,如果你以前开发过服务号下的微信支付,那么你会发现其实小程序里的微信支付和服务号里的开发过 ...
- 关于webpack,打包时遇到的错误
最近在研究webpack这玩意,然后遇到一个问题,执行npm run build的时候,出现下面这个问题,各种搜索后,各种尝试,都没解决 运行时报错ERROR in ./src/app.vue Mod ...
- C#图解教程 第二十章 异步编程
笔记 异步编程 什么是异步 示例 async/await特性的结构什么是异步方法 异步方法的控制流await表达式取消一个异步操作异常处理和await表达式在调用方法中同步地等待任务在异步方法中异步地 ...
- Labview中嵌入flex/flash
将flash动画作为ActiveX文档插入LabVIEW程序的前面板的方法 (1)在前面板插入Controls的ActiveX Container控件. (2)在Container控件上单击鼠标右键, ...
- Redis进阶实践之十六 Redis大批量增加数据
一.介绍 有时,Redis实例需要在很短的时间内加载大量先前存在或用户生成的数据,以便尽可能快地创建数百万个键.这就是所谓的批量插入,本文档的目标是提供有关如何以尽可能快的速度向Redis提 ...
- 【HNOI 2002 】营业额统计(splay)
题面 Description Tiger最近被公司升任为营业部经理,他上任后接受公司交给的第一项任务便是统计并分析公司成立以来的营业情况. Tiger拿出了公司的账本,账本上记录了公司成立以来每天的营 ...
- angular采坑记录
在angular中会遇到一些莫名的问题,导致不能完成想要的功能,可能是某项用法使用错误,或许是angular相对应不支持,或者是我们功力根本就没有达到.为了在每次采坑之后能有所收获,再遇到时能理解其根 ...